Recognition: unknown
DeltaSeg: Tiered Attention and Deep Delta Learning for Multi-Class Structural Defect Segmentation
Pith reviewed 2026-05-10 04:18 UTC · model grok-4.3
The pith
DeltaSeg integrates tiered attention and a Deep Delta Attention module to segment multiple structural defects more accurately than prior models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeltaSeg establishes that a tiered attention strategy combined with the Deep Delta Attention module, which applies a learned delta operator for nuisance suppression and decoder-conditioned spatial attention gates on skip connections, produces superior boundary delineation and generalization for multi-class structural defect segmentation compared to twelve existing architectures on two benchmarks.
What carries the argument
The Deep Delta Attention (DDA) module, a dual-path mechanism in the skip connections that combines a learned delta operator for feature suppression with spatial attention conditioned on decoder signals.
If this is right
- The model maintains spatial resolution while expanding receptive fields through dilated depthwise convolutions and ASPP at the bottleneck.
- Deep supervision via auxiliary heads at multiple decoder scales strengthens gradient flow and produces semantically richer intermediate features.
- Skip-connection refinement through DDA enables better handling of extreme class imbalance and precise boundary delineation across damage types.
- Consistent outperformance on S2DS (7 classes) and CSDD (9 classes) indicates generalization across imaging conditions and structural geometries.
Where Pith is reading between the lines
- Similar dual-path delta operators could be tested in other dense prediction tasks that face class imbalance, such as medical or satellite image segmentation.
- The staged placement of different attention types suggests that uniform attention across all layers may be suboptimal for encoder-decoder networks.
- Real-time inspection pipelines would require measuring inference speed and memory use on edge hardware to confirm practicality beyond accuracy benchmarks.
Load-bearing premise
The reported gains stem from the tiered attention and Deep Delta Attention design rather than unstated differences in training protocols, data augmentation, or hyperparameter choices.
What would settle it
A controlled experiment that retrains the twelve baseline models (U-Net, SegFormer, Swin-UNet, etc.) with identical data splits, augmentation, optimizer settings, and loss functions as DeltaSeg and measures whether the performance gap disappears.
Figures

read the original abstract
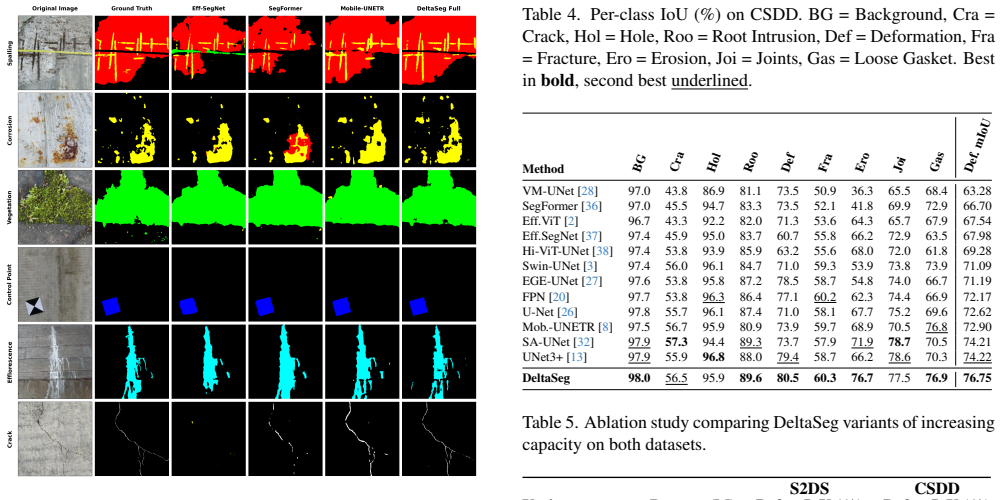
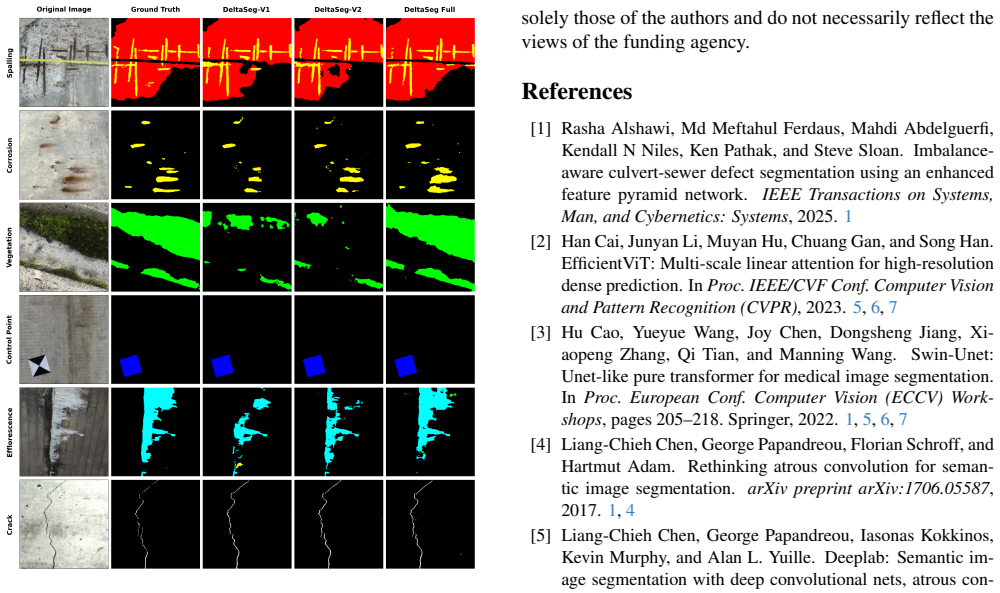
