Recognition: unknown
Low-Rank Adaptation for Critic Learning in Off-Policy Reinforcement Learning
Pith reviewed 2026-05-10 02:51 UTC · model grok-4.3
The pith
Freezing base critic weights and training only low-rank adapters reduces overfitting and boosts performance in off-policy RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
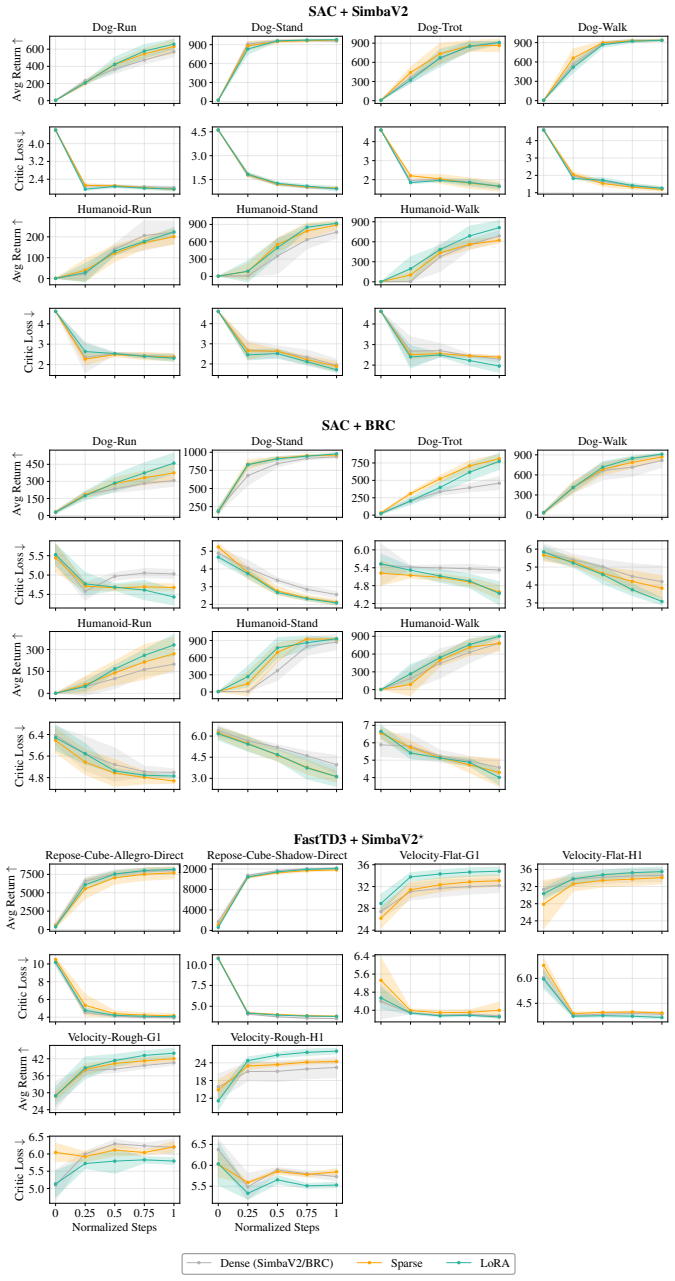
Our approach freezes randomly initialized base matrices and optimizes only the corresponding low-rank adapters in the critic, thereby constraining critic updates to a low-dimensional subspace. This provides a simple structural regularizer that efficiently reduces critic loss and improves policy performance in off-policy RL settings.
What carries the argument
Low-Rank Adaptation (LoRA) on critic networks, freezing base matrices and training only low-rank adapters to constrain updates to a low-dimensional subspace.
If this is right
- Critic loss decreases more efficiently throughout training.
- Policy performance improves or matches the best results on most tasks.
- The method applies across SAC, FastTD3, and different network architectures.
- Structural regularization emerges without extra hyperparameters or loss terms.
Where Pith is reading between the lines
- The subspace constraint may support longer training runs before instability sets in.
