Recognition: unknown
Discrete Tilt Matching
Pith reviewed 2026-05-10 04:27 UTC · model grok-4.3
The pith
Discrete Tilt Matching recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting to sidestep intractable marginal likelihoods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
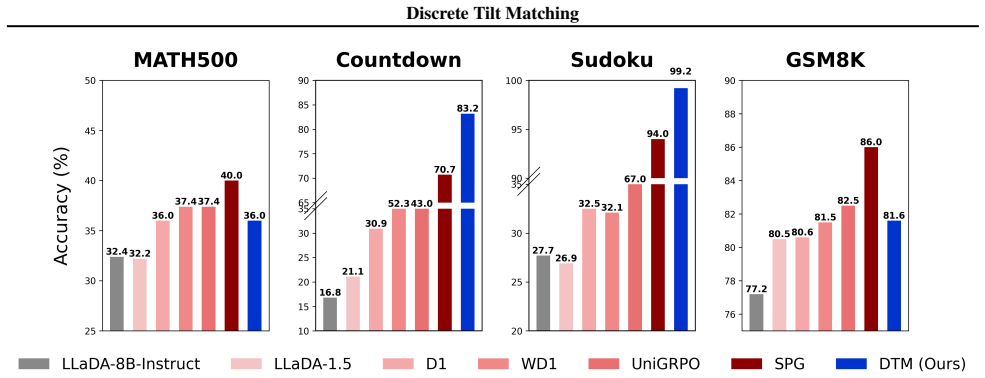
We derive Discrete Tilt Matching (DTM), a likelihood-free method that recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting. DTM takes the form of a weighted cross-entropy objective with explicit minimizer, and admits control variates that improve training stability. On a synthetic maze-planning task, we analyze how DTM's annealing schedule and control variates affect training stability and prevent mode collapse. At scale, fine-tuning LLaDA-8B-Instruct with DTM yields strong gains on Sudoku and Countdown while remaining competitive on MATH500 and GSM8K.
What carries the argument
Discrete Tilt Matching objective, a weighted cross-entropy loss that aligns reward-tilted local unmasking posteriors at each state.
If this is right
- DTM can be applied to any masked diffusion model without requiring approximations to full-sequence marginals.
- Control variates and annealing schedules keep training stable and avoid mode collapse during reward-based fine-tuning.
- An 8B model fine-tuned with DTM improves on structured tasks such as Sudoku and Countdown.
- Performance on standard math benchmarks stays competitive after the same fine-tuning procedure.
Where Pith is reading between the lines
- The state-level formulation could allow finer-grained reward shaping than sequence-level methods permit.
- Similar tilting and matching steps may transfer to other discrete diffusion or non-autoregressive generators.
- The explicit control variates might be reusable in other likelihood-free alignment settings on discrete data.
Load-bearing premise
Matching state-level local unmasking posteriors under reward tilting is sufficient to achieve effective sequence-level fine-tuning without access to marginal likelihoods.
What would settle it
A head-to-head comparison of DTM against an exact sequence-level RL method on a small dLLM where marginal likelihoods can be computed exactly, checking whether the resulting sequence-level performance is identical.
Figures










read the original abstract
Masked diffusion large language models (dLLMs) are a promising alternative to autoregressive generation. While reinforcement learning (RL) methods have recently been adapted to dLLM fine-tuning, their objectives typically depend on sequence-level marginal likelihoods, which are intractable for masked diffusion models. To address this, we derive Discrete Tilt Matching (DTM), a likelihood-free method that recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting. DTM takes the form of a weighted cross-entropy objective with explicit minimizer, and admits control variates that improve training stability. On a synthetic maze-planning task, we analyze how DTM's annealing schedule and control variates affect training stability and prevent mode collapse. At scale, fine-tuning LLaDA-8B-Instruct with DTM yields strong gains on Sudoku and Countdown while remaining competitive on MATH500 and GSM8K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives Discrete Tilt Matching (DTM), a likelihood-free objective for fine-tuning masked diffusion LLMs (dLLMs) by recasting the problem as state-level matching of local unmasking posteriors under reward tilting. DTM is expressed as a weighted cross-entropy loss with an explicit minimizer and admits control variates for improved stability. Experiments on a synthetic maze task examine the effects of annealing and control variates on stability and mode collapse, while scaling to LLaDA-8B-Instruct shows gains on Sudoku and Countdown with competitive performance on MATH500 and GSM8K.
