Recognition: unknown
AlignCultura: Towards Culturally Aligned Large Language Models?
Pith reviewed 2026-05-10 02:33 UTC · model grok-4.3
The pith
A UNESCO-grounded dataset and fine-tuning pipeline lets language models cut cultural failures by 18 percent while lifting joint HHH scores 4 to 6 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
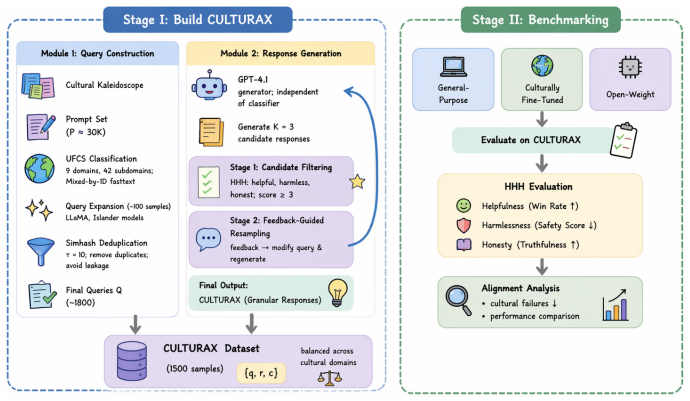
Align-Cultura is a pipeline whose first stage creates the CULTURAX dataset by reclassifying prompts to expand underrepresented cultural domains, applying SimHash to block leakage, and using two-stage rejection sampling to generate responses aligned with tangible and intangible cultural forms; its second stage evaluates general, culturally tuned, and open-weight models on this data, demonstrating 4-6 percent gains in joint HHH, 18 percent fewer cultural failures, 10-12 percent efficiency improvements, and leakage limited to 0.3 percent.
What carries the argument
The CULTURAX dataset of 1,500 HHH-aligned samples spanning 30 UNESCO cultural subdomains, produced by query reclassification, SimHash deduplication, and two-stage rejection sampling.
If this is right
- Models fine-tuned on CULTURAX deliver measurably higher joint HHH performance than untuned baselines.
- The same fine-tuning reduces the rate of culturally insensitive outputs by 18 percent.
- Efficiency gains of 10-12 percent accompany the alignment improvements.
- Data leakage stays below 0.3 percent when the SimHash step is applied during dataset creation.
Where Pith is reading between the lines
- The pipeline could be applied to non-English data to test whether the same gains appear outside English-dominant training distributions.
- Repeating the evaluation on additional open-weight models would clarify whether the reported improvements scale with model size or architecture.
- Embedding the UNESCO taxonomy directly into the reward model or loss function might produce alignment that does not require a separate fine-tuning stage.
Load-bearing premise
The methods of query construction, SimHash deduplication, and two-stage rejection sampling actually generate responses that reflect genuine cultural alignment with UNESCO principles rather than preferences introduced by the evaluators or the sampling process itself.
What would settle it
Independent ratings by cultural experts from varied regions who find that the generated responses systematically mismatch real cultural practices or introduce new stereotypes would show the alignment claim does not hold.