- Low-rank critics could scale to higher capacities in environments with scarce or noisy data.
- Similar freezing of base weights might regularize other components such as actors in the same framework.
Load-bearing premise
Freezing randomly initialized base matrices and optimizing only low-rank adapters sufficiently preserves the critic's expressive power while preventing overfitting in replay-based training.
What would settle it
A direct comparison on tasks with minimal overfitting risk where LoRA critics achieve noticeably lower returns than full-parameter critics, showing the low-rank constraint has removed necessary capacity.
Figures






read the original abstract
Scaling critic capacity is a promising direction for improving off-policy reinforcement learning (RL). However, recent work shows that larger critics are prone to overfitting and instability in replay-based bootstrapped training. In this paper, we propose using Low-Rank Adaptation (LoRA) as a structural regularizer for critic learning. Our approach freezes randomly initialized base matrices and optimizes only the corresponding low-rank adapters, thereby constraining critic updates to a low-dimensional subspace. We evaluate our method across different off-policy RL algorithms, including SAC and FastTD3 based on different network architectures. Empirically, LoRA efficiently reduces critic loss during training and improves overall policy performance, achieving the best or competitive results on most tasks. Extensive experiments demonstrate that our low-rank updates provide a simple and effective form of structural regularization for critic learning in off-policy RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Low-Rank Adaptation (LoRA) as a structural regularizer for critic networks in off-policy RL algorithms such as SAC and FastTD3. Randomly initialized base matrices are frozen while only low-rank adapters are optimized, constraining critic updates to a low-dimensional subspace during replay-based bootstrapped training. The authors claim this reduces critic loss, mitigates overfitting from large critics, and yields best or competitive policy performance across tasks, supported by extensive experiments on different network architectures.
Significance. If the central claim holds after addressing experimental controls, the work offers a simple, hyperparameter-light way to regularize critic capacity in off-policy RL by leveraging parameter-efficient adaptation techniques. This could help scale critics without instability, building on known benefits of LoRA in other domains. The approach is credited for its straightforward integration and focus on a practical issue in replay-based training.
major comments (2)
- [Experiments] Experiments section: The claim that low-rank subspace constraints provide structural regularization (distinct from capacity reduction) is not isolated, as no control baseline matches the number of trainable parameters using a full-rank but narrower architecture. Without this, performance gains could be explained by reduced capacity alone, which is already known to mitigate overfitting in off-policy settings.
- [Results] Results and abstract: No quantitative metrics, ablation details, error bars, or statistical significance tests are reported for the claimed improvements on SAC and FastTD3, preventing assessment of effect sizes or robustness of the empirical findings.
minor comments (1)
- [Method] Method section: The description of how base matrices are initialized and frozen could include an explicit equation for the adapted critic output to clarify the low-rank update form.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we intend to make to strengthen the paper.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The claim that low-rank subspace constraints provide structural regularization (distinct from capacity reduction) is not isolated, as no control baseline matches the number of trainable parameters using a full-rank but narrower architecture. Without this, performance gains could be explained by reduced capacity alone, which is already known to mitigate overfitting in off-policy settings.
Authors: We agree that the current experiments do not fully isolate the effect of constraining updates to a low-rank subspace from the general benefit of reduced trainable parameters. A narrower full-rank critic with matched parameter count would provide a stronger control. We will add this baseline to the revised experiments section, evaluating it on representative tasks from the SAC and FastTD3 suites to better distinguish the structural regularization aspect of LoRA. revision: yes
-
Referee: [Results] Results and abstract: No quantitative metrics, ablation details, error bars, or statistical significance tests are reported for the claimed improvements on SAC and FastTD3, preventing assessment of effect sizes or robustness of the empirical findings.
