Recognition: unknown
One Step Forward and K Steps Back: Better Reasoning with Denoising Recursion Models
Pith reviewed 2026-05-10 04:52 UTC · model grok-4.3
The pith
Denoising Recursion Models reverse noise over multiple recursive steps to improve performance on ARC-AGI reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Denoising Recursion Models corrupt data with varying magnitudes of noise and train the model to reverse the corruption over multiple recursive steps. This provides a tractable curriculum of intermediate states while better aligning training with testing and incentivizing non-greedy, forward-looking generation.
What carries the argument
Denoising Recursion Model, which trains a shared transformer to reverse noise corruption in multiple recursive steps.
If this is right
- Long refinement trajectories for difficult problems become easier to learn through the provided intermediate states.
- Training behavior matches testing behavior more closely by using multi-step reversal.
- Non-greedy generation is incentivized as the model learns to plan over multiple steps.
- Superior performance is achieved compared to the Tiny Recursion Model on ARC-AGI.
Where Pith is reading between the lines
- Such models could be applied to other iterative tasks where building structure from noise is key, like image generation or planning.
- Adjusting the number of recursive steps during training might offer a way to control the difficulty of the curriculum dynamically.
- This suggests potential for improving parameter-efficient deep reasoning in other looped neural architectures.
Load-bearing premise
Training to reverse noise over multiple recursive steps will supply a useful curriculum, align train and test distributions, and incentivize non-greedy behavior without new optimization instabilities.
What would settle it
Running the Denoising Recursion Model on ARC-AGI and observing no performance gain over the Tiny Recursion Model would disprove the benefit of the multi-step approach.
Figures







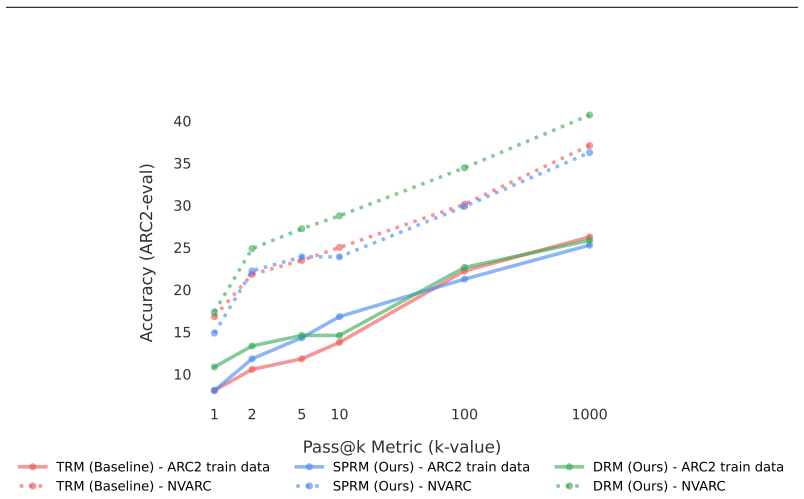
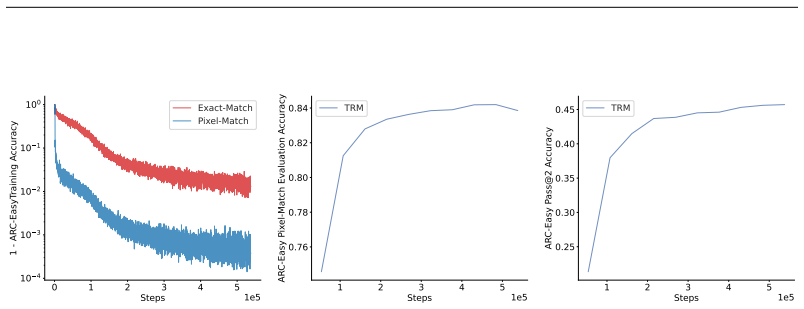



read the original abstract
Looped transformers scale computational depth without increasing parameter count by repeatedly applying a shared transformer block and can be used for iterative refinement, where each loop rewrites a full fixed-size prediction in parallel. On difficult problems, such as those that require search-like computation, reaching a highly structured solution starting from noise can require long refinement trajectories. Learning such trajectories is challenging when training specifies only the target solution and provides no supervision over the intermediate refinement path. Diffusion models tackle this issue by corrupting data with varying magnitudes of noise and training the model to reverse it in a \textit{single step}. However, this process misaligns training and testing behaviour. We introduce Denoising Recursion Models, a method that similarly corrupts data with noise but trains the model to reverse the corruption over \textit{multiple} recursive steps. This strategy provides a tractable curriculum of intermediate states, while better aligning training with testing and incentivizing non-greedy, forward-looking generation. Through extensive experiments, we show this approach outperforms the Tiny Recursion Model (TRM) on ARC-AGI, where it recently achieved breakthrough performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Denoising Recursion Models, which extend looped transformers by corrupting inputs with noise and training a shared transformer block to reverse the corruption over multiple recursive steps (rather than one). This is argued to supply an intermediate-state curriculum, better align training and test distributions, and incentivize non-greedy behavior. The central claim is that the resulting models outperform the Tiny Recursion Model (TRM) on ARC-AGI, as demonstrated through extensive experiments.
