Recognition: unknown
Ocean: Fast Estimation-Based Sparse General Matrix-Matrix Multiplication on GPU
Pith reviewed 2026-05-10 02:34 UTC · model grok-4.3
The pith
Estimation replaces exact symbolic passes to speed up GPU SpGEMM computations
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our approach replaces the costly symbolic step with lightweight HyperLogLog estimators, combined with an analysis strategy that dynamically selects the optimal workflow and guides accumulator configuration. In addition, we introduce a hybrid accumulator design, including a novel hash-based accumulator that leverages both shared and global memory. This estimation-based SpGEMM workflow consistently outperforms leading GPU SpGEMM implementations across a wide range of both square and rectangular matrices.
What carries the argument
HyperLogLog cardinality estimators that approximate output row sizes to replace exact symbolic counting, driving dynamic workflow choice and configuration of a hybrid shared-plus-global hash accumulator.
Load-bearing premise
HyperLogLog estimation error stays small enough that the selected workflow and accumulator still produce correct results and do not introduce hidden overhead that cancels the reported gains for the tested matrix distributions.
What would settle it
Measure output correctness and total runtime when the method is applied to matrices engineered to produce large HyperLogLog errors, such as highly skewed row-density distributions, and check whether speedups vanish or errors appear.
Figures


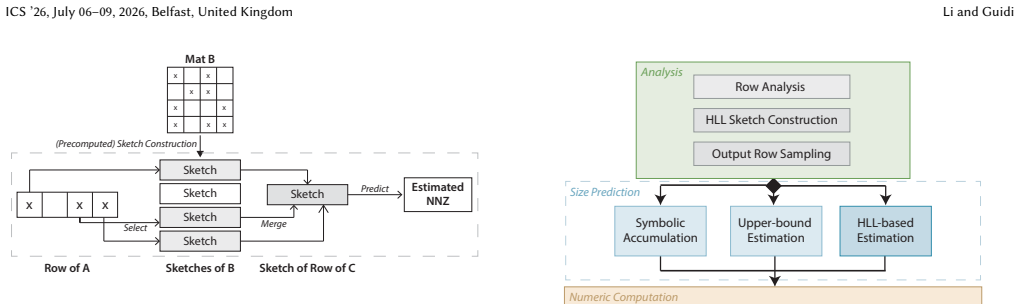





read the original abstract
In computational science and data analytics, many workloads involve irregular and sparse computations that are inherently difficult to optimize for modern hardware. A key kernel is Sparse General Matrix-Matrix Multiplication (SpGEMM), which underpins simulations, graph analytics, and machine learning applications. SpGEMM exhibits irregular memory access patterns and workload imbalance, making it challenging to achieve high performance on GPUs. Current GPU SpGEMM solutions typically rely on a two-pass workflow to address load imbalance and reduce memory access. The symbolic pass, which determines the number of output elements per row, accounts for roughly 28% of the total runtime on average. In this work, we question the necessity of exact symbolic computation and introduce an estimation-based SpGEMM workflow. Our approach replaces the costly symbolic step with lightweight HyperLogLog estimators, combined with an analysis strategy that dynamically selects the optimal workflow and guides accumulator configuration. In addition, we introduce a hybrid accumulator design, including a novel hash-based accumulator that leverages both shared and global memory. Our approach consistently outperforms leading GPU SpGEMM implementations across a wide range of both square and rectangular matrices, achieving speedups of 1.4x-2.8x on NVIDIA A100 and H100 architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ocean, an estimation-based SpGEMM algorithm for GPUs that replaces the exact symbolic pass (averaging 28% of runtime) with HyperLogLog cardinality estimators, adds dynamic workflow selection to choose optimal paths and accumulator configurations, and proposes a hybrid hash-based accumulator that uses both shared and global memory. It reports consistent speedups of 1.4x–2.8x versus leading GPU SpGEMM implementations on NVIDIA A100 and H100 GPUs across square and rectangular matrices.
Significance. If the HyperLogLog estimates maintain sufficient accuracy to guarantee correct output nnz counts and avoid hidden fallback overhead, the work would meaningfully advance GPU sparse linear algebra by eliminating a major source of overhead in irregular workloads. This could benefit graph analytics, scientific simulations, and ML kernels that rely on SpGEMM. The empirical timing comparisons to external baselines constitute the primary evidence; no parameter-free derivations or machine-checked proofs are present.
major comments (2)
- [Abstract] Abstract: the central claim that the estimation-based workflow 'consistently outperforms' leading implementations with 1.4x–2.8x speedups rests on the unverified assumption that HyperLogLog error remains small enough for the dynamic selector and hybrid accumulator to provision correct capacity. No quantitative error rates, failure-case analysis, or worst-case behavior for high-variance row distributions are supplied, so the correctness-to-performance link cannot be assessed from the given text.