Authors: We acknowledge that the presentation of results can be improved by including more quantitative details. Although our experiments were conducted with multiple random seeds, we will revise the results section and figures to report mean returns with standard deviations, include error bars, expand ablation studies on LoRA rank and related hyperparameters, and add statistical significance tests (such as paired t-tests) where appropriate to quantify the improvements on SAC and FastTD3. revision: yes
Circularity Check
No circularity: empirical proposal grounded in external task performance
full rationale
The paper proposes LoRA-based low-rank updates as a structural regularizer for critics in off-policy RL and validates it through experiments on SAC and FastTD3 across tasks. No derivation chain, equations, or first-principles predictions are presented that reduce to fitted parameters or self-referential definitions by construction. The central claim rests on observed reductions in critic loss and policy improvements, which are measured against external benchmarks rather than internal fits or self-citations. The approach is self-contained as an empirical regularization technique.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor.International conference on machine learning, 2018
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor.International conference on machine learning, 2018
2018
-
[2]
Addressing function approximation error in actor-critic methods.International Conference on Machine Learning, 2018
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods.International Conference on Machine Learning, 2018
2018
-
[3]
Stop regressing: Training value functions via classification for scalable deep rl
Jesse Farebrother, Jordi Orbay, Quan Vuong, Adrien Ali Taïga, Yevgen Chebotar, Ted Xiao, Alex Irpan, Sergey Levine, Pablo Samuel Castro, Aleksandra Faust, et al. Stop regressing: Training value functions via classification for scalable deep rl.arXiv preprint arXiv:2403.03950, 2024
-
[4]
Double q-learning.Advances in neural information processing systems, 23, 2010
Hado Hasselt. Double q-learning.Advances in neural information processing systems, 23, 2010
2010
-
[5]
Deep reinforcement learning with double q-learning, 2015
Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning, 2015
2015
-
[6]
Crossq: Batch normalization in deep reinforcement learning for greater sample efficiency and simplicity.The Twelfth International Conference on Learning Represen- tations, 2024
Aditya Bhatt, Daniel Palenicek, Boris Belousov, Max Argus, Artemij Amiranashvili, Thomas Brox, and Jan Peters. Crossq: Batch normalization in deep reinforcement learning for greater sample efficiency and simplicity.The Twelfth International Conference on Learning Represen- tations, 2024
2024
-
[7]
Wurman, Jaegul Choo, Peter Stone, and Takuma Seno
Hojoon Lee, Dongyoon Hwang, Donghu Kim, Hyunseung Kim, Jun Jet Tai, Kaushik Subra- manian, Peter R. Wurman, Jaegul Choo, Peter Stone, and Takuma Seno. Simba: Simplicity bias for scaling up parameters in deep reinforcement learning.The Thirteenth International Conference on Learning Representations, 2025
2025
-
[8]
Hyper- spherical normalization for scalable deep reinforcement learning.International Conference on Machine Learning, 2025
Hojoon Lee, Youngdo Lee, Takuma Seno, Donghu Kim, Peter Stone, and Jaegul Choo. Hyper- spherical normalization for scalable deep reinforcement learning.International Conference on Machine Learning, 2025
2025
-
[9]
A distributional perspective on rein- forcement learning
Marc G Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on rein- forcement learning. InInternational conference on machine learning, pages 449–458. Pmlr, 2017
2017
-
[10]
Daniel Palenicek, Florian V ogt, Joe Watson, and Jan Peters. Scaling off-policy reinforcement learning with batch and weight normalization.arXiv preprint arXiv:2502.07523, 2025
-
[11]
TD-MPC2: Scalable, robust world models for continuous control.The Twelfth International Conference on Learning Representations, 2024
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control.The Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
Bigger, regularized, optimistic: scaling for compute and sample-efficient continuous control
Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miło´s, and Marek Cygan. Bigger, regularized, optimistic: scaling for compute and sample-efficient continuous control. Advances in neural information processing systems, 2024
