Recognition: unknown
AI scientists produce results without reasoning scientifically
Pith reviewed 2026-05-10 03:51 UTC · model grok-4.3
The pith
Current LLM-based agents execute scientific workflows but do not exhibit the epistemic patterns that characterize scientific reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
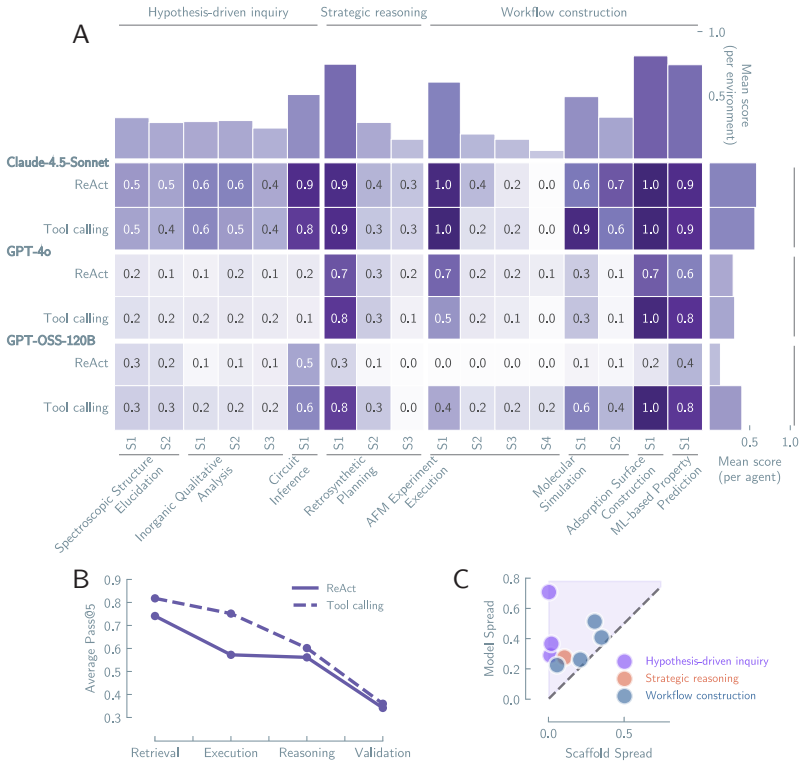
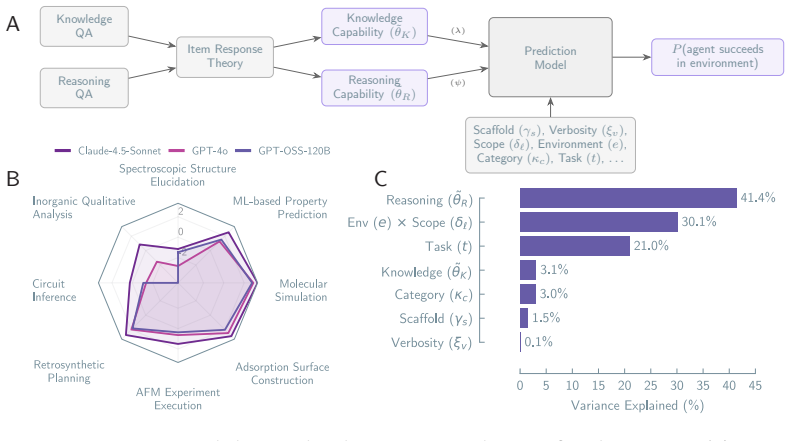
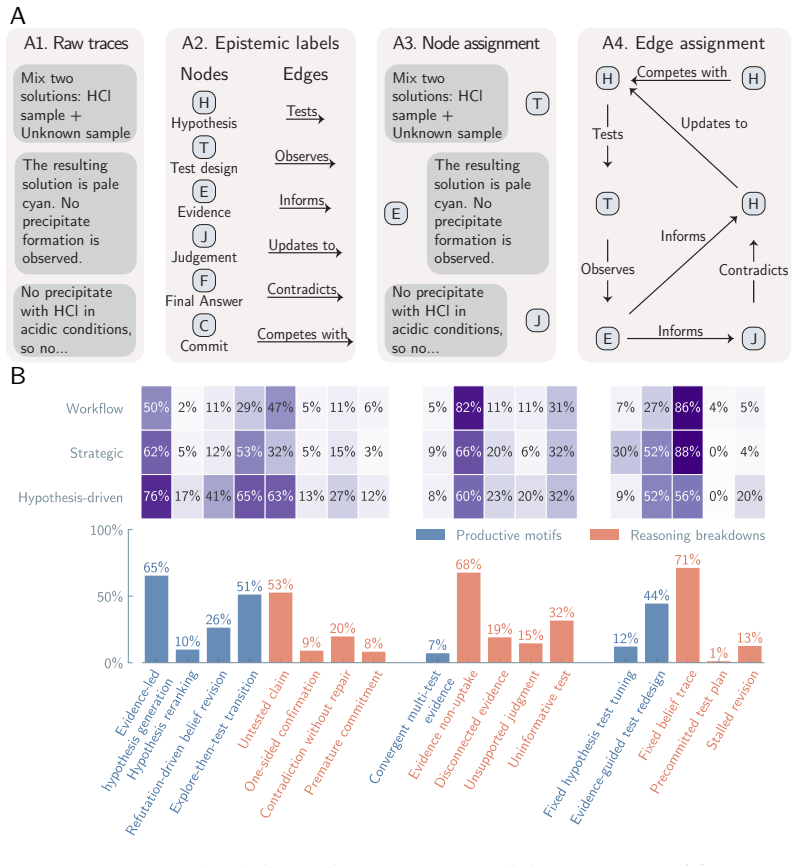
LLM-based agents execute scientific workflows but do not exhibit the epistemic patterns that characterize scientific reasoning. Evidence is ignored in 68 percent of traces, refutation-driven belief revision occurs in 26 percent, and convergent multi-test evidence is rare. The same patterns appear in both computational workflow execution and hypothesis-driven inquiry. The base model is the primary determinant, explaining 41.4 percent of variance versus 1.5 percent for the scaffold. These issues persist even with near-complete successful trajectories provided as context, and unreliability compounds across trials.
What carries the argument
Behavioral analysis of agent reasoning traces using metrics that track evidence ignoring, refutation-driven belief revision, and convergent multi-test evidence, combined with variance decomposition between base model and scaffold.
Load-bearing premise
The custom behavioral metrics accurately measure whether agent traces follow scientific epistemic norms across the tested domains.
What would settle it
An experiment in which agents in hypothesis-driven tasks routinely seek disconfirming evidence from multiple independent tests and update their beliefs accordingly at rates that match documented scientific practice.
Figures


read the original abstract