Automated segmentation of structural defects from visual inspection imagery remains challenging due to the diversity of damage types, extreme class imbalance, and the need for precise boundary delineation. This paper presents DeltaSeg, a U-shaped encoder-decoder architecture with a tiered attention strategy that integrates Squeeze-and-Excitation (SE) channel attention in the encoder, Coordinate Attention at the bottleneck and decoder, and a novel Deep Delta Attention (DDA) mechanism in the skip connections. The encoder uses depthwise separable convolutions with dilated stages to maintain spatial resolution while expanding the receptive field. Atrous Spatial Pyramid Pooling (ASPP) at the bottleneck captures multi-scale context. The DDA module refines skip connections through a dual-path scheme combining a learned delta operator for nuisance feature suppression with spatial attention gates conditioned on decoder signals. Deep supervision through multi-scale auxiliary heads further strengthens gradient flow and encourages semantically meaningful features at intermediate decoder stages. We evaluate DeltaSeg on two datasets: the S2DS dataset (7 classes) and the Culvert-Sewer Defect Dataset (CSDD, 9 classes). Across both benchmarks, DeltaSeg consistently outperforms 12 competing architectures including U-Net, SA-UNet, UNet3+, SegFormer, Swin-UNet, EGE-UNet, FPN, and Mobile-UNETR, demonstrating strong generalization across damage types, imaging conditions, and structural geometries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DeltaSeg, a U-shaped encoder-decoder architecture for multi-class structural defect segmentation. It integrates tiered attention via Squeeze-and-Excitation (SE) blocks in the encoder, Coordinate Attention at the bottleneck and decoder stages, and a novel Deep Delta Attention (DDA) module in the skip connections that combines a learned delta operator for nuisance suppression with decoder-conditioned spatial gates. The encoder employs depthwise separable convolutions with dilated stages and ASPP at the bottleneck; deep supervision is added via multi-scale auxiliary heads. Evaluation is performed on the S2DS dataset (7 classes) and CSDD (9 classes), with the claim that DeltaSeg outperforms 12 baselines including U-Net, SA-UNet, UNet3+, SegFormer, Swin-UNet, EGE-UNet, FPN, and Mobile-UNETR across damage types and imaging conditions.
Significance. If the reported gains are shown to arise specifically from the tiered attention and DDA design rather than training-protocol differences, the work would provide a practical contribution to automated infrastructure inspection by improving boundary precision and handling class imbalance in real-world structural imagery.
major comments (1)
- [Experiments] The experimental section does not describe a unified training protocol (identical data splits, augmentation pipelines, optimizer, learning-rate schedule, loss function, and epoch count) applied to all 12 baselines. Without this, the central claim that outperformance on S2DS and CSDD is caused by the SE+Coordinate+DDA architecture cannot be isolated from possible confounding factors.
minor comments (2)
- [Abstract] The abstract states 'consistent outperformance' but supplies no numerical metrics (mIoU, Dice, etc.), error bars, or statistical tests; the results tables in the full manuscript should include these for each dataset and class.
