Recognition: unknown
Probing for Reading Times
Pith reviewed 2026-05-10 05:15 UTC · model grok-4.3
The pith
Early layers of language models outperform surprisal in predicting initial human reading times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
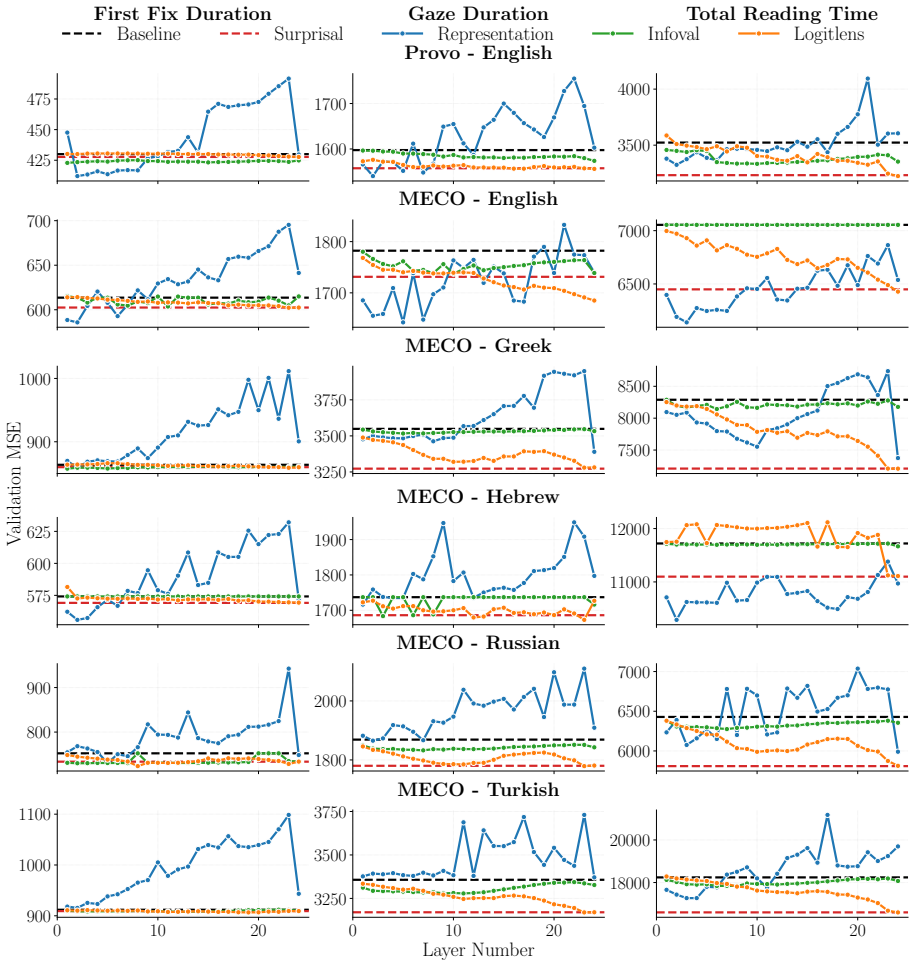
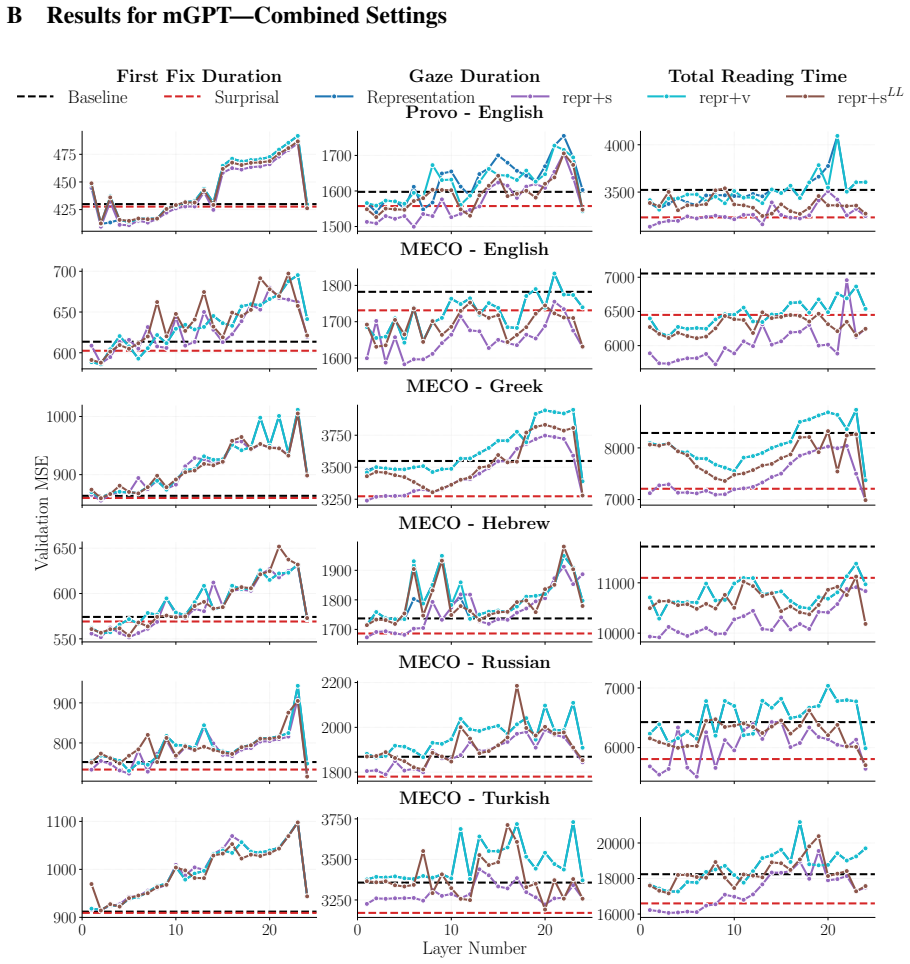
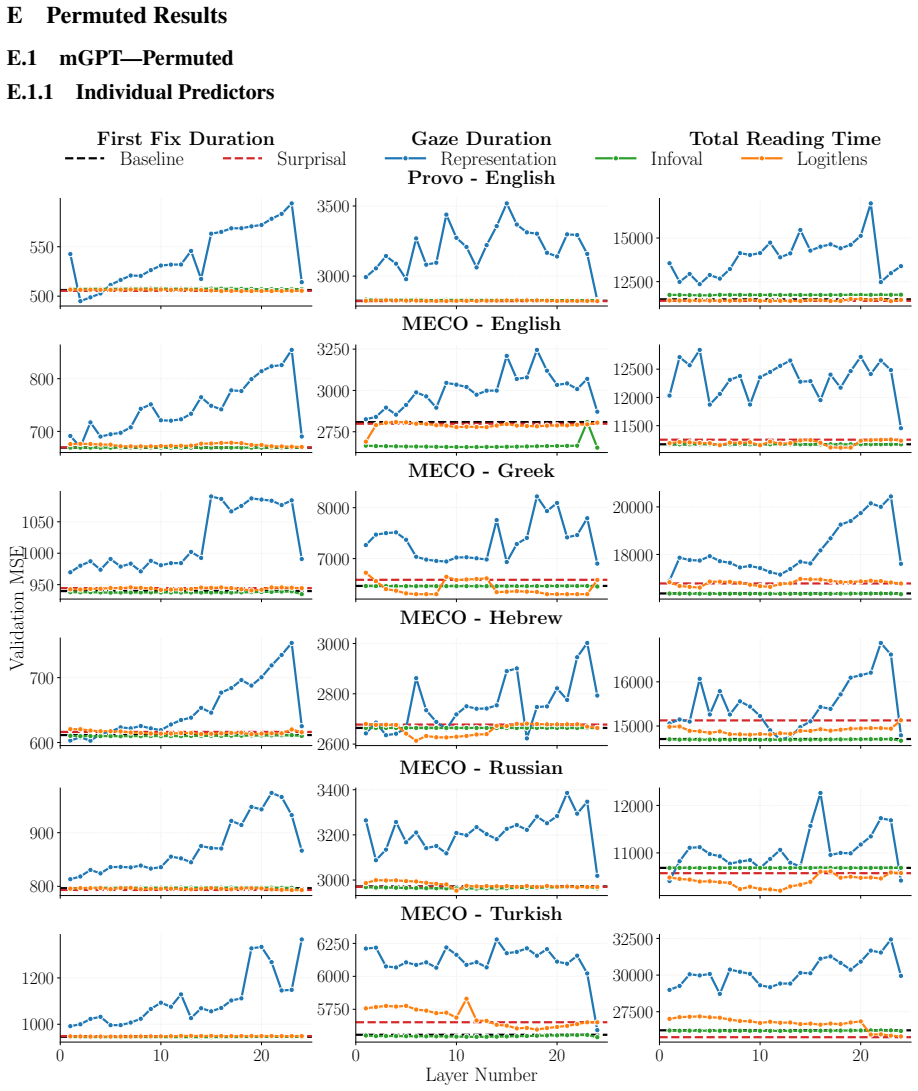
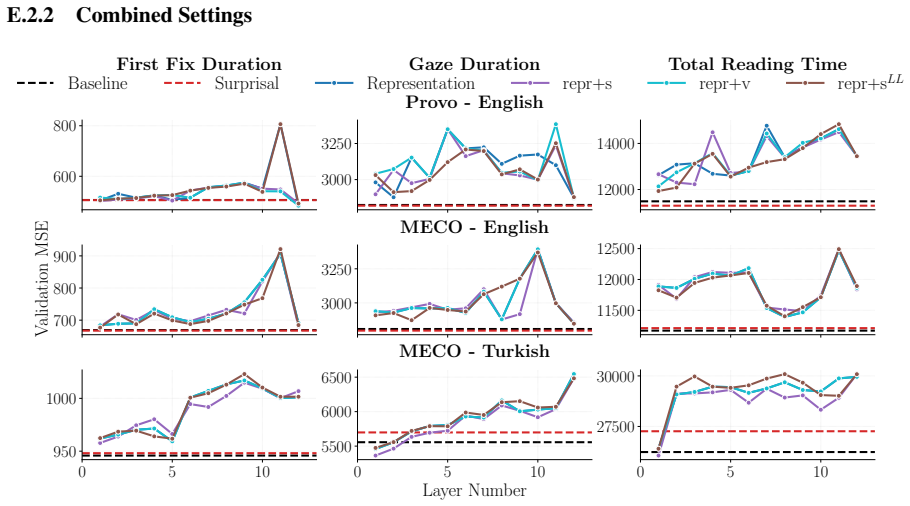
Probing language model representations with regularized linear regression on eye-tracking corpora spanning English, Greek, Hebrew, Russian, and Turkish shows that activations from early layers outperform scalar surprisal, information value, and logit-lens surprisal for early-pass measures such as first fixation duration and gaze duration. For late-pass measures such as total reading time, scalar surprisal remains superior despite its compressed form. Gains occur when combining surprisal with early-layer representations, although the single best predictor varies by language and measure.
What carries the argument
Layer-wise probing via regularized linear regression that compares transformer activations at each depth against surprisal baselines to predict eye-movement durations.
If this is right
- Model depth aligns with temporal stages of human reading, with early layers matching initial fixations.
- Surprisal better captures later integration or re-reading processes.
- Hybrid use of surprisal and early-layer representations yields stronger predictions overall.
- The optimal predictor depends on both the specific eye-tracking measure and the language.
Where Pith is reading between the lines
- Layer selection in future cognitive modeling could be guided by whether the target signal occurs early or late in reading.
- The observed alignment may shift under different training regimes or model sizes, suggesting targeted experiments on larger or differently trained models.
- Similar layer-wise patterns could be tested against other human signals such as brain activity recordings to check for broader functional correspondences.
Load-bearing premise
The performance edge of early-layer representations specifically reflects capture of human-like cognitive signals rather than other statistical properties of the representations or unaccounted factors in the eye-tracking data.
What would settle it
A regression on eye-tracking data collected from scrambled or non-linguistic word sequences where early layers continue to outperform surprisal would indicate that the advantage is not tied to human-like processing.