Large language model (LLM)-based systems are increasingly deployed to conduct scientific research autonomously, yet whether their reasoning adheres to the epistemic norms that make scientific inquiry self-correcting is poorly understood. Here, we evaluate LLM-based scientific agents across eight domains, spanning workflow execution to hypothesis-driven inquiry, through more than 25,000 agent runs and two complementary lenses: (i) a systematic performance analysis that decomposes the contributions of the base model and the agent scaffold, and (ii) a behavioral analysis of the epistemological structure of agent reasoning. We observe that the base model is the primary determinant of both performance and behavior, accounting for 41.4% of explained variance versus 1.5% for the scaffold. Across all configurations, evidence is ignored in 68% of traces, refutation-driven belief revision occurs in 26%, and convergent multi-test evidence is rare. The same reasoning pattern appears whether the agent executes a computational workflow or conducts hypothesis-driven inquiry. They persist even when agents receive near-complete successful reasoning trajectories as context, and the resulting unreliability compounds across repeated trials in epistemically demanding domains. Thus, current LLM-based agents execute scientific workflows but do not exhibit the epistemic patterns that characterize scientific reasoning. Outcome-based evaluation cannot detect these failures, and scaffold engineering alone cannot repair them. Until reasoning itself becomes a training target, the scientific knowledge produced by such agents cannot be justified by the process that generated it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates LLM-based scientific agents across eight domains via >25,000 runs. It decomposes performance and behavior into base-model versus scaffold contributions (41.4% vs 1.5% explained variance) and applies custom behavioral metrics showing evidence ignored in 68% of traces, refutation-driven revision in 26%, and rare convergent multi-test evidence. The central claim is that agents execute workflows but lack the epistemic patterns of scientific reasoning; outcome-based evaluation is blind to these failures and scaffold engineering cannot fix them.