Significance. If the empirical results hold under rigorous controls, the work could advance training of parameter-efficient iterative refinement architectures for search-like reasoning tasks. By integrating multi-step denoising into recursion, it addresses the lack of intermediate supervision in looped models while potentially avoiding some train-test misalignment issues of standard diffusion approaches.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): The manuscript asserts outperformance on ARC-AGI via 'extensive experiments' but the provided description supplies no quantitative metrics, matched baselines, ablation results on recursion depth K, statistical tests, or controls for hyperparameter tuning budgets. This renders the central empirical claim unverifiable and leaves open whether multi-step denoising yields net gains or merely requires compensatory tuning.
- [§3 (Method)] §3 (Method): The claim that training to reverse noise over K recursive steps 'automatically' supplies a useful curriculum, aligns distributions, and avoids greedy behavior without introducing compounding prediction errors or gradient instabilities is presented without supporting analysis, loss diagnostics across depth, or sensitivity studies. This assumption is load-bearing for the proposed advantage over single-step or standard recursion.
minor comments (2)
- [Abstract] Abstract: Including at least one key performance number or comparison would help substantiate the outperformance claim for readers.
- [Notation] Notation and figures: Ensure the noise schedule, recursion update rule, and loss formulation are defined with explicit equations and that any diagrams of the K-step process are clearly labeled.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for acknowledging the potential of integrating multi-step denoising into looped transformers for reasoning tasks. We address the two major comments below with specific plans for revision. We believe these changes will enhance the verifiability of our empirical claims and the supporting analysis for our methodological assumptions.
read point-by-point responses
-
Referee: [§4 (Experiments)] The manuscript asserts outperformance on ARC-AGI via 'extensive experiments' but the provided description supplies no quantitative metrics, matched baselines, ablation results on recursion depth K, statistical tests, or controls for hyperparameter tuning budgets. This renders the central empirical claim unverifiable and leaves open whether multi-step denoising yields net gains or merely requires compensatory tuning.
Authors: We acknowledge that the summary in Section 4 could be expanded for greater clarity and verifiability. The full manuscript does include quantitative comparisons in Tables 1–3 reporting ARC-AGI accuracy improvements over TRM and other baselines, along with some matched controls. However, we agree that explicit ablations on recursion depth K, statistical significance (e.g., standard deviations over seeds), and details on hyperparameter tuning budgets are necessary to rule out compensatory tuning effects. We will revise Section 4 to add these elements, including a dedicated ablation table for K=1 to K=8, multiple-run statistics, and a description of the tuning protocol used for all models. revision: yes
-
Referee: [§3 (Method)] The claim that training to reverse noise over K recursive steps 'automatically' supplies a useful curriculum, aligns distributions, and avoids greedy behavior without introducing compounding prediction errors or gradient instabilities is presented without supporting analysis, loss diagnostics across depth, or sensitivity studies. This assumption is load-bearing for the proposed advantage over single-step or standard recursion.