- [Abstract] Abstract and evaluation description: the reported speedups are presented without accompanying data on estimation overhead, the fraction of cases where the dynamic selector chooses a sub-optimal path, or full benchmark tables that would allow verification that net gains are not canceled by under-allocation or fallback costs.
minor comments (1)
- The abstract refers to 'a wide range of both square and rectangular matrices' without naming the specific test suites or matrix properties (e.g., nnz distribution, aspect ratios), which would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below. Where the feedback identifies gaps in the presentation of supporting data or analysis, we have revised the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the estimation-based workflow 'consistently outperforms' leading implementations with 1.4x–2.8x speedups rests on the unverified assumption that HyperLogLog error remains small enough for the dynamic selector and hybrid accumulator to provision correct capacity. No quantitative error rates, failure-case analysis, or worst-case behavior for high-variance row distributions are supplied, so the correctness-to-performance link cannot be assessed from the given text.
Authors: We agree that the abstract as written does not supply quantitative error rates or worst-case analysis, making it difficult for readers to directly assess the assumption. The full manuscript reports end-to-end timings that implicitly reflect any estimation inaccuracies (as incorrect capacity would trigger fallback or incorrect results), but we acknowledge this is insufficient. We will revise the abstract to include a concise statement on observed estimator accuracy and add a new subsection in the evaluation that provides quantitative error rates, failure-case analysis, and behavior for high-variance row distributions. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: the reported speedups are presented without accompanying data on estimation overhead, the fraction of cases where the dynamic selector chooses a sub-optimal path, or full benchmark tables that would allow verification that net gains are not canceled by under-allocation or fallback costs.
Authors: The evaluation section already measures and reports component runtimes that include estimation overhead and dynamic selector decisions. However, we accept that the abstract and main text do not present these breakdowns or full per-matrix tables explicitly enough to let readers verify net gains independently. We will expand the evaluation section with additional tables and figures showing estimation overhead percentages, the fraction of sub-optimal selector choices, and complete benchmark results per matrix to confirm that reported speedups are not offset by under-allocation or fallback costs. revision: yes
Circularity Check
No circularity in empirical SpGEMM estimation workflow
full rationale
The paper replaces the exact symbolic pass in GPU SpGEMM with HyperLogLog cardinality estimation, adds dynamic workflow selection, and a hybrid hash-based accumulator, then reports empirical speedups of 1.4x-2.8x versus external baselines on A100/H100. No mathematical derivation, prediction, or first-principles result is claimed; the central performance claims rest on direct timing measurements against independent implementations rather than any fitted parameter renamed as output, self-citation chain, or self-definitional reduction. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- HyperLogLog precision bits
- Dynamic selection thresholds
Reference graph
Works this paper leans on
-
[1]
Rasmus Resen Amossen, Andrea Campagna, and Rasmus Pagh. 2014. Better Size Estimation for Sparse Matrix Products.Algorithmica69, 3 (July 2014), 741–757. doi:10.1007/s00453-012-9692-9
-
[2]
Pham Nguyen Quang Anh, Rui Fan, and Yonggang Wen. 2016. Balanced hashing and efficient gpu sparse general matrix-matrix multiplication. InProceedings of the 2016 International Conference on Supercomputing. 1–12
2016
-
[3]
Ariful Azad, Georgios A Pavlopoulos, Christos A Ouzounis, Nikos C Kyrpides, and Aydin Buluç. 2018. HipMCL: a high-performance parallel implementation of the Markov clustering algorithm for large-scale networks.Nucleic acids research 46, 6 (2018), e33–e33
2018
-
[4]
Nathan Bell, Steven Dalton, and Luke N. Olson. 2012. Exposing Fine-Grained Parallelism in Algebraic Multigrid Methods.SIAM Journal on Scientific Computing 34, 4 (2012), C123–C152. doi:10.1137/110838844
-
[5]
Julian Bellavita, Lorenzo Pichetti, Thomas Pasquali, Flavio Vella, and Giulia Guidi
-
[6]
Communication-Avoiding SpGEMM via Trident Partitioning on Hierar- chical GPU Interconnects. InProceedings of the 2026 International Conference on Supercomputing (ICS ’26)(Belfast, United Kingdom). ACM, New York, NY, USA, 1–13. doi:10.1145/3797905.3800543
-
[7]
Benjamin Brock, Aydın Buluç, and Katherine Yelick. 2024. RDMA-based Algo- rithms for Sparse Matrix Multiplication on GPUs. InProceedings of the 38th ACM International Conference on Supercomputing. 225–235
2024
- [8]
-
[9]
Edith Cohen. 1996. On optimizing multiplications of sparse matrices. InInter- national Conference on Integer Programming and Combinatorial Optimization. Springer, 219–233
1996
-
[10]
Edith Cohen. 1997. Size-Estimation Framework with Applications to Transitive Closure and Reachability.J. Comput. System Sci.55, 3 (Dec. 1997), 441–453. doi:10.1006/jcss.1997.1534
-
[11]
Steven Dalton, Sean Baxter, Duane Merrill, Luke Olson, and Michael Garland
-
[12]
In2015 IEEE International Parallel and Distributed Processing Symposium
Optimizing sparse matrix operations on gpus using merge path. In2015 IEEE International Parallel and Distributed Processing Symposium. IEEE, 407–416
-
[13]
Zhaoyang Du, Yijin Guan, Tianchan Guan, Dimin Niu, Linyong Huang, Hongzhong Zheng, and Yuan Xie. 2022. OpSparse: A Highly Optimized Frame- work for Sparse General Matrix Multiplication on GPUs.IEEE Access10 (2022), 85960–85974. doi:10.1109/ACCESS.2022.3196940
-
[14]
Zhaoyang Du, Yijin Guan, Tianchan Guan, Dimin Niu, Nianxiong Tan, Xiaopeng Yu, Hongzhong Zheng, Jianyi Meng, Xiaolang Yan, and Yuan Xie. 2022. Predicting the Output Structure of Sparse Matrix Multiplication with Sampled Compression Ratio. doi:10.48550/arXiv.2207.13848 arXiv:2207.13848 [cs]
-
[15]
Philippe Flajolet, Éric Fusy, Olivier Gandouet, and Frédéric Meunier. 2007. Hyper- LogLog: the analysis of a near-optimal cardinality estimation algorithm.Discrete Mathematics & Theoretical Computer ScienceDMTCS Proceedings vol. AH,..., Proceedings (Jan. 2007). doi:10.46298/dmtcs.3545 Publisher: Centre pour la Communication Scientifique Directe (CCSD). Oc...
-
[16]
Jianhua Gao, Weixing Ji, Fangli Chang, Shiyu Han, Bingxin Wei, Zeming Liu, and Yizhuo Wang. 2023. A Systematic Survey of General Sparse Matrix-matrix Multiplication.ACM Comput. Surv.55, 12 (Dec. 2023), 1–36. doi:10.1145/3571157
-
[17]
John R Gilbert, Cleve Moler, and Robert Schreiber. 1992. Sparse matrices in MATLAB: Design and implementation.SIAM journal on matrix analysis and applications13, 1 (1992), 333–356
1992
-
[18]
Giulia Guidi, Marquita Ellis, Daniel Rokhsar, Katherine Yelick, and Aydın Buluç
-
[19]
InSIAM Conference on Applied and Computational Discrete Algorithms (ACDA21)
BELLA: Berkeley efficient long-read to long-read aligner and overlapper. InSIAM Conference on Applied and Computational Discrete Algorithms (ACDA21). SIAM, 123–134
-
[20]
Giulia Guidi, Oguz Selvitopi, Marquita Ellis, Leonid Oliker, Katherine Yelick, and Aydın Buluç. 2021. Parallel string graph construction and transitive reduction for de novo genome assembly. In2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 517–526
2021
-
[21]
Fred G Gustavson. 1978. Two fast algorithms for sparse matrices: Multiplication and permuted transposition.ACM Transactions on Mathematical Software (TOMS) 4, 3 (1978), 250–269
1978
-
[22]
Stefan Heule, Marc Nunkesser, and Alexander Hall. 2013. HyperLogLog in prac- tice: algorithmic engineering of a state of the art cardinality estimation algorithm. InProceedings of the 16th International Conference on Extending Database Tech- nology. ACM, Genoa Italy, 683–692. doi:10.1145/2452376.2452456
-
[23]
Abdullah Al Raqibul Islam, Helen Xu, Dong Dai, and Aydın Buluç. 2025. Im- proving SpGEMM Performance Through Matrix Reordering and Cluster-wise Computation. doi:10.48550/arXiv.2507.21253 arXiv:2507.21253 [cs]
- [24]
-
[25]
1998.The Art of Computer Programming: Sorting and Searching, Volume 3
