Recognition: unknown
Task Switching Without Forgetting via Proximal Decoupling
Pith reviewed 2026-05-10 04:47 UTC · model grok-4.3
The pith
Operator splitting decouples task learning from stability enforcement to prevent forgetting in continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
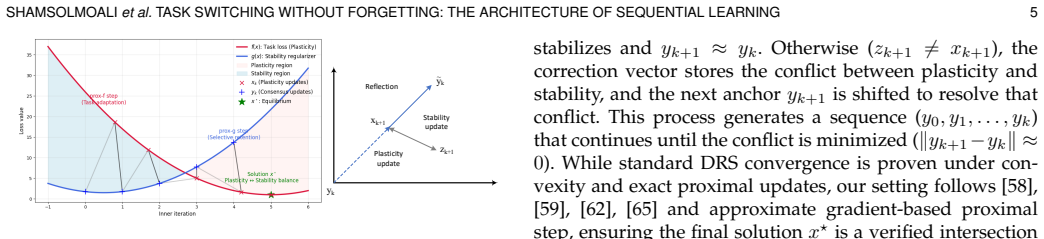
The paper claims that applying operator splitting to the continual learning objective separates the process into a learning operator focused on minimizing the current task loss and a proximal stability operator equipped with a sparse regularizer. The stability operator prunes unnecessary parameters and preserves those critical for previous tasks. This avoids the over-constraining that arises when regularization is added directly to the loss and produces a negotiated update between the two operators.
What carries the argument
Operator splitting between a task-learning operator minimizing current loss and a proximal stability operator with sparse regularization that prunes redundant parameters while retaining task-critical ones.
If this is right
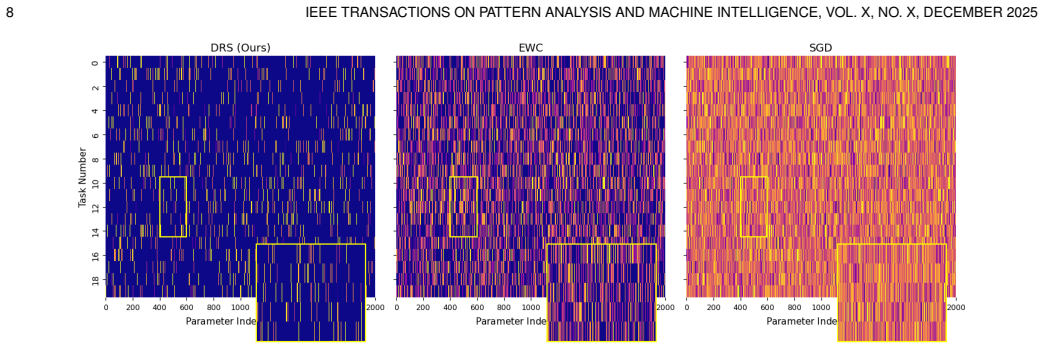
- Improves both stability on old tasks and adaptability to new tasks on standard benchmarks.
- Removes the need for replay buffers, Bayesian sampling, or meta-learning components.
- Supports better forward transfer and more efficient capacity use as the number of tasks increases.
- Supplies theoretical justification for the splitting method applied to the continual-learning objective.
Where Pith is reading between the lines
- The operator separation could extend to other settings where optimization involves conflicting objectives, such as multi-task or federated learning.
- The built-in sparse regularization may produce models that are naturally more compact, aiding inference on limited hardware.
- Applying the same split to reinforcement learning continual settings could reduce interference between policy updates for successive environments.
Load-bearing premise
The proximal stability step with a sparse regularizer can reliably identify and preserve task-relevant parameters while pruning others across growing task sequences without introducing new instabilities or requiring task-specific tuning.
What would settle it
A long sequence of dissimilar tasks where the method exhibits rising forgetting rates or requires per-task hyperparameter adjustments comparable to standard regularization would refute the advantage of the decoupling.
Figures












read the original abstract
In continual learning, the primary challenge is to learn new information without forgetting old knowledge. A common solution addresses this trade-off through regularization, penalizing changes to parameters critical for previous tasks. In most cases, this regularization term is directly added to the training loss and optimized with standard gradient descent, which blends learning and retention signals into a single update and does not explicitly separate essential parameters from redundant ones. As task sequences grow, this coupling can over-constrain the model, limiting forward transfer and leading to inefficient use of capacity. We propose a different approach that separates task learning from stability enforcement via operator splitting. The learning step focuses on minimizing the current task loss, while a proximal stability step applies a sparse regularizer to prune unnecessary parameters and preserve task-relevant ones. This turns the stability-plasticity into a negotiated update between two complementary operators, rather than a conflicting gradient. We provide theoretical justification for the splitting method on the continual-learning objective, and demonstrate that our proposed solver achieves state-of-the-art results on standard benchmarks, improving both stability and adaptability without the need for replay buffers, Bayesian sampling, or meta-learning components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Proximal Decoupling for continual learning, using operator splitting to separate a learning step (minimizing current-task loss) from a proximal stability step that applies a sparse regularizer to prune redundant parameters while preserving those relevant to prior tasks. It claims this decouples the stability-plasticity trade-off, supplies theoretical justification for the splitting method on the continual-learning objective, and achieves SOTA results on standard benchmarks without replay buffers, Bayesian sampling, or meta-learning.
Significance. If the proximal operator reliably identifies task-relevant parameters in non-convex DNN losses, the method would provide a simple, buffer-free alternative to regularization-based continual learning that improves both stability and adaptability. The explicit separation of operators and the claimed theoretical grounding are strengths that could influence future work on scalable task sequences.
major comments (3)
- [Theoretical justification] Theoretical justification section: the derivation of the splitting method on the continual-learning objective must explicitly address non-convexity of the DNN loss and show why the proximal map (typically soft-thresholding for the sparse regularizer) aligns with functional task relevance rather than weight magnitude; otherwise the separation claim does not hold for growing task sequences.
- [Method and Experiments] Method and experimental sections: the central claim that the proximal stability step works without per-task tuning or new instabilities requires ablations demonstrating that the sparse regularizer strength can be fixed across tasks; misalignment between magnitude-based pruning and true importance would violate the no-replay, no-meta-learning SOTA result.
- [Experiments] Experimental evaluation: the SOTA claims on standard benchmarks need error bars, statistical significance tests, and analysis of capacity usage over long sequences to confirm that pruning does not cause unintended forgetting or wasted capacity.
minor comments (1)
- [Abstract and Method] Abstract and method: the description of the proximal operator and sparse regularizer would benefit from an explicit equation or pseudocode in the main text rather than relying solely on prose.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will make targeted revisions to strengthen the theoretical and experimental sections.
read point-by-point responses
-
Referee: [Theoretical justification] Theoretical justification section: the derivation of the splitting method on the continual-learning objective must explicitly address non-convexity of the DNN loss and show why the proximal map (typically soft-thresholding for the sparse regularizer) aligns with functional task relevance rather than weight magnitude; otherwise the separation claim does not hold for growing task sequences.
Authors: We appreciate the referee's emphasis on rigor here. The derivation in the manuscript applies operator splitting directly to the continual-learning objective, separating the task-loss minimization from the proximal stability operator. Proximal methods are known to apply under non-convexity when the non-smooth term is handled separately, and we will revise the section to explicitly note this and reference supporting results from non-convex proximal optimization literature. On alignment with functional relevance, we will add clarification that the proximal map is magnitude-based but operates iteratively within the stability objective; this process retains parameters that support prior-task performance, as confirmed by our retention metrics. We view this as sufficient to uphold the separation claim for the evaluated task sequences. revision: partial
-
Referee: [Method and Experiments] Method and experimental sections: the central claim that the proximal stability step works without per-task tuning or new instabilities requires ablations demonstrating that the sparse regularizer strength can be fixed across tasks; misalignment between magnitude-based pruning and true importance would violate the no-replay, no-meta-learning SOTA result.
Authors: We agree that fixed hyperparameters are central to the method's appeal. The sparse regularizer strength was held constant across tasks in all reported experiments, with no per-task retuning or observed instabilities. We will add an explicit ablation subsection showing results under a single fixed strength value, confirming stable performance. Regarding potential misalignment, the proximal step enforces sparsity based on the stability objective rather than isolated magnitude; the achieved SOTA results without replay, Bayesian methods, or meta-learning demonstrate that this does not produce the violation described. revision: yes
-
Referee: [Experiments] Experimental evaluation: the SOTA claims on standard benchmarks need error bars, statistical significance tests, and analysis of capacity usage over long sequences to confirm that pruning does not cause unintended forgetting or wasted capacity.