Significance. If the behavioral findings are robust, the work supplies large-scale empirical evidence that current LLM agents fall short of self-correcting scientific norms even when they produce correct outputs. This directly challenges reliance on outcome metrics for AI-driven science and identifies a training-target gap that scaffold improvements alone will not close. The scale of the trace analysis and the model-versus-scaffold variance split are notable strengths.
major comments (3)
- [Behavioral trace analysis] Behavioral analysis section: the headline percentages (evidence ignored 68%, refutation-driven revision 26%, convergent evidence rare) rest on custom operational definitions whose validity and reliability are not demonstrated. No inter-annotator agreement, no correlation with expert scientist ratings of the same traces, and no comparison to established epistemic-cognition instruments are reported. Because these metrics drive both the variance decomposition and the claim that outcome evaluation is blind to epistemic failure, their unvalidated status is load-bearing.
- [Performance analysis] Performance decomposition: the reported 41.4% base-model versus 1.5% scaffold explained variance requires explicit specification of the statistical model (regression, ANOVA, or mixed-effects), the exact predictors, and any controls for domain or task difficulty. Without these details it is unclear whether the attribution is robust or sensitive to post-hoc modeling choices.
- [Context-augmented runs] Context-injection experiment: the claim that epistemic patterns persist even when agents receive near-complete successful reasoning trajectories as context is central to the conclusion that scaffolds cannot repair the deficit. The manuscript must clarify how those trajectories were selected, verified as successful, and presented, and whether any filtering or post-selection occurred.
minor comments (2)
- [Abstract and Methods] The abstract states 'more than 25,000 agent runs' and 'eight domains'; the methods section should give the exact counts and list the domains explicitly for reproducibility.
- [Methods] Notation for the behavioral metrics (e.g., how 'evidence ignored' is coded from traces) should be defined once in a dedicated subsection rather than scattered across results paragraphs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate revisions made to the manuscript.
read point-by-point responses
-
Referee: [Behavioral trace analysis] Behavioral analysis section: the headline percentages (evidence ignored 68%, refutation-driven revision 26%, convergent evidence rare) rest on custom operational definitions whose validity and reliability are not demonstrated. No inter-annotator agreement, no correlation with expert scientist ratings of the same traces, and no comparison to established epistemic-cognition instruments are reported. Because these metrics drive both the variance decomposition and the claim that outcome evaluation is blind to epistemic failure, their unvalidated status is load-bearing.
Authors: We agree that the metrics are custom operationalizations and that formal validation was not reported in the original submission. The definitions were derived directly from standard epistemic norms (consideration of evidence and belief revision upon refutation) and implemented via rule-based detection on traces for scalability. In the revised manuscript we have expanded the Methods section with explicit decision criteria, pseudocode, and multiple example traces for each category. We have also added a limitation paragraph noting the absence of full inter-annotator agreement across the entire corpus and have included a pilot validation on a random subsample of 200 traces rated by two independent experts (Cohen’s κ = 0.79 for evidence ignoring; κ = 0.71 for revision), which we report in the supplement. We view this as a partial but substantive improvement given the scale of the study. revision: partial
-
Referee: [Performance analysis] Performance decomposition: the reported 41.4% base-model versus 1.5% scaffold explained variance requires explicit specification of the statistical model (regression, ANOVA, or mixed-effects), the exact predictors, and any controls for domain or task difficulty. Without these details it is unclear whether the attribution is robust or sensitive to post-hoc modeling choices.
Authors: We thank the referee for highlighting the need for statistical transparency. The decomposition was obtained from a linear mixed-effects model with base model and scaffold as fixed effects and domain plus task difficulty (operationalized as mean human accuracy on the same tasks) as random intercepts. Variance components were extracted via the lme4 package and the reported percentages are the marginal R² contributions of each fixed effect. The revised Methods section now contains the full model formula, convergence diagnostics, and a sensitivity table comparing results with and without the random effects; the relative contributions remain stable under these alternatives. revision: yes
-
Referee: [Context-augmented runs] Context-injection experiment: the claim that epistemic patterns persist even when agents receive near-complete successful reasoning trajectories as context is central to the conclusion that scaffolds cannot repair the deficit. The manuscript must clarify how those trajectories were selected, verified as successful, and presented, and whether any filtering or post-selection occurred.
