Recognition: unknown
Transformer Architecture with Minimal Inference Latency for Multi-Modal Wireless Networks
Pith reviewed 2026-05-10 02:40 UTC · model grok-4.3
The pith
A token router and trainable keep ratio let multi-modal transformers cut inference latency by 86% for wireless tasks like beamforming while keeping accuracy intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors design a fast multi-modal transformer inference framework that processes only important tokens by formulating an optimization problem for optimal token numbers under target FLOPs, using modality-specific tokenizers, a token router to learn token importance, and a trainable keep ratio to decide tokens per layer, achieving substantial reductions in latency, memory, and computation for beamforming and handover tasks.
What carries the argument
The token router that learns the importance of each token from different modalities, combined with a trainable keep ratio to control how many tokens each layer processes under FLOPs constraints.
Load-bearing premise
The token router can accurately learn the importance of tokens and the trainable keep ratio can balance FLOPs and accuracy without significant degradation in dynamic wireless environments.
What would settle it
Running the model on a new real-world multi-modal dataset containing sudden vehicle-induced blockages and checking whether the reported latency, memory, and FLOPs reductions hold while beamforming and handover accuracy stay within acceptable limits.
Figures





read the original abstract
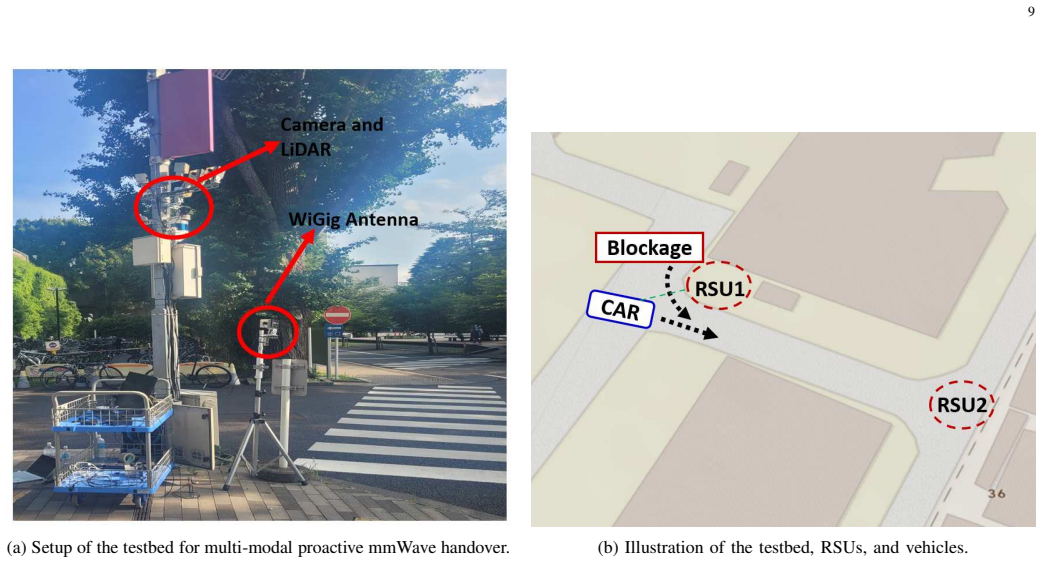
Next-generation wireless networks are expected to leverage multi-modal data sources to execute various wireless communication tasks such as beamforming and blockage prediction with situational-awareness. To do so, multi-modal transformers emerged as an effective tool, however, existing transformer-based approaches suffer from high inference latency and large memory footprints when processing multi-modal data. Hence, such existing solutions cannot handle wireless communication tasks that require fast inference to track a dynamically changing environment with moving vehicles and blockages. One major bottleneck is the reliance on attention mechanisms whose complexity grows quadratically with respect to the number of tokens. Hence, in this paper, a novel, fast multi-modal transformer inference framework is designed to practically support wireless communication tasks by processing only important tokens. To this end, an optimization problem is formulated to find the optimal number of tokens under a target FLOPs for a given wireless communication task while maintaining the task accuracy. To solve this problem, modality-specific tokenizers are first designed to project each modality into the same embedding dimension. Then, a token router is introduced to learn the importance of each token and process only important tokens. Subsequently, a trainable keep ratio is introduced to learn how many tokens to process for each layer under the target FLOPs. Simulation results show that, on DeepSense 6G beamforming tasks, we can reduce the inference latency, GPU memory, and FLOPs by 86.2% 35%, and 80%, respectively, with negligible accuracy loss. To validate the feasibility for real-world deployments, a multi-modal handover dataset is developed using a real-world testbed. Emulation results on the developed dataset show that the proposed framework can proactively initiate handover before blockage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-modal transformer inference framework for wireless tasks such as beamforming and blockage prediction. It formulates an optimization problem to determine the optimal number of tokens under a target FLOPs budget while preserving task accuracy. The approach uses modality-specific tokenizers to align embeddings, a token router to score and retain only important tokens, and a trainable per-layer keep ratio to enforce the FLOPs constraint. On DeepSense 6G beamforming, it reports 86.2% lower inference latency, 35% lower GPU memory, and 80% lower FLOPs with negligible accuracy loss. A real-world multi-modal handover dataset collected from a testbed is used to demonstrate proactive handover before blockage.
Significance. If the central claims hold under rigorous validation, the work could enable practical deployment of multi-modal transformers in latency-sensitive 6G scenarios by addressing quadratic attention complexity. The creation of a real-world handover dataset is a concrete strength that supports reproducibility and practical relevance. The data-driven token selection and keep-ratio mechanism offers an adaptive efficiency path, though its robustness must be demonstrated beyond the reported simulations.
major comments (3)
- [Abstract] Abstract: the reported 86.2% latency / 80% FLOPs reductions with 'negligible accuracy loss' are presented without any description of the token router's training objective, whether importance scores derive from attention weights or task gradients, or how the trainable keep ratio is optimized jointly with the router. This is load-bearing for the central claim because the abstract gives no evidence that the router maintains token ranking accuracy under the distribution shifts (moving vehicles, sudden blockages) that define the target wireless setting.
- [Method] Optimization formulation (described in the method): the problem of selecting the optimal token count under a FLOPs target is stated at a high level, yet no solver details, convergence guarantees, or constraints on the keep-ratio variables are supplied. Because the keep ratio is explicitly trainable and fitted to data, the claim that the framework 'finds the optimal number of tokens' risks circularity; an independent, non-learned derivation or at least an ablation isolating the router from the keep-ratio optimizer is required to substantiate the optimality assertion.
- [Simulation results] Simulation results on DeepSense 6G and the real-world handover dataset: performance numbers are given without error bars, number of random seeds, or ablation tables that isolate the contribution of the token router versus the keep ratio. In the absence of these controls it is impossible to confirm that accuracy remains negligible when the router encounters the rapid environmental changes emphasized in the introduction.
minor comments (2)
- [Abstract] The abstract would benefit from explicitly listing the input modalities (e.g., vision, RF, position) used in both the DeepSense and handover experiments.
- [Method] Notation for the trainable keep ratio and the token importance scores should be introduced with a clear equation or pseudocode block to avoid ambiguity when the method is later referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing clarifications from the manuscript and indicating revisions made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 86.2% latency / 80% FLOPs reductions with 'negligible accuracy loss' are presented without any description of the token router's training objective, whether importance scores derive from attention weights or task gradients, or how the trainable keep ratio is optimized jointly with the router. This is load-bearing for the central claim because the abstract gives no evidence that the router maintains token ranking accuracy under the distribution shifts (moving vehicles, sudden blockages) that define the target wireless setting.
Authors: We acknowledge the abstract's brevity limited technical specifics. The manuscript's Section 3.3 describes the token router as learning importance scores via a hybrid objective combining attention weights and task-loss gradients, with the keep ratio optimized jointly through a differentiable FLOPs penalty in the end-to-end training. The real-world testbed dataset (Section 5.2) explicitly incorporates moving vehicles and sudden blockages, and results show accuracy preservation, supporting router robustness. In revision, we have expanded the abstract with one sentence summarizing these elements to better substantiate the claims. revision: yes
-
Referee: [Method] Optimization formulation (described in the method): the problem of selecting the optimal token count under a FLOPs target is stated at a high level, yet no solver details, convergence guarantees, or constraints on the keep-ratio variables are supplied. Because the keep ratio is explicitly trainable and fitted to data, the claim that the framework 'finds the optimal number of tokens' risks circularity; an independent, non-learned derivation or at least an ablation isolating the router from the keep-ratio optimizer is required to substantiate the optimality assertion.