- [Method] The DDA module is described at a high level in the abstract; the method section should provide the explicit equations for the delta operator and the conditioning mechanism to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The primary concern regarding the experimental protocol is addressed below. We will revise the manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: The experimental section does not describe a unified training protocol (identical data splits, augmentation pipelines, optimizer, learning-rate schedule, loss function, and epoch count) applied to all 12 baselines. Without this, the central claim that outperformance on S2DS and CSDD is caused by the SE+Coordinate+DDA architecture cannot be isolated from possible confounding factors.
Authors: We agree that an explicit, unified training protocol must be documented to isolate the contribution of the tiered attention and DDA components. Although the same protocol (identical splits, augmentations, optimizer, scheduler, loss, and epoch budget) was applied to DeltaSeg and all baselines during our experiments, the manuscript did not consolidate these details into a single, clearly labeled subsection. In the revised manuscript we will add a dedicated 'Training Protocol' subsection under Experiments that enumerates the exact data splits, augmentation pipeline, optimizer (AdamW), learning-rate schedule, loss function (combined Dice + cross-entropy with class weighting), batch size, and maximum epoch count used uniformly across all 12 models. This addition will allow readers to verify that performance differences arise from the architectural choices rather than training discrepancies. revision: yes
Circularity Check
No circularity in derivation or performance attribution
full rationale
The paper introduces an architectural design (tiered SE+Coordinate+DDA attention, ASPP, deep supervision) and reports empirical results on two external public datasets against 12 published baselines. No equations, fitted parameters, or self-citations are shown that reduce the claimed outperformance to quantities defined from the same test data or to prior self-referential results. The central claim rests on standard benchmark comparisons whose validity depends on training-protocol details (not addressed here), but this is an empirical gap rather than a circular reduction by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The S2DS and CSDD datasets are representative of structural defects encountered in practice.
invented entities (1)
-
Deep Delta Attention (DDA) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Imbalance- aware culvert-sewer defect segmentation using an enhanced feature pyramid network.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025
Rasha Alshawi, Md Meftahul Ferdaus, Mahdi Abdelguerfi, Kendall N Niles, Ken Pathak, and Steve Sloan. Imbalance- aware culvert-sewer defect segmentation using an enhanced feature pyramid network.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025. 1
2025
-
[2]
EfficientViT: Multi-scale linear attention for high-resolution dense prediction
Han Cai, Junyan Li, Muyan Hu, Chuang Gan, and Song Han. EfficientViT: Multi-scale linear attention for high-resolution dense prediction. InProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2023. 5, 6, 7
2023
-
[3]
Swin-Unet: Unet-like pure transformer for medical image segmentation
Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xi- aopeng Zhang, Qi Tian, and Manning Wang. Swin-Unet: Unet-like pure transformer for medical image segmentation. InProc. European Conf. Computer Vision (ECCV) Work- shops, pages 205–218. Springer, 2022. 1, 5, 6, 7
2022
-
[4]
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartmut Adam. Rethinking atrous convolution for seman- tic image segmentation.arXiv preprint arXiv:1706.05587,
work page internal anchor Pith review arXiv
-
[5]
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille. Deeplab: Semantic im- age segmentation with deep convolutional nets, atrous con- volution, and fully connected crfs.IEEE Trans. Pattern Anal. Mach. Intell., 40(4):834–848, 2018
2018
-
[6]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartmut Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proc. European Conf. Computer Vision (ECCV), pages 801–
-
[7]