Authors: We agree that the selection procedure required clarification. Successful trajectories were drawn from an initial pool of 500 runs per domain; a trajectory qualified if the final answer matched ground truth and the trace contained all required reasoning steps (verified by automated string and entailment matching against reference solutions). No further manual filtering or cherry-picking occurred. The revised manuscript adds a dedicated subsection detailing these criteria, the exact prompt template used for injection, and the number of qualifying trajectories per domain. The epistemic failure rates in the augmented condition remain statistically indistinguishable from the baseline, supporting the original claim. revision: yes
Circularity Check
No circularity: empirical measurements with no derivational reduction
full rationale
The paper is an empirical study reporting direct observations from >25,000 agent traces: performance variance decomposition (base model 41.4% vs scaffold 1.5%), evidence ignored in 68% of traces, refutation-driven revision in 26%, and rarity of convergent multi-test evidence. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text or abstract. The central claim follows from the reported behavioral counts and variance analysis without any step that reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Defined behavioral categories (evidence ignored, refutation-driven belief revision) accurately reflect scientific epistemic norms
Forward citations
Cited by 1 Pith paper
-
Heterogeneous Scientific Foundation Model Collaboration
Eywa enables language-based agentic AI systems to collaborate with specialized scientific foundation models for improved performance on structured data tasks.
Reference graph
Works this paper leans on
-
[1]
Mirza, A.et al.A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists.Nature Chemistry 17,1027–1034 (2025)
2025
-
[2]
Alampara, N.et al.Probing the limitations of multimodal language models for chemistry and materials research.Nature Computational Science5,952–961 (2025)
2025
-
[3]
Laurent, J. M.et al.Lab-bench: Measuring capabilities of language models for biology research.arXiv preprint arXiv:2407.10362(2024)
- [4]
- [5]
- [6]
-
[7]
& Jablonka, K
Alampara, N., Schilling-Wilhelmi, M. & Jablonka, K. M. Lessons from the trenches on evaluating machine learning systems in materials science.Computational Materials Science259,114041 (2025)
2025
- [8]
-
[9]
Liu, Y.et al.Researchbench: Benchmarking llms in scientific discovery via inspiration- based task decomposition.arXiv preprint arXiv:2503.21248(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Du, M., Xu, B., Zhu, C., Wang, X. & Mao, Z. Deepresearch bench: A comprehensive benchmark for deep research agents.arXiv preprint arXiv:2506.11763(2025)
-
[11]
Bragg, J.et al.Astabench: Rigorous benchmarking of ai agents with a scientific research suite.arXiv preprint arXiv:2510.21652(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
Liu, X.et al.Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688 (2023)
work page internal anchor Pith review arXiv 2023
-
[14]
& Scialom, T.Gaia: a benchmark for general ai assistantsinThe Twelfth International Conference on Learning Representations(2023)
Mialon, G., Fourrier, C., Wolf, T., LeCun, Y. & Scialom, T.Gaia: a benchmark for general ai assistantsinThe Twelfth International Conference on Learning Representations(2023)
2023
- [15]
- [16]
-
[17]
Lu, J.et al. Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilitiesinFindings of the Association for Computational Linguistics: NAACL 2025(2025), 1160–1183
2025
-
[18]
On the Measure of Intelligence
Chollet, F. On the Measure of Intelligence.arXiv preprint arXiv:1911.01547(2019)
work page internal anchor Pith review arXiv 1911
-
[19]
Lu, C.et al.Towards end-to-end automation of AI research.Nature651,914–919 (2026)
2026
- [20]
-
[21]
Bran, A.et al.Augmenting large language models with chemistry tools.Nature Machine Intelligence6,525–535 (2024)
M. Bran, A.et al.Augmenting large language models with chemistry tools.Nature Machine Intelligence6,525–535 (2024)
2024
-
[22]
A., MacKnight, R., Kline, B
Boiko, D. A., MacKnight, R., Kline, B. & Gomes, G. Autonomous chemical research with large language models.Nature624,570–578 (2023)
2023
-
[23]
Zou, Y.et al.El Agente: An autonomous agent for quantum chemistry.Matter8(2025)
