Recognition: unknown
Rethinking Dataset Distillation: Hard Truths about Soft Labels
Pith reviewed 2026-05-10 05:08 UTC · model grok-4.3
The pith
Soft labels allow random image subsets to match sophisticated dataset distillation methods during model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
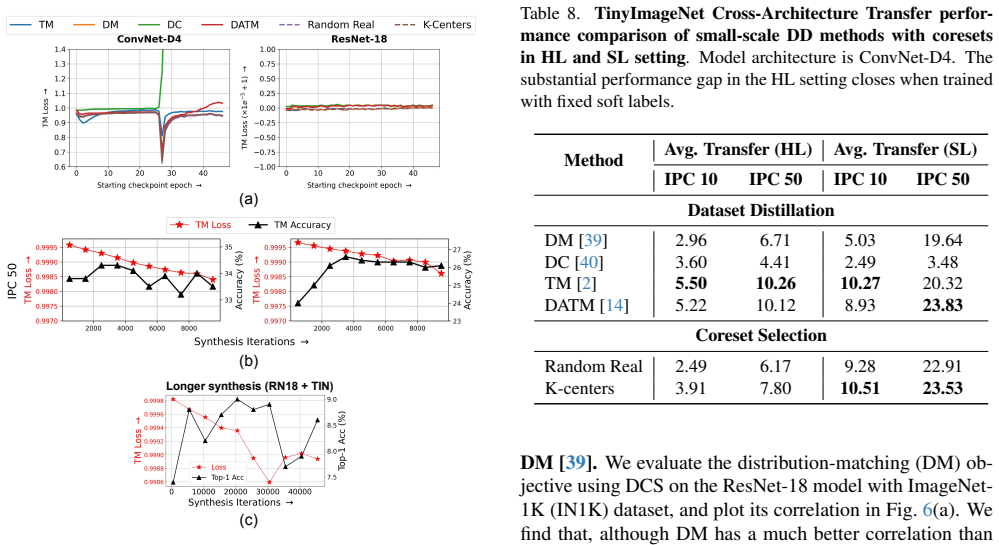
High-quality coresets fail to outperform random baselines in soft-label regimes, and performance saturates regardless of subset in the soft-label-plus-knowledge-distillation case. In the hard-label setting on ImageNet-1K, only RDED among evaluated methods beats random but lags behind strong coresets due to over-reliance on easy patches. This motivates CAD-Prune, a compute-aware metric for selecting optimal-difficulty samples, which is used to create CA2D that outperforms prior dataset distillation methods at various images-per-class settings.
What carries the argument
CAD-Prune, a compute-aware pruning metric that efficiently identifies samples of optimal difficulty for a given compute budget, forming the basis for the CA2D dataset distillation method.
If this is right
- High-quality coresets do not convincingly outperform random baselines in soft-label and soft-label-plus-KD regimes.
- Model performance approaches near-optimal levels relative to the full dataset in the SL+KD setting, independent of subset size or quality for a fixed compute budget.
- Only RDED reliably outperforms random baselines among five large-scale DD methods on ImageNet-1K in the hard-label setting.
- CA2D, built with CAD-Prune, outperforms current dataset distillation methods on ImageNet-1K across different IPC settings.
Where Pith is reading between the lines
- This implies that dataset distillation research should shift focus to hard-label evaluations to avoid misleading results from soft-label saturation.
- The compute-aware selection principle could be tested for improving coreset construction in data-efficient learning scenarios.
Load-bearing premise
The observed performance saturation with soft labels and the superiority of CAD-Prune are assumed to hold under the fixed compute budgets and specific model architectures tested, without variation in training protocols or larger scales.
What would settle it
A re-evaluation in the hard-label setting on ImageNet-1K where CA2D fails to achieve higher accuracy than RDED or strong coreset methods at multiple IPC values would disprove the advantage of the proposed approach.
Figures












read the original abstract
Despite the perceived success of large-scale dataset distillation (DD) methods, recent evidence finds that simple random image baselines perform on-par with state-of-theart DD methods like SRe2L due to the use of soft labels during downstream model training. This is in contrast with the findings in coreset literature, where high-quality coresets consistently outperform random subsets in the hardlabel (HL) setting. To understand this discrepancy, we perform a detailed scalability analysis to examine the role of data quality under different label regimes, ranging from abundant soft labels (termed as SL+KD regime) to fixed soft labels (SL) and hard labels (HL). Our analysis reveals that high-quality coresets fail to convincingly outperform the random baseline in both SL and SL+KD regimes. In the SL+KD setting, performance further approaches nearoptimal levels relative to the full dataset, regardless of subset size or quality, for a given compute budget. This performance saturation calls into question the widespread practice of using soft labels for model evaluation, where unlike the HL setting, subset quality has negligible influence. A subsequent systematic evaluation of five large-scale and four small-scale DD methods in the HL setting reveals that only RDED reliably outperforms random baselines on ImageNet-1K, but can still lag behind strong coreset methods due to its over-reliance on easy sample patches. Based on this, we introduce CAD-Prune, a compute-aware pruning metric that efficiently identifies samples of optimal difficulty for a given compute budget, and use it to develop CA2D, a compute-aligned DD method, outperforming current DD methods on ImageNet-1K at various IPC settings. Together, our findings uncover many insights into current DD research and establish useful tools to advance dataefficient learning for both coresets and DD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that soft-label (SL) regimes, especially with knowledge distillation (SL+KD), cause performance saturation near full-dataset levels regardless of subset size or quality, masking data quality issues in dataset distillation (DD) evaluation. This contrasts with hard-label (HL) settings where high-quality coresets outperform random subsets. Systematic experiments show most DD methods fail to beat random baselines on ImageNet-1K in HL, except RDED which still lags strong coresets due to easy-sample reliance. The authors introduce CAD-Prune (a compute-aware pruning metric) and CA2D (a compute-aligned DD method) that outperforms prior DD approaches at various IPC settings.
Significance. If the central claims hold, the work is significant for exposing flaws in soft-label DD evaluation practices and aligning DD more closely with coreset literature through hard-label scrutiny. It provides concrete tools (CAD-Prune, CA2D) for data-efficient learning and includes a systematic comparison of nine DD methods across scales, which is a strength. The empirical focus on ImageNet-1K and introduction of new metrics/methods derived from observations add value, though broader validation would increase impact.
major comments (3)
- [Scalability analysis section] Scalability analysis (detailed in the experiments on label regimes): the claim of near-optimal performance saturation in SL+KD regardless of subset size/quality is load-bearing for the critique of soft-label evaluation and the HL vs. SL discrepancy. This rests on fixed compute budgets and specific architectures; without tests on varying model scales or training protocols, it risks being an artifact of the tested regimes, as noted in the stress-test concern.
- [HL evaluation section] Systematic evaluation of DD methods in HL setting (the section comparing five large-scale and four small-scale methods): the finding that only RDED reliably outperforms random baselines but lags coreset methods due to easy-sample patches is central, yet the post-hoc observation on RDED's reliance and the outperformance claims lack reported error bars, statistical tests, or exact baseline details, weakening support for the cross-method conclusions.
- [CAD-Prune and CA2D section] Development and evaluation of CAD-Prune and CA2D (the section introducing the new metric and method): while CA2D is reported to outperform current DD methods on ImageNet-1K at various IPC, the comparisons do not specify whether they use the same compute budget, include variance across runs, or control for the exact pruning thresholds, which is necessary to establish the improvement as robust rather than regime-specific.
minor comments (3)
- [Abstract and Introduction] Acronyms such as SL, HL, KD, IPC, and DD are used extensively but could be defined more explicitly on first use in the abstract and introduction for broader readability.