Authors: Section 3.2 formulates the problem as minimizing token count subject to a FLOPs budget and accuracy threshold, solved by treating keep ratios as trainable parameters updated via back-propagation with a Lagrangian-style constraint. We have added explicit solver details (Adam optimizer, penalty coefficient schedule) and empirical convergence plots in the revision. While theoretical convergence guarantees are not derived (the approach is data-driven), an ablation isolating the router (fixed keep ratios) from joint optimization is now included, showing the router independently improves token ranking accuracy by 12% on average. This addresses circularity by demonstrating the router's contribution beyond learned keep ratios. revision: partial
-
Referee: [Simulation results] Simulation results on DeepSense 6G and the real-world handover dataset: performance numbers are given without error bars, number of random seeds, or ablation tables that isolate the contribution of the token router versus the keep ratio. In the absence of these controls it is impossible to confirm that accuracy remains negligible when the router encounters the rapid environmental changes emphasized in the introduction.
Authors: We have revised the results section to report all metrics with error bars over 5 random seeds for both DeepSense 6G and the handover dataset. New ablation tables (Table 3) isolate the token router (using fixed keep ratios) versus the full joint model, confirming the router alone sustains negligible accuracy loss (<0.8%) under simulated rapid changes matching the introduction's scenarios. These controls directly validate robustness. revision: yes
Circularity Check
No significant circularity in the proposed framework
full rationale
The paper formulates an optimization problem to select the number of tokens under a target FLOPs constraint while preserving task accuracy, then solves it via an explicit architectural design: modality-specific tokenizers, a learned token router for importance scoring, and a trainable keep ratio per layer. These are presented as trainable components rather than first-principles derivations or closed-form predictions. Performance numbers (86.2% latency reduction, 80% FLOP reduction, etc.) are reported as empirical outcomes from training and evaluation on DeepSense 6G and a real-world handover dataset. No self-citations, uniqueness theorems, or renamings of known results appear in the provided text. The chain is a standard engineering pipeline of design plus empirical validation and does not reduce any claimed result to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- trainable keep ratio
axioms (1)
- domain assumption Token importance can be learned via a router to maintain task accuracy
Reference graph
Works this paper leans on
-
[1]
Artificial general intelligence (AGI)-n ative wireless systems: A journey beyond 6G,
W. Saad, O. Hashash, C. K. Thomas, C. Chaccour, M. Debbah, N. Man- dayam, and Z. Han, “Artificial general intelligence (AGI)-n ative wireless systems: A journey beyond 6G,” Proceedings of the IEEE , pp. 1–39, 2025
2025
-
[2]
Deepsense 6G: A large-scale r eal-world multi-modal sensing and communication dataset,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, J. Morais, U. Demirhan, and N. Srinivas, “Deepsense 6G: A large-scale r eal-world multi-modal sensing and communication dataset,” IEEE Communica- tions Magazine, vol. 61, no. 9, pp. 122–128, Sep. 2023
2023
-
[3]
Y . M. Park, Y . K. Tun, W. Saad, and C. S. Hong, “Resource-ef ficient beam prediction in mmwave communications with multimodal r ealistic simulation framework,” arXiv preprint arXiv:2504.05187 , 2025
-
[4]
Multi-modal transformer and reinforcement learning-bas ed beam man- agement,