Authors: We will update the experimental section to report error bars from multiple random seeds and include statistical significance tests (e.g., Wilcoxon signed-rank tests) against baselines to support the SOTA claims. We will also add a capacity-usage analysis tracking the fraction of active parameters after each proximal step and verifying no unintended forgetting on the standard benchmarks. While our evaluation follows the sequence lengths conventional in the literature, we will discuss scalability implications for longer sequences. revision: yes
Circularity Check
No significant circularity; derivation presented as independent solver
full rationale
The paper introduces operator splitting to decouple task learning (current loss minimization) from proximal stability enforcement (sparse regularizer on parameters) for continual learning. This is framed as a new solver with claimed theoretical justification on the CL objective and empirical SOTA results on benchmarks, without replay or meta-learning. No equations or steps in the abstract or description reduce a prediction or first-principles result to its own inputs by construction, nor rely on self-citation chains, ansatz smuggling, or renaming of known results as the core derivation. The approach is self-contained against external benchmarks and does not exhibit self-definitional or fitted-input patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proximal operators for sparse regularization can separate stability enforcement from task loss minimization without introducing instability
Reference graph
Works this paper leans on
-
[1]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology. Learn. Motiv., volume 24, pages 109–165. 1989
1989
-
[2]
Memory aware synapses: Learn- ing what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. Memory aware synapses: Learn- ing what (not) to forget. InEur. Conf. Comput. Vis., pages 139–154, 2018
2018
-
[3]
No one left behind: Real-world federated class- incremental learning.Trans
Jiahua Dong, Hongliu Li, Yang Cong, Gan Sun, Yulun Zhang, and Luc Van Gool. No one left behind: Real-world federated class- incremental learning.Trans. Pattern Anal. Mach. Intell., 46(4):2054– 2070, 2023. 12 IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE, VOL. X, NO. X, DECEMBER 2025
2054
-
[4]
A theoret- ical perspective on streaming noisy data with distribution shift
Wenshui Luo, Shuo Chen, Tao Zhou, and Chen Gong. A theoret- ical perspective on streaming noisy data with distribution shift. Trans. Pattern Anal. Mach. Intell., 2025
2025
-
[5]
Catastrophic forgetting in connectionist net- works.Trends Cogn
Robert M French. Catastrophic forgetting in connectionist net- works.Trends Cogn. Sci., 3(4):128–135, 1999
1999
-
[6]
Mitigating catastrophic forgetting in online continual learning by modeling previous task interrelations via pareto optimization
Yichen Wu, Hong Wang, Peilin Zhao, Yefeng Zheng, Ying Wei, and Long-Kai Huang. Mitigating catastrophic forgetting in online continual learning by modeling previous task interrelations via pareto optimization. InInt. Conf. Mach. Learn., 2024
2024
-
[7]
Layerwise proximal replay: A proximal point method for online continual learning.Int
Jason Yoo, Yunpeng Liu, Frank Wood, and Geoff Pleiss. Layerwise proximal replay: A proximal point method for online continual learning.Int. Conf. Mach. Learn., 2024
2024
-
[8]
Addressing loss of plasticity and catastrophic forgetting in continual learning.Int
Mohamed Elsayed and A Rupam Mahmood. Addressing loss of plasticity and catastrophic forgetting in continual learning.Int. Conf. Learn. Represent., 2024
2024
-
[9]
Bayesian adaptation of network depth and width for continual learning
Jeevan Thapa and Rui Li. Bayesian adaptation of network depth and width for continual learning. InInt. Conf. Learn. Represent., 2024
2024
-
[10]
Star: Stability-inducing weight perturbation for continual learning.Int