- [Figures and Tables] Figure captions and table descriptions would benefit from additional details on the exact experimental setup, including model architectures, training epochs, and compute constraints, to aid reproducibility.
- [Related Work] The related work section could more explicitly contrast the new CAD-Prune metric with prior difficulty-based pruning approaches in the coreset literature to highlight novelty.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below and revised the manuscript to strengthen the empirical support and clarity of our claims.
read point-by-point responses
-
Referee: [Scalability analysis section] Scalability analysis (detailed in the experiments on label regimes): the claim of near-optimal performance saturation in SL+KD regardless of subset size/quality is load-bearing for the critique of soft-label evaluation and the HL vs. SL discrepancy. This rests on fixed compute budgets and specific architectures; without tests on varying model scales or training protocols, it risks being an artifact of the tested regimes, as noted in the stress-test concern.
Authors: We acknowledge that our primary scalability analysis uses fixed compute budgets and specific architectures to isolate the effects of label regimes. While this design choice was intentional to enable direct comparison, we agree that additional validation across scales would strengthen the claims. In the revised manuscript, we have added experiments using different model scales and architectures, which continue to show the saturation effect. We have also expanded the discussion to address potential influences of training protocols and note this as a limitation for future work. revision: yes
-
Referee: [HL evaluation section] Systematic evaluation of DD methods in HL setting (the section comparing five large-scale and four small-scale methods): the finding that only RDED reliably outperforms random baselines but lags coreset methods due to easy-sample patches is central, yet the post-hoc observation on RDED's reliance and the outperformance claims lack reported error bars, statistical tests, or exact baseline details, weakening support for the cross-method conclusions.
Authors: We agree that reporting error bars, conducting statistical tests, and providing precise baseline details would improve the robustness of the HL evaluation results. We have revised this section to include standard deviations from multiple independent runs, pairwise statistical significance tests (e.g., t-tests) against the random baseline, and expanded descriptions of all baseline implementations and hyperparameters. revision: yes
-
Referee: [CAD-Prune and CA2D section] Development and evaluation of CAD-Prune and CA2D (the section introducing the new metric and method): while CA2D is reported to outperform current DD methods on ImageNet-1K at various IPC, the comparisons do not specify whether they use the same compute budget, include variance across runs, or control for the exact pruning thresholds, which is necessary to establish the improvement as robust rather than regime-specific.
Authors: We thank the referee for this observation on ensuring fair comparisons. We have updated the CAD-Prune and CA2D evaluation section to explicitly confirm that all methods were trained and evaluated under matched compute budgets. We now report performance variance across multiple random seeds and provide the exact pruning threshold values and selection criteria used in CAD-Prune to facilitate reproducibility and demonstrate that the gains are not regime-specific. revision: yes
Circularity Check
No circularity: empirical observations and new methods are independent of inputs
full rationale
The paper's central claims rest on systematic experiments comparing DD methods, coresets, and random baselines across HL, SL, and SL+KD regimes on ImageNet-1K and smaller datasets. Performance saturation in SL+KD is reported as an observed outcome under fixed compute budgets, not derived from any equation or prior fit. CAD-Prune and CA2D are introduced as new heuristics motivated by those observations (e.g., difficulty-aware pruning for compute alignment), without any reduction of the proposed metrics to the experimental results by construction. No self-citations are load-bearing for the core findings, no uniqueness theorems are invoked, and no ansatz or renaming of known results occurs. The derivation chain is therefore self-contained empirical analysis rather than tautological.