Figures








read the original abstract
Cultural alignment in Large Language Models (LLMs) is essential for producing contextually aware, respectful, and trustworthy outputs. Without it, models risk generating stereotyped, insensitive, or misleading responses that fail to reflect cultural diversity w.r.t Helpful, Harmless, and Honest (HHH) paradigm. Existing benchmarks represent early steps toward cultural alignment; yet, no benchmarks currently enables systematic evaluation of cultural alignment in line with UNESCO's principles of cultural diversity w.r.t HHH paradigm. Therefore, to address this gap, we built Align-Cultura, two-stage pipeline for cultural alignment. Stage I constructs CULTURAX, the HHH-English dataset grounded in the UNESCO cultural taxonomy, through Query Construction, which reclassifies prompts, expands underrepresented domains (or labels), and prevents data leakage with SimHash. Then, Response Generation pairs prompts with culturally grounded responses via two-stage rejection sampling. The final dataset contains 1,500 samples spanning 30 subdomains of tangible and intangible cultural forms. Stage II benchmarks CULTURAX on general-purpose models, culturally fine-tuned models, and open-weight LLMs (Qwen3-8B and DeepSeek-R1-Distill-Qwen-7B). Empirically, culturally fine-tuned models improve joint HHH by 4%-6%, reduce cultural failures by 18%, achieve 10%-12% efficiency gains, and limit leakage to 0.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Align-Cultura, a two-stage pipeline for culturally aligning LLMs with UNESCO principles under the HHH (Helpful, Harmless, Honest) framework. Stage I constructs the CULTURAX dataset (1,500 samples spanning 30 subdomains of tangible and intangible cultural forms) via query reclassification/expansion, SimHash deduplication to prevent leakage, and two-stage rejection sampling to generate culturally grounded responses. Stage II benchmarks general-purpose, culturally fine-tuned, and open-weight models (including Qwen3-8B and DeepSeek-R1-Distill-Qwen-7B), claiming that fine-tuned models yield 4-6% gains in joint HHH, 18% fewer cultural failures, 10-12% efficiency improvements, and 0.3% leakage.
Significance. A rigorously validated UNESCO-grounded dataset and alignment pipeline would be a useful contribution to the growing literature on culturally sensitive LLMs, offering a concrete resource beyond existing English-centric or ad-hoc cultural benchmarks. The reported efficiency and leakage reductions, if shown to generalize, could inform practical fine-tuning strategies. However, the absence of independent validation in the current manuscript substantially weakens the evidential basis for these claims.
major comments (2)
- [Abstract] The empirical results (4%-6% joint HHH lift, 18% cultural-failure reduction, etc.) are stated in the abstract without any information on benchmark sample sizes, statistical tests, exact metric definitions (e.g., how joint HHH or cultural failures are scored), baseline model versions, or error bars. This omission prevents verification that the deltas support the stated improvements.
- [Stage II] Stage II evaluates culturally fine-tuned models exclusively on the CULTURAX dataset produced by the identical two-stage pipeline (query construction + SimHash + two-stage rejection sampling) described in Stage I. No held-out test set, cross-taxonomy hold-out, or external human validation against UNESCO principles is described; therefore the observed gains may reflect overfitting to dataset-specific templates and constraints rather than transferable cultural alignment.
minor comments (2)
- [Abstract] The abstract introduces 'HHH' before expanding it; a parenthetical expansion on first use would improve readability.
- [Stage I] The description of how two-stage rejection sampling enforces UNESCO cultural taxonomy alignment is high-level; concrete criteria or examples of rejected vs. accepted responses would clarify the process.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and insightful comments on our work. We have addressed the major concerns raised by revising the manuscript to provide more details on the experimental results and by adding a discussion of the evaluation limitations. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract] The empirical results (4%-6% joint HHH lift, 18% cultural-failure reduction, etc.) are stated in the abstract without any information on benchmark sample sizes, statistical tests, exact metric definitions (e.g., how joint HHH or cultural failures are scored), baseline model versions, or error bars. This omission prevents verification that the deltas support the stated improvements.
Authors: We thank the referee for highlighting this issue. In the revised version of the manuscript, we have updated the abstract to include the necessary details. The benchmark uses the full set of 1,500 samples from CULTURAX. Joint HHH is computed as the average of the Helpful, Harmless, and Honest scores, each rated on a scale of 1 to 5 using an automated evaluator. Cultural failures are defined as responses that fail to respect the cultural elements as per the UNESCO taxonomy in the query. The baseline models are the original general-purpose versions of Qwen3-8B and DeepSeek-R1-Distill-Qwen-7B. We have added error bars representing the standard error across multiple evaluation runs in the results figures. Statistical significance of the improvements was determined using paired t-tests, with results reported in the main body of the paper. These additions should allow readers to better verify the reported gains. revision: yes
-
Referee: [Stage II] Stage II evaluates culturally fine-tuned models exclusively on the CULTURAX dataset produced by the identical two-stage pipeline (query construction + SimHash + two-stage rejection sampling) described in Stage I. No held-out test set, cross-taxonomy hold-out, or external human validation against UNESCO principles is described; therefore the observed gains may reflect overfitting to dataset-specific templates and constraints rather than transferable cultural alignment.
Authors: We appreciate the referee's point regarding the risk of overfitting. The CULTURAX dataset serves as both the training resource for fine-tuning and the evaluation benchmark to measure the effectiveness of the alignment process. The improvements observed are relative to the base models on the same set of culturally specific queries, indicating that the fine-tuning successfully teaches the models to generate more culturally aligned responses. The use of SimHash for deduplication and the two-stage rejection sampling helps ensure that the data is not overly repetitive or template-driven. Nevertheless, to strengthen the manuscript, we have revised the Stage II section to explicitly describe the evaluation setup and added a limitations section that acknowledges the absence of external human validation and suggests it as an important direction for future work. We believe this addresses the concern while maintaining the integrity of the current results. revision: partial
Circularity Check
No circularity: empirical dataset construction and benchmarking
full rationale
The paper presents an empirical contribution consisting of a two-stage pipeline (query construction with reclassification, SimHash deduplication, and two-stage rejection sampling to build the 1,500-sample CULTURAX dataset grounded in UNESCO taxonomy) followed by direct benchmarking of general-purpose, fine-tuned, and open-weight models on that dataset, reporting measured deltas in joint HHH, cultural failures, efficiency, and leakage. No equations, derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The reported improvements are observational outcomes of model evaluation rather than quantities that reduce by construction to the pipeline inputs or prior author results. The work is therefore self-contained as a dataset-plus-benchmarking effort without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption UNESCO cultural taxonomy accurately and comprehensively captures relevant dimensions of cultural diversity for evaluating LLM outputs
- domain assumption Joint HHH scores can serve as a valid proxy for cultural alignment when combined with the new dataset
Reference graph
Works this paper leans on
-
[1]
Trustworthy llms: a survey and guideline for evaluating large language models’ alignment
Trustworthy llms: a survey and guideline for evaluating large language models' alignment , author=. arXiv preprint arXiv:2308.05374 , year=
-
[2]
NPJ digital medicine , volume=
The ethics of ChatGPT in medicine and healthcare: a systematic review on Large Language Models (LLMs) , author=. NPJ digital medicine , volume=. 2024 , publisher=
2024
-
[3]
arXiv preprint arXiv:2409.11917 , year=
Llms in education: Novel perspectives, challenges, and opportunities , author=. arXiv preprint arXiv:2409.11917 , year=
-
[4]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
(A) I am not A lawyer, but...: engaging legal experts towards responsible LLM policies for legal advice , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[5]
Tekin, Selim Furkan and Ilhan, Fatih and Hu, Sihao and Huang, Tiansheng and Xu, Yichang and Yahn, Zachary and Liu, Ling , booktitle=. H
-
[6]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Uni-moe: Scaling unified multimodal llms with mixture of experts , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[7]
Branch-train-mix: Mixing expert llms into a mixture-of-experts llm , author=. arXiv preprint arXiv:2403.07816 , year=
-
[8]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Dialogue summarization with mixture of experts based on large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
arXiv preprint arXiv:2407.14093 , year=
Routing experts: Learning to route dynamic experts in multi-modal large language models , author=. arXiv preprint arXiv:2407.14093 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Read-ME: Refactorizing LLMs as Router-Decoupled Mixture of Experts with System Co-Design , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2309.10313 , year=
Investigating the catastrophic forgetting in multimodal large language models , author=. arXiv preprint arXiv:2309.10313 , year=
-
[12]
Conference on Parsimony and Learning , pages=
Investigating the catastrophic forgetting in multimodal large language model fine-tuning , author=. Conference on Parsimony and Learning , pages=. 2024 , organization=
2024
-
[13]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Analyzing and Reducing Catastrophic Forgetting in Parameter Efficient Tuning , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[14]