Figures






read the original abstract
Probing has shown that language model representations encode rich linguistic information, but it remains unclear whether they also capture cognitive signals about human processing. In this work, we probe language model representations for human reading times. Using regularized linear regression on two eye-tracking corpora spanning five languages (English, Greek, Hebrew, Russian, and Turkish), we compare the representations from every model layer against scalar predictors -- surprisal, information value, and logit-lens surprisal. We find that the representations from early layers outperform surprisal in predicting early-pass measures such as first fixation and gaze duration. The concentration of predictive power in the early layers suggests that human-like processing signatures are captured by low-level structural or lexical representations, pointing to a functional alignment between model depth and the temporal stages of human reading. In contrast, for late-pass measures such as total reading time, scalar surprisal remains superior, despite its being a much more compressed representation. We also observe performance gains when using both surprisal and early-layer representations. Overall, we find that the best-performing predictor varies strongly depending on the language and eye-tracking measure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript uses regularized linear regression to probe every layer of language models against human reading times from eye-tracking corpora in five languages. It compares high-dimensional layer representations to scalar baselines (surprisal, information value, logit-lens surprisal) and reports that early-layer representations outperform surprisal on early-pass measures (first fixation duration, gaze duration), while surprisal remains superior for late-pass measures such as total reading time. The authors interpret the early-layer advantage as evidence that low-level structural or lexical representations capture human-like processing signatures, implying functional alignment between model depth and temporal stages of reading; they also note performance gains from combining predictors and strong variation across languages and measures.
Significance. If the layer-specific effects survive proper controls, the work would offer a concrete bridge between transformer representations and psycholinguistic processing stages, extending probing methodology to cognitive signals. Credit is due for the multi-language design, direct comparison against multiple scalar baselines, and the observation that the best predictor depends on both language and eye-tracking measure. These elements make the empirical contribution potentially valuable even if the cognitive-alignment interpretation requires strengthening.
major comments (2)
- [Methods] Methods section (regression specification): the layer probes are not residualized against or augmented with standard lexical covariates (word length, log-frequency, orthographic features). Early layers predominantly encode token identity and frequency-like statistics, which are established strong predictors of first-fixation and gaze duration; without explicit controls, the reported outperformance over surprisal could be explained by more effective recovery of these surface confounds rather than capture of human-like cognitive signals. This directly undermines the central interpretive claim in the abstract.
- [Results] Results section (statistical reporting): no mention is made of multiple-comparison correction across layers, languages, and measures, nor of effect-size reporting or pre-registration of layer selection. Given that the key finding is the concentration of predictive power in early layers, absence of these controls leaves open the possibility that the advantage is an artifact of post-hoc choices, consistent with the low soundness rating.
minor comments (2)
- [Abstract] Abstract: the statement that 'the best-performing predictor varies strongly depending on the language' would be more persuasive if accompanied by a compact summary table of per-language, per-measure rankings rather than left as a qualitative observation.
- [Discussion] Discussion: the paper would benefit from citing prior eye-tracking regression studies that explicitly control for length and frequency when benchmarking surprisal, to better situate the baseline comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below and have revised the manuscript to incorporate the suggested improvements where feasible.
read point-by-point responses
-
Referee: [Methods] Methods section (regression specification): the layer probes are not residualized against or augmented with standard lexical covariates (word length, log-frequency, orthographic features). Early layers predominantly encode token identity and frequency-like statistics, which are established strong predictors of first-fixation and gaze duration; without explicit controls, the reported outperformance over surprisal could be explained by more effective recovery of these surface confounds rather than capture of human-like cognitive signals. This directly undermines the central interpretive claim in the abstract.
Authors: We agree that this is an important control. In the revised manuscript we have augmented all regression models with the standard lexical covariates (word length, log-frequency, and orthographic neighborhood features). We now present results both with and without these covariates. The early-layer advantage over surprisal remains statistically reliable after inclusion of the covariates, indicating that the layer representations capture predictive information beyond surface lexical statistics. This change directly addresses the concern and bolsters the interpretive claim. revision: yes
-
Referee: [Results] Results section (statistical reporting): no mention is made of multiple-comparison correction across layers, languages, and measures, nor of effect-size reporting or pre-registration of layer selection. Given that the key finding is the concentration of predictive power in early layers, absence of these controls leaves open the possibility that the advantage is an artifact of post-hoc choices, consistent with the low soundness rating.
Authors: We accept the need for stricter statistical controls. The revised results section now applies Bonferroni correction across all layer-language-measure combinations and reports adjusted significance levels. We have also added incremental R² effect-size values for the key comparisons between layer representations and scalar baselines. Because the study was not pre-registered, we cannot retroactively satisfy that requirement; however, we now explicitly state that all layers were evaluated and report the full set of results without selective emphasis on early layers. revision: partial
- Pre-registration of the analysis plan and layer-selection procedure, which cannot be performed retroactively.