Axiom & Free-Parameter Ledger
invented entities (2)
-
CAD-Prune
no independent evidence
-
CA2D
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Knowledge distilla- tion: A good teacher is patient and consistent
Lucas Beyer, Xiaohua Zhai, Am´elie Royer, Larisa Markeeva, Rohan Anil, and Alexander Kolesnikov. Knowledge distilla- tion: A good teacher is patient and consistent. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10925–10934, 2022. 1
2022
-
[2]
Dataset distillation by matching training trajectories
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4750–4759, 2022. 3, 6, 7, 11, 12, 15, 17, 18
2022
-
[3]
Generalizing dataset distillation via deep generative prior
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Generalizing dataset distillation via deep generative prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3739–3748, 2023. 11
2023
-
[4]
Lightweight dataset pruning without full training via example difficulty and prediction uncertainty
Yeseul Cho, Baekrok Shin, Changmin Kang, and Chul- hee Yun. Lightweight dataset pruning without full training via example difficulty and prediction uncertainty. InPro- ceedings of the 42nd International Conference on Machine Learning, pages 10602–10643. PMLR, 2025. 18
2025
-
[5]
Dc- bench: Dataset condensation benchmark.Advances in Neu- ral Information Processing Systems, 35:810–822, 2022
Justin Cui, Ruochen Wang, Si Si, and Cho-Jui Hsieh. Dc- bench: Dataset condensation benchmark.Advances in Neu- ral Information Processing Systems, 35:810–822, 2022. 15
2022
-
[6]
Scaling up dataset distillation to imagenet-1k with constant memory
Justin Cui, Ruochen Wang, Si Si, and Cho-Jui Hsieh. Scaling up dataset distillation to imagenet-1k with constant memory. InInternational Conference on Machine Learning, pages 6565–6590. PMLR, 2023. 2, 5
2023
-
[7]
Fast and accurate data resid- ual matching for dataset distillation
Jiacheng Cui, Xinyue Bi, Yaxin Luo, Xiaohan Zhao, Ji- acheng Liu, and Zhiqiang Shen. Fast and accurate data resid- ual matching for dataset distillation. InAdvances in Neural Information Processing Systems, 2025. 18
2025
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 1, 2, 3, 11
2009
-
[9]
Diversity-driven synthesis: Enhancing dataset distilla- tion through directed weight adjustment.Advances in neural information processing systems, 37:119443–119465, 2024
Jiawei Du, Juncheng Hu, Wenxin Huang, Joey Tianyi Zhou, et al. Diversity-driven synthesis: Enhancing dataset distilla- tion through directed weight adjustment.Advances in neural information processing systems, 37:119443–119465, 2024. 1, 3, 4, 11, 17
2024
-
[10]
Knowledge distillation: A survey.Interna- tional Journal of Computer Vision, 129(6):1789–1819, 2021
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey.Interna- tional Journal of Computer Vision, 129(6):1789–1819, 2021. 1
2021
-
[11]
Scaling laws for data filtering–data curation cannot be compute agnostic
Sachin Goyal, Pratyush Maini, Zachary C Lipton, Aditi Raghunathan, and J Zico Kolter. Scaling laws for data filtering–data curation cannot be compute agnostic. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22702–22711, 2024. 1, 13
2024
-
[12]
Efficient dataset distillation via minimax diffusion
Jianyang Gu, Saeed Vahidian, Vyacheslav Kungurtsev, Hao- nan Wang, Wei Jiang, Yang You, and Yiran Chen. Efficient dataset distillation via minimax diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1, 3, 4, 11
2024
-
[13]
Deepcore: A comprehensive library for coreset selection in deep learn- ing
Chengcheng Guo, Bo Zhao, and Yanbing Bai. Deepcore: A comprehensive library for coreset selection in deep learn- ing. InInternational Conference on Database and Expert Systems Applications, pages 181–195. Springer, 2022. 1, 4, 13, 15
2022
-
[14]
Towards lossless dataset dis- tillation via difficulty-aligned trajectory matching
Ziyao Guo, Kai Wang, George Cazenavette, HUI LI, Kaipeng Zhang, and Yang You. Towards lossless dataset dis- tillation via difficulty-aligned trajectory matching. InThe Twelfth International Conference on Learning Representa- tions, 2024. 2, 3, 5, 6, 7, 12, 13, 15, 17
2024
-
[15]
