Recognition: unknown
Intentional Updates for Streaming Reinforcement Learning
Pith reviewed 2026-05-10 03:41 UTC · model grok-4.3
The pith
Specifying desired function changes first then solving for step sizes stabilizes streaming reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Intentional updates achieve stable streaming deep reinforcement learning by first defining an intended outcome for each update and then solving for the step size that approximately achieves it. Intentional TD targets a fixed fractional reduction of the TD error. Intentional Policy Gradient targets a bounded per-step change in the policy that limits local KL divergence. Practical implementations combine these rules with eligibility traces and diagonal scaling, and empirical results show state-of-the-art performance in the streaming regime, frequently matching batch and replay-buffer baselines.
What carries the argument
The intentional update rule: specify the intended outcome (fixed fractional TD error reduction or bounded policy change limiting local KL divergence) and solve for the step size that approximately produces it, then combine with eligibility traces and diagonal scaling.
If this is right
- Agents can perform stable value and policy updates from individual experiences without storing past data in a replay buffer.
- Streaming performance can reach levels previously associated only with batch or offline methods that reuse data.
- The normalized least mean squares principle from supervised learning extends directly to both temporal-difference and policy-gradient updates in RL.
- Diagonal scaling makes the step-size solution tractable for deep networks while preserving the intentional property.
- Eligibility traces integrate with the intentional framework to handle credit assignment over multiple steps.
Where Pith is reading between the lines
- Real-time systems such as robotics controllers could adopt this approach to learn continuously from live interaction without memory for replay.
- The bounded local KL target might offer an alternative route to controlling policy change that complements or replaces explicit entropy regularization.
- Non-stationary environments could be used to test whether the fixed fractional error reduction remains appropriate or requires online adjustment of the target fraction.
- Similar intentional framing might be applied to other gradient-based online learners outside RL to derive step-size rules from desired output changes.
Load-bearing premise
That defining intended outcomes as a fixed fractional reduction of the TD error and a bounded per-step change in the policy will produce stable and effective learning when combined with eligibility traces and diagonal scaling in deep networks.
What would settle it
A streaming RL experiment on a standard benchmark in which the intentional TD and policy-gradient updates with traces and diagonal scaling produce divergence or markedly lower returns than replay-buffer methods.
Figures






read the original abstract
In gradient-based learning, a step size chosen in parameter units does not produce a predictable per-step change in function output. This often leads to instability in the streaming setting (i.e., batch size=1), where stochasticity is not averaged out and update magnitudes can momentarily become arbitrarily big or small. Instead, we propose intentional updates: first specify the intended outcome of an update and then solve for the step size that approximately achieves it. This strategy has precedent in online supervised linear regression via Normalized Least Mean Squares algorithm, which selects a step size to yield a specified change in the function output proportional to the current error. We extend this principle to streaming deep reinforcement learning by defining appropriate intended outcomes: Intentional TD aims for a fixed fractional reduction of the TD error, and Intentional Policy Gradient aims for a bounded per-step change in the policy, limiting local KL divergence. We propose practical algorithms combining eligibility traces and diagonal scaling. Empirically, these methods yield state-of-the-art streaming performance, frequently performing on par with batch and replay-buffer approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes intentional updates for streaming RL (batch size 1), where step sizes are solved to achieve explicitly defined intended outcomes in function space: a fixed fractional reduction of the TD error for value learning, and a bounded per-step policy change (limiting local KL divergence) for policy gradients. These are combined with eligibility traces and diagonal scaling to yield practical algorithms, with the central claim being that the resulting methods achieve state-of-the-art streaming performance, frequently matching batch and replay-buffer baselines.
Significance. If the empirical claims hold under rigorous verification, the work offers a principled alternative to ad-hoc step-size tuning or replay buffers in online deep RL by directly controlling update effects in output space. It usefully extends the NLMS idea from linear supervised learning to nonlinear RL settings and could improve stability in truly streaming regimes where stochasticity is not averaged.
major comments (3)
- [§3] §3 (Intentional TD derivation): the step-size solution for a fixed fractional TD-error reduction is derived under a local linearity assumption on the TD error with respect to the parameter update (after eligibility trace and diagonal scaling). This is exact only for linear models; the manuscript provides no error bound or analysis showing how well the realized post-update TD error matches the target in deep nonlinear networks, which is load-bearing for the stability claim in the batch-size=1 regime.
