Recognition: unknown
Mechanistic Anomaly Detection via Functional Attribution
Pith reviewed 2026-05-10 02:56 UTC · model grok-4.3
The pith
A neural network's output can be checked for anomalous internal mechanisms by measuring how much it depends on a small trusted reference set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By quantifying the functional influence of samples from a trusted reference set on a test input's output via influence functions and parameter-space sampling, attribution failure indicates that the model is relying on anomalous internal mechanisms rather than normal learned behavior.
What carries the argument
Influence functions that measure functional coupling between a test sample and a trusted reference set through parameter-space sampling.
If this is right
- State-of-the-art detection of seven backdoor attacks across four vision datasets with average DER of 0.93.
- Improved detection of backdoors in LLMs, including explicitly obfuscated cases.
- Detection of adversarial and out-of-distribution samples without modality-specific changes.
- Ability to distinguish multiple distinct anomalous mechanisms operating inside one model.
Where Pith is reading between the lines
- The method could support continuous monitoring of deployed models by maintaining a small trusted reference set and flagging outputs that cannot be attributed to it.
- Because the approach is modality-agnostic, it may unify detection of anomalies that previously required separate tools for vision and language models.
- If attribution failure reliably tracks mechanism shifts, the technique might help identify when fine-tuning or updates introduce unintended behaviors.
- Extending the reference set size or sampling strategy could be tested to see whether it improves robustness against sophisticated obfuscation.
Load-bearing premise
Weak attribution to the trusted reference set specifically signals anomalous internal mechanisms rather than other factors such as high uncertainty or ordinary distribution shift.
What would settle it
A controlled test where a model with a known backdoor or adversarial trigger still shows strong influence-function attribution to the trusted set, or where normal samples produce weak attribution without any anomaly present.
Figures







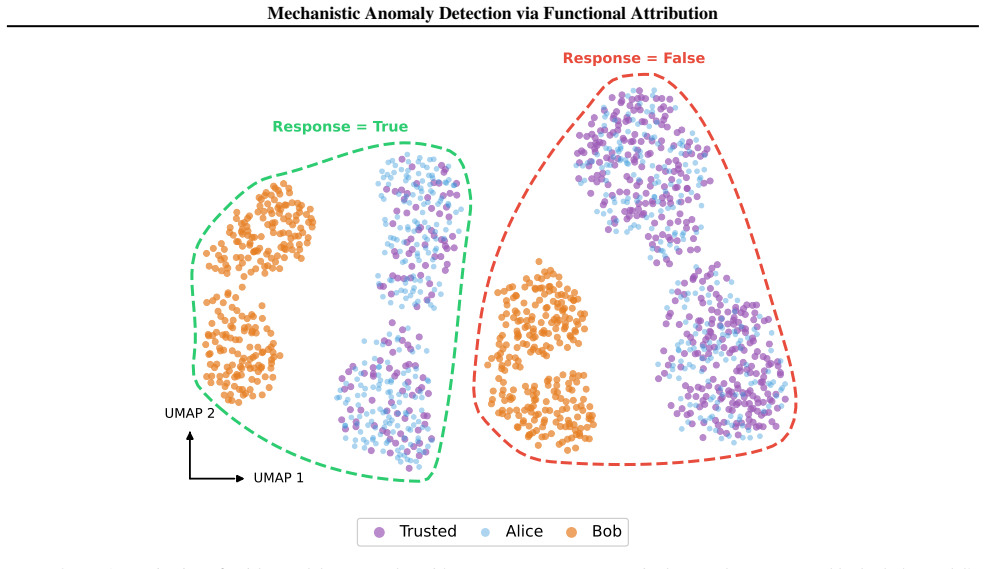
read the original abstract
We can often verify the correctness of neural network outputs using ground truth labels, but we cannot reliably determine whether the output was produced by normal or anomalous internal mechanisms. Mechanistic anomaly detection (MAD) aims to flag these cases, but existing methods either depend on latent space analysis, which is vulnerable to obfuscation, or are specific to particular architectures and modalities. We reframe MAD as a functional attribution problem: asking to what extent samples from a trusted set can explain the model's output, where attribution failure signals anomalous behavior. We operationalize this using influence functions, measuring functional coupling between test samples and a small reference set via parameter-space sampling. We evaluate across multiple anomaly types and modalities. For backdoors in vision models, our method achieves state-of-the-art detection on BackdoorBench, with an average Defense Effectiveness Rating (DER) of 0.93 across seven attacks and four datasets (next best 0.83). For LLMs, we similarly achieve a significant improvement over baselines for several backdoor types, including on explicitly obfuscated models. Beyond backdoors, our method can detect adversarial and out-of-distribution samples, and distinguishes multiple anomalous mechanisms within a single model. Our results establish functional attribution as an effective, modality-agnostic tool for detecting anomalous behavior in deployed models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reframes mechanistic anomaly detection (MAD) as a functional attribution problem: it uses influence functions with parameter-space sampling to measure the extent to which a small trusted reference set explains a test sample's output, interpreting attribution failure as evidence of anomalous internal mechanisms. The approach is evaluated on backdoors in vision models (SOTA average DER 0.93 on BackdoorBench across 7 attacks and 4 datasets), LLMs (including obfuscated models), adversarial examples, OOD samples, and distinguishing multiple anomaly types within one model.