2025
-
[24]
Darvish, K.et al.ORGANA: A robotic assistant for automated chemistry experimenta- tion and characterization.Matter8,101897 (2025)
2025
-
[25]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, A.et al.AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131(2025)
work page internal anchor Pith review arXiv 2025
-
[26]
& Buehler, M
Ghafarollahi, A. & Buehler, M. J. SciAgents: automating scientific discovery through bioinspired multi-agent intelligent graph reasoning.Advanced Materials37,2413523 (2025)
2025
-
[27]
Wang, F. Y.et al.Autonomous Agents Coordinating Distributed Discovery Through Emergent Artifact Exchange.arXiv preprint arXiv:2603.14312(2026)
-
[28]
L., Pak, J
Swanson, K., Wu, W., Bulaong, N. L., Pak, J. E. & Zou, J. The Virtual Lab of AI agents designs new SARS-CoV-2 nanobodies.Nature646,716–723 (2025)
2025
-
[29]
& Buehler, M
Ghafarollahi, A. & Buehler, M. J. ProtAgents: protein discovery via large language model multi-agent collaborations combining physics and machine learning.Digital Discovery3,1389–1409 (2024)
2024
-
[30]
& Buehler, M
Ni, B. & Buehler, M. J. MechAgents: Large language model multi-agent collaborations can solve mechanics problems, generate new data, and integrate knowledge.Extreme Mechanics Letters67,102131 (2024)
2024
-
[31]
Du, Y.et al.Accelerating Scientific Discovery with Autonomous Goal-evolving Agents. arXiv preprint arXiv:2512.21782(2025)
-
[32]
Buehler, M. J. PRefLexOR: preference-based recursive language modeling for ex- ploratory optimization of reasoning and agentic thinking.npj Artificial Intelligence1,4 (2025)
2025
-
[33]
Tang, X.et al.Risks of AI scientists: prioritizing safeguarding over autonomy.Nature Communications16(2025). 106
2025
-
[34]
Ma, Z.et al.SkillClaw: Let Skills Evolve Collectively with Agentic Evolver.arXiv preprint arXiv:2604.08377(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Advances in neural information processing systems35,24824–24837 (2022)
Wei, J.et al.Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35,24824–24837 (2022)
2022
-
[36]
React: Synergizing reasoning and acting in language modelsinThe eleventh international conference on learning representations(2022)
Yao, S.et al. React: Synergizing reasoning and acting in language modelsinThe eleventh international conference on learning representations(2022)
2022
-
[37]
Wang, X.et al.Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171(2022)
work page internal anchor Pith review arXiv 2022
-
[38]
Schick, T.et al.Toolformer: Language models can teach themselves to use tools.Ad- vances in Neural Information Processing Systems36,68539–68551 (2023)
2023
-
[39]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G.et al.Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review arXiv 2023
-
[40]
Shinn, N.et al.Reflexion: Language Agents with Verbal Reinforcement Learning.arXiv preprint arXiv:2303.11366(2023)
work page internal anchor Pith review arXiv 2023
-
[41]
& Allen, C.The Influence of Scaffolds on Coordination Scaling Laws in LLM AgentsinWorkshop on Scaling Environments for Agents()
Meireles, M., Bhati, R., Lauffer, N. & Allen, C.The Influence of Scaffolds on Coordination Scaling Laws in LLM AgentsinWorkshop on Scaling Environments for Agents()
-
[42]
& Yamada, T
Hori, K., Fukuhara, H. & Yamada, T. Item response theory and its applications in educational measurement Part I: Item response theory and its implementation in R. Wiley Interdisciplinary Reviews: Computational Statistics14,e1531 (2022)
2022
-
[43]
Toland, M. D. Practical guide to conducting an item response theory analysis.The Journal of Early Adolescence34,120–151 (2014)
2014
-
[44]
& Brickman, P
Lovelace, M. & Brickman, P. Best practices for measuring students’ attitudes toward learning science.CBE—Life Sciences Education12,606–617 (2013)
2013
-
[45]
P., Wu, H
Lalor, J. P., Wu, H. & Yu, H.Building an evaluation scale using item response theoryin Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (2016), 648–657
2016
-
[46]
P., Wu, H., Munkhdalai, T
Lalor, J. P., Wu, H., Munkhdalai, T. & Yu, H.Understanding deep learning performance through an examination of test set difficulty: A psychometric case studyinProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing(2018), 4711–4716
2018
-
[47]