Masih Eskandar, Tooba Imtiaz, Davin Hill, Zifeng Wang, and Jen- nifer Dy. Star: Stability-inducing weight perturbation for continual learning.Int. Conf. Mach. Learn., 2025
2025
-
[11]
Efficient lifelong learning with a-gem.Int
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem.Int. Conf. Learn. Represent., 2019
2019
-
[12]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review arXiv 2016
-
[13]
Continual learning with scaled gradient projection
Gobinda Saha and Kaushik Roy. Continual learning with scaled gradient projection. InProc. AAAI Conf. Artif. Intell., volume 37, pages 9677–9685, 2023
2023
-
[14]
Disentangling the causes of plasticity loss in neural networks,
Clare Lyle, Zeyu Zheng, Khimya Khetarpal, Hado van Hasselt, Razvan Pascanu, James Martens, and Will Dabney. Disentangling the causes of plasticity loss in neural networks.arXiv preprint arXiv:2402.18762, 2024
-
[15]
Meta-learning representations for continual learning.Adv
Khurram Javed and Martha White. Meta-learning representations for continual learning.Adv. Neural Inform. Process. Syst., 32, 2019
2019
-
[16]
Measuring catastrophic forgetting in neural networks
Ronald Kemker, Marc McClure, Angelina Abitino, Tyler Hayes, and Christopher Kanan. Measuring catastrophic forgetting in neural networks. InProc. AAAI Conf. Artif. Intell., volume 32, 2018
2018
-
[17]
Recasting continual learning as sequence modeling.Adv
Soochan Lee, Jaehyeon Son, and Gunhee Kim. Recasting continual learning as sequence modeling.Adv. Neural Inform. Process. Syst., 36, 2023
2023
-
[18]
Learning to continually learn with the bayesian principle.Int
Soochan Lee, Hyeonseong Jeon, Jaehyeon Son, and Gunhee Kim. Learning to continually learn with the bayesian principle.Int. Conf. Mach. Learn., 2024
2024
-
[19]
Became: Bayesian continual learning with adaptive model merging.Int
Mei Li, Yuxiang Lu, Qinyan Dai, Suizhi Huang, Yue Ding, and Hongtao Lu. Became: Bayesian continual learning with adaptive model merging.Int. Conf. Mach. Learn., 2025
2025
-
[20]
Bayesian structural adaptation for continual learning
Abhishek Kumar, Sunabha Chatterjee, and Piyush Rai. Bayesian structural adaptation for continual learning. InInt. Conf. Mach. Learn., pages 5850–5860, 2021
2021
-
[21]
Bayesian continual learning and forgetting in neural networks.arXiv preprint arXiv:2504.13569, 2025
Djohan Bonnet, Kellian Cottart, Tifenn Hirtzlin, Tarcisius Januel, Thomas Dalgaty, Elisa Vianello, and Damien Querlioz. Bayesian continual learning and forgetting in neural networks.arXiv preprint arXiv:2504.13569, 2025
-
[22]
Continual learning and catastrophic forgetting.arXiv preprint arXiv:2403.05175, 2024
Gido M Van de Ven, Nicholas Soures, and Dhireesha Kudithipudi. Continual learning and catastrophic forgetting.arXiv preprint arXiv:2403.05175, 2024
-
[23]
Overcoming catastrophic forgetting in neural networks.Proc
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proc. Natl. Acad. Sci. U.S.A., 114(13):3521–3526, 2017
2017
-
[24]
Continual domain adversarial adaptation via double-head dis- criminators
Yan Shen, Zhanghexuan Ji, Chunwei Ma, and Mingchen Gao. Continual domain adversarial adaptation via double-head dis- criminators. InInt. Conf. Artif. Intell. Stat., pages 2584–2592, 2024
2024
-
[25]
Progressive learning: A deep learning framework for continual learning.Neural Net., 128:345–357, 2020
Haytham M Fayek, Lawrence Cavedon, and Hong Ren Wu. Progressive learning: A deep learning framework for continual learning.Neural Net., 128:345–357, 2020
2020
-
[26]
Continual lifelong learning with neural networks: A review.Neural Net., 113:54–71, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Net., 113:54–71, 2019
2019
-
[27]
spred: Solving l1 penalty with sgd
Liu Ziyin and Zihao Wang. spred: Solving l1 penalty with sgd. In Int. Conf. Mach. Learn., pages 43407–43422, 2023
2023
-
[28]
Springer Science & Business Media, 2004
Larry Wasserman.All of statistics: a concise course in statistical inference. Springer Science & Business Media, 2004
2004
-