Significance. If the central claim holds, the work would provide a modality-agnostic and architecture-independent tool for MAD that avoids latent-space analysis and works on obfuscated models. The reported benchmark gains and ability to handle multiple anomaly types would make it a practical addition to deployed-model monitoring, especially if the functional-attribution framing proves more robust than prior latent or architecture-specific methods.
major comments (2)
- [Abstract] Abstract: The load-bearing claim is that attribution failure via influence functions specifically signals anomalous internal mechanisms. However, influence functions (even with sampling) are known to produce low coupling scores under high predictive uncertainty or distribution shift even for clean models; the manuscript does not provide controls or ablations showing that the method isolates mechanistic anomalies from these other sources, despite also claiming detection of adversarial and OOD inputs.
- [Methodology and evaluation sections] Methodology and evaluation sections: The construction and size of the trusted reference set are central to the functional-coupling score, yet the manuscript lacks detailed ablations on reference-set selection, sensitivity to its composition, and error analysis of the influence-function approximations. These omissions make it difficult to assess whether the reported DER gains (0.93 vs. 0.83) are robust or depend on favorable reference-set choices.
minor comments (2)
- [Abstract] Abstract: Reporting only the average DER without per-attack/per-dataset breakdowns or confidence intervals in the main text reduces the ability to judge consistency of the improvement.
- [Methods] The description of 'parameter-space sampling' for influence functions would benefit from explicit implementation details (number of samples, sampling distribution, Hessian approximation) to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our work on functional attribution for mechanistic anomaly detection. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim is that attribution failure via influence functions specifically signals anomalous internal mechanisms. However, influence functions (even with sampling) are known to produce low coupling scores under high predictive uncertainty or distribution shift even for clean models; the manuscript does not provide controls or ablations showing that the method isolates mechanistic anomalies from these other sources, despite also claiming detection of adversarial and OOD inputs.
Authors: We acknowledge that influence functions can yield low coupling scores in the presence of high predictive uncertainty or distribution shift, even for models without mechanistic anomalies. Our method is intended to detect functional anomalies more broadly, encompassing both internal mechanistic changes (such as backdoors) and other forms of anomalous behavior like adversarial examples and OOD samples. To address the need for better isolation of mechanistic anomalies, we will add targeted controls and ablations in the revised manuscript. These will evaluate the functional coupling score on clean models under controlled levels of uncertainty and non-mechanistic distribution shifts, allowing direct comparison to scores from backdoored or otherwise mechanistically altered models. We will also revise the abstract and introduction to clarify the scope of anomalies detected by the approach. revision: yes
-
Referee: [Methodology and evaluation sections] Methodology and evaluation sections: The construction and size of the trusted reference set are central to the functional-coupling score, yet the manuscript lacks detailed ablations on reference-set selection, sensitivity to its composition, and error analysis of the influence-function approximations. These omissions make it difficult to assess whether the reported DER gains (0.93 vs. 0.83) are robust or depend on favorable reference-set choices.
Authors: We agree that additional analysis of the trusted reference set and influence function approximations is needed to demonstrate robustness. In the revised manuscript, we will include new ablations that systematically vary the size and composition of the reference set, using strategies such as random sampling, class-balanced selection, and feature-stratified selection. We will report how the Defense Effectiveness Rating and other metrics change under these variations. We will also add an error analysis of the influence function approximations, including comparisons to exact computations where feasible (e.g., on smaller models) and assessments of variance across different sampling configurations. These additions will help confirm that the reported performance improvements hold across reasonable reference set choices. revision: yes
Circularity Check
No significant circularity; method uses standard influence functions with empirical validation
full rationale
The paper reframes MAD as functional attribution and operationalizes it with influence functions plus parameter-space sampling. This builds directly on established prior techniques without self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. Performance claims (e.g., DER 0.93 on BackdoorBench) are empirical results on public benchmarks, not reductions by construction. The derivation chain is self-contained against external methods and data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Influence functions accurately approximate the functional effect of reference samples on model outputs for anomaly detection purposes.