- [§4] §4 (Intentional Policy Gradient): the KL-divergence bound is enforced via a solved step size under a diagonal approximation to the policy output curvature. The paper does not quantify the deviation from the target KL increment when off-diagonal terms are ignored or when the network is deep, directly affecting whether the intended bounded change is actually achieved in streaming updates.
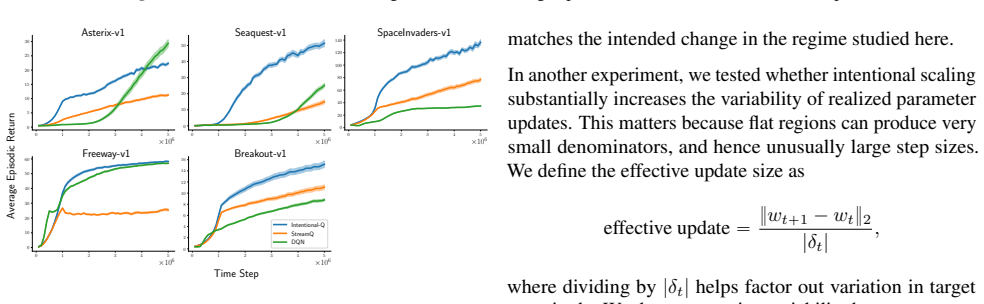
- [§5] §5 (Experiments): the central empirical claim of SOTA streaming performance (frequently on par with batch/replay methods) is presented without reported details on the number of random seeds, statistical significance tests, or exact baseline implementations and hyperparameter matching, making it impossible to assess whether the performance advantage is robust or reproducible.
minor comments (3)
- [§3] The notation distinguishing the intended fractional reduction target from the realized TD error after the update could be made more explicit to avoid reader confusion.
- [Introduction] A reference to the original NLMS algorithm and its convergence properties should be added in the introduction for context.
- [§5] Figure captions for the streaming performance plots should include the precise environment names and whether results are averaged over seeds.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (Intentional TD derivation): the step-size solution for a fixed fractional TD-error reduction is derived under a local linearity assumption on the TD error with respect to the parameter update (after eligibility trace and diagonal scaling). This is exact only for linear models; the manuscript provides no error bound or analysis showing how well the realized post-update TD error matches the target in deep nonlinear networks, which is load-bearing for the stability claim in the batch-size=1 regime.
Authors: We agree that the derivation relies on a local linearity assumption that holds exactly only for linear approximators. For deep networks the step-size computation is necessarily an approximation. The manuscript does not supply a formal error bound on the mismatch between target and realized TD-error reduction. We will revise §3 to explicitly state this limitation and add a short empirical analysis (new figure or table) that reports the actual fractional TD-error reduction achieved after each intentional update on the deep-network tasks, thereby providing direct evidence that the approximation remains effective in the regimes studied. revision: partial
-
Referee: §4 (Intentional Policy Gradient): the KL-divergence bound is enforced via a solved step size under a diagonal approximation to the policy output curvature. The paper does not quantify the deviation from the target KL increment when off-diagonal terms are ignored or when the network is deep, directly affecting whether the intended bounded change is actually achieved in streaming updates.
Authors: The diagonal approximation to the output curvature is indeed a practical simplification; the manuscript does not quantify the resulting deviation from the target per-step KL increment. We will revise §4 to include an empirical quantification—reporting both the intended KL bound and the realized KL change (computed via Monte-Carlo sampling of the policy outputs) across training on the evaluated environments—so that readers can assess how closely the bound is respected under the diagonal approximation. revision: partial
-
Referee: §5 (Experiments): the central empirical claim of SOTA streaming performance (frequently on par with batch/replay methods) is presented without reported details on the number of random seeds, statistical significance tests, or exact baseline implementations and hyperparameter matching, making it impossible to assess whether the performance advantage is robust or reproducible.