arXiv preprint arXiv:2403.16854 , year=
An expert is worth one token: Synergizing multiple expert llms as generalist via expert token routing , author=. arXiv preprint arXiv:2403.16854 , year=
-
[15]
Editing Models with Task Arithmetic
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
work page internal anchor Pith review arXiv
-
[16]
arXiv preprint arXiv:2309.14976 , year=
Mocae: Mixture of calibrated experts significantly improves object detection , author=. arXiv preprint arXiv:2309.14976 , year=
-
[17]
A Survey of Large Language Models
A survey of large language models , author=. arXiv preprint arXiv:2303.18223 , volume=
work page internal anchor Pith review arXiv
-
[18]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review arXiv
-
[19]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Safe rlhf: Safe reinforcement learning from human feedback , author=. arXiv preprint arXiv:2310.12773 , year=
work page internal anchor Pith review arXiv
-
[20]
Raft: Reward ranked finetuning for generative foundation model alignment , author=. arXiv preprint arXiv:2304.06767 , year=
-
[21]
arXiv preprint arXiv:2310.00212 , year=
Pairwise proximal policy optimization: Harnessing relative feedback for llm alignment , author=. arXiv preprint arXiv:2310.00212 , year=
-
[22]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[24]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Llama-moe: Building mixture-of-experts from llama with continual pre-training , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[25]
arXiv preprint arXiv:2305.14705 , year=
Mixture-of-experts meets instruction tuning: A winning combination for large language models , author=. arXiv preprint arXiv:2305.14705 , year=
-
[26]
2023 , publisher=
Stanford alpaca: An instruction-following llama model , author=. 2023 , publisher=
2023
-
[27]
Alpacaeval: An automatic evaluator of instruction-following models , author=
-
[28]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[30]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[32]
Monthly weather review , volume=
Verification of forecasts expressed in terms of probability , author=. Monthly weather review , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Aligner: Efficient alignment by learning to correct , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
arXiv preprint arXiv:2409.01586 (2024)
Booster: Tackling harmful fine-tuning for large language models via attenuating harmful perturbation , author=. arXiv preprint arXiv:2409.01586 , year=
-
[36]
Unlocking Decoding-time Controllability: Gradient-Free Multi-Objective Alignment with Contrastive Prompts , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[37]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Arithmetic Control of LLMs for Diverse User Preferences: Directional Preference Alignment with Multi-Objective Rewards , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
NeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability , year=
HyperDPO: Conditioned One-Shot Multi-Objective Fine-Tuning Framework , author=. NeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability , year=
2024
-
[39]
Advances in Neural Information Processing Systems , volume=
Metaaligner: Towards generalizable multi-objective alignment of language models , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
arXiv preprint arXiv:2503.07119 , year=
Improving Deep Ensembles by Estimating Confusion Matrices , author=. arXiv preprint arXiv:2503.07119 , year=
-
[41]
Forty-second International Conference on Machine Learning , year=
Whoever Started the interference Should End It: Guiding Data-Free Model Merging via Task Vectors , author=. Forty-second International Conference on Machine Learning , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Knowledge composition using task vectors with learned anisotropic scaling , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Fractal Calibration for long-tailed object detection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[44]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[45]
International Conference on Learning Representations , year=
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding , author=. International Conference on Learning Representations , year=
-
[46]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[47]
22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25) , pages=
Optimizing \ RLHF \ training for large language models with stage fusion , author=. 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25) , pages=