Reference graph
Works this paper leans on
-
[1]
Mechanistic Anomaly Detection and
Christiano, Paul and Xu, Mark , year=. Mechanistic Anomaly Detection and
-
[2]
and Maxwell, Tim and Cheng, Newton and others , journal=
Hubinger, Evan and Denison, Carson and Mu, Jesse and Lambert, Mike and Tong, Meg and MacDiarmid, Monte and Lanham, Tamera and Ziegler, Daniel M. and Maxwell, Tim and Cheng, Newton and others , journal=. Sleeper Agents: Training Deceptive
-
[3]
arXiv preprint arXiv:1906.01820 , year =
Risks from Learned Optimization in Advanced Machine Learning Systems , author=. arXiv preprint arXiv:1906.01820 , year=
-
[4]
International Conference on Learning Representations Workshop on Mathematical and Empirical Understanding of Foundation Models , year=
Eliciting Latent Knowledge from Quirky Language Models , author=. International Conference on Learning Representations Workshop on Mathematical and Empirical Understanding of Foundation Models , year=
-
[5]
International Conference on Learning Representations , year=
van der Weij, Teun and Hofst. International Conference on Learning Representations , year=
-
[6]
Advances in Neural Information Processing Systems , year=
Noise Injection Reveals Hidden Capabilities of Sandbagging Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[7]
Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Annotation Artifacts in Natural Language Inference Data , author=. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
-
[8]
International Conference on Learning Representations , year=
Progress Measures for Grokking via Mechanistic Interpretability , author=. International Conference on Learning Representations , year=
-
[9]
Nature Machine Intelligence , volume=
Shortcut Learning in Deep Neural Networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[10]
International Conference on Learning Representations , year=
Revisiting the Assumption of Latent Separability for Backdoor Defenses , author=. International Conference on Learning Representations , year=
-
[11]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Detecting Adversarial Samples Using Influence Functions and Nearest Neighbors , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
European Conference on Artificial Intelligence , year=
Be Persistent: Towards a Unified Solution for Mitigating Shortcuts in Deep Learning , author=. European Conference on Artificial Intelligence , year=
-
[13]
arXiv preprint arXiv:2202.05189 , year=
Understanding Rare Spurious Correlations in Neural Networks , author=. arXiv preprint arXiv:2202.05189 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Pretraining Task Diversity and the Emergence of Non-Bayesian In-Context Learning for Regression , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
European Conference on Computer Vision , year=
Flatness-Aware Sequential Learning Generates Resilient Backdoors , author=. European Conference on Computer Vision , year=
-
[16]
2019 , publisher=
Gu, Tianyu and Liu, Kang and Dolan-Gavitt, Brendan and Garg, Siddharth , journal=. 2019 , publisher=
2019
-
[17]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning , author=. arXiv preprint arXiv:1712.05526 , year=
work page internal anchor Pith review arXiv
-
[18]
Nguyen, Tuan Anh and Tran, Anh Tuan , booktitle=
-
[19]
A New Backdoor Attack in
Barni, Mauro and Kallas, Kassem and Tondi, Benedetta , booktitle=. A New Backdoor Attack in
-
[20]
IEEE/CVF International Conference on Computer Vision , pages=
Invisible Backdoor Attack with Sample-Specific Triggers , author=. IEEE/CVF International Conference on Computer Vision , pages=
-
[21]
Wang, Zhenting and Zhai, Juan and Ma, Shiqing , booktitle=
-
[22]
Network and Distributed System Security Symposium , year=
Trojaning Attack on Neural Networks , author=. Network and Distributed System Security Symposium , year=
-
[23]
Rethinking
Rao, Quanrui and Wang, Lin and Liu, Wuying , booktitle=. Rethinking
-
[24]
Network and Distributed System Security Symposium , year=
The ``Beatrix'' Resurrections: Robust Backdoor Detection via Gram Matrices , author=. Network and Distributed System Security Symposium , year=
-
[25]
IEEE Symposium on Security and Privacy , year=
Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks , author=. IEEE Symposium on Security and Privacy , year=
-
[26]
Advances in Neural Information Processing Systems , year=
Spectral Signatures in Backdoor Attacks , author=. Advances in Neural Information Processing Systems , year=
-
[27]
AAAI Conference on Artificial Intelligence Workshop on Artificial Intelligence Safety , year=
Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering , author=. AAAI Conference on Artificial Intelligence Workshop on Artificial Intelligence Safety , year=