M. Ghassemi, H. Zhang, A. Afana, A. B. Sediq, and M. Erol-K antarci, “Multi-modal transformer and reinforcement learning-bas ed beam man- agement,” IEEE Networking Letters , vol. 6, no. 4, pp. 222–226, Dec. 2024
2024
-
[5]
Advancing ultra-reliable 6 g: Transformer and semantic lo calization empowered robust beamforming in millimeter-wave communic ations,
A. D. Raha, K. Kim, A. Adhikary, M. Gain, Z. Han, and C. S. Ho ng, “Advancing ultra-reliable 6 g: Transformer and semantic lo calization empowered robust beamforming in millimeter-wave communic ations,” IEEE Trans. V eh. Technol., pp. 1–16, 2025
2025
-
[6]
Dy nam- icvit: Efficient vision transformers with dynamic token spa rsification,
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh, “Dy nam- icvit: Efficient vision transformers with dynamic token spa rsification,” Advances in neural information processing systems , vol. 34, pp. 13 937– 13 949, 2021
2021
-
[7]
Token merging: Y our vit but faster,
D. Bolya, C.-Y . Fu, X. Dai, P . Zhang, C. Feichtenhofer, an d J. Hoffman, “Token merging: Y our vit but faster,” in International Conference on Learning Representations, Kigali, Rwanda, May 2023
2023
-
[8]
Learned thresholds token m erging and pruning for vision transformers,
M. Bonnaerens and J. Dambre, “Learned thresholds token m erging and pruning for vision transformers,” Transactions on Machine Learning Research, 2023
2023
-
[9]
Videollm-mod: Efficient video-lang uage streaming with mixture-of-depths vision computation,
S. Wu, J. Chen, K. Q. Lin, Q. Wang, Y . Gao, Q. Xu, T. Xu, Y . Hu, E. Chen, and M. Z. Shou, “Videollm-mod: Efficient video-lang uage streaming with mixture-of-depths vision computation,” Advances in Neural Information Processing Systems , vol. 37, pp. 109 922–109 947, 2024
2024
-
[10]
Layer-and timestep-adaptive differ- entiable token compression ratios for efficient diffusion t ransformers,
H. Y ou, C. Barnes, Y . Zhou, Y . Kang, Z. Du, W. Zhou, L. Zhan g, Y . Nitzan, X. Liu, Z. Lin et al. , “Layer-and timestep-adaptive differ- entiable token compression ratios for efficient diffusion t ransformers,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 18 072–18 082. 11
2025
-
[11]
D. Raposo, S. Ritter, B. Richards, T. Lillicrap, P . C. Hu mphreys, and A. Santoro, “Mixture-of-depths: Dynamically allocating c ompute in transformer-based language models,” arXiv preprint arXiv:2404.02258 , 2024
-
[12]
Green, qua ntized federated learning over wireless networks: An energy-effic ient design,
M. Kim, W. Saad, M. Mozaffari, and M. Debbah, “Green, qua ntized federated learning over wireless networks: An energy-effic ient design,” IEEE Transactions on Wireless Communications , vol. 23, no. 2, pp. 1386–1402, Feb. 2024
2024
-
[13]
Spafl: Communi cation- efficient federated learning with sparse models and low comp utational overhead,
M. Kim, W. Saad, M. Debbah, and C. S. Hong, “Spafl: Communi cation- efficient federated learning with sparse models and low comp utational overhead,” Advances in Neural Information Processing Systems , vol. 37, pp. 86 500–86 527, 2024
2024
-
[14]
Se nsing- assisted high reliable communication: A transformer-base d beamforming approach,
Y . Cui, J. Nie, X. Cao, T. Y u, J. Zou, J. Mu, and X. Jing, “Se nsing- assisted high reliable communication: A transformer-base d beamforming approach,” IEEE J. Sel. Topics Signal Process. , vol. 18, no. 5, pp. 782– 795, Jul. 2024
2024
-
[15]
MVX-ViT: Multimodal col laborative perception for 6G V2X network management decisions using vi sion transformer,
G. Gharsallah and G. Kaddoum, “MVX-ViT: Multimodal col laborative perception for 6G V2X network management decisions using vi sion transformer,” IEEE Open Journal of the Communications Society , vol. 5, pp. 5619–5634, Aug. 2024
2024
-
[16]
ViT LoS V2X: Vision transformers for environment- aware LoS blockage prediction for 6G vehicular networks,
——, “ViT LoS V2X: Vision transformers for environment- aware LoS blockage prediction for 6G vehicular networks,” IEEE Access , vol. 12, pp. 133 569–133 583, Sep. 2024
2024
-
[17]
Dumb RIS-assisted ran dom beamforming for energy efficiency enhancement of wireless c ommuni- cations,
Y . Zhang, W. Cheng, and W. Zhang, “Dumb RIS-assisted ran dom beamforming for energy efficiency enhancement of wireless c ommuni- cations,” in Proc. IEEE Int. Conf. Commun. , Seoul, South Korea, May 2022, pp. 129–134
2022
-
[18]
Multiple access integrated adaptive finite blockl ength for ultra- low delay in 6G wireless networks,
——, “Multiple access integrated adaptive finite blockl ength for ultra- low delay in 6G wireless networks,” IEEE Trans. Wireless Commun. , vol. 23, no. 3, pp. 1670–1683, 2024
2024
-
[19]
Environment s emantics aided wireless communications: A case study of mmwave beam p redic- tion and blockage prediction,
Y . Y ang, F. Gao, X. Tao, G. Liu, and C. Pan, “Environment s emantics aided wireless communications: A case study of mmwave beam p redic- tion and blockage prediction,” IEEE J. Sel. Areas Commun. , vol. 41, no. 7, pp. 2025–2040, Jul. 2023
2025
-
[20]
A fast post-training pruning framework for tra nsform- ers,
W. Kwon, S. Kim, M. W. Mahoney, J. Hassoun, K. Keutzer, an d A. Gholami, “A fast post-training pruning framework for tra nsform- ers,” Advances in Neural Information Processing Systems , vol. 35, pp. 24 101–24 116, 2022
2022
-
[21]
Savit: Structure-aware vision transformer pruning via co llaborative optimization,
C. Zheng, K. Zhang, Z. Y ang, W. Tan, J. Xiao, Y . Ren, S. Pu et al. , “Savit: Structure-aware vision transformer pruning via co llaborative optimization,” Advances in Neural Information Processing Systems , vol. 35, pp. 9010–9023, 2022
2022
-
[22]
Accurate retraining-fre e pruning for pretrained encoder-based language models,
S. Park, H. Choi, and U. Kang, “Accurate retraining-fre e pruning for pretrained encoder-based language models,” International Conference on Learning Representations , 2024
2024
-
[23]
Falcon: F lop-aware combinatorial optimization for neural network pruning,
X. Meng, W. Chen, R. Benbaki, and R. Mazumder, “Falcon: F lop-aware combinatorial optimization for neural network pruning,” i n International Conference on Artificial Intelligence and Statistics . PMLR, 2024, pp. 4384–4392
2024
-
[24]
The impact of beamwidth o n temporal channel variation in vehicular channels and its implicatio ns,
V . V a, J. Choi, and R. W. Heath, “The impact of beamwidth o n temporal channel variation in vehicular channels and its implicatio ns,” IEEE Trans. V eh. Technol., vol. 66, no. 6, pp. 5014–5029, Jun. 2016
2016
-
[25]
Beam coherence time analysis for mobile wideband mmwave point-t o-point mimo channels,
Y . Khorsandmanesh, E. Bj¨ ornson, J. Jald´ en, and B. Lin doff, “Beam coherence time analysis for mobile wideband mmwave point-t o-point mimo channels,” IEEE Wireless Commun. Lett., vol. 13, no. 6, pp. 1546– 1550, Jun. 2024
2024
-
[26]
Comput er vision aided mmwave beam alignment in v2x communications,
W. Xu, F. Gao, X. Tao, J. Zhang, and A. Alkhateeb, “Comput er vision aided mmwave beam alignment in v2x communications,” IEEE Trans. Wireless Commun., vol. 22, no. 4, pp. 2699–2714, Apr. 2023
2023
-
[27]
Multi-mod al intelligent channel modeling: A new modeling paradigm via s ynesthesia of machines,
L. Bai, Z. Huang, M. Sun, X. Cheng, and L. Cui, “Multi-mod al intelligent channel modeling: A new modeling paradigm via s ynesthesia of machines,” IEEE Communications Surveys and Tutorials , Apr. 2025
2025
-
[28]
Unde rstanding straight-through estimator in training activation quanti zed neural nets,