[29]
Feature selection for nonlinear regression and its application to cancer research
Yijun Sun, Jin Yao, and Steve Goodison. Feature selection for nonlinear regression and its application to cancer research. InProc. SIAM Int. Conf. Data Min., pages 73–81. SIAM, 2015
2015
-
[30]
On the numerical solution of heat conduction problems in two and three space variables.Trans
Jim Douglas and Henry H Rachford. On the numerical solution of heat conduction problems in two and three space variables.Trans. Amer. Math. Soc., 82(2):421–439, 1956
1956
-
[31]
On the dou- glas—rachford splitting method and the proximal point algorithm for maximal monotone operators.Math
Jonathan Eckstein and Dimitri P Bertsekas. On the dou- glas—rachford splitting method and the proximal point algorithm for maximal monotone operators.Math. Program., 55:293–318, 1992
1992
-
[32]
A statistical theory of deep learning via proximal splitting.arXiv preprint arXiv:1509.06061, 2015
Nicholas G Polson, Brandon T Willard, and Massoud Heidari. A statistical theory of deep learning via proximal splitting.arXiv preprint arXiv:1509.06061, 2015
-
[33]
Loss of plasticity in deep continual learning.Nature, 632:768–774, 2024
Shibhansh Dohare, J Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A Rupam Mahmood, and Richard S Sutton. Loss of plasticity in deep continual learning.Nature, 632:768–774, 2024
2024
-
[34]
The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects.Front
Martial Mermillod, Aur ´elia Bugaiska, and Patrick Bonin. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects.Front. Psy- chol., 4:504, 2013
2013
-
[35]
Progres- sive learning without forgetting
Tao Feng, Hangjie Yuan, Mang Wang, Ziyuan Huang, Ang Bian, and Jianzhou Zhang. Progressive learning without forgetting. arXiv preprint arXiv:2211.15215, 2022
-
[36]
Lifelong learning with dynamically expandable networks.Int
Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks.Int. Conf. Learn. Represent., 2018
2018
-
[37]
Forget-free continual learning with winning subnetworks
Haeyong Kang, Rusty John Lloyd Mina, Sultan Rizky Hikmawan Madjid, Jaehong Yoon, Mark Hasegawa-Johnson, Sung Ju Hwang, and Chang D Yoo. Forget-free continual learning with winning subnetworks. InInt. Conf. Mach. Learn., pages 10734–10750, 2022
2022
-
[38]
Tag: Task-based accumulated gradients for lifelong learning
Pranshu Malviya, Balaraman Ravindran, and Sarath Chandar. Tag: Task-based accumulated gradients for lifelong learning. InConf. Lifelong Learn. Agents, pages 366–389, 2022
2022
-
[39]
Rehearsal-free and efficient continual learning for cross-domain face anti-spoofing.Trans
Rizhao Cai, Yawen Cui, Zitong Yu, Xun Lin, Changsheng Chen, and Alex Kot. Rehearsal-free and efficient continual learning for cross-domain face anti-spoofing.Trans. Pattern Anal. Mach. Intell., 2025
2025
-
[40]
Continual learning via sequential function- space variational inference
Tim GJ Rudner, Freddie Bickford Smith, Qixuan Feng, Yee Whye Teh, and Yarin Gal. Continual learning via sequential function- space variational inference. InInt. Conf. Mach. Learn., pages 18871– 18887, 2022
2022
-
[41]
Remind your neural network to prevent catastrophic forgetting
Tyler L Hayes, Kushal Kafle, Robik Shrestha, Manoj Acharya, and Christopher Kanan. Remind your neural network to prevent catastrophic forgetting. InEur. Conf. Comput. vis., pages 466–483, 2020
2020
-
[42]
Tight verifi- cation of probabilistic robustness in bayesian neural networks
Ben Batten, Mehran Hosseini, and Alessio Lomuscio. Tight verifi- cation of probabilistic robustness in bayesian neural networks. In Int. Conf. Artif. Intell. Stat., pages 4906–4914, 2024
2024
-
[43]
Shibhansh Dohare, Richard S Sutton, and A Rupam Mahmood. Continual backprop: Stochastic gradient descent with persistent randomness.arXiv preprint arXiv:2108.06325, 2021
-
[44]
Evcl: Elastic variational continual learning with weight consolidation.Int
