Recognition: unknown
CHICO-Agent: An LLM Agent for the Cross-layer Optimization of 2.5D and 3D Chiplet-based Systems
Pith reviewed 2026-05-10 03:09 UTC · model grok-4.3
The pith
CHICO-Agent uses LLM multi-agents and a persistent knowledge base to find lower-cost chiplet designs than simulated annealing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
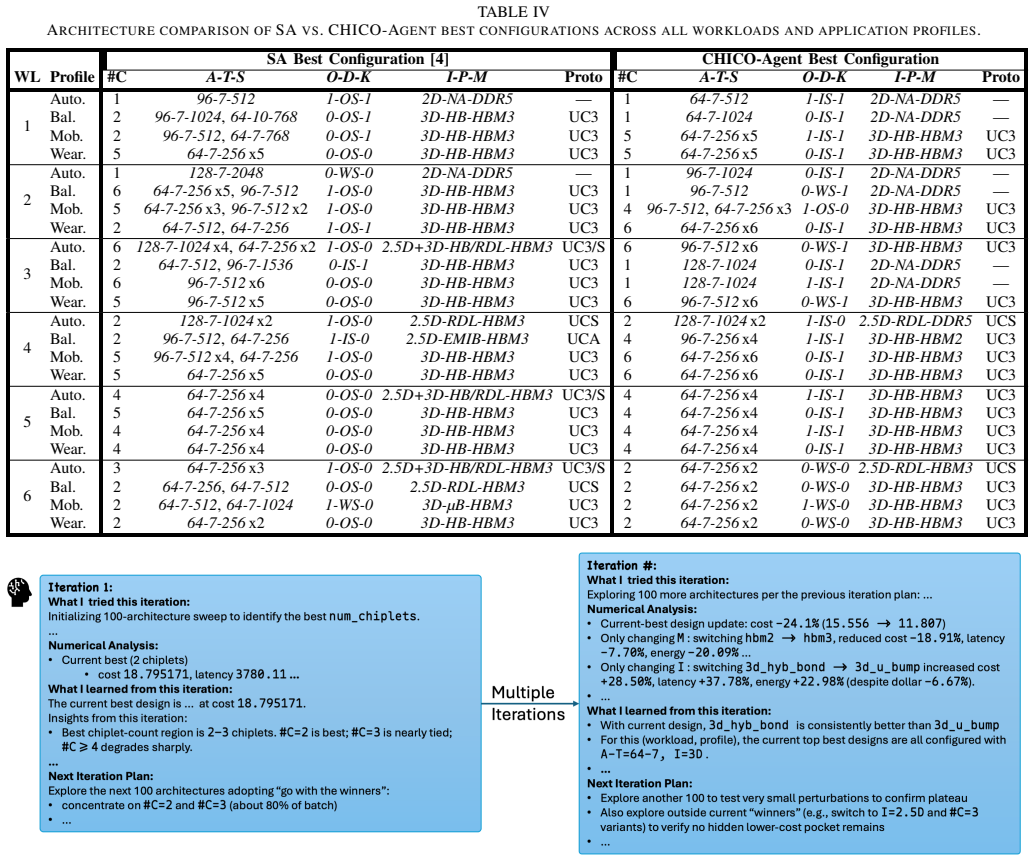
CHICO-Agent maintains a persistent knowledge base to capture parameter-outcome trends and coordinates exploration through an admin-field multi-agent workflow. This structure enables it to identify lower-cost configurations for cross-layer optimization of 2.5D and 3D chiplet-based systems than a simulated-annealing baseline while also generating an interpretable audit trail of decisions.
What carries the argument
The admin-field multi-agent workflow supported by a persistent knowledge base that records how design parameters map to latency, energy, area, and cost outcomes.
If this is right
- Designers obtain chiplet configurations that achieve lower total cost across the evaluated metrics.
- The optimization run produces a documented trail showing how specific parameter choices were selected.
- Exploration covers trade-offs among latency, energy, area, and cost without requiring exhaustive enumeration.
- The same workflow applies to both 2.5D and 3D chiplet integration approaches.
Where Pith is reading between the lines
- The accumulated knowledge base could allow designers to carry lessons from one chiplet project to related future projects.
- Adding agents that handle additional physical effects such as thermal or power-delivery constraints could extend the framework.
