Recognition: unknown
Gradient-Based Program Synthesis with Neurally Interpreted Languages
Pith reviewed 2026-05-10 04:26 UTC · model grok-4.3
The pith
The Neural Language Interpreter learns its own discrete operations and refines programs via gradient descent at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NLI autonomously discovers a vocabulary of primitive operations and uses a differentiable neural executor to interpret variable-length sequences of these primitives. This allows NLI to represent programs that are not bound to a constant number of computation steps, enabling it to solve more complex problems than those seen during training. The same differentiability permits an initial program guess to be refined by gradient descent through the neural executor at inference time.
What carries the argument
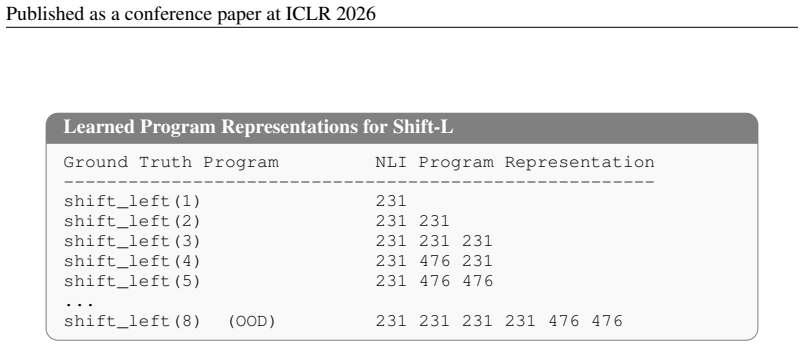
Neural Language Interpreter (NLI) that discovers primitives and executes them via a Gumbel-Softmax-relaxed differentiable neural executor for variable-length programs.
If this is right
- Programs produced by NLI can have arbitrary length and are not limited to the fixed computation depth used in training.
- The same model can be applied to new tasks in the same domain by running a few steps of gradient descent on the program parameters.
- No hand-designed domain-specific language is required because the primitive set is discovered from data.
- Combinatorial generalization improves because the discrete structure is preserved while still being trainable.
Where Pith is reading between the lines
- The approach may reduce the engineering cost of building new program induction systems for each domain.
- Inspecting the learned primitives after training could reveal what the model considers useful building blocks.
- The method might extend to settings where the output is itself a program that must be executed in an external environment.
Load-bearing premise
The Gumbel-Softmax relaxation produces useful gradients for discrete program choices and the neural executor can faithfully interpret sequences of varying length during both training and test-time adaptation.
What would settle it
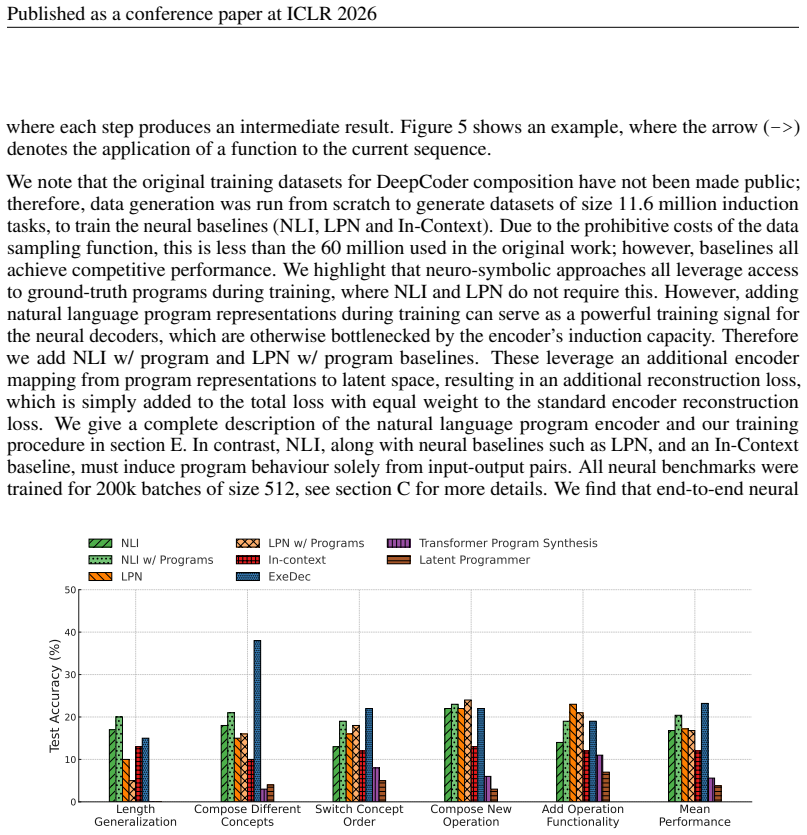
On held-out tasks that require combining known primitives in new ways, NLI's final performance after test-time gradient steps is no better than a non-differentiable program induction baseline or a continuous latent program network.