Significance. If the local matching is proven to induce the correct global sequence-level distribution, DTM would provide a valuable practical tool for dLLM fine-tuning by avoiding intractable marginal likelihoods. The explicit minimizer and control variates represent clear strengths for training. The reported empirical improvements on reasoning tasks are promising, though the synthetic results focus mainly on stability rather than confirming global optimality.
major comments (2)
- Abstract: The central derivation recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting to yield a weighted cross-entropy with explicit minimizer, but no steps are shown establishing that this local objective's fixed point coincides with the reward-tilted sequence measure (i.e., that the Markov chain of unmasking steps preserves the global path measure under tilting).
- Synthetic maze-planning task: The analysis probes how the annealing schedule and control variates affect stability and prevent mode collapse, but does not test whether the DTM fixed point equals the desired global optimum under the sequence-level reward-tilted distribution, leaving the sufficiency of local matching unverified.
minor comments (2)
- Experimental details on the precise form of the control variates, the functional form of the annealing schedule, and the exact baselines used for comparison are insufficient for full reproducibility.
- Quantitative results on the large-scale tasks (e.g., exact accuracy deltas, standard deviations, or number of runs) are not reported in the abstract or summary, weakening the strength of the 'strong gains' claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight an important aspect of the derivation that would benefit from greater explicitness. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and proof steps.
read point-by-point responses
-
Referee: Abstract: The central derivation recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting to yield a weighted cross-entropy with explicit minimizer, but no steps are shown establishing that this local objective's fixed point coincides with the reward-tilted sequence measure (i.e., that the Markov chain of unmasking steps preserves the global path measure under tilting).
Authors: We agree that the manuscript would be strengthened by including explicit intermediate steps in the derivation. In the revised version we will expand Section 3 to contain a dedicated subsection that proves the fixed point of the local DTM objective coincides with the reward-tilted sequence measure. The argument proceeds by showing that the unmasking process is a Markov chain on states and that consistent tilting of the local posteriors at each step preserves the global path measure; we will write out the telescoping product of the tilted transition probabilities and demonstrate that the minimizer of the weighted cross-entropy is exactly the desired tilted distribution. This addition directly addresses the concern. revision: yes
-
Referee: Synthetic maze-planning task: The analysis probes how the annealing schedule and control variates affect stability and prevent mode collapse, but does not test whether the DTM fixed point equals the desired global optimum under the sequence-level reward-tilted distribution, leaving the sufficiency of local matching unverified.
Authors: The synthetic maze experiments were designed to isolate and quantify the effects of annealing schedules and control variates on training stability and mode collapse, which are practically critical for scaling DTM. We acknowledge that these runs do not empirically confirm global optimality. With the expanded theoretical proof we will add (per the first comment), the equivalence between local and global objectives will be established analytically. In the revision we will clarify the purpose of the synthetic section and explicitly reference the theoretical guarantee, so that readers understand the experiments address implementation issues rather than the sufficiency proof itself. revision: partial
Circularity Check
No circularity: DTM derived as independent objective with explicit minimizer
full rationale
The paper presents DTM as a derived likelihood-free objective that recasts dLLM fine-tuning via state-level matching of tilted local unmasking posteriors, expressed as a weighted cross-entropy with an explicit closed-form minimizer. This construction does not reduce to fitted inputs renamed as predictions, self-definitional loops, or load-bearing self-citations; the abstract and description show a forward derivation from the masked diffusion Markov structure to the new loss without tautological equivalence to prior parameters. The sufficiency of local-to-global induction is a separate modeling claim, not a circularity in the derivation chain itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- annealing schedule
axioms (1)
- domain assumption The unmasking process in dLLMs allows for local posterior computation
Reference graph