Hunar Batra and Ronald Clark. Evcl: Elastic variational continual learning with weight consolidation.Int. Conf. Mach. Learn., 2024
2024
-
[45]
Deep reinforcement learning with plasticity injection.Adv
Evgenii Nikishin, Junhyuk Oh, Georg Ostrovski, Clare Lyle, Raz- van Pascanu, Will Dabney, and Andr´e Barreto. Deep reinforcement learning with plasticity injection.Adv. Neural Inform. Process. Syst., 36:37142–37159, 2023
2023
-
[46]
Loss of plasticity in continual deep reinforce- ment learning
Zaheer Abbas, Rosie Zhao, Joseph Modayil, Adam White, and Marlos C Machado. Loss of plasticity in continual deep reinforce- ment learning. InConf. Lifelong Learn. Agents, pages 620–636, 2023
2023
-
[47]
Approximate bayesian class- conditional models under continuous representation shift
Thomas L Lee and Amos Storkey. Approximate bayesian class- conditional models under continuous representation shift. InInt. Conf. Artif. Intell. Stat., pages 3628–3636, 2024
2024
-
[48]
Flashbacks to harmonize stability and plasticity in continual learning.Neural Net., page 107616, 2025
Leila Mahmoodi, Peyman Moghadam, Munawar Hayat, Christian Simon, and Mehrtash Harandi. Flashbacks to harmonize stability and plasticity in continual learning.Neural Net., page 107616, 2025
2025
-
[49]
Achieving a better stability-plasticity trade-off via auxiliary networks in continual learning
Sanghwan Kim, Lorenzo Noci, Antonio Orvieto, and Thomas Hofmann. Achieving a better stability-plasticity trade-off via auxiliary networks in continual learning. InIEEE Conf. Comput. Vis. Pattern Recog., pages 11930–11939, 2023
2023
-
[50]
Switching between tasks can cause ai to lose the ability to learn.Nature, 2024
Clare Lyle and Razvan Pascanu. Switching between tasks can cause ai to lose the ability to learn.Nature, 2024
2024
-
[51]
Uncertainty-based continual learning with adaptive regulariza- tion.Adv
Hongjoon Ahn, Sungmin Cha, Donggyu Lee, and Taesup Moon. Uncertainty-based continual learning with adaptive regulariza- tion.Adv. Neural Inform. Process. Syst., 32, 2019. SHAMSOLMOALIet al.TASK SWITCHING WITHOUT FORGETTING: THE ARCHITECTURE OF SEQUENTIAL LEARNING 13
2019
-
[52]
Overcoming catastrophic forgetting by bayesian generative regularization
Pei-Hung Chen, Wei Wei, Cho-Jui Hsieh, and Bo Dai. Overcoming catastrophic forgetting by bayesian generative regularization. In Int. Conf. Learn. Represent., pages 1760–1770, 2021
2021
-
[53]
A dual algorithm for the solution of nonlinear variational problems via finite element ap- proximation.Comput
Daniel Gabay and Bertrand Mercier. A dual algorithm for the solution of nonlinear variational problems via finite element ap- proximation.Comput. Math. Appl., 2(1):17–40, 1976
1976
-
[54]
Douglas- rachford networks: Learning both the image prior and data fidelity terms for blind image deconvolution
Raied Aljadaany, Dipan K Pal, and Marios Savvides. Douglas- rachford networks: Learning both the image prior and data fidelity terms for blind image deconvolution. InIEEE Conf. Comput. Vis. Pattern Recog., pages 10235–10244, 2019
2019
-
[55]
Osqp: An operator splitting solver for quadratic programs.Math
Bartolomeo Stellato, Goran Banjac, Paul Goulart, Alberto Bempo- rad, and Stephen Boyd. Osqp: An operator splitting solver for quadratic programs.Math. Program. Comput., 12(4):637–672, 2020
2020
-
[56]
Cosmo: A conic operator splitting method for convex conic problems.J
Michael Garstka, Mark Cannon, and Paul Goulart. Cosmo: A conic operator splitting method for convex conic problems.J. Optim. Theory Appl., 190(3):779–810, 2021
2021
-
[57]
A fast and accurate splitting method for optimal transport: Analysis and implementation.Int
Vien V Mai, Jacob Lindb ¨ack, and Mikael Johansson. A fast and accurate splitting method for optimal transport: Analysis and implementation.Int. Conf. Learn. Represent., 2022
2022
-
[58]
Feddr–randomized douglas-rachford splitting algorithms for non- convex federated composite optimization.Adv