Authors: Section 3 presents a conceptual rationale: multi-step noise reversal creates a curriculum of progressively cleaner intermediate states, the shared recursive process aligns train and test distributions, and forward-looking reversal discourages greedy local corrections. We did not include loss-per-depth diagnostics or sensitivity plots in the initial submission. We agree this supporting analysis would strengthen the paper and will add it in revision, specifically loss curves across recursion steps, gradient norm statistics to address stability, and performance sensitivity as a function of K to demonstrate the absence of compounding errors. revision: yes
Circularity Check
No circularity: empirical claims rest on experiments, not definitional reduction
full rationale
The paper proposes Denoising Recursion Models as a training strategy for looped transformers, describing how noise corruption followed by multi-step reversal supplies a curriculum and alignment by design. However, the central result—outperformance over TRM on ARC-AGI—is asserted via 'extensive experiments' rather than any derivation, equation, or fitted parameter that reduces to the method's own inputs. No self-citations, uniqueness theorems, or ansatzes are invoked to force conclusions; the argument remains externally falsifiable through the reported empirical comparisons and does not contain load-bearing steps that collapse by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Looped transformers can perform iterative refinement by repeatedly applying a shared block to rewrite a fixed-size prediction.
- domain assumption Single-step noise reversal in diffusion-style training misaligns with the multi-step inference behavior of looped models.
Reference graph
Works this paper leans on
-
[1]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Large Language Diffusion Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[2]
IEEE transactions on pattern analysis and machine intelligence , volume=
Diffusion models in vision: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2023 , publisher=
2023
-
[3]
The Principles of Diffusion Models,
The principles of diffusion models , author=. arXiv preprint arXiv:2510.21890 , year=
-
[4]
OpenAI , howpublished =
-
[5]
2025 , journal=
Sketch-of-Thought: Efficient LLM Reasoning with Adaptive Cognitive-Inspired Sketching , author=. 2025 , journal=
2025
-
[6]
The Benefits of a Concise Chain of Thought on Problem-Solving in Large Language Models , year=
Renze, Matthew and Guven, Erhan , booktitle=. The Benefits of a Concise Chain of Thought on Problem-Solving in Large Language Models , year=
-
[7]
2025 , journal=
How Well do LLMs Compress Their Own Chain-of-Thought? A Token Complexity Approach , author=. 2025 , journal=
2025
-
[8]
The Impact of Reasoning Step Length on Large Language Models
Jin, Mingyu and Yu, Qinkai and Shu, Dong and Zhao, Haiyan and Hua, Wenyue and Meng, Yanda and Zhang, Yongfeng and Du, Mengnan. The Impact of Reasoning Step Length on Large Language Models. Findings of the Association for Computational Linguistics. 2024
2024
-
[9]
2025 , archivePrefix=
Concise Thoughts: Impact of Output Length on LLM Reasoning and Cost , author=. 2025 , archivePrefix=
2025
-
[10]
2024 , journal=
C3oT: Generating Shorter Chain-of-Thought without Compromising Effectiveness , author=. 2024 , journal=
2024
-
[11]
2025 , archivePrefix=
Token-Budget-Aware LLM Reasoning , author=. 2025 , archivePrefix=
2025
-
[12]
2025 , journal=
Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs , author=. 2025 , journal=
2025
-
[13]
2025 , journal=
Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging , author=. 2025 , journal=
2025
-
[14]
2025 , journal=
Self-Training Elicits Concise Reasoning in Large Language Models , author=. 2025 , journal=
2025
-
[15]
2025 , journal=
Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning , author=. 2025 , journal=
2025
-
[16]
Conference on Neural Information Processing Systems , year=
Can Language Models Learn to Skip Steps? , author=. Conference on Neural Information Processing Systems , year=
-
[17]
2025 , journal=
Z1: Efficient Test-time Scaling with Code , author=. 2025 , journal=
2025
-
[18]
2025 , journal=
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling , author=. 2025 , journal=
2025
-
[19]
A Thorough Examination of Decoding Methods in the Era of LLM s