Donald E Knuth. 1998.The Art of Computer Programming: Sorting and Searching, Volume 3. Addison-Wesley Professional
1998
-
[26]
Weifeng Liu and Brian Vinter. 2014. An efficient GPU general sparse matrix- matrix multiplication for irregular data. In2014 IEEE 28th international parallel and distributed processing symposium. IEEE, 370–381
2014
-
[27]
Yusuke Nagasaka, Satoshi Matsuoka, Ariful Azad, and Aydın Buluç. 2019. Perfor- mance optimization, modeling and analysis of sparse matrix-matrix products on multi-core and many-core processors.Parallel Comput.90 (2019), 102545
2019
-
[28]
Yusuke Nagasaka, Akira Nukada, and Satoshi Matsuoka. 2017. High-Performance and Memory-Saving Sparse General Matrix-Matrix Multiplication for NVIDIA Pascal GPU. In2017 46th International Conference on Parallel Processing (ICPP). IEEE, Bristol, United Kingdom, 101–110. doi:10.1109/ICPP.2017.19
-
[29]
Yuyao Niu, Zhengyang Lu, Haonan Ji, Shuhui Song, Zhou Jin, and Weifeng Liu
-
[30]
InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming
TileSpGEMM: a tiled algorithm for parallel sparse general matrix-matrix multiplication on GPUs. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. ACM, Seoul Republic of Korea, 90–106. doi:10.1145/3503221.3508431
-
[31]
NVIDIA Corporation. 2026. cuSPARSE Library. https://docs.nvidia.com/cuda/ cusparse/. Version 13.1
2026
-
[32]
2026.Volta Tuning Guide Release 13.1
NVIDIA Corporation. 2026.Volta Tuning Guide Release 13.1. NVIDIA Corporation. https://docs.nvidia.com/cuda/volta-tuning-guide/index.html
2026
-
[33]
Mathias Parger, Martin Winter, Daniel Mlakar, and Markus Steinberger. 2020. spECK: accelerating GPU sparse matrix-matrix multiplication through light- weight analysis. InProceedings of the 25th ACM SIGPLAN Symposium on Princi- ples and Practice of Parallel Programming. ACM, San Diego California, 362–375. doi:10.1145/3332466.3374521
-
[34]
John G Saw, Mark CK Yang, and Tse Chin Mo. 1984. Chebyshev inequality with estimated mean and variance.The American Statistician38, 2 (1984), 130–132
1984
-
[35]
Oguz Selvitopi, Saliya Ekanayake, Giulia Guidi, Georgios A Pavlopoulos, Ari- ful Azad, and Aydın Buluç. 2020. Distributed many-to-many protein sequence alignment using sparse matrices. InSC20: International Conference for High Per- formance Computing, Networking, Storage and Analysis. IEEE, 1–14
2020
-
[36]
Alok Tripathy, Katherine Yelick, and Aydın Buluç. 2020. Reducing communication in graph neural network training. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–14
2020
-
[37]
Minjie Wang, Da Zheng, Zihao Ye, Quan Gan, Mufei Li, Xiang Song, Jinjing Zhou, Chao Ma, Lingfan Yu, Yu Gai, Tianjun Xiao, Tong He, George Karypis, Jinyang Li, and Zheng Zhang. 2019. Deep Graph Library: A Graph-Centric, Highly- Performant Package for Graph Neural Networks.arXiv preprint arXiv:1909.01315 (2019)
-
[38]
Yizhuo Wang, Hongpeng Lin, Bingxin Wei, Jianhua Gao, and Weixing Ji. 2025. Optimizing General Sparse Matrix-Matrix Multiplication on the GPU.ACM Trans. Archit. Code Optim.(Nov. 2025), 3774654. doi:10.1145/3774654
-
[39]
2013.The cuda handbook: A comprehensive guide to gpu program- ming
Nicholas Wilt. 2013.The cuda handbook: A comprehensive guide to gpu program- ming. Pearson Education
2013
-
[40]
Martin Winter, Daniel Mlakar, Rhaleb Zayer, Hans-Peter Seidel, and Markus Stein- berger. 2019. Adaptive sparse matrix-matrix multiplication on the GPU. InPro- ceedings of the 24th Symposium on Principles and Practice of Parallel Programming. ACM, Washington District of Columbia, 68–81. doi:10.1145/3293883.3295701
-
[41]
Martin Winter, Daniel Mlakar, Rhaleb Zayer, Hans-Peter Seidel, and Markus Steinberger. 2019. Adaptive sparse matrix-matrix multiplication on the GPU. In Proceedings of the 24th symposium on principles and practice of parallel program- ming. 68–81
2019
-
[42]
Min Wu, Huizhang Luo, Fenfang Li, Yiran Zhang, Zhuo Tang, Kenli Li, Jeff Zhang, and Chubo Liu. 2025. HSMU-SpGEMM: Achieving High Shared Memory Utiliza- tion for Parallel Sparse General Matrix-Matrix Multiplication on Modern GPUs. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, Las Vegas, NV, USA, 1452–1466. doi:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.