-
[48]
Advances in Neural Information Processing Systems , volume=
Honestllm: Toward an honest and helpful large language model , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Normative conflicts and shallow AI alignment: R
Milli. Normative conflicts and shallow AI alignment: R. Milli. Philosophical Studies , pages=. 2025 , publisher=
2025
-
[50]
Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI Feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[53]
Proceedings of the National Academy of Sciences (PNAS) , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences (PNAS) , volume=
-
[54]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Deep Reinforcement Learning from Human Preferences , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Defining and Characterizing Reward Hacking , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[56]
International Conference on Machine Learning (ICML) , year=
Understanding Dataset Difficulty with V-Usable Information , author=. International Conference on Machine Learning (ICML) , year=
-
[57]
o pf, Yannic Kilcher, Dimitri von R \
OpenAssistant Conversations - Democratizing Large Language Model Alignment , author=. arXiv preprint arXiv:2304.07327 , year=
-
[58]
arXiv preprint arXiv:2305.14825 , year=
Catastrophic Forgetting in Fine-Tuned Language Models , author=. arXiv preprint arXiv:2305.14825 , year=
-
[59]
TACL , year=
Modular Adaptation for Multitask Learning in Language Models , author=. TACL , year=
-
[60]
EMNLP , year=
Adapter-Based Routing for Efficient Multi-Task Learning , author=. EMNLP , year=
-
[61]
EMNLP , year=
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models , author=. EMNLP , year=
-
[62]
Fine-Tuning Language Models from Human Preferences
Fine-Tuning Language Models from Human Preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review arXiv 1909
-
[63]
ICLR , year=
Editing Models with Task Arithmetic , author=. ICLR , year=
-
[64]
NeurIPS , year=
Task Composition for Zero-Shot Transfer Learning , author=. NeurIPS , year=
-
[65]
arXiv preprint arXiv:2308.03225 , year=
A Survey on Alignment in Large Language Models , author=. arXiv preprint arXiv:2308.03225 , year=
-
[66]
ICLR , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. ICLR , year=
-
[67]
NeurIPS , year=
Towards Efficient and Scalable Adaptation of Large Language Models , author=. NeurIPS , year=
-
[68]
ICML , year=
RLAIF: Scaling Reinforcement Learning from AI Feedback , author=. ICML , year=
-
[69]
International Conference on Machine Learning (ICML) , pages=
MARL-Focal: Multi-Axis Alignment via Dynamic Reward Decomposition , author=. International Conference on Machine Learning (ICML) , pages=. 2023 , url=
2023
-
[70]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Multi-Agent Reinforcement Learning for Aligning Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=. 2023 , url=
2023
-
[71]
International Conference on Learning Representations (ICLR) , year=
MARL for Multi-Objective Alignment of Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[72]
Transactions on Machine Learning Research (TMLR) , year=
Multi-Agent Reinforcement Learning for LLM Alignment , author=. Transactions on Machine Learning Research (TMLR) , year=
-
[74]
In Findings of the Association for Computational Linguistics: ACL 2024, pages 4998–5017, 2024
Disentangling length from quality in direct preference optimization , author=. arXiv preprint arXiv:2403.19159 , year=
-
[75]
Advances in Neural Information Processing Systems , volume=
Simpo: Simple preference optimization with a reference-free reward , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
WPO: Enhancing RLHF with Weighted Preference Optimization , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[77]
Advances in neural information processing systems , volume=
Transformer in transformer , author=. Advances in neural information processing systems , volume=
-
[78]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Too Helpful, Too Harmless, Too Honest or Just Right? , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[79]
Advances in neural information processing systems , volume=
Language Models are Few-Shot Learners , author=. Advances in neural information processing systems , volume=
-
[80]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[81]
2023 , howpublished=
GPT-4 Technical Report , author=. 2023 , howpublished=
2023
-
[84]
Aligning AI with Shared Human Values , author=. arXiv preprint arXiv:2008.02275 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.