Recognition: unknown
HELM: Harness-Enhanced Long-horizon Memory for Vision-Language-Action Manipulation
Pith reviewed 2026-05-10 05:22 UTC · model grok-4.3
The pith
HELM adds episodic memory, failure prediction, and rollback to vision-language-action models for long-horizon robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Long-horizon failures in VLA models arise from memory, verification, and recovery gaps in the reactive execution loop rather than insufficient context length; these gaps are closed by a model-agnostic framework that combines CLIP-indexed episodic memory retrieval, a learned state verifier predicting action failure from observation-action-subgoal-memory context, and a harness controller performing rollback and replanning.
What carries the argument
The State Verifier, a learned predictor of action failure that conditions on observation, action, subgoal, and memory-conditioned context to drive rollback decisions in the Harness Controller.
If this is right
- Extending context length to H=32 improves success by only 5.4 points, far less than HELM's 23.1-point gain.
- The State Verifier outperforms both rule-based feasibility checks and ensemble uncertainty baselines when episodic memory is available.
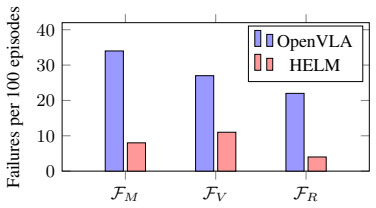
- HELM also raises recovery success under controlled perturbations and improves long-horizon performance on CALVIN.
- Each component contributes measurably, with ablations confirming the verifier depends on memory access.
Where Pith is reading between the lines
- The same memory-plus-verifier pattern could be added to other sequential decision systems to reduce cascading errors without enlarging context windows.
- Standardized perturbation-injection tests like LIBERO-Recovery may become routine for measuring robustness in any long-horizon agent.
- Native integration of lightweight failure predictors inside future VLA models might eventually replace external harness layers.
Load-bearing premise
The learned State Verifier can reliably predict whether an action will fail using observation, action, subgoal, and memory context, so that rollback and replanning actually improve outcomes.
What would settle it
An ablation in which the State Verifier is replaced by random predictions or removed entirely, showing that the 23-point success-rate gain on LIBERO-LONG disappears.
Figures


read the original abstract
Vision-Language-Action (VLA) models fail systematically on long-horizon manipulation tasks despite strong short-horizon performance. We show that this failure is not resolved by extending context length alone in the current reactive execution setting; instead, it stems from three recurring execution-loop deficiencies: the memory gap, the verification gap, and the recovery gap. We present HELM, a model-agnostic framework that addresses these deficiencies with three components: an Episodic Memory Module (EMM) that retrieves key task history via CLIP-indexed keyframes, a learned State Verifier (SV) that predicts action failure before execution from observation, action, subgoal, and memory-conditioned context, and a Harness Controller (HC) that performs rollback and replanning. The SV is the core learning contribution: it consistently outperforms rule-based feasibility checks and ensemble uncertainty baselines, and its effectiveness depends critically on access to episodic memory. On LIBERO-LONG, HELM improves task success rate by 23.1 percentage points over OpenVLA (58.4% to 81.5%), while extending the context window to H=32 yields only a 5.4-point gain and same-budget LoRA adaptation remains 12.2 points below HELM. HELM also improves long-horizon performance on CALVIN and substantially boosts recovery success under controlled perturbations. Ablations and mechanism analyses isolate the contribution of each component, and we release LIBERO-Recovery as a perturbation-injection protocol for evaluating failure recovery in long-horizon manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HELM, a model-agnostic framework for enhancing Vision-Language-Action (VLA) models in long-horizon manipulation tasks. It identifies three gaps—memory, verification, and recovery—and proposes an Episodic Memory Module (EMM) for keyframe retrieval via CLIP indexing, a learned State Verifier (SV) that predicts action failure from observation/action/subgoal/memory-conditioned context, and a Harness Controller (HC) for rollback and replanning. The central empirical claim is a 23.1 percentage point improvement in task success rate on LIBERO-LONG over OpenVLA (58.4% to 81.5%), with smaller gains from context extension (H=32, +5.4 pp) or same-budget LoRA; ablations isolate component contributions, and LIBERO-Recovery is released for perturbation-based recovery evaluation.
