Recognition: unknown
SAVOIR: Learning Social Savoir-Faire via Shapley-based Reward Attribution
Pith reviewed 2026-05-10 02:23 UTC · model grok-4.3
The pith
Shapley values from game theory fairly assign credit to individual utterances, enabling effective reinforcement learning for social intelligence in language agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAVOIR grounds reward attribution in cooperative game theory by combining expected utility shifts for prospective valuation of each utterance's strategic potential with Shapley values that provide axiomatic guarantees of efficiency, symmetry, and marginality, thereby solving credit assignment in social RL and producing agents with superior performance on interaction benchmarks.
What carries the argument
The Shapley value mechanism for distributing episode-level rewards to utterances, computed via marginal contributions across coalitions and combined with expected utility for forward-looking assessment rather than backward-looking attribution.
If this is right
- Language agents achieve better navigation of interpersonal dynamics through theoretically grounded credit assignment.
- Open 7B models can reach or surpass closed proprietary models on social intelligence tasks.
- Social intelligence training benefits from axiomatic fairness properties that prevent arbitrary reward allocation.
- Large reasoning-focused models remain limited on tasks requiring prospective social strategy.
- Reinforcement learning for dialogues can move beyond heuristic reward models to principled cooperative-game methods.
Where Pith is reading between the lines
- The same prospective Shapley approach might transfer to credit assignment in other sequential decision domains such as planning or tool use.
- If the method generalizes, it could reduce dependence on ever-larger models for acquiring human-like interaction norms.
- Applying the framework to multi-agent settings with conflicting goals could yield more stable cooperative behaviors.
- Future benchmarks that include longer horizons or cultural variation would test whether the prospective valuation remains robust.
Load-bearing premise
The SOTOPIA benchmark and its simulated dialogues sufficiently represent the credit assignment challenges and outcomes of real-world social interactions.
What would settle it
Evaluation on a new set of unscripted, multi-turn interactions with human participants showing no performance gain for SAVOIR-trained agents over baselines that use direct language-model reward distribution.
Figures







read the original abstract
Social intelligence, the ability to navigate complex interpersonal interactions, presents a fundamental challenge for language agents. Training such agents via reinforcement learning requires solving the credit assignment problem: determining how individual utterances contribute to multi-turn dialogue outcomes. Existing approaches directly employ language models to distribute episode-level rewards, yielding attributions that are retrospective and lack theoretical grounding. We propose SAVOIR (ShApley Value fOr SocIal RL), a novel principled framework grounded in cooperative game theory. Our approach combines two complementary principles: expected utility shifts evaluation from retrospective attribution to prospective valuation, capturing an utterance's strategic potential for enabling favorable future trajectories; Shapley values ensure fair credit distribution with axiomatic guarantees of efficiency, symmetry, and marginality. Experiments on the SOTOPIA benchmark demonstrate that SAVOIR achieves new state-of-the-art performance across all evaluation settings, with our 7B model matching or exceeding proprietary models including GPT-4o and Claude-3.5-Sonnet. Notably, even large reasoning models consistently underperform, suggesting social intelligence requires qualitatively different capabilities than analytical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
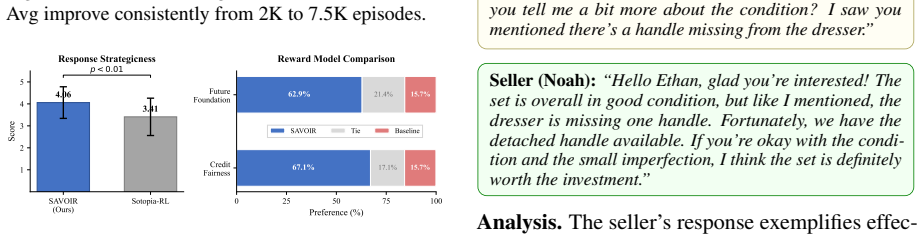
Summary. The manuscript introduces SAVOIR, a framework for training language agents on social intelligence tasks via reinforcement learning. It addresses credit assignment in multi-turn dialogues by combining expected utility (for prospective valuation of utterances' strategic potential) with Shapley values from cooperative game theory (for axiomatic fair attribution satisfying efficiency, symmetry, and marginality). The central empirical claim is that this yields new state-of-the-art performance on the SOTOPIA benchmark, with a 7B model matching or exceeding proprietary models including GPT-4o and Claude-3.5-Sonnet.