-
[28]
and Nepal, Surya , booktitle=
Gao, Yansong and Xu, Chang and Wang, Derui and Chen, Shiping and Ranasinghe, Damith C. and Nepal, Surya , booktitle=
-
[29]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Detecting Backdoors During the Inference Stage Based on Corruption Robustness Consistency , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[30]
Guo, Junfeng and Li, Yiming and Chen, Xun and Guo, Hanqing and Sun, Lichao and Liu, Cong , booktitle=
-
[31]
IEEE Symposium on Security and Privacy , year=
Robust Backdoor Detection for Deep Learning via Topological Evolution Dynamics , author=. IEEE Symposium on Security and Privacy , year=
-
[32]
2024 , url =
Monte MacDiarmid and Timothy Maxwell and Nicholas Schiefer and Jesse Mu and Jared Kaplan and David Duvenaud and Sam Bowman and Alex Tamkin and Ethan Perez and Mrinank Sharma and Carson Denison and Evan Hubinger , title =. 2024 , url =
2024
-
[33]
Obfuscated Activations Bypass
Bailey, Luke and Serrano, Alex and Sheshadri, Abhay and Seleznyov, Mikhail and Taylor, Jordan and Jenner, Erik and Hilton, Jacob and Casper, Stephen and Guestrin, Carlos and Emmons, Scott , journal=. Obfuscated Activations Bypass
-
[34]
IEEE European Symposium on Security and Privacy , pages=
Bypassing Backdoor Detection Algorithms in Deep Learning , author=. IEEE European Symposium on Security and Privacy , pages=
-
[35]
Advances in Neural Information Processing Systems , year=
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , author=. Advances in Neural Information Processing Systems , year=
-
[36]
A Simple Fix to Mahalanobis Distance for Improving Near-
Ren, Jie and Fort, Stanislav and Liu, Jeremiah and Roy, Abhijit Guha and Padhy, Shreyas and Lakshminarayanan, Balaji , booktitle=. A Simple Fix to Mahalanobis Distance for Improving Near-
-
[37]
International Conference on Machine Learning , year=
M. International Conference on Machine Learning , year=
-
[38]
Special Lecture on IE , volume=
Variational Autoencoder based Anomaly Detection using Reconstruction Probability , author=. Special Lecture on IE , volume=
-
[39]
Yang, Jingkang and Wang, Pengyun and Zou, Dejian and Zhou, Zitang and Ding, Kunyuan and Peng, Wenxuan and Wang, Haoqi and Chen, Guangyao and Li, Bo and Sun, Yiyou and Du, Xuefeng and Zhou, Kaiyang and Zhang, Wayne and Hendrycks, Dan and Li, Yixuan and Liu, Ziwei , booktitle=
-
[40]
International Conference on Learning Representations , year=
Influence Functions in Deep Learning Are Fragile , author=. International Conference on Learning Representations , year=
-
[41]
International Conference on Machine Learning , pages=
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density , author=. International Conference on Machine Learning , pages=
-
[42]
Journal of the American Statistical Association , volume=
The Influence Curve and Its Role in Robust Estimation , author=. Journal of the American Statistical Association , volume=
-
[43]
Technometrics , volume=
Detection of Influential Observation in Linear Regression , author=. Technometrics , volume=
-
[44]
International Conference on Machine Learning , pages=
Understanding Black-box Predictions via Influence Functions , author=. International Conference on Machine Learning , pages=
-
[45]
arXiv preprint arXiv:2308.03296 , year=
Studying Large Language Model Generalization with Influence Functions , author=. arXiv preprint arXiv:2308.03296 , year=
-
[46]
Park, Sung Min and Georgiev, Kristian and Ilyas, Andrew and Leclerc, Guillaume and Madry, Aleksander , booktitle=
-
[47]
Advances in Neural Information Processing Systems , year=
Training Data Attribution via Approximate Unrolled Differentiation , author=. Advances in Neural Information Processing Systems , year=
-
[48]
International Conference on Machine Learning Workshop on Actionable Interpretability , year=
Bayesian Influence Functions for Scalable Data Attribution , author=. International Conference on Machine Learning Workshop on Actionable Interpretability , year=
-
[49]
arXiv preprint arXiv:2509.26537 , year=
The Loss Kernel: A Geometric Probe for Deep Learning Interpretability , author=. arXiv preprint arXiv:2509.26537 , year=
-
[50]
Advances in Neural Information Processing Systems , year=
Estimating Training Data Influence by Tracing Gradient Descent , author=. Advances in Neural Information Processing Systems , year=
-
[51]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Composite Backdoor Attacks Against Large Language Models , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[52]
Instruction Backdoor Attacks Against Customized