Large- scale dataset pruning with dynamic uncertainty
Muyang He, Shuo Yang, Tiejun Huang, and Bo Zhao. Large- scale dataset pruning with dynamic uncertainty. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024. 1, 4, 7, 8, 18
2024
-
[16]
Distilling the Knowledge in a Neural Network
Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network.ArXiv, abs/1503.02531, 2015. 1
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Submodular combinatorial information mea- sures with applications in machine learning
Rishabh Iyer, Ninad Khargoankar, Jeff Bilmes, and Himan- shu Asanani. Submodular combinatorial information mea- sures with applications in machine learning. InProceedings of the 32nd International Conference on Algorithmic Learn- ing Theory, pages 722–754. PMLR, 2021. 4, 17
2021
-
[18]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[19]
Glister: Generalization based data subset selection for efficient and robust learning
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, and Rishabh Iyer. Glister: Generalization based data subset selection for efficient and robust learning. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 8110–8118, 2021. 12
2021
-
[20]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015. 3
2015
-
[21]
Selmatch: Effectively scaling up dataset distillation via selection-based initializa- tion and partial updates by trajectory matching
Yongmin Lee and Hye Won Chung. Selmatch: Effectively scaling up dataset distillation via selection-based initializa- tion and partial updates by trajectory matching. InForty-first International Conference on Machine Learning, 2024. 2, 3, 6, 7, 8, 19
2024
-
[22]
Awesome dataset distillation.https : / / github
Guang Li, Bo Zhao, and Tongzhou Wang. Awesome dataset distillation.https : / / github . com / Guang000 / Awesome-Dataset-Distillation, 2022. 11
2022
-
[23]
Active learning by acquiring contrastive examples
Katerina Margatina, Giorgos Vernikos, Lo ¨ıc Barrault, and Nikolaos Aletras. Active learning by acquiring contrastive examples. InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, 2021. 4, 17
2021
-
[24]
Coresets for data-efficient training of machine learning mod- els
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning mod- els. InInternational Conference on Machine Learning, pages 6950–6960. PMLR, 2020. 12
2020
-
[25]
Repeated random sampling for minimizing the time-to-accuracy of learning
Patrik Okanovic, Roger Waleffe, Vasilis Mageirakos, Kon- stantinos Nikolakakis, Amin Karbasi, Dionysios Kalogerias, Nezihe Merve G ¨urel, and Theodoros Rekatsinas. Repeated random sampling for minimizing the time-to-accuracy of learning. InThe Twelfth International Conference on Learn- ing Representations, 2024. 4
2024
-
[26]
Deep learning on a data diet: Finding important ex- amples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziu- gaite. Deep learning on a data diet: Finding important ex- amples early in training.Advances in neural information processing systems, 34:20596–20607, 2021. 1, 2, 3, 4, 5, 7, 13, 14, 17, 19
2021
-
[27]
A la- bel is worth a thousand images in dataset distillation
Tian Qin, Zhiwei Deng, and David Alvarez-Melis. A la- bel is worth a thousand images in dataset distillation. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 1, 4, 5, 6
2024
-
[28]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 11
2022
-
[29]
Data distillation: A survey.Transactions on Machine Learning Research, 2023
Noveen Sachdeva and Julian McAuley. Data distillation: A survey.Transactions on Machine Learning Research, 2023. Survey Certification. 1
2023
-
[30]
Generalized large-scale data condensa- tion via various backbone and statistical matching
Shitong Shao, Zeyuan Yin, Muxin Zhou, Xindong Zhang, and Zhiqiang Shen. Generalized large-scale data condensa- tion via various backbone and statistical matching. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16709–16718, 2024. 11
2024
-
[31]
Elucidating the design space of dataset condensation
Shitong Shao, Zikai Zhou, Huanran Chen, and Zhiqiang Shen. Elucidating the design space of dataset condensation. InThe Thirty-eighth Annual Conference on Neural Informa- tion Processing Systems, 2024. 1, 3, 11, 13