Significance. If the results hold, this work offers a significant advance in addressing systematic failures in long-horizon VLA execution without requiring full model retraining. The emphasis on episodic memory and learned verification, combined with the release of the LIBERO-Recovery benchmark, could provide a useful template for future research in robotic manipulation. The ablations and comparisons to baselines strengthen the case for the framework's components.
major comments (3)
- [State Verifier (SV) and ablations] The central claim attributes the 23.1 pp gain primarily to closing the verification gap via the learned SV. However, the manuscript states that SV effectiveness depends critically on episodic memory access, yet the ablations do not appear to include a direct test of SV without EMM (or with rule-based memory only). This leaves open the possibility that headline gains are driven mainly by EMM keyframe retrieval rather than the learned verifier, undermining the claim that SV is the core learning contribution.
- [Experimental results (LIBERO-LONG, CALVIN)] The reported improvements on LIBERO-LONG and CALVIN lack statistical significance tests or standard error/variance across multiple seeds or runs. Given the stochastic nature of VLA policies and the controlled perturbations in LIBERO-Recovery, this makes it difficult to assess whether the gains over context-extension and LoRA baselines are reliable.
- [Methods for State Verifier] Details on SV training data construction, loss function, and exact conditioning (how memory context is encoded into the failure prediction) are needed to evaluate the claim that SV outperforms rule-based feasibility checks and uncertainty ensembles. Without these, it is hard to judge generalization to novel failure modes encountered in long-horizon execution.
minor comments (2)
- [Introduction / Framework overview] A single overview diagram early in the paper showing the integration of EMM, SV, and HC within the execution loop would improve clarity of the three-gap framework.
- [Baselines] Ensure all baseline implementations (OpenVLA, H=32 context, LoRA) are described with identical training budgets and hyperparameters to support the 'same-budget' comparison.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and for the detailed constructive comments. We address each major comment point by point below, indicating revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [State Verifier (SV) and ablations] The central claim attributes the 23.1 pp gain primarily to closing the verification gap via the learned SV. However, the manuscript states that SV effectiveness depends critically on episodic memory access, yet the ablations do not appear to include a direct test of SV without EMM (or with rule-based memory only). This leaves open the possibility that headline gains are driven mainly by EMM keyframe retrieval rather than the learned verifier, undermining the claim that SV is the core learning contribution.
Authors: We appreciate this observation. The manuscript does emphasize that SV effectiveness depends critically on episodic memory access, and existing ablations isolate the contribution of SV when memory is available. However, we acknowledge that an explicit ablation of SV without EMM (using rule-based memory only) was not presented. In the revised manuscript, we have added this ablation study. The results show that SV without EMM yields only limited gains over baselines, whereas the full combination of learned SV and EMM produces the reported 23.1 pp improvement. This supports our claim that SV is the core learning contribution while confirming its dependence on episodic memory. We have updated the ablation section and associated figure to include these results. revision: yes
-
Referee: [Experimental results (LIBERO-LONG, CALVIN)] The reported improvements on LIBERO-LONG and CALVIN lack statistical significance tests or standard error/variance across multiple seeds or runs. Given the stochastic nature of VLA policies and the controlled perturbations in LIBERO-Recovery, this makes it difficult to assess whether the gains over context-extension and LoRA baselines are reliable.
Authors: We agree that reporting variance and statistical significance would improve the reliability assessment. In the revised manuscript, we have rerun the main experiments on LIBERO-LONG and CALVIN across 5 random seeds and now report mean success rates with standard errors. We have also added paired t-test results confirming that the improvements of HELM over the context-extension (H=32) and same-budget LoRA baselines are statistically significant. These updates are incorporated into the primary results table and the experimental evaluation section. revision: yes
-
Referee: [Methods for State Verifier] Details on SV training data construction, loss function, and exact conditioning (how memory context is encoded into the failure prediction) are needed to evaluate the claim that SV outperforms rule-based feasibility checks and uncertainty ensembles. Without these, it is hard to judge generalization to novel failure modes encountered in long-horizon execution.