Figures




read the original abstract
A central challenge in program induction has long been the trade-off between symbolic and neural approaches. Symbolic methods offer compositional generalisation and data efficiency, yet their scalability is constrained by formalisms such as domain-specific languages (DSLs), which are labour-intensive to create and may not transfer to new domains. In contrast, neural networks flexibly learn from data but tend to generalise poorly in compositional and out-of-distribution settings. We bridge this divide with an instance of a Latent Adaptation Network architecture named Neural Language Interpreter (NLI), which learns its own discrete, symbolic-like programming language end-to-end. NLI autonomously discovers a vocabulary of primitive operations and uses a novel differentiable neural executor to interpret variable-length sequences of these primitives. This allows NLI to represent programs that are not bound to a constant number of computation steps, enabling it to solve more complex problems than those seen during training. To make these discrete, compositional program structures amenable to gradient-based optimisation, we employ the Gumbel-Softmax relaxation, enabling the entire model to be trained end-to-end. Crucially, this same differentiability enables powerful test-time adaptation. At inference, NLI's program inductor provides an initial program guess. This guess is then refined via gradient descent through the neural executor, enabling efficient search for the neural program that best explains the given data. We demonstrate that NLI outperforms in-context learning, test-time training, and continuous latent program networks on tasks that require combinatorial generalisation and rapid adaptation to unseen tasks. Our results establish a new path toward models that combine the compositionality of discrete languages with the gradient-based search and end-to-end learning of neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural Language Interpreter (NLI), a Latent Adaptation Network that autonomously discovers a discrete vocabulary of primitive operations and employs a differentiable neural executor to interpret variable-length program sequences. Using Gumbel-Softmax relaxation for end-to-end differentiability, NLI supports gradient-based training and test-time adaptation via gradient descent on an initial program guess, claiming to outperform in-context learning, test-time training, and continuous latent program networks on tasks requiring combinatorial generalization and rapid adaptation to unseen tasks.
Significance. If the empirical outperformance holds, NLI offers a promising bridge between symbolic compositionality and neural gradient-based optimization by learning its own programming language without hand-crafted DSLs, potentially improving data efficiency and generalization in program synthesis and few-shot adaptation settings.
major comments (1)
- Abstract: The central claim that NLI 'outperforms in-context learning, test-time training, and continuous latent program networks on tasks that require combinatorial generalisation and rapid adaptation' is unsupported by any quantitative results, metrics, baselines, error bars, or experimental protocol details, which is load-bearing for verifying whether the Gumbel-Softmax relaxation and neural executor enable the asserted combinatorial generalization.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment regarding the abstract below.
read point-by-point responses
-
Referee: Abstract: The central claim that NLI 'outperforms in-context learning, test-time training, and continuous latent program networks on tasks that require combinatorial generalisation and rapid adaptation' is unsupported by any quantitative results, metrics, baselines, error bars, or experimental protocol details, which is load-bearing for verifying whether the Gumbel-Softmax relaxation and neural executor enable the asserted combinatorial generalization.