Quoc Tran Dinh, Nhan H Pham, Dzung Phan, and Lam Nguyen. Feddr–randomized douglas-rachford splitting algorithms for non- convex federated composite optimization.Adv. Neural Inform. Process. Syst., 34:30326–30338, 2021
2021
-
[59]
Douglas–rachford splitting for nonconvex optimization with application to nonconvex feasibility problems.Math
Guoyin Li and Ting Kei Pong. Douglas–rachford splitting for nonconvex optimization with application to nonconvex feasibility problems.Math. Program., 159(1):371–401, 2016
2016
-
[60]
Rethinking fast adversarial training: A splitting technique to overcome catas- trophic overfitting
Masoumeh Zareapoor and Pourya Shamsolmoali. Rethinking fast adversarial training: A splitting technique to overcome catas- trophic overfitting. InEur. Conf. Comput. Vis., pages 34–51, 2024
2024
-
[61]
A three-operator splitting scheme derived from three- block admm.Optimization and Engineering, 2025
Anshika Anshika, Jiaxing Li, Debdas Ghosh, and Xiangxiong Zhang. A three-operator splitting scheme derived from three- block admm.Optimization and Engineering, 2025
2025
-
[62]
Accelerated forward–backward and douglas–rachford splitting dynamics.Au- tomatica, 175:112210, 2025
Ibrahim K Ozaslan and Mihailo R Jovanovi ´c. Accelerated forward–backward and douglas–rachford splitting dynamics.Au- tomatica, 175:112210, 2025
2025
-
[63]
Rethinking gradient projection continual learning: Stability/plasticity feature space decoupling
Zhen Zhao, Zhizhong Zhang, Xin Tan, Jun Liu, Yanyun Qu, Yuan Xie, and Lizhuang Ma. Rethinking gradient projection continual learning: Stability/plasticity feature space decoupling. InIEEE Conf. Comput. Vis. Pattern Recog., pages 3718–3727, 2023
2023
-
[64]
Proximal residual flows for bayesian inverse problems
Johannes Hertrich. Proximal residual flows for bayesian inverse problems. InInt. Conf. Scale Space Var. Methods Comput. Vis., pages 210–222, 2023
2023
-
[65]
The douglas–rachford algorithm for convex and nonconvex feasibility problems.Math
Francisco J Arag ´on Artacho, Rub ´en Campoy, and Matthew K Tam. The douglas–rachford algorithm for convex and nonconvex feasibility problems.Math. Methods Oper. Res., 91(2):201–240, 2020
2020
-
[66]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE Conf. Comput. Vis. Pattern Recog., pages 770–778, 2016
2016
-
[67]
Overcoming catastrophic forgetting with hard attention to the task
Joan Serra, Didac Suris, Marius Miron, and Alexandros Karat- zoglou. Overcoming catastrophic forgetting with hard attention to the task. InInt. Conference Mach. Learn., pages 4548–4557, 2018
2018
-
[68]
Learning multiple layers of features from tiny images.Ph.D
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images.Ph.D. dissertation, University of Toronto, 2009
2009
-
[69]
Emnist: Extending mnist to handwritten letters
Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andre Van Schaik. Emnist: Extending mnist to handwritten letters. In Int. Joint Conf. Neural Netw., pages 2921–2926, 2017
2017
-
[70]
Ms-celeb-1m: A dataset and benchmark for large-scale face recognition
Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He, and Jianfeng Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. InEur. Conf. Comput. Vis., pages 87–102, 2016
2016
-
[71]
Tiny imagenet challenge
Jiayu Wu, Qixiang Zhang, and Guoxi Xu. Tiny imagenet challenge. Technical report, 2017
2017
-
[72]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei- Fei. Imagenet: A large-scale hierarchical image database. InIEEE Conf. Comput. Vis. Pattern Recog., pages 248–255, 2009
2009
-
[73]
Casia online and offline chinese handwriting databases
Cheng-Lin Liu, Fei Yin, Da-Han Wang, and Qiu-Feng Wang. Casia online and offline chinese handwriting databases. InInt. Conf. Doc. Anal. Recognit., pages 37–41, 2011. Pourya Shamsolmoali(Senior Member, IEEE) received the PhD degree in computer science from Shanghai Jiao Tong University. He has been a visiting researcher with Link ¨oping Uni- versity, INRIA...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.