Rodriguez, P.et al. Evaluation examples are not equally informative: How should that change NLP leaderboards?inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)(2021), 4486–4503
2021
-
[48]
& Jablonka, K
Schilling-Wilhelmi, M., Alampara, N. & Jablonka, K. M.Lifting the benchmark iceberg with item-response theoryinAI for Accelerated Materials Design-ICLR 2025(2025). 107
2025
-
[49]
Lost in benchmarks? rethinking large language model benchmarking with item response theoryinProceedings of the AAAI Conference on Artificial Intelligence40 (2026), 35085–35093
Zhou, H.et al. Lost in benchmarks? rethinking large language model benchmarking with item response theoryinProceedings of the AAAI Conference on Artificial Intelligence40 (2026), 35085–35093
2026
-
[50]
Efficient benchmarking of AI agents
Ndzomga, F. Efficient Benchmarking of AI Agents.arXiv preprint arXiv:2603.23749 (2026)
-
[51]
P., Fanelli, D., Dunne, D
Ioannidis, J. P., Fanelli, D., Dunne, D. D. & Goodman, S. N. Meta-research: evaluation and improvement of research methods and practices.PLoS biology13,e1002264 (2015)
2015
-
[52]
& Evans, J
Hao, Q., Xu, F., Li, Y. & Evans, J. Artificial intelligence tools expand scientists’ impact but contract science’s focus.Nature,1–7 (2026)
2026
-
[53]
Mitchell, M. & Krakauer, D. C. The debate over understanding in AI’s large language models.Proceedings of the National Academy of Sciences120. http://dx.doi.org/ 10.1073/pnas.2215907120(2023)
-
[54]
https://philsci-archive.pitt.edu/28744/(2026)
Thais, S.et al.AI for Science Needs Scientific Alignment.Philsci Archive preprint. https://philsci-archive.pitt.edu/28744/(2026)
2026
-
[55]
& Steup, M
Ichikawa, J. & Steup, M. inThe Stanford Encyclopedia of Philosophy(eds Zalta, E. N. & Nodelman, U.) Spring 2026 (Metaphysics Research Lab, Stanford University, 2026)
2026
-
[56]
Popper, K.The logic of scientific discovery(Routledge, 2005)
2005
-
[57]
Tukey, J. W.et al. Exploratory data analysis(Springer, 1977)
1977
-
[58]
Lindley, D. V. On a measure of the information provided by an experiment.The Annals of Mathematical Statistics27,986–1005 (1956)
1956
-
[59]
V.Theory of optimal experiments(Elsevier, 2013)
Fedorov, V. V.Theory of optimal experiments(Elsevier, 2013)
2013
-
[60]
Priem, J., Piwowar, H. & Orr, R.OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts2022. arXiv: 2205.01833 [cs.DL]. https://arxiv. org/abs/2205.01833
-
[61]
Product page, accessed 2026-04-19
Nanosurf.DriveAFM: Tip-Scanning AFM System https://www.nanosurf.com/en/ products/driveafm. Product page, accessed 2026-04-19
2026
-
[62]
Jain, A.et al.Commentary: The Materials Project: A materials genome approach to accelerating materials innovation.APL materials1(2013)
2013
-
[63]
Kannas, C., Thakkar, A., Bjerrum, E. & Genheden, S. rxnutils – A Cheminformatics Python Library for Manipulating Chemical Reaction Data.chemrxiv preprint 10.26434/chemrxiv- 2022-wt440-v2.http://dx.doi.org/10.26434/chemrxiv-2022-wt440-v2(2022)
-
[64]
Binev, Y., Marques, M. M. B. & Aires-de-Sousa, J. Prediction of 1H NMR Coupling Constants with Associative Neural Networks Trained for Chemical Shifts.Journal of Chemical Information and Modeling47,2089–2097 (2007)
2089
-
[65]
& Patiny, L
Banfi, D. & Patiny, L. www.nmrdb.org: Resurrecting and Processing NMR Spectra On-line.CHIMIA62,280 (2008). 108
2008
-
[66]
M., Patiny, L
Jablonka, K. M., Patiny, L. & Smit, B. Making Molecules Vibrate: Interactive Web Environment for the Teaching of Infrared Spectroscopy.Journal of Chemical Education 99,561–569 (2022)
2022
-
[67]
Leal, A. M. M.Reaktoro: An open-source unified framework for modeling chemically reactive systemshttps://reaktoro.org. Accessed: 2026-04-19. 2015
2026
-
[68]
corral-QAs (Revision bb74c25)2026
Alampara, N.et al. corral-QAs (Revision bb74c25)2026. https://huggingface.co/ datasets/jablonkagroup/corral-QAs
2026
-
[69]
& Gabry, J
Vehtari, A., Gelman, A. & Gabry, J. Practical Bayesian model evaluation using leave- one-out cross-validation and WAIC.Statistics and computing27,1413–1432 (2017)
2017
-
[70]
Salvatier, J., Wiecki, T. V. & Fonnesbeck, C. Probabilistic programming in Python using PyMC3.PeerJ Computer Science2,e55 (2016)
2016
-
[71]
& Martín, O
Kumar, R., Carroll, C., Hartikainen, A. & Martín, O. A. ArviZ a unified library for exploratory analysis of Bayesian models in Python (2019). 109
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.