Shi, Chufan and Yang, Haoran and Cai, Deng and Zhang, Zhisong and Wang, Yifan and Yang, Yujiu and Lam, Wai. A Thorough Examination of Decoding Methods in the Era of LLM s. Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2024
2024
-
[20]
International Conference on Learning Representations , year=
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models , author=. International Conference on Learning Representations , year=
-
[21]
2021 , journal=
Training Verifiers to Solve Math Word Problems , author=. 2021 , journal=
2021
-
[22]
International Conference on Learning Representations , year=
Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces , author=. International Conference on Learning Representations , year=
-
[23]
2024 , journal=
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations , author=. 2024 , journal=
2024
-
[24]
2024 , journal=
Training Large Language Models to Reason in a Continuous Latent Space , author=. 2024 , journal=
2024
-
[25]
2025 , journal=
SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs , author=. 2025 , journal=
2025
-
[26]
2025 , journal=
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation , author=. 2025 , journal=
2025
-
[27]
2025 , journal=
Efficient Reasoning with Hidden Thinking , author=. 2025 , journal=
2025
-
[28]
2025 , journal=
LightThinker: Thinking Step-by-Step Compression , author=. 2025 , journal=
2025
-
[29]
2025 , journal=
InftyThink: Breaking the Length Limits of Long-Context Reasoning in Large Language Models , author=. 2025 , journal=
2025
-
[30]
2025 , journal=
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking , author=. 2025 , journal=
2025
-
[31]
Conference on Neural Information Processing Systems , year=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Conference on Neural Information Processing Systems , year=
-
[32]
International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations , year=
-
[33]
2025 , journal=
Chain of Draft: Thinking Faster by Writing Less , author=. 2025 , journal=
2025
-
[34]
ICML 2024 Workshop on In-Context Learning , year=
Universal Self-Consistency for Large Language Models , author=. ICML 2024 Workshop on In-Context Learning , year=
2024
-
[35]
Conference on Neural Information Processing Systems , year=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. Conference on Neural Information Processing Systems , year=
-
[36]
Aggarwal, Pranjal and Madaan, Aman and Yang, Yiming and. Let
-
[37]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[38]
International Conference on Learning Representations , year=
Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning , author=. International Conference on Learning Representations , year=
-
[39]
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning , author=. arXiv preprint arXiv:2408.13457 , year=
-
[40]
Think Smarter not Harder: Adaptive Reasoning with Inference Aware Optimization , author=. arXiv preprint arXiv:2501.17974 , year=
-
[41]
Integrate the Essence and Eliminate the Dross: Fine-Grained Self-Consistency for Free-Form Language Generation
Wang, Xinglin and Li, Yiwei and Feng, Shaoxiong and Yuan, Peiwen and Pan, Boyuan and Wang, Heda and Hu, Yao and Li, Kan. Integrate the Essence and Eliminate the Dross: Fine-Grained Self-Consistency for Free-Form Language Generation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 2024
2024
-
[42]
2025 , journal=
Think More, Hallucinate Less: Mitigating Hallucinations via Dual Process of Fast and Slow Thinking , author=. 2025 , journal=
2025
-
[43]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review arXiv
-
[44]
2025 , journal=
s1: Simple test-time scaling , author=. 2025 , journal=
2025
-
[45]
2025 , eprint=
Concise Reasoning via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[46]
2025 , archivePrefix=
CoT-Valve: Length-Compressible Chain-of-Thought Tuning , author=. 2025 , archivePrefix=
2025
-
[47]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[48]
Dast: Difficulty-adaptive slow-thinking for large reasoning models
Dast: Difficulty-adaptive slow-thinking for large reasoning models , author=. arXiv preprint arXiv:2503.04472 , year=
-
[49]
2025 , journal=
TokenSkip: Controllable Chain-of-Thought Compression in LLMs , author=. 2025 , journal=
2025
-
[50]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning.ArXiv, abs/2501.12570, 2025