- Direct coupling to existing circuit simulators might tighten the accuracy of the recorded outcome trends.
Load-bearing premise
LLM agents can explore the large combinatorial space of chiplet designs while keeping accurate records of parameter trends and avoiding major biases or overlooked superior options.
What would settle it
Apply CHICO-Agent and the simulated-annealing baseline to a collection of chiplet benchmarks whose minimum achievable cost is already known from exhaustive search or expert analysis, then check whether the agent system consistently matches or beats the baseline cost without fabricating trends.
Figures



read the original abstract
The rapid growth of large language models (LLMs) and AI workloads has pushed monolithic silicon to its reticle and economic limits, accelerating the adoption of 2.5D/3D chiplet systems. However, these systems increase design complexity by requiring co-design across multiple levels of the computing stack, including application, architecture, chip, and package. The resulting design space is highly combinatorial, with trade-offs among latency, energy, area, and cost. To address this challenge, we propose CHICO-Agent, an LLM-driven optimization framework for 2.5D/3D chiplet-based systems. CHICO-Agent maintains a persistent knowledge base to capture parameter-outcome trends and coordinates exploration through an admin-field multi-agent workflow. Compared with a simulated-annealing baseline, CHICO-Agent finds lower-cost configurations and provides an interpretable audit trail for designers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CHICO-Agent, an LLM-driven multi-agent optimization framework for cross-layer co-design of 2.5D and 3D chiplet systems spanning application, architecture, chip, and package levels. It maintains a persistent knowledge base to record parameter-outcome trends and coordinates exploration via an admin-field multi-agent workflow. The central empirical claim is that CHICO-Agent identifies lower-cost configurations than a simulated-annealing baseline while supplying an interpretable audit trail for human designers.
Significance. If the empirical claims are substantiated, the work would address a pressing need in electronic design automation for AI accelerators, where chiplet systems create highly combinatorial, multi-objective spaces that strain conventional optimizers. The combination of LLM agents with a persistent trend-capturing knowledge base and built-in interpretability could reduce design iteration time and improve designer trust, representing a potentially useful direction for AI-assisted hardware design.
major comments (2)
- [Evaluation] The manuscript provides no quantitative results, benchmark workloads, design-space dimensions, cost model details, or implementation description of the simulated-annealing baseline. Without these, the claim that CHICO-Agent finds lower-cost configurations cannot be evaluated and is therefore load-bearing for the central contribution.
- [Methodology] No description is given of how the persistent knowledge base stores and retrieves parameter-outcome trends, how model biases are mitigated, or the precise admin-field multi-agent coordination protocol. These mechanisms are essential to assessing whether the framework reliably explores the combinatorial space without omission or systematic error.
minor comments (1)
- [Abstract] The abstract is concise but would benefit from a single sentence stating the scale of the design space explored or the number of chiplet configurations evaluated.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and constructive comments. We agree that additional details are necessary to substantiate the claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation] The manuscript provides no quantitative results, benchmark workloads, design-space dimensions, cost model details, or implementation description of the simulated-annealing baseline. Without these, the claim that CHICO-Agent finds lower-cost configurations cannot be evaluated and is therefore load-bearing for the central contribution.
Authors: We acknowledge this gap in the submitted manuscript. The revised version will include quantitative results from our experiments, specifying the benchmark workloads used (such as representative AI and HPC applications), the dimensions of the design space (e.g., number of chiplets, interconnect options, package configurations), the full cost model with equations for latency, energy, area, and monetary cost, and the implementation details of the simulated annealing baseline, including temperature schedule and acceptance criteria. We will present comparative data showing the cost improvements and the interpretability benefits. revision: yes
-
Referee: [Methodology] No description is given of how the persistent knowledge base stores and retrieves parameter-outcome trends, how model biases are mitigated, or the precise admin-field multi-agent coordination protocol. These mechanisms are essential to assessing whether the framework reliably explores the combinatorial space without omission or systematic error.