Authors: The abstract is intended as a high-level overview of the paper's contributions and results. The detailed quantitative evidence, including metrics, baselines, error bars, and experimental protocols, is provided in the Experiments section of the manuscript, where we compare NLI against in-context learning, test-time training, and continuous latent program networks on combinatorial generalization and rapid adaptation tasks. These results support the claim that the Gumbel-Softmax relaxation and neural executor facilitate the observed performance. To better substantiate the claim within the abstract itself, we will revise it to include a concise reference to the key empirical findings, such as average performance improvements across the evaluated tasks. This constitutes a partial revision as the full details remain in the body of the paper. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes an end-to-end architecture using the standard Gumbel-Softmax relaxation to enable gradient flow through discrete program choices and a neural executor for variable-length interpretation. These are independent, externally established components rather than quantities fitted to the target predictions or defined in terms of the claimed generalization performance. No self-citation load-bearing steps, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation appear in the derivation; the combinatorial generalization claims rest on the described training and test-time adaptation procedure without reducing to input data by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Artificial Intelligence Research , volume=
Program synthesis with best-first bottom-up search , author=. Journal of Artificial Intelligence Research , volume=
-
[2]
Proceedings of the ACM on Programming Languages , volume=
Just-in-time learning for bottom-up enumerative synthesis , author=. Proceedings of the ACM on Programming Languages , volume=. 2020 , publisher=
2020
-
[3]
International Conference on Learning Representations , year=
Categorical Reparameterization with Gumbel-Softmax , author=. International Conference on Learning Representations , year=
-
[4]
Augustus Odena and Kensen Shi and David Bieber and Rishabh Singh and Charles Sutton and Hanjun Dai , booktitle=
-
[5]
Program Generation Using Simulated Annealing and Model Checking
Husien, Idress and Schewe, Sven. Program Generation Using Simulated Annealing and Model Checking. Software Engineering and Formal Methods. 2016
2016
-
[6]
Advances in Neural Information Processing Systems , year =
Neural Discrete Representation Learning , author =. Advances in Neural Information Processing Systems , year =
-
[7]
Transactions on Machine Learning Research , year=
Language Models Speed Up Local Search for Finding Programmatic Policies , author=. Transactions on Machine Learning Research , year=
-
[8]
Proceedings of the 12th international conference on Architectural support for programming languages and operating systems , pages=
Combinatorial sketching for finite programs , author=. Proceedings of the 12th international conference on Architectural support for programming languages and operating systems , pages=
-
[9]
2004 , publisher=
Stochastic Local Search: Foundations and Applications , author=. 2004 , publisher=
2004
-
[10]
International Conference on Machine Learning , pages=
Compile: Compositional imitation learning and execution , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[11]
International Conference on Machine Learning , pages=
Latent programmer: Discrete latent codes for program synthesis , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[12]
arXiv preprint arXiv:2505.17703 , year=
Gradient-Based Program Repair: Fixing Bugs in Continuous Program Spaces , author=. arXiv preprint arXiv:2505.17703 , year=
-
[13]
International Conference on Machine Learning , year=
Neural program synthesis from diverse demonstration videos , author=. International Conference on Machine Learning , year=
-
[14]
Advances in neural information processing systems , volume=
One-shot imitation learning , author=. Advances in neural information processing systems , volume=
-
[15]
Conference on robot learning , year=
One-shot visual imitation learning via meta-learning , author=. Conference on robot learning , year=
-
[16]
Neural task programming: Learning to generalize across hierarchical tasks , author=
-
[17]
International Conference on Machine Learning , year=
Taco: Learning task decomposition via temporal alignment for control , author=. International Conference on Machine Learning , year=
-
[18]
arXiv preprint arXiv:2410.14817 , year=
A Complexity-Based Theory of Compositionality , author=. arXiv preprint arXiv:2410.14817 , year=
-
[19]
arXiv preprint arXiv:2002.01365 , year=
Compositional languages emerge in a neural iterated learning model , author=. arXiv preprint arXiv:2002.01365 , year=