Significance. If the results hold, the work would be significant for supplying a principled, axiomatically grounded alternative to heuristic LM-based reward distribution in social RL. The shift to prospective expected-utility valuation plus Shapley guarantees could improve robustness in credit assignment for complex interpersonal interactions, and the observation that large reasoning models underperform highlights that social competence may demand qualitatively different capabilities than analytical reasoning.
major comments (2)
- [Experiments] Experimental evaluation: The SOTOPIA results are presented as establishing SOTA across all settings, yet the manuscript supplies no details on baselines, ablations, statistical significance, or implementation specifics (e.g., how Shapley values are approximated over dialogue trajectories). This directly prevents verification of the central performance claim that the 7B model matches or exceeds GPT-4o and Claude-3.5-Sonnet.
- [Evaluation] Method and evaluation: The approach rests on SOTOPIA's LLM-as-judge metrics and simulated scenarios, but no external validation (human ratings on held-out real interactions, adversarial test cases, or cross-benchmark transfer) is reported. This is load-bearing for the claim that prospective Shapley attribution produces generalizable social intelligence rather than benchmark-specific patterns.
minor comments (1)
- [Abstract] The abstract refers to 'all evaluation settings' without enumerating them; a brief list or reference to the relevant table/figure would improve clarity.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. We have carefully considered the comments on experimental details and evaluation methodology. Below, we provide point-by-point responses and indicate the changes we will implement in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experimental evaluation: The SOTOPIA results are presented as establishing SOTA across all settings, yet the manuscript supplies no details on baselines, ablations, statistical significance, or implementation specifics (e.g., how Shapley values are approximated over dialogue trajectories). This directly prevents verification of the central performance claim that the 7B model matches or exceeds GPT-4o and Claude-3.5-Sonnet.
Authors: We agree that additional experimental details are necessary for reproducibility and verification of our claims. In the revised manuscript, we will provide a detailed description of the baselines, including how they were implemented and any hyperparameters used. We will include ablation studies that isolate the contributions of the expected utility valuation and the Shapley value attribution. Statistical significance will be reported using results from multiple independent training runs, including means, standard deviations, and p-values from appropriate tests. For the Shapley value approximation, we will explain the Monte Carlo sampling procedure over dialogue trajectories, including the number of samples used and any variance reduction techniques. Furthermore, we will present a comprehensive table with exact scores for our 7B model alongside GPT-4o and Claude-3.5-Sonnet across all SOTOPIA evaluation settings to substantiate the performance claims. revision: yes
-
Referee: [Evaluation] Method and evaluation: The approach rests on SOTOPIA's LLM-as-judge metrics and simulated scenarios, but no external validation (human ratings on held-out real interactions, adversarial test cases, or cross-benchmark transfer) is reported. This is load-bearing for the claim that prospective Shapley attribution produces generalizable social intelligence rather than benchmark-specific patterns.
Authors: We recognize the value of external validation to support the generalizability of our findings. The SOTOPIA benchmark was chosen because it provides a standardized way to evaluate social intelligence through multi-turn interactions, and its LLM-as-judge protocol has been shown to align with human preferences in prior work. In the revision, we will expand the discussion to include potential limitations of relying on simulated environments and LLM judges, such as the risk of overfitting to benchmark-specific patterns. We will also highlight the consistency of improvements across different SOTOPIA scenarios as preliminary evidence of robustness. However, we do not currently have access to human ratings on held-out real-world interactions or results from other benchmarks, as collecting such data would require substantial additional effort. We will add this as a direction for future research in the Limitations section. revision: partial
- We cannot provide new external validation experiments such as human ratings on held-out real interactions, adversarial test cases, or cross-benchmark transfer results within the scope of this revision.
Circularity Check
No significant circularity detected in the derivation.