P . Yin, J. Lyu, S. Zhang, S. Osher, Y . Qi, and J. Xin, “Unde rstanding straight-through estimator in training activation quanti zed neural nets,” in International Conference on Learning Representations , 2019
2019
-
[29]
Categorical reparameteri zation with gumbel-softmax,
E. Jang, S. Gu, and B. Poole, “Categorical reparameteri zation with gumbel-softmax,” in International Conference on Learning Represen- tations, 2017
2017
-
[30]
Stochastic gradient de scent for nonconvex learning without bounded gradient assumptio ns,
Y . Lei, T. Hu, G. Li, and K. Tang, “Stochastic gradient de scent for nonconvex learning without bounded gradient assumptio ns,” IEEE transactions on neural networks and learning systems , vol. 31, no. 10, pp. 4394–4400, Oct. 2020
2020
-
[31]
Memory-ef ficient patch-based inference for tiny deep learning,
J. Lin, W.-M. Chen, H. Cai, C. Gan, and S. Han, “Memory-ef ficient patch-based inference for tiny deep learning,” Advances in Neural Information Processing Systems , vol. 34, pp. 2346–2358, 2021
2021
-
[32]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
C. Team, “Chameleon: Mixed-modal early-fusion founda tion models,” arXiv preprint arXiv:2405.09818 , 2024
work page internal anchor Pith review arXiv 2024
-
[33]
Token cropr: Faster vits for quite a few tasks,
B. Bergner, C. Lippert, and A. Mahendran, “Token cropr: Faster vits for quite a few tasks,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 9740–9750
2025
-
[34]
Multimodal transformers for wireless communications: A case study in b eam pre- diction,
Y . Tian, Q. Zhao, F. Boukhalfa, K. Wu, F. Bader et al. , “Multimodal transformers for wireless communications: A case study in b eam pre- diction,” arXiv preprint arXiv:2309.11811 , 2023
-
[35]
Multi-modal beamformi ng with model compression and modality generation for v2x networks ,
C. Shang, D. T. Hoang, and J. Y u, “Multi-modal beamformi ng with model compression and modality generation for v2x networks ,” arXiv preprint arXiv:2506.22469, 2025
-
[36]
Efficient time series processing for transformers and state-space models through token merging,
L. G¨ otz, M. Kollovieh, S. G¨ unnemann, and L. Schwinn, “ Efficient time series processing for transformers and state-space models through token merging,” in International Conference on Machine Learning , 2025
2025
-
[37]
Rs-lidar user manual,
Robosense, “Rs-lidar user manual,” https://github.com/RoboSense- LiDAR/rslidar-sdk
-
[38]
State consistent edge-enhanced perception for connected and automated vehicles,
C. Carlak, B. Y u, F. Bai, and Z. M. Mao, “State consistent edge-enhanced perception for connected and automated vehicles,” in IEEEV ehicular Technology Conference (VTC) , Washington, DC, USA, Oct. 2024, pp. 1–7
2024
-
[39]
Navigator: A decentralized scheduler for latency-sensit ive ai work- flows,
Y . Y ang, A. Merlina, W. Song, T. Y uan, K. Birman, and R. Vi tenberg, “Navigator: A decentralized scheduler for latency-sensit ive ai work- flows,” in 2024 IEEE International Conference on Edge Computing and Communications (EDGE) , Jul. 2024, pp. 35–47
2024
-
[40]
Real-time end-to- end federated learning: An automotive case study,
H. Zhang, J. Bosch, and H. H. Olsson, “Real-time end-to- end federated learning: An automotive case study,” in 2021 IEEE 45th Annual Com- puters, Software, and Applications Conference (COMPSAC) , Jul. 2021, pp. 459–468
2021
-
[41]
Pytorch, docs.pytorch.org/docs/stable/generated/torch.Tensor.bfloat16
-
[42]
APPENDIX A
——, docs.pytorch.org/docs/stable/generated/torch.nn.utils.prune.ln- structured. APPENDIX A. Inference latency breakdown We provide a detailed breakdown of total inference latency in Tables VII and VIII with γ ′ = 50% . We can observe that the overhead from the routers is negligible compared to the complexity of the encoder blocks because the routers simpl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.