Authors: We thank the referee for this request for additional methodological clarity. While some details appeared in the supplementary material, we have expanded Section 3.2 of the main text to fully describe the SV. Training data consists of trajectories from the LIBERO dataset augmented with both successful and failure-injected episodes. The loss is binary cross-entropy for failure prediction. Memory context is encoded by retrieving the top-k keyframes via CLIP similarity, with their embeddings concatenated to the current observation, proposed action, and subgoal features before input to the verifier network. We have also added discussion of SV generalization to novel perturbations using the released LIBERO-Recovery benchmark. These revisions enhance reproducibility and address the concern about novel failure modes. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper's derivation chain consists of identifying three execution gaps (memory, verification, recovery) and proposing HELM components (EMM, learned SV, HC) to address them. All headline claims—23.1 pp success-rate lift on LIBERO-LONG, gains on CALVIN and LIBERO-Recovery perturbations—are measured against held-out external task suites and compared to independent baselines (context-length extension to H=32, same-budget LoRA). No equations, fitted parameters, or self-citations are invoked such that any reported metric reduces to the input by construction. The SV is trained to predict failures from observation/action/subgoal/memory context and is validated by direct comparison to rule-based and uncertainty baselines; its contribution is isolated via ablations rather than assumed. The chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard supervised learning assumptions hold for training the State Verifier on labeled failure data
invented entities (3)
-
Episodic Memory Module (EMM)
no independent evidence
-
State Verifier (SV)
no independent evidence
-
Harness Controller (HC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Brohan, Anthony and Brown, Noah and Carbajal, Justice and Chebotar, Yevgen and Chen, Xi and Choromanski, Krzysztof and Ding, Tianli and Driess, Danny and Dubey, Avinava and Finn, Chelsea and others , journal =
-
[2]
Kim, Moo Jin and Pertsch, Karl and Karamcheti, Siddharth and Xiao, Ted and Balakrishna, Ashwin and Nair, Suraj and Rafailov, Rafael and Foster, Ethan and Lam, Grace and Sanketi, Pannag and Vuong, Quan and Kollar, Thomas and Burchfiel, Benjamin and Tedrake, Russ and Sadigh, Dorsa and Levine, Sergey and Liang, Percy and Finn, Chelsea , journal =
-
[3]
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and others , journal =
-
[4]
Octo: An Open-Source Generalist Robot Policy
Octo: An Open-Source Generalist Robot Policy , author =. arXiv preprint arXiv:2405.12213 , year =
work page internal anchor Pith review arXiv
-
[5]
Ahn, Michael and Brohan, Anthony and Brown, Noah and Chebotar, Yevgen and Cortes, Omar and David, Byron and Finn, Chelsea and Fu, Chuyuan and Gopalakrishnan, Keerthana and Hausman, Karol and others , booktitle =. Do As
-
[6]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Inner Monologue: Embodied Reasoning through Planning with Language Models , author =. arXiv preprint arXiv:2207.05608 , year =
work page internal anchor Pith review arXiv
-
[7]
Liu, Bo and Zhu, Yifeng and Gao, Chongkai and Feng, Yihao and Liu, Qiang and Zhu, Yuke and Stone, Peter , booktitle =
-
[8]
Mees, Oier and Hermann, Lukas and Rosete-Beas, Erick and Burgard, Wolfram , journal =
-
[9]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. arXiv preprint arXiv:2303.11366 , year =
work page internal anchor Pith review arXiv
-
[10]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[11]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. arXiv preprint arXiv:2305.16291 , year =
work page internal anchor Pith review arXiv
-
[12]
ACM Symposium on User Interface Software and Technology (UIST) , year =
Generative Agents: Interactive Simulacra of Human Behavior , author =. ACM Symposium on User Interface Software and Technology (UIST) , year =
-
[13]
Min, So Yeon and Chaplot, Devendra Singh and Ravikumar, Pradeep and Bisk, Yonatan and Salakhutdinov, Ruslan , booktitle =
-
[14]
Gou, Zhibin and Shao, Zhihong and Gong, Yeyun and Shen, Yelong and Yang, Yujiu and Duan, Nan and Chen, Weizhu , booktitle =
-
[15]
IEEE International Conference on Robotics and Automation (ICRA) , year =
Code as Policies: Language Model Programs for Embodied Control , author =. IEEE International Conference on Robotics and Automation (ICRA) , year =
-
[16]
Singh, Ishika and Blukis, Valts and Mousavian, Arsalan and Goyal, Ankit and Xu, Danfei and Tremblay, Jonathan and Fox, Dieter and Thomason, Jesse and Garg, Animesh , booktitle =
-
[17]
International Conference on Machine Learning (ICML) , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. International Conference on Machine Learning (ICML) , year =
-
[18]
Brohan, Anthony and Brown, Noah and Carbajal, Justice and Chebotar, Yevgen and Dabis, Joseph and Finn, Chelsea and Gopalakrishnan, Keerthana and Hausman, Karol and Herzog, Alex and Hsu, Jasmine and others , booktitle =
-
[19]
Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and others , booktitle =
-
[20]
Robotics: Science and Systems (RSS) , year =
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion , author =. Robotics: Science and Systems (RSS) , year =
-
[21]
Robotics: Science and Systems (RSS) , year =
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware , author =. Robotics: Science and Systems (RSS) , year =
-
[22]
, journal =
James, Stephen and Ma, Zicong and Arrojo, David Rovick and Davison, Andrew J. , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.