Circularity Check
No significant circularity in empirical probing study
full rationale
The paper reports results from an empirical probing experiment: regularized linear regression is used to predict eye-tracking reading times from LM layer activations (and from scalar baselines like surprisal) on external corpora in five languages. No equations, derivations, or first-principles claims appear in the provided text; performance differences are measured directly on held-out data rather than being defined by construction from the same fitted quantities. The interpretive claim about layer-depth alignment with reading stages follows from the observed pattern but does not reduce to a self-referential definition or self-citation chain. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guillaume Alain and Yoshua Bengio. 2017. https://arxiv.org/abs/1610.01644 Understanding intermediate layers using linear classifier probes . In International Conference on Learning Representations
work page Pith review arXiv 2017
-
[2]
Catherine Arnett and Benjamin Bergen. 2025. https://aclanthology.org/2025.coling-main.441/ Why do language models perform worse for morphologically complex languages? In Proceedings of the International Conference on Computational Linguistics
2025
-
[3]
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. 2025. https://arxiv.org/abs/2303.08112 Eliciting latent predictions from transformers with the tuned lens
work page internal anchor Pith review arXiv 2025
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://proceedings.neurips.cc/paper_fil...
2020
-
[5]
Raymond B. Cattell. 1966. https://doi.org/10.1207/s15327906mbr0102\_10 The scree test for the number of factors . Multivariate Behavioral Research, 1(2):245--276. PMID: 26828106
-
[6]
Charlotte Caucheteux and Jean-R \'e mi King. 2022. https://doi.org/10.1038/s42003-022-03036-1 Brains and algorithms partially converge in natural language processing . Communications Biology, 5(1)
-
[7]
Charles Clifton, Adrian Staub, and Keith Rayner. 2007. https://www.sciencedirect.com/science/article/pii/B9780080449807500173 Eye movements in reading words and sentences . In Eye Movements. Elsevier
2007
-
[8]
Anne E. Cook and Wencl Wei. 2019. https://doi.org/10.3390/vision3030045 What can eye movements tell us about higher level comprehension? Vision, 3(3)
-
[9]
Juan Luis Gastaldi, John Terilla, Luca Malagutti, Brian DuSell, Tim Vieira, and Ryan Cotterell. 2025. https://openreview.net/forum?id=B5iOSxM2I0 The foundations of tokenization: Statistical and computational concerns . In The International Conference on Learning Representations
2025
-
[10]
Mario Giulianelli, Luca Malagutti, Juan Luis Gastaldi, Brian DuSell, Tim Vieira, and Ryan Cotterell. 2024 a . https://aclanthology.org/2024.emnlp-main.1032/ On the proper treatment of tokenization in psycholinguistics . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
2024
-
[11]
Mario Giulianelli, Andreas Opedal, and Ryan Cotterell. 2024 b . https://aclanthology.org/2024.findings-emnlp.682/ Generalized measures of anticipation and responsivity in online language processing . In Findings of the Association for Computational Linguistics: EMNLP 2024
2024
-
[12]
Mario Giulianelli, Sarenne Wallbridge, Ryan Cotterell, and Raquel Fern \'a ndez. 2026. https://www.sciencedirect.com/science/article/pii/S0749596X25001081 Incremental alternative sampling as a lens into the temporal and representational resolution of linguistic prediction . Journal of Memory and Language, 148
2026
-
[13]
Mario Giulianelli, Sarenne Wallbridge, and Raquel Fern \'a ndez. 2023. https://aclanthology.org/2023.emnlp-main.343/ Information value: Measuring utterance predictability as distance from plausible alternatives . In Proceedings of the Conference on Empirical Methods in Natural Language Processing
2023
-
[14]
Adam Goodkind and Klinton Bicknell. 2018. https://aclanthology.org/W18-0102 Predictive power of word surprisal for reading times is a linear function of language model quality . In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics
2018
-
[15]
John Hale. 2001. https://aclanthology.org/N01-1021/ A probabilistic Earley parser as a psycholinguistic model . In Proceedings of the Meeting of the North American Chapter of the Association for Computational Linguistics
2001
-
[16]
Alexander Immer, Lucas Torroba Hennigen, Vincent Fortuin, and Ryan Cotterell. 2022. https://aclanthology.org/2022.acl-long.129/ Probing as quantifying inductive bias . In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2022
-
[17]
Marcel A. Just and Patricia A. Carpenter. 1980. https://doi.org/10.1037/0033-295X.87.4.329 A theory of reading: From eye fixations to comprehension . Psychological Review, 87(4)
-
[18]
H. Toprak Kesgin, M. Kaan Yuce, Eren Dogan, M. Egemen Uzun, Atahan Uz, H. Emre Seyrek, Ahmed Zeer, and M. Fatih Amasyali. 2024. https://doi.org/10.1109/INISTA62901.2024.10683863 Introducing cosmosGPT : Monolingual training for Turkish language models . In International Conference on INnovations in Intelligent SysTems and Applications (INISTA)
-
[19]
Samuel Kiegeland, V \'e steinn Sn bjarnarson, Tim Vieira, and Ryan Cotterell. 2026. On the proper treatment of units in surprisal theory. In Proceedings of the Annual Meeting of the Association for Computational Linguistics
2026
- [20]
-
[21]
Tatsuki Kuribayashi, Yohei Oseki, and Timothy Baldwin. 2024. https://aclanthology.org/2024.findings-naacl.129/ Psychometric predictive power of large language models . In Findings of the Association for Computational Linguistics: NAACL 2024
2024
-
[22]
Tatsuki Kuribayashi, Yohei Oseki, Souhaib Ben Taieb, Kentaro Inui, and Timothy Baldwin. 2025. https://aclanthology.org/2025.tacl-1.78/ Large language models are human-like internally . Transactions of the Association for Computational Linguistics, 13
2025
-
[23]
Roger Levy. 2008. https://www.sciencedirect.com/science/article/pii/S0010027707001436 Expectation-based syntactic comprehension . Cognition, 106(3)
2008
-
[24]
Steven G. Luke and Kiel Christianson. 2018. https://link.springer.com/article/10.3758/s13428-017-0908-4 The Provo corpus: A large eye-tracking corpus with predictability norms . Behavior Research Methods, 50
-
[25]
Clara Meister, Tiago Pimentel, Thomas Clark, Ryan Cotterell, and Roger Levy. 2022. https://aclanthology.org/2022.acl-short.3/ Analyzing wrap-up effects through an information-theoretic lens . In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
2022
-
[26]
Maxime M \'e loux, Silviu Maniu, Fran c ois Portet, and Maxime Peyrard. 2025. https://openreview.net/forum?id=5IWJBStfU7 Everything, everywhere, all at once: Is mechanistic interpretability identifiable? In The International Conference on Learning Representations
2025
-
[27]
nostalgebraist. 2020. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens Interpreting GPT : The logit lens
2020
-
[28]
Byung-Doh Oh and William Schuler. 2023. https://doi.org/10.1162/tacl_a_00548 Why does surprisal from larger transformer-based language models provide a poorer fit to human reading times? Transactions of the Association for Computational Linguistics, 11
-
[29]
Byung-Doh Oh and William Schuler. 2024. https://aclanthology.org/2024.emnlp-main.202/ Leading whitespaces of language models' subword vocabulary pose a confound for calculating word probabilities . In Proceedings of the Conference on Empirical Methods in Natural Language Processing
2024
-
[30]
Andreas Opedal, Eleanor Chodroff, Ryan Cotterell, and Ethan Wilcox. 2024. https://aclanthology.org/2024.emnlp-main.179/ On the role of context in reading time prediction . In Proceedings of the Conference on Empirical Methods in Natural Language Processing
2024
-
[31]
Tiago Pimentel and Clara Meister. 2024. https://aclanthology.org/2024.emnlp-main.1020/ How to compute the probability of a word . In Proceedings of the Conference on Empirical Methods in Natural Language Processing
2024
-
[32]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf Language models are unsupervised multitask learners
2019
-
[33]