2024
-
[13]
Network sparsity unlocks the scaling potential of deep reinforcement learning.International Conference on Machine Learning, 2025
Guozheng Ma, Lu Li, Zilin Wang, Li Shen, Pierre-Luc Bacon, and Dacheng Tao. Network sparsity unlocks the scaling potential of deep reinforcement learning.International Conference on Machine Learning, 2025
2025
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.International Conference on Learning Representations, 2022. 10
2022
-
[15]
Big- ger, regularized, categorical: High-capacity value functions are efficient multi-task learners
Michal Nauman, Marek Cygan, Carmelo Sferrazza, Aviral Kumar, and Pieter Abbeel. Big- ger, regularized, categorical: High-capacity value functions are efficient multi-task learners. Advances in Neural Information Processing Systems, 2025
2025
-
[16]
Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control, 2025
Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control, 2025
2025
-
[17]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[18]
Marcin Andrychowicz, Anton Raichuk, Piotr Sta´nczyk, Manu Orsini, Sertan Girgin, Raphael Marinier, Léonard Hussenot, Matthieu Geist, Olivier Pietquin, Marcin Michalski, et al. What matters in on-policy reinforcement learning? a large-scale empirical study.arXiv preprint arXiv:2006.05990, 2020
-
[19]
Yuexin Bian, Jie Feng, Tao Wang, Yijiang Li, Sicun Gao, and Yuanyuan Shi. Rn-d: Discretized categorical actors with regularized networks for on-policy reinforcement learning.arXiv preprint arXiv:2601.23075, 2026
-
[20]
Implicit under- parameterization inhibits data-efficient deep reinforcement learning.International Conference on Learning Representations, 2021
Aviral Kumar, Rishabh Agarwal, Dibya Ghosh, and Sergey Levine. Implicit under- parameterization inhibits data-efficient deep reinforcement learning.International Conference on Learning Representations, 2021
2021
-
[21]
Understanding plasticity in neural networks.International Conference on Machine Learning, 2023
Clare Lyle, Zeyu Zheng, Evgenii Nikishin, Bernardo Avila Pires, Razvan Pascanu, and Will Dabney. Understanding plasticity in neural networks.International Conference on Machine Learning, 2023
2023
-
[22]
The primacy bias in deep reinforcement learning.International Conference on Machine Learning, 2022
Evgenii Nikishin, Max Schwarzer, Pierluca D’Oro, Pierre-Luc Bacon, and Aaron Courville. The primacy bias in deep reinforcement learning.International Conference on Machine Learning, 2022
2022
-
[23]
Towards deeper deep reinforcement learning with spectral normalization.Advances in neural information processing systems, 34:8242–8255, 2021
Nils Bjorck, Carla P Gomes, and Kilian Q Weinberger. Towards deeper deep reinforcement learning with spectral normalization.Advances in neural information processing systems, 34:8242–8255, 2021
2021
-
[24]
A simple weight decay can improve generalization.Advances in neural information processing systems, 4, 1991
Anders Krogh and John Hertz. A simple weight decay can improve generalization.Advances in neural information processing systems, 4, 1991
1991
-
[25]
Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958, 2014
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958, 2014
1929
-
[26]
On the effectiveness of parameter-efficient fine-tuning
Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the effectiveness of parameter-efficient fine-tuning. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 12799–12807, 2023
2023
- [27]
-
[28]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review arXiv 2018
-
[29]
Orbit: A unified simulation framework for interactive robot learning environments.IEEE Robotics and Automation Letters, 8(6):3740–3747, 2023
Mayank Mittal, Calvin Yu, Qinxi Yu, Jingzhou Liu, Nikita Rudin, David Hoeller, Jia Lin Yuan, Ritvik Singh, Yunrong Guo, Hammad Mazhar, Ajay Mandlekar, Buck Babich, Gavriel State, Marco Hutter, and Animesh Garg. Orbit: A unified simulation framework for interactive robot learning environments.IEEE Robotics and Automation Letters, 8(6):3740–3747, 2023. 11 A...
2023
-
[30]
This observation motivates the initialization scheme for the frozen base matrix and the LoRA adapters described below. C Why standard row-wise weight normalization is incompatible with frozen LoRA bases A natural approach to combining LoRA with hyperspherical weight normalization is to apply the standard row-wise normalization directly to the effective we...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.