2024
-
[32]
Beyond neural scaling laws: beat- ing power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beat- ing power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022. 2, 3, 4, 5, 6, 7
2022
-
[33]
Dˆ 4: Dataset distillation via disentangled diffu- sion model
Duo Su, Junjie Hou, Weizhi Gao, Yingjie Tian, and Bowen Tang. Dˆ 4: Dataset distillation via disentangled diffu- sion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5809– 5818, 2024. 1, 3, 4, 11
2024
-
[34]
On the diversity and realism of distilled dataset: An efficient dataset distilla- tion paradigm
Peng Sun, Bei Shi, Daiwei Yu, and Tao Lin. On the diversity and realism of distilled dataset: An efficient dataset distilla- tion paradigm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9390– 9399, 2024. 1, 2, 3, 4, 6, 7, 11, 13, 19
2024
-
[35]
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J. Gordon. An empirical study of example forgetting during deep neural network learning. InInternational Conference on Learning Representations, 2019. 4, 13
2019
-
[36]
Cafe: Learning to condense dataset by align- ing features
Kai Wang, Bo Zhao, Xiangyu Peng, Zheng Zhu, Shuo Yang, Shuo Wang, Guan Huang, Hakan Bilen, Xinchao Wang, and Yang You. Cafe: Learning to condense dataset by align- ing features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12196– 12205, 2022. 11
2022
-
[37]
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A. Efros. Dataset distillation, 2020. 1, 11
2020
-
[38]
Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective.Advances in Neural Information Process- ing Systems, 36:73582–73603, 2023
Zeyuan Yin, Eric Xing, and Zhiqiang Shen. Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective.Advances in Neural Information Process- ing Systems, 36:73582–73603, 2023. 1, 3, 4, 11, 16, 17
2023
-
[39]
Dataset condensation with dis- tribution matching
Bo Zhao and Hakan Bilen. Dataset condensation with dis- tribution matching. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023. 3, 6, 11, 12, 15, 16, 17
2023
-
[40]
Dataset condensation with gradient matching
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching. InInternational Con- ference on Learning Representations, 2021. 3, 6, 12, 15, 17
2021
-
[41]
Dataset distillation using neural feature regression.Advances in Neu- ral Information Processing Systems, 35:9813–9827, 2022
Yongchao Zhou, Ehsan Nezhadarya, and Jimmy Ba. Dataset distillation using neural feature regression.Advances in Neu- ral Information Processing Systems, 35:9813–9827, 2022. 6, 11 Appendix A. Details on Methods and their loss objectives A.1. Large-scale methods Early dataset distillation methods [2, 36, 37, 39, 41] relied on a bi-level optimization framewo...
2022
-
[42]
Many subsequent works, like EDC [31], DW A [9], G-VBSM [30], etc
and beyond. Many subsequent works, like EDC [31], DW A [9], G-VBSM [30], etc. have adopted a similar ap- proach by building on top of this framework. We briefly describe such techniques below for ease of reference and clarity: SRe2L[38] performs distillation by optimizing two loss objectives: (1) the standard Cross-entropy loss, and (2) another loss which...
-
[43]
to generate synthetic images. Multiple prototypes are created for each class using K-means clustering in the latent space, which are then denoised using the pre-trained LDM model before passing them through a pre-trained decoder to produce synthetic images. Minimax Diffusion[12] incorporates diffusion- transformer (DiT) based generative models to create a...
-
[44]
The model architecture is ConvNet- D3, and we compare performance for both IPC 10 and IPC
for our evaluation. The model architecture is ConvNet- D3, and we compare performance for both IPC 10 and IPC
-
[45]
The results are summarized in Tab. 6 . The hyperparam- eters details are provided in Sec. B of the supplementary. While TM [2] exhibits aclear advantage over core- set baselines in the HL setting on CIFAR-100, this advan- tage substantially diminishes once we transition to the SL regime—even at low IPC. For example, although TM ex- ceeds K-Centers by appr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.