Keith Rayner. 1998. http://dx.doi.org/10.1037/0033-2909.124.3.372 Eye movements in reading and information processing: 20 years of research . Psychological Bulletin, 124(3)
-
[34]
Keith Rayner. 2009. https://doi.org/10.1080/17470210902816461 Eye movements and attention in reading, scene perception, and visual search . The Quarterly Journal of Experimental Psychology, 62(8)
-
[35]
Keith Rayner and Martin H. Fischer. 1996. https://doi.org/10.3758/BF03213106 Mindless reading revisited: Eye movements during reading and scanning are different . Perception & Psychophysics, 58(5)
-
[36]
Keith Rayner, Gretchen Kambe, and Susan A. Duffy. 2000. https://doi.org/10.1080/713755934 The effect of clause wrap-up on eye movements during reading . The Quarterly Journal of Experimental Psychology Section A, 53(4)
-
[37]
Francesco Ignazio Re, Andreas Opedal, Glib Manaiev, Mario Giulianelli, and Ryan Cotterell. 2025. https://aclanthology.org/2025.acl-long.1474/ A spatio-temporal point process for fine-grained modeling of reading behavior . In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2025
-
[38]
Hosseini, Nancy Kanwisher, Joshua B
Martin Schrimpf, Idan Asher Blank, Greta Tuckute, Carina Kauf, Eghbal A. Hosseini, Nancy Kanwisher, Joshua B. Tenenbaum, and Evelina Fedorenko. 2021. https://www.pnas.org/doi/abs/10.1073/pnas.2105646118 The neural architecture of language: Integrative modeling converges on predictive processing . Proceedings of the National Academy of Sciences, 118(45)
-
[39]
Cory Shain, Clara Meister, Tiago Pimentel, Ryan Cotterell, and Roger Levy. 2024. https://www.pnas.org/doi/abs/10.1073/pnas.2307876121 Large-scale evidence for logarithmic effects of word predictability on reading time . Proceedings of the National Academy of Sciences, 121(10)
-
[40]
Oleh Shliazhko, Alena Fenogenova, Maria Tikhonova, Anastasia Kozlova, Vladislav Mikhailov, and Tatiana Shavrina. 2024. https://aclanthology.org/2024.tacl-1.4/ m GPT : Few-shot learners go multilingual . Transactions of the Association for Computational Linguistics, 12
2024
-
[41]
Noam Siegelman, Sascha Schroeder, Cengiz Acart \"u rk, Hee-Don Ahn, Svetlana Alexeeva, Simona Amenta, Raymond Bertram, Rolando Bonandrini, Marc Brysbaert, and Daria Chernova. 2022. https://link.springer.com/article/10.3758/s13428-021-01772-6 Expanding horizons of cross-linguistic research on reading: T he Multilingual Eye-movement Corpus ( MECO ) . Behavi...
-
[42]
Smith and Roger Levy
Nathaniel J. Smith and Roger Levy. 2013. https://www.sciencedirect.com/science/article/pii/S0010027713000413 The effect of word predictability on reading time is logarithmic . Cognition, 128(3)
2013
-
[43]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html Attention is all you need . In Advances in Neural Information Processing Systems, volume 30
2017
-
[44]
O'Donnell, and Ryan Cotterell
Tim Vieira, Benjamin Lebrun, Mario Giulianelli, Juan Luis Gastaldi, Brian Dusell, John Terilla, Timothy J. O'Donnell, and Ryan Cotterell. 2025. https://proceedings.mlr.press/v267/vieira25a.html From language models over tokens to language models over characters . In Proceedings of the International Conference on Machine Learning, volume 267
2025
-
[45]
Chris Wendler, Veniamin Veselovsky, Giovanni Monea, and Robert West. 2024. https://aclanthology.org/2024.acl-long.820/ Do Llamas work in English ? on the latent language of multilingual transformers . In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2024
-
[46]
White, Tiago Pimentel, Naomi Saphra, and Ryan Cotterell
Jennifer C. White, Tiago Pimentel, Naomi Saphra, and Ryan Cotterell. 2021. https://aclanthology.org/2021.naacl-main.12/ A non-linear structural probe . In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
2021
-
[47]
Wilcox, Tiago Pimentel, Clara Meister, Ryan Cotterell, and Roger P
Ethan G. Wilcox, Tiago Pimentel, Clara Meister, Ryan Cotterell, and Roger P. Levy. 2023. https://aclanthology.org/2023.tacl-1.82/ Testing the predictions of surprisal theory in 11 languages . Transactions of the Association for Computational Linguistics, 11
2023
- [48]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.