full rationale
The SAVOIR method is explicitly derived from external cooperative game theory (standard Shapley value axioms for efficiency, symmetry, and marginality) combined with expected-utility shifts for prospective valuation. These foundations are independent mathematical results, not self-citations or data fits. Performance claims are empirical SOTOPIA results rather than predictions that reduce by construction to training parameters or benchmark labels. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the abstract or method outline; the central claim remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Axioms of cooperative game theory including efficiency, symmetry, and marginality for Shapley values
Reference graph
Works this paper leans on
-
[1]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
To- wards reasoning era: A survey of long chain-of- thought for reasoning large language models.ArXiv, abs/2503.09567. Yang Deng, Wenxuan Zhang, Wai Lam, See-Kiong Ng, and Tat-Seng Chua
work page internal anchor Pith review arXiv
-
[2]
InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Aus- tria, May 7-11,
Plug-and-play policy planner for large language model powered dialogue agents. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Aus- tria, May 7-11,
2024
-
[3]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 10301– 10314
Reasoning does not necessarily improve role- playing ability. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10301– 10314. Xiachong Feng, Longxu Dou, Ella Li, Qinghao Wang, Haochuan Wang, Yu Guo, Chang Ma, and Ling- peng Kong
2025
-
[4]
A survey on large language model-based social agents in game-theoretic scenarios,
A survey on large language model-based social agents in game-theoretic scenar- ios.ArXiv preprint, abs/2412.03920. Kanishk Gandhi, Jan-Philipp Fränken, Tobias Gersten- berg, and Noah D. Goodman
-
[5]
InAdvances in Neural Information Pro- cessing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
Understanding social reasoning in language models with language models. InAdvances in Neural Information Pro- cessing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
2023
-
[6]
ArXiv preprint, abs/2501.01821
Sdpo: Segment- level direct preference optimization for social agents. ArXiv preprint, abs/2501.01821. Sangmin Lee, Minzhi Li, Bolin Lai, Wenqi Jia, Fiona Ryan, Xu Cao, Ozgur Kara, Bikram Boote, Weiyan Shi, Diyi Yang, and 1 others
-
[7]
Towards social ai: A survey on understanding social interactions.ArXiv preprint, abs/2409.15316. Kenneth Li, Yiming Wang, Fernanda Vi’egas, and Mar- tin Wattenberg. 2024a. Dialogue action tokens: Steer- ing language models in goal-directed dialogue with a multi-turn planner.ArXiv preprint, abs/2406.11978. Minzhi Li, Weiyan Shi, Caleb Ziems, and Diyi Yang....
- [8]
-
[9]
A unified approach to interpreting model predictions. InAd- vances in Neural Information Processing Systems 30: Annual Conference on Neural Information Process- ing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 4765–4774. Leena Mathur, Paul Pu Liang, and Louis-Philippe Morency
2017
-
[10]
ArXiv preprint, abs/2404.11023
Advancing social intelligence in ai agents: Technical challenges and open questions. ArXiv preprint, abs/2404.11023. Kamal Ndousse, Douglas Eck, Sergey Levine, and Natasha Jaques
-
[11]
Emergent social learning via multi-agent reinforcement learning. InProceed- ings of the 38th International Conference on Ma- chine Learning, ICML 2021, 18-24 July 2021, Vir- tual Event, volume 139 ofProceedings of Machine Learning Research, pages 7991–8004. PMLR. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Mi...
2021
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models. ArXiv preprint, abs/2402.03300. Ruiyi Wang, Haofei Yu, Wenxin Zhang, Zhengyang Qi, Maarten Sap, Graham Neubig, Yonatan Bisk, and Hao Zhu
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Diyi Yang, Caleb Ziems, William Held, Omar Shaikh, Michael S Bernstein, and John Mitchell
Sotopia-pi: Interactive learning of socially intelligent language agents.ArXiv preprint, abs/2403.08715. Diyi Yang, Caleb Ziems, William Held, Omar Shaikh, Michael S Bernstein, and John Mitchell
-
[14]
Social skill training with large language models.arXiv preprint arXiv:2404.04204, 2024
Social skill training with large language models.ArXiv preprint, abs/2404.04204. Haofei Yu, Zhengyang Qi, Yining Zhao, Kolby Notting- ham, Keyang Xuan, Bodhisattwa Prasad Majumder, Hao Zhu, Paul Pu Liang, and Jiaxuan You
-
[15]
ArXiv preprint, abs/2508.03905
Sotopia-rl: Reward design for social intelligence. ArXiv preprint, abs/2508.03905. Wenyuan Zhang, Tianyun Liu, Mengxiao Song, Xi- aodong Li, and Tingwen Liu
-
[16]
Social- eval: Evaluating social intelligence of large language models.ArXiv preprint, abs/2506.00900. Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap
-
[17]
In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
SOTOPIA: interactive evalua- tion for social intelligence in language agents. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[18]
Social intelligence in the age of llms. InProceedings of the 2025 Annual Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage Technologies (Volume 5: Tutorial Abstracts), pages 51–55. A Shapley Value Computation Explained This section provides a detailed explanation of the Shapley value com...
2025
-
[19]
Benjamin, I know we’ve been having fun, but I really need to win this game
Setup.Consider a dialogue with three utterances from the target agent:N={a 1, a2, a3}. We want to compute the Shapley value ϕa2 for utterance a2. Permutation-Based Interpretation.The Shap- ley value can be computed by averaging the marginal contribution of a2 across all possible or- derings (permutations) in which utterances could “join” the dialogue. For...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.