Authors: We will expand the methodology to address these points. The knowledge base will be described as maintaining a log of explored configurations and their outcomes, with retrieval via embedding-based similarity to recall relevant trends for the agents. Bias mitigation includes using temperature sampling, self-consistency checks across multiple LLM queries, and grounding outputs in the cost model simulator. The admin-field protocol will be specified with the division of labor among agents (e.g., one for exploration, one for evaluation, one for auditing) and the exact message passing and decision-making process coordinated by the admin agent. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes CHICO-Agent as an LLM-driven empirical optimization framework and reports experimental comparisons against a simulated-annealing baseline. No mathematical derivation chain, fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations appear in the abstract or described content. Claims rest on reported experimental outcomes rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
HISIM: Analytical Performance Modeling and Design Space Exploration of 2.5D/3D Integration for AI Computing,
Z. Wang,et al., “HISIM: Analytical Performance Modeling and Design Space Exploration of 2.5D/3D Integration for AI Computing,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025
2025
-
[2]
CATCH: A Cost Analysis Tool for Co-Optimization of Chiplet-Based Heterogeneous Systems,
A. Graening,et al., “CATCH: A Cost Analysis Tool for Co-Optimization of Chiplet-Based Heterogeneous Systems,” 2025. arXiv preprint arXiv:2503.15753
-
[3]
Chiplet-Gym: Optimizing Chiplet-Based AI Accelerator Design With Reinforcement Learning,
K. Mishty and M. Sadi, “Chiplet-Gym: Optimizing Chiplet-Based AI Accelerator Design With Reinforcement Learning,”IEEE Transactions on Computers, vol. 74, p. 43–56, Jan. 2025
2025
-
[4]
CarbonPATH: Carbon-Aware Pathfinding and Architecture Optimization for Chiplet-Based AI Systems,
C. C. Sudarshan,et al., “CarbonPATH: Carbon-Aware Pathfinding and Architecture Optimization for Chiplet-Based AI Systems,” 2026. arXiv preprint arXiv:2603.03878
-
[5]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao,et al., “React: Synergizing reasoning and acting in language models,” 2023. arXiv preprint arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
MAHL: Multi-Agent LLM-Guided Hierarchical Chiplet Design with Adaptive Debugging,
J. Tang,et al., “MAHL: Multi-Agent LLM-Guided Hierarchical Chiplet Design with Adaptive Debugging,” inProceedings of the IEEE/ACM International Conference on Computer-Aided Design, 2025
2025
-
[7]
3D-CIMlet: A Chiplet Co-Design Framework for Hetero- geneous In-Memory Acceleration of Edge LLM Inference and Continual Learning,
S. Du,et al., “3D-CIMlet: A Chiplet Co-Design Framework for Hetero- geneous In-Memory Acceleration of Edge LLM Inference and Continual Learning,” inProceedings of the ACM/IEEE Design Automation Con- ference, 2025
2025
-
[8]
M.-Y . Lee and S. Yu, “ChatNeuroSim: An LLM Agent Framework for Automated Compute-in-Memory Accelerator Deployment and Optimiza- tion,” 2026. arXiv preprint arXiv:2603.08745
-
[9]
CHICO-Agent
“CHICO-Agent.” https://anonymous.4open.science/r/ CHICO-Agent-08D4
-
[10]
Towards Self-Driving Codebases - Cursor,
W. Lin, “Towards Self-Driving Codebases - Cursor,” Feb 2026
2026
-
[11]
Particle Swarm Optimization,
J. Kennedy and R. Eberhart, “Particle Swarm Optimization,” inProceed- ings of ICNN’95 - International Conference on Neural Networks, vol. 4, pp. 1942–1948 vol.4, 1995
1942
-
[12]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei,et al., “Chain-of-thought prompting elicits reasoning in large language models,” inProceedings of the International Conference on Neural Information Processing Systems, 2022
2022
-
[13]
SCALE-Sim: Systolic CNN Accelerator Simulator
A. Samajdar,et al., “SCALE-Sim: Systolic CNN Accelerator Simulator,” arXiv preprint arXiv:1811.02883, 2018
work page Pith review arXiv 2018
-
[14]
‘Go with the Winners’ Algorithms,
D. Aldous and U. Vazirani, “‘Go with the Winners’ Algorithms,” in Proceedings of the Annual Symposium on Foundations of Computer Science, 1994
1994
-
[15]
GPT-5.3-Codex,
OpenAI, “GPT-5.3-Codex,” February 2026
2026
-
[16]
Evaluating Large Language Models Trained on Code,
M. Chen,et al., “Evaluating Large Language Models Trained on Code,”
-
[17]
arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.