O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning , author=. arXiv preprint arXiv:2501.12570 , year=
-
[51]
Optimizing test-time compute via meta reinforcement fine-tuning
Optimizing test-time compute via meta reinforcement fine-tuning , author=. arXiv preprint arXiv:2503.07572 , year=
-
[52]
Conference on Neural Information Processing Systems , year=
Chain of preference optimization: Improving chain-of-thought reasoning in llms , author=. Conference on Neural Information Processing Systems , year=
-
[53]
arXiv preprint arXiv:2503.17363 , year=
Dancing with Critiques: Enhancing LLM Reasoning with Stepwise Natural Language Self-Critique , author=. arXiv preprint arXiv:2503.17363 , year=
-
[54]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
-
[55]
When More is Less: Understanding Chain-of-Thought Length in
Yuyang Wu and Yifei Wang and Tianqi Du and Stefanie Jegelka and Yisen Wang , booktitle=. When More is Less: Understanding Chain-of-Thought Length in
-
[56]
International Conference on Learning Representations , year=
System 1.x: Learning to Balance Fast and Slow Planning with Language Models , author=. International Conference on Learning Representations , year=
-
[57]
Training language models to reason efficiently.ArXiv, abs/2502.04463, 2025
Training Language Models to Reason Efficiently , author=. arXiv preprint arXiv:2502.04463 , year=
-
[58]
Reasoning Aware Self-Consistency: Leveraging Reasoning Paths for Efficient LLM Sampling
-
[59]
2025 , journal=
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks , author=. 2025 , journal=
2025
-
[60]
2025 , journal=
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning , author=. 2025 , journal=
2025
-
[61]
Sampling-Efficient Test-Time Scaling: Self-Estimating the Best-of-N Sampling in Early Decoding
-
[62]
2025 , journal=
FastMCTS: A Simple Sampling Strategy for Data Synthesis , author=. 2025 , journal=
2025
-
[63]
Conference on Neural Information Processing Systems , year=
Fast Best-of-N Decoding via Speculative Rejection , author=. Conference on Neural Information Processing Systems , year=
-
[64]
2024 , journal=
MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time , author=. 2024 , journal=
2024
-
[65]
2024 , journal=
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , author=. 2024 , journal=
2024
-
[66]
2025 , journal=
Iterative Deepening Sampling for Large Language Models , author=. 2025 , journal=
2025
-
[67]
2024 , archivePrefix=
Training Language Models to Self-Correct via Reinforcement Learning , author=. 2024 , archivePrefix=
2024
-
[68]
, title =
Vazirani, Vijay V. , title =. 2010 , publisher =
2010
-
[69]
Conference on Neural Information Processing Systems , year=
Simple and Effective Masked Diffusion Language Models , author=. Conference on Neural Information Processing Systems , year=
-
[70]
2025 , journal=
Let LLMs Break Free from Overthinking via Self-Braking Tuning , author=. 2025 , journal=
2025
-
[71]
2025 , journal=
Adaptive Deep Reasoning: Triggering Deep Thinking When Needed , author=. 2025 , journal=
2025
-
[72]
2025 , journal=
ARM: Adaptive Reasoning Model , author=. 2025 , journal=
2025
-
[73]
2025 , journal=
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking , author=. 2025 , journal=
2025
-
[74]
2025 , journal=
AdaCtrl: Towards Adaptive and Controllable Reasoning via Difficulty-Aware Budgeting , author=. 2025 , journal=
2025
-
[75]
2025 , journal=
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition , author=. 2025 , journal=
2025
-
[76]
2025 , journal=
Think Only When You Need with Large Hybrid-Reasoning Models , author=. 2025 , journal=
2025
-
[77]
2025 , journal=
Long-Short Chain-of-Thought Mixture Supervised Fine-Tuning Eliciting Efficient Reasoning in Large Language Models , author=. 2025 , journal=
2025
-
[78]
2024 , journal=
OpenAI o1 System Card , author=. 2024 , journal=
2024
-
[79]
Tianzhe Chu and Yuexiang Zhai and Jihan Yang and Shengbang Tong and Saining Xie and Sergey Levine and Yi Ma , booktitle=
-
[80]
Exploring Transformers as Compact, Data-efficient Language Models
Fields, Clayton and Kennington, Casey. Exploring Transformers as Compact, Data-efficient Language Models. Proceedings of the 27th Conference on Computational Natural Language Learning. 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.