Works this paper leans on
-
[1]
2025 , url =
Arel , title =. 2025 , url =
2025
-
[2]
International Conference on Learning Representations (ICLR 2019) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR 2019) , year =
2019
-
[3]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the 41st International Conference on Machine Learning (ICML 2024) , series =
Generative Flows on Discrete State-Spaces: Enabling Multimodal Flows with Applications to Protein Co-Design , author =. Proceedings of the 41st International Conference on Machine Learning (ICML 2024) , series =. 2024 , address =
2024
-
[5]
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation , author=. arXiv preprint arXiv:2506.20639 , year=
-
[6]
Dream-coder 7b: An open diffusion language model for code.arXiv preprint arXiv:2509.01142, 2025
Dream-coder 7b: An open diffusion language model for code , author=. arXiv preprint arXiv:2509.01142 , year=
-
[7]
2025 , eprint=
LLaDA2.0: Scaling Up Diffusion Language Models to 100B , author=. 2025 , eprint=
2025
-
[8]
2026 , eprint=
Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model , author=. 2026 , eprint=
2026
-
[9]
Potaptchik, Peter and Lee, Cheuk-Kit and Albergo, Michael S
Tilt Matching for Scalable Sampling and Fine-Tuning , author = "Potaptchik, Peter and Lee, Cheuk-Kit and Albergo, Michael S.", eprint=
-
[10]
International Conference on Learning Representations (ICLR 2022) , year =
LoRA: Low-Rank Adaptation of Large Language Models , author =. International Conference on Learning Representations (ICLR 2022) , year =
2022
-
[11]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =
-
[12]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. arXiv preprint arXiv:2402.03300 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2025 , eprint =
Proximal Diffusion Neural Sampler , author =. 2025 , eprint =
2025
-
[14]
SSD-LM: Semi-autoregressive Simplex-based Diffusion Language Model for Text Generation and Modular Control , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2023.acl-long.647 , url =
-
[15]
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , series =
Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML 2025) , series =. 2025 , address =
2025
-
[16]
Any-order flexible length masked diffusion.arXiv preprint arXiv:2509.01025,
Any-Order Flexible Length Masked Diffusion , author =. 2025 , eprint =. doi:10.48550/arXiv.2509.01025 , url =
-
[17]
The Twelfth International Conference on Learning Representations (ICLR 2024) , year =
Let’s Verify Step by Step , author =. The Twelfth International Conference on Learning Representations (ICLR 2024) , year =
2024
-
[18]
Reinforcing Diffusion Models by Direct Group Preference Optimization , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.08425 , url =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
Large Language Diffusion Models , author =. Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
2025
-
[20]
2025 , url =
Pan, Jiayi and Zhang, Junjie and Wang, Xingyao and Yuan, Lifan , title =. 2025 , url =
2025
-
[21]
arXiv preprint arXiv:2510.08554 , year=
Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.08554 , url =
-
[22]
International Conference on Learning Representations (ICLR 2025) , year =
Flow Matching with General Discrete Paths: A Kinetic-Optimal Perspective , author =. International Conference on Learning Representations (ICLR 2025) , year =
2025
-
[23]
wd1: Weighted Policy Optimization for Reasoning in Diffusion Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2507.08838 , url =
-
[24]
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.09541 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.09541 2025
-
[25]
d2 : Improved techniques for training reasoning diffusion language models
d2: Improved Techniques for Training Reasoning Diffusion Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2509.21474 , url =
-
[26]
Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
MMaDA: Multimodal Large Diffusion Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
2025
-
[27]
Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
2025
-
[28]
Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling , author=. arXiv preprint arXiv:2409.02908 , year=
-
[29]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2505.19223 , url =
work page internal anchor Pith review doi:10.48550/arxiv.2505.19223 2025
-
[30]
2024 , eprint=
Simple and Effective Masked Diffusion Language Models , author=. 2024 , eprint=
2024
-
[31]
2024 , eprint=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. 2024 , eprint=
2024
-
[32]
2022 , eprint=
MaskGIT: Masked Generative Image Transformer , author=. 2022 , eprint=
2022
-
[33]
2024 , eprint=
Discrete Flow Matching , author=. 2024 , eprint=
2024
-
[34]
2025 , eprint=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. 2025 , eprint=
2025
-
[35]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[36]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[37]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.