Authors: The referee correctly identifies that the experimental section lacks these reproducibility details. We will expand §5 (and the associated appendix) to report the exact number of random seeds, mean and standard-deviation performance curves, any statistical significance tests performed, and precise descriptions of baseline implementations together with the hyperparameter values used for both our methods and the baselines. revision: yes
Circularity Check
No significant circularity detected in the derivation of intentional updates
full rationale
The paper's derivation explicitly defines intended outcomes (fixed fractional TD-error reduction and bounded per-step policy change limiting local KL) and solves for the step size to approximately achieve them, extending the NLMS precedent from linear regression. This is a direct construction based on stated targets plus eligibility traces and diagonal scaling, without any reduction of a claimed prediction to a fitted input, self-definition of variables in terms of each other, or load-bearing reliance on self-citations. The approximations (local linearity, diagonal scaling) are part of the method's stated heuristic nature rather than a hidden circularity. Empirical claims are presented separately as validation and do not close any loop back to the derivation inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- fractional TD error reduction target
- KL divergence bound
axioms (1)
- domain assumption Specifying intended function-output changes and solving for step size yields stable streaming updates in deep RL
Reference graph
Works this paper leans on
-
[1]
Machine Learning Proceedings 1995 , publisher =
Residual Algorithms: Reinforcement Learning with Function Approximation , editor =. Machine Learning Proceedings 1995 , publisher =. 1995 , isbn =. doi:https://doi.org/10.1016/B978-1-55860-377-6.50013-X , author =
-
[2]
Tom Schaul and Georg Ostrovski and Iurii Kemaev and Diana Borsa , title =. CoRR , volume =. 2021 , url =. 2105.05347 , timestamp =
-
[3]
Hyperspherical normalization for scalable deep reinforcement learning , author=. arXiv preprint arXiv:2502.15280 , year=
-
[4]
2015 , eprint =
Continuous control with deep reinforcement learning , author =. 2015 , eprint =
2015
-
[5]
Proceedings of the 35th International Conference on Machine Learning,
Scott Fujimoto and Herke van Hoof and David Meger , title =. Proceedings of the 35th International Conference on Machine Learning,. 2018 , url =
2018
-
[6]
Proceedings of the 35th International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[7]
Gautham Vasan and Mohamed Elsayed and Seyed Alireza Azimi and Jiamin He and Fahim Shahriar and Colin Bellinger and Martha White and Rupam Mahmood , title =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[8]
2018 , edition=
Reinforcement Learning: An Introduction , author=. 2018 , edition=
2018
-
[9]
Machine Learning , volume=
Learning to predict by the methods of temporal differences , author=. Machine Learning , volume=. 1988 , publisher=
1988
-
[10]
Sutton and David A
Richard S. Sutton and David A. McAllester and Satinder Singh and Yishay Mansour , title =. Advances in Neural Information Processing Systems 12,
-
[11]
Williams , title =
Ronald J. Williams , title =. Mach. Learn. , volume =. 1992 , doi =
1992
-
[12]
Streaming Deep Reinforcement Learning Finally Works , author =. arXiv preprint , year =. 2410.14606 , eprinttype =
-
[13]
Proceedings of the Twenty-Sixth
Adaptive Step-Size for Online Temporal Difference Learning , author =. Proceedings of the Twenty-Sixth. 2012 , doi =
2012
-
[14]
, journal =
Javed, Khurram and Sharifnassab, Arsalan and Sutton, Richard S. , journal =
-
[15]
Proceedings of the
Tuning-Free Step-Size Adaptation , author =. Proceedings of the. 2012 , organization =
2012
-
[16]
Proceedings of the Tenth National Conference on Artificial Intelligence (
Adapting Bias by Gradient Descent: An Incremental Version of Delta-Bar-Delta , author =. Proceedings of the Tenth National Conference on Artificial Intelligence (
-
[17]
Adaptive Switching Circuits , author =. 1960. 1960 , organization =
1960
-
[18]
1967 , doi =
A Learning Method for System Identification , author =. 1967 , doi =
1967
-
[19]
Adaptive Filter Theory , author =
-
[20]