Springer, 2018. 1, 2
2018
-
[8]
Xception: Deep learning with depthwise separable convolutions
Franc ¸ois Chollet. Xception: Deep learning with depthwise separable convolutions. InProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), pages 1251–1258,
-
[9]
Roth, and Daguang Xu
Ali Hatamizadeh, Yucheng Tang, Vishwesh Nath, Dong Yang, Andriy Myronenko, Bennett Landman, Holger R. Roth, and Daguang Xu. UNETR: Transformers for 3d med- ical image segmentation. InProc. IEEE/CVF Winter Conf. Applications of Computer Vision (WACV), pages 574–584,
-
[10]
Hoang, and Bil- lie F
Vedhus Hoskere, Yasutaka Narazaki, Tu A. Hoang, and Bil- lie F. Spencer. MaDnet: Multi-task semantic segmentation of multiple types of structural materials and damage in im- ages of civil infrastructure.J. Civ. Struct. Health Monit., 10: 757–773, 2020. 2, 5
2020
-
[11]
Coordinate atten- tion for efficient mobile network design
Qibin Hou, Daquan Zhou, and Jiashi Feng. Coordinate atten- tion for efficient mobile network design. InProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), pages 13713–13722, 2021. 1, 2, 4
2021
-
[12]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco An- dreetto, and Hartmut Adam. Mobilenets: Efficient convolu- tional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017. 2
work page internal anchor Pith review arXiv 2017
-
[13]
Squeeze-and-excitation net- works
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net- works. InProc. IEEE/CVF Conf. Computer Vision and Pat- tern Recognition (CVPR), pages 7132–7141, 2018. 1, 2, 4
2018
-
[14]
UNet 3+: A full-scale connected UNet for medical image segmentation
Huimin Huang, Lanfen Lin, Ruofeng Tong, Hongjie Hu, Qiaowei Zhang, Yutaro Iwamoto, Xianhua Han, Yen-Wei Chen, and Jian Wu. UNet 3+: A full-scale connected UNet for medical image segmentation. InProc. IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP), pages 1055–1059, 2020. 5, 6, 7
2020
-
[15]
Batch normalization: Accelerating deep network training by reducing internal co- variate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal co- variate shift. InProc. Int. Conf. Machine Learning (ICML), pages 448–456, 2015. 3
2015
-
[16]
Panoptic feature pyramid net- works
Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Doll ´ar. Panoptic feature pyramid net- works. InProc. IEEE/CVF Conf. Computer Vision and Pat- tern Recognition (CVPR), pages 6399–6408, 2019. 1
2019
-
[17]
A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure.Adv
Christian Koch, Kristina Georgieva, Varun Kasireddy, Burcu Akinci, and Paul Fieguth. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure.Adv. Eng. Inform., 29(2):196– 210, 2015. 1, 2
2015
-
[18]
Machine learning applications in detecting sand boils from images.Array, 3:100012, 2019
Aditi Kuchi, Md Tamjidul Hoque, Mahdi Abdelguerfi, and Maik C Flanagin. Machine learning applications in detecting sand boils from images.Array, 3:100012, 2019. 1
2019
-
[19]
A machine learning ap- proach to detecting cracks in levees and floodwalls.Remote Sensing Applications: Society and Environment, 22:100513,
Aditi Kuchi, Manisha Panta, Md Tamjidul Hoque, Mahdi Abdelguerfi, and Maik C Flanagin. A machine learning ap- proach to detecting cracks in levees and floodwalls.Remote Sensing Applications: Society and Environment, 22:100513,
-
[20]
Deeply-supervised nets
Chi-Yeon Lee, Saining Xie, Patrick Gallagher, Zhengyou Zhang, and Zhuowen Tu. Deeply-supervised nets. InProc. Int. Conf. Artificial Intelligence and Statistics (AISTATS), pages 562–570, 2015. 5
2015
-
[21]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), pages 2117–2125, 2017. 1, 5, 6, 7
2017
-
[22]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InProc. IEEE Int. Conf. Computer Vision (ICCV), pages 2980–2988,
-
[23]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. InProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), pages 3431–3440, 2015. 1, 2
2015
-
[24]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProc. Int. Conf. Learning Representations (ICLR), 2019. 6
2019
-
[25]
Hammerla, Bernhard Kainz, Ben Glocker, and Daniel Rueckert
Ozan Oktay, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y . Hammerla, Bernhard Kainz, Ben Glocker, and Daniel Rueckert. Attention U-Net: Learning where to look for the pancreas. InProc. Int. Conf. Medical Imaging with Deep Learning (MIDL), 2018. 1, 2
2018
-
[26]
Iterlunet: deep learning architecture for pixel-wise crack detection in levee systems.IEEE Ac- cess, 11:12249–12262, 2023
Manisha Panta, Md Tamjidul Hoque, Mahdi Abdelguerfi, and Maik C Flanagin. Iterlunet: deep learning architecture for pixel-wise crack detection in levee systems.IEEE Ac- cess, 11:12249–12262, 2023. 1
2023
-
[27]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InProc. Int. Conf. Medical Image Computing and Computer- Assisted Intervention (MICCAI), pages 234–241. Springer,
-
[28]
EGE-UNet: An efficient group enhanced UNet for skin lesion segmentation
Jiacheng Ruan, Mingye Xie, Jingsheng Gao, Ting Liu, and Yuzhuo Fu. EGE-UNet: An efficient group enhanced UNet for skin lesion segmentation. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2023, pages 481–490. Springer Nature Switzerland, 2023. 5, 6, 7
2023
-
[29]
VM- UNet: Vision mamba UNet for medical image segmentation
Jiacheng Ruan, Jincheng Li, and Suncheng Xiang. VM- UNet: Vision mamba UNet for medical image segmentation. ACM Trans. Multimedia Comput. Commun. Appl., 2024. 5, 6, 7
2024
-
[30]
Attention gated networks: Learning to leverage salient re- gions in medical images.Med
Jo Schlemper, Ozan Oktay, Michiel Schaap, Mattias Hein- rich, Bernhard Kainz, Ben Glocker, and Daniel Rueckert. Attention gated networks: Learning to leverage salient re- gions in medical images.Med. Image Anal., 53:197–207,
-
[31]
Spencer, Vedhus Hoskere, and Yasutaka Narazaki
Billie F. Spencer, Vedhus Hoskere, and Yasutaka Narazaki. Advances in computer vision-based civil infrastructure in- spection and monitoring.Engineering, 5(2):199–222, 2019. 1
2019
-
[32]
Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M
Carole H. Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M. Jorge Cardoso. Generalised Dice overlap as a deep learning loss function for highly unbalanced segmen- tations. InProc. Int. Workshop on Deep Learning in Medical Image Analysis, pages 240–248. Springer, 2017. 5
2017
-
[33]
SA-UNet: Spatial attention u-net for retinal vessel seg- mentation.Pattern Recognit
Yicheng Sun, Ming Dai, Runbo Ji, Jiaying Li, and Yining Liu. SA-UNet: Spatial attention u-net for retinal vessel seg- mentation.Pattern Recognit. Lett., 159:135–141, 2022. 2, 5, 6, 7
2022
-
[34]
Army Corps of Engineers
U.S. Army Corps of Engineers. Culvert-sewer defect dataset (CSDD): Annotated inspection video frames follow- ing NASSCO PACP standards. Proprietary dataset. 6,300 frames from 580 inspection videos, 9 classes, 2024. 2, 5
2024
-
[35]
ECA-Net: Efficient channel attention for deep convolutional neural networks
Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wang- meng Zuo, and Qinghua Hu. ECA-Net: Efficient channel attention for deep convolutional neural networks. InProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), pages 11534–11542, 2020. 2
2020
-
[36]
CBAM: Convolutional block attention module
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. CBAM: Convolutional block attention module. In Proc. European Conf. Computer Vision (ECCV), pages 3–19. Springer, 2018. 1, 2
2018
-
[37]
Alvarez, and Ping Luo
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. SegFormer: Simple and efficient design for semantic segmentation with transformers. InProc. Advances in Neural Information Processing Systems (NeurIPS), 2021. 1, 5, 6, 7
2021
-
[38]
Ef- ficientSegNet: Lightweight semantic segmentation with multi-scale feature fusion and boundary enhancement.Sen- sors, 25(19):5934, 2025
Le Zhang, Mengwei Li, Peng Zhang, and Peng Liu. Ef- ficientSegNet: Lightweight semantic segmentation with multi-scale feature fusion and boundary enhancement.Sen- sors, 25(19):5934, 2025. 5, 6, 7
2025
-
[39]
HiViT: A simpler and more efficient design of hierarchical vision transformer
Xiaosong Zhang, Yunjie Tian, Lingxi Xie, Wei Huang, Qi Dai, Qixiang Ye, and Qi Tian. HiViT: A simpler and more efficient design of hierarchical vision transformer. InProc. Int. Conf. Learning Representations (ICLR), 2023. 5, 6, 7
2023
-
[40]
Pyramid scene parsing network
Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proc. IEEE/CVF Conf. Computer Vision and Pattern Recog- nition (CVPR), pages 2881–2890, 2017. 2
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.