-
[20]
International conference on machine learning , year=
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks , author=. International conference on machine learning , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Ease-of-teaching and language structure from emergent communication , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
arXiv preprint arXiv:1804.03984 , year=
Emergence of linguistic communication from referential games with symbolic and pixel input , author=. arXiv preprint arXiv:1804.03984 , year=
-
[23]
arXiv preprint arXiv:1904.09067 , year=
Emergence of compositional language with deep generational transmission , author=. arXiv preprint arXiv:1904.09067 , year=
-
[24]
2024 , howpublished =
Francois Chollet and Mike Knoop and Bryan Landers and Greg Kamradt and Hansueli Jud and Walter Reade and Addison Howard , title =. 2024 , howpublished =
2024
-
[25]
Journal of the ACM , volume=
A methodology for LISP program construction from examples , author=. Journal of the ACM , volume=
-
[26]
The inference of regular
Biermann, Alan W , journal=. The inference of regular
-
[27]
International Conference on Machine Learning , year=
Differentiable programs with neural libraries , author=. International Conference on Machine Learning , year=
-
[28]
ACM Sigplan Notices , volume=
Automating string processing in spreadsheets using input-output examples , author=. ACM Sigplan Notices , volume=
-
[29]
International conference on machine learning , pages=
Robustfill: Neural program learning under noisy i/o , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[30]
International Conference on Computer Aided Verification , year=
Guiding enumerative program synthesis with large language models , author=. International Conference on Computer Aided Verification , year=
-
[31]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
International Conference on Software Engineering , year=
Jigsaw: Large language models meet program synthesis , author=. International Conference on Software Engineering , year=
-
[33]
International Conference on Machine Learning , pages=
CodeIt: Self-Improving Language Models with Prioritized Hindsight Replay , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[34]
Advances in Neural Information Processing Systems , volume=
Latent execution for neural program synthesis beyond domain-specific languages , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Genetic and Evolutionary Computation Conference Companion , year=
COIL: Constrained optimization in learned latent space: Learning representations for valid solutions , author=. Genetic and Evolutionary Computation Conference Companion , year=
-
[36]
International Conference on Learning Representations , year=
Learning a latent search space for routing problems using variational autoencoders , author=. International Conference on Learning Representations , year=
-
[37]
"Noisier" Noise Contrastive Eestimation is (Almost) Maximum Likelihood
Latent energy-based odyssey: Black-box optimization via expanded exploration in the energy-based latent space , author=. arXiv preprint arXiv:2405.16730 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
International Conference on Machine Learning , year=
Diffusion models for black-box optimization , author=. International Conference on Machine Learning , year=
-
[39]
Advances in Neural Information Processing Systems , year=
Advancing Bayesian optimization via learning correlated latent space , author=. Advances in Neural Information Processing Systems , year=
-
[40]
arXiv preprint arXiv:1608.04428 , year=
Terpret: A probabilistic programming language for program induction , author=. arXiv preprint arXiv:1608.04428 , year=
-
[41]
Automatic chemical design using a data-driven continuous representation of molecules , author=
-
[42]
Advances in Neural Information Processing Systems , year=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems , year=
-
[43]
Advances in Neural Information Processing Systems , volume=
Winner takes it all: Training performant rl populations for combinatorial optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Advances in Neural Information Processing Systems , year=
Combinatorial optimization with policy adaptation using latent space search , author=. Advances in Neural Information Processing Systems , year=
-
[45]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Geometric deep learning: Grids, groups, graphs, geodesics, and gauges , author=. arXiv preprint arXiv:2104.13478 , year=
work page internal anchor Pith review arXiv
-
[46]
Science , volume=
Reducing the dimensionality of data with neural networks , author=. Science , volume=
-
[47]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv preprint arXiv:2303.05510 , year=
Planning with large language models for code generation , author=. arXiv preprint arXiv:2303.05510 , year=