Proceedings of the 32nd International Conference on Machine Learning (
Trust Region Policy Optimization , author =. Proceedings of the 32nd International Conference on Machine Learning (. 2015 , publisher =
2015
-
[21]
CoRR , volume =
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , title =. CoRR , volume =. 2017 , url =
2017
-
[22]
Machine Learning , volume =
Learning to Predict by the Methods of Temporal Differences , author =. Machine Learning , volume =. 1988 , doi =
1988
-
[23]
Reinforcement Learning: An Introduction , author =
-
[24]
Lecture 6.5---
Tieleman, Tijmen and Hinton, Geoffrey , howpublished =. Lecture 6.5---
-
[25]
2012 , organization =
Todorov, Emanuel and Erez, Tom and Tassa, Yuval , booktitle =. 2012 , organization =
2012
-
[26]
DeepMind Control Suite , author =. arXiv preprint , year =. 1801.00690 , eprinttype =
work page internal anchor Pith review arXiv
-
[27]
Journal of Artificial Intelligence Research , volume =
The Arcade Learning Environment: An Evaluation Platform for General Agents , author =. Journal of Artificial Intelligence Research , volume =. 2013 , doi =
2013
-
[28]
Nature , volume =
Loss of Plasticity in Deep Continual Learning , author =. Nature , volume =. 2024 , doi =
2024
-
[29]
Proceedings of the
Meta-Descent for Online, Continual Prediction , author =. Proceedings of the
-
[30]
Advances in Neural Information Processing Systems , volume =
Deep Policy Gradient Methods Without Batch Updates, Target Networks, or Replay Buffers , author =. Advances in Neural Information Processing Systems , volume =. 2024 , address =
2024
-
[31]
Journal of Machine Learning Research , volume =
True Online Temporal-Difference Learning , author =. Journal of Machine Learning Research , volume =. 2016 , url =
2016
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Expected Eligibility Traces , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2021 , doi =
2021
-
[33]
1987 , isbn =
Introduction to Optimization , author =. 1987 , isbn =
1987
-
[34]
Stochastic Polyak Step-size for
Loizou, Nicolas and Vaswani, Sharan and Hadj Laradji, Issam and Lacoste-Julien, Simon , booktitle =. Stochastic Polyak Step-size for. 2021 , editor =
2021
-
[35]
2010 , type =
Automatic Step-size Adaptation in Incremental Supervised Learning , author =. 2010 , type =
2010
-
[36]
Forty-second International Conference on Machine Learning , year=
MetaOptimize: A Framework for Optimizing Step Sizes and Other Meta-parameters , author=. Forty-second International Conference on Machine Learning , year=
-
[37]
Continuous control with deep reinforcement learning
Continuous Control with Deep Reinforcement Learning , author =. International Conference on Learning Representations , year =. 1509.02971 , eprinttype =
work page internal anchor Pith review arXiv
-
[38]
International Conference on Machine Learning , series =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. International Conference on Machine Learning , series =. 2018 , publisher =
2018
-
[39]
1984 , publisher=
Adaptive Filtering Prediction and Control , author=. 1984 , publisher=
1984
-
[40]
International Conference on Learning Representations (ICLR) , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations (ICLR) , year=
-
[41]
Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude , author=
-
[42]
, journal=
Amari, S. , journal=. Natural gradient works efficiently in learning , year=
-
[43]
A Natural Policy Gradient , volume =
Kakade, Sham M , booktitle =. A Natural Policy Gradient , volume =
-
[44]
Proceedings of the 35th International Conference on Machine Learning , series =
Time Limits in Reinforcement Learning , author =. Proceedings of the 35th International Conference on Machine Learning , series =. 2018 , editor =
2018
-
[45]
arXiv preprint arXiv:1903.03176 , year=
MinAtar: An Atari-Inspired Testbed for Thorough and Reproducible Reinforcement Learning Experiments , author =. 2019 , journal =. 1903.03176 , archivePrefix =
-
[46]
Proceedings of the Thirty-Second
Matteo Hessel and Joseph Modayil and Hado van Hasselt and Tom Schaul and Georg Ostrovski and Will Dabney and Dan Horgan and Bilal Piot and Mohammad Gheshlaghi Azar and David Silver , title =. Proceedings of the Thirty-Second. 2018 , doi =
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.