Zhang, Rui and Li, Hongwei and Wen, Rui and Jiang, Wenbo and Zhang, Yuan and Backes, Michael and Shen, Yun and Zhang, Yang , booktitle=. Instruction Backdoor Attacks Against Customized
-
[53]
Bayesian Learning via Stochastic Gradient
Welling, Max and Teh, Yee Whye , booktitle=. Bayesian Learning via Stochastic Gradient
-
[54]
Preconditioned Stochastic Gradient
Li, Chunyuan and Chen, Changyou and Carlson, David and Carin, Lawrence , booktitle=. Preconditioned Stochastic Gradient
-
[55]
International Conference on Artificial Intelligence and Statistics , pages=
The Local Learning Coefficient: A Singularity-Aware Complexity Measure , author=. International Conference on Artificial Intelligence and Statistics , pages=
-
[56]
2009 , publisher=
Algebraic Geometry and Statistical Learning Theory , author=. 2009 , publisher=
2009
-
[57]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond , author=. arXiv preprint arXiv:1611.07476 , year=
-
[58]
Biometrics , volume=
A Concordance Correlation Coefficient to Evaluate Reproducibility , author=. Biometrics , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Refusal in Language Models Is Mediated by a Single Direction , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Interpretability in the Wild: A Circuit for Indirect Object Identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the Wild: A Circuit for Indirect Object Identification in
-
[61]
Mechanistic Interpretability for
Bereska, Leonard and Gavves, Efstratios , journal=. Mechanistic Interpretability for
-
[62]
IEEE Symposium on Foundations of Computational Intelligence , pages=
Almost All Learning Machines Are Singular , author=. IEEE Symposium on Foundations of Computational Intelligence , pages=
-
[63]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Deep Learning Is Singular, and That's Good , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2023 , doi=
2023
-
[64]
International Conference on Learning Representations , year=
Structural Inference: Interpreting Small Language Models with Susceptibilities , author=. International Conference on Learning Representations , year=
-
[65]
You Are What You Eat --
Pepin Lehalleur, Simon and Hoogland, Jesse and Farrugia-Roberts, Matthew and Wei, Susan and Gietelink Oldenziel, Alexander and Wang, George and Carroll, Liam and Murfet, Daniel , journal=. You Are What You Eat --
-
[66]
Loss Landscape Degeneracy and Stagewise Development in Transformers , author=. arXiv preprint arXiv:2402.02364 , year=
-
[67]
Dynamics of Transient Structure in In-Context Linear Regression Transformers , author=. arXiv preprint arXiv:2501.17745 , year=
-
[68]
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang
Differentiation and Specialization of Attention Heads via the Refined Local Learning Coefficient , author=. arXiv preprint arXiv:2410.02984 , year=
-
[69]
arXiv preprint arXiv:2508.00331 , year=
Embryology of a Language Model , author=. arXiv preprint arXiv:2508.00331 , year=
-
[70]
Advances in Neural Information Processing Systems , year=
Adversarial Neuron Pruning Purifies Backdoored Deep Models , author=. Advances in Neural Information Processing Systems , year=
-
[71]
International Conference on Learning Representations , year=
Adversarial Unlearning of Backdoors via Implicit Hypergradient , author=. International Conference on Learning Representations , year=
-
[72]
Advances in Neural Information Processing Systems , year=
Anti-Backdoor Learning: Training Clean Models on Poisoned Data , author=. Advances in Neural Information Processing Systems , year=
-
[73]
Wu, Baoyuan and Chen, Hongrui and Zhang, Mingda and Zhu, Zihao and Wei, Shaokui and Yuan, Danni and Shen, Chao , booktitle=
-
[74]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving Open Language Models at a Practical Size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review arXiv
-
[75]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[76]
Conference on Empirical Methods in Natural Language Processing , pages=
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author=. Conference on Empirical Methods in Natural Language Processing , pages=
-
[77]
ACM Conference on Fairness, Accountability, and Transparency , pages=
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting , author=. ACM Conference on Fairness, Accountability, and Transparency , pages=
-
[78]
van Wingerden, Stan and Hoogland, Jesse and Wang, George and Zhou, William , year=
-
[79]
and Lu, Qinghua and Zhao, Dehai and Zhu, Liming , booktitle=
Shamsujjoha, Md. and Lu, Qinghua and Zhao, Dehai and Zhu, Liming , booktitle=. Swiss Cheese Model for
-
[80]
International Conference on Learning Representations , year=
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.