-
[50]
International Conference on Programming Language Design and Implementation , year=
Dreamcoder: Bootstrapping inductive program synthesis with wake-sleep library learning , author=. International Conference on Programming Language Design and Implementation , year=
-
[51]
arXiv preprint arXiv:2305.19555 , year=
Large language models are not strong abstract reasoners , author=. arXiv preprint arXiv:2305.19555 , year=
-
[52]
International Joint Conference on Artificial Intelligence , year=
Version spaces: A candidate elimination approach to rule learning , author=. International Joint Conference on Artificial Intelligence , year=
-
[53]
arXiv preprint arXiv:2311.09247 , year=
Comparing humans, gpt-4, and gpt-4v on abstraction and reasoning tasks , author=. arXiv preprint arXiv:2311.09247 , year=
-
[54]
G., Rao, K., Sadigh, D., and Zeng, A
Large language models as general pattern machines , author=. arXiv preprint arXiv:2307.04721 , year=
-
[55]
arXiv preprint arXiv:2302.09425 , year=
A Neurodiversity-Inspired Solver for the Abstraction & Reasoning Corpus (ARC) Using Visual Imagery and Program Synthesis , author=. arXiv preprint arXiv:2302.09425 , year=
-
[56]
arXiv preprint arXiv:2011.09860 , year=
Neural abstract reasoner , author=. arXiv preprint arXiv:2011.09860 , year=
-
[57]
Spectral Norm Regularization for Improving the Generalizability of Deep Learning
Spectral norm regularization for improving the generalizability of deep learning , author=. arXiv preprint arXiv:1705.10941 , year=
-
[58]
arXiv preprint arXiv:2106.05126 , year=
Efficient active search for combinatorial optimization problems , author=. arXiv preprint arXiv:2106.05126 , year=
-
[59]
The conceptarc benchmark: Evaluating understanding and generalization in the arc domain , author=. arXiv preprint arXiv:2305.07141 , year=
-
[60]
Fast and flexible: Human program induction in abstract reasoning tasks , author=. arXiv preprint arXiv:2103.05823 , year=
-
[61]
Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L
Embers of autoregression: Understanding large language models through the problem they are trained to solve , author=. arXiv preprint arXiv:2309.13638 , year=
-
[62]
arXiv preprint arXiv:2202.07206 , year=
Impact of pretraining term frequencies on few-shot reasoning , author=. arXiv preprint arXiv:2202.07206 , year=
-
[63]
arXiv preprint arXiv:2310.02227 (2023)
Snip: Bridging mathematical symbolic and numeric realms with unified pre-training , author=. arXiv preprint arXiv:2310.02227 , year=
-
[64]
2024 , eprint=
Tackling the Abstraction and Reasoning Corpus with Vision Transformers: the Importance of 2D Representation, Positions, and Objects , author=. 2024 , eprint=
2024
-
[65]
2024 , eprint=
Addressing the Abstraction and Reasoning Corpus via Procedural Example Generation , author=. 2024 , eprint=
2024
-
[66]
Information processing letters , volume=
Occam's razor , author=. Information processing letters , volume=. 1987 , publisher=
1987
-
[67]
Automatica , volume=
Modeling by shortest data description , author=. Automatica , volume=. 1978 , publisher=
1978
-
[68]
Understanding disentangling in $\beta$-VAE
Understanding disentangling in -VAE , author=. arXiv preprint arXiv:1804.03599 , year=
-
[69]
Nature , volume=
Deep learning , author=. Nature , volume=
-
[70]
1994 , publisher=
Karel the robot: a gentle introduction to the art of programming , author=. 1994 , publisher=
1994
-
[71]
arXiv preprint arXiv:2410.12166 , year=
Reclaiming the source of programmatic policies: Programmatic versus latent spaces , author=. arXiv preprint arXiv:2410.12166 , year=
-
[72]
Advances in Neural Information Processing Systems , volume=
Learning to synthesize programs as interpretable and generalizable policies , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
Neural Sketch Learning for Conditional Program Generation
Neural sketch learning for conditional program generation , author=. arXiv preprint arXiv:1703.05698 , year=
-
[74]
IJCAI , pages=
Limited discrepancy beam search , author=. IJCAI , pages=
-
[75]
Learning Meets Combinatorial Algorithms at NeurIPS2020 , year=
Continuous latent search for combinatorial optimization , author=. Learning Meets Combinatorial Algorithms at NeurIPS2020 , year=
-
[76]
2011 , publisher=
Kahneman, Daniel , title=. 2011 , publisher=
2011
-
[77]
Completely Derandomized Self-Adaptation in Evolution Strategies , year=
Hansen, Nikolaus and Ostermeier, Andreas , journal=. Completely Derandomized Self-Adaptation in Evolution Strategies , year=
-
[78]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[79]
Jonathan Heek and Anselm Levskaya and Avital Oliver and Marvin Ritter and Bertrand Rondepierre and Andreas Steiner and Marc van
-
[80]
2019 , eprint=
Adaptive Input Representations for Neural Language Modeling , author=. 2019 , eprint=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.