Recognition: unknown
STK-Adapter: Incorporating Evolving Graph and Event Chain for Temporal Knowledge Graph Extrapolation
Pith reviewed 2026-05-10 02:36 UTC · model grok-4.3
The pith
The STK-Adapter integrates spatial-temporal information from evolving graphs and event chains into large language models via mixture-of-experts modules for improved temporal knowledge graph extrapolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Spatial-Temporal Knowledge Adapter flexibly combines an evolving graph encoder with a large language model through Spatial-Temporal MoE for capturing structures and patterns, Event-Aware MoE for temporal dependencies in events, and Cross-Modality Alignment MoE for TKG-guided deep alignment, thereby addressing information loss and feature dilution in TKG extrapolation.
What carries the argument
Spatial-Temporal Knowledge Adapter (STK-Adapter) using three mixture-of-experts modules for spatial-temporal capture, event awareness, and cross-modality alignment.
Load-bearing premise
The proposed mixture-of-experts modules successfully achieve deep cross-modality alignment and preserve the TKG's evolving structural features without introducing new losses or overfitting during LLM fine-tuning.
What would settle it
Conducting the reported experiments on the benchmark datasets and finding that STK-Adapter does not significantly outperform prior methods in extrapolation metrics or cross-dataset performance.
Figures







read the original abstract
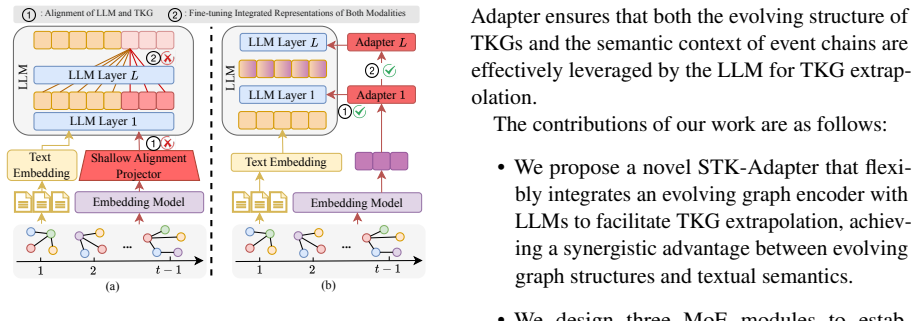
Temporal Knowledge Graph (TKG) extrapolation aims to predict future events based on historical facts. Recent studies have attempted to enhance TKG extrapolation by integrating TKG's evolving structural representations and textual event chains into Large Language Models (LLMs). Yet, two main challenges limit these approaches: (1) The loss of essential spatial-temporal information due to shallow alignment between TKG's graph evolving structural representation and the LLM's semantic space, and (2) the progressive dilution of the TKG's evolving structural features during LLM fine-tuning. To address these challenges, we propose the Spatial-Temporal Knowledge Adapter (STK-Adapter), which flexibly integrates the evolving graph encoder and the LLM to facilitate TKG reasoning. In STK-Adapter, a Spatial-Temporal MoE is designed to capture spatial structures and temporal patterns inherent in TKGs. An Event-Aware MoE is employed to model intricate temporal semantics dependencies within event chains. In addition, a Cross-Modality Alignment MoE is proposed to facilitate deep cross-modality alignment by TKG-guided attention experts. Extensive experiments on benchmark datasets demonstrate that STK-Adapter significantly outperforms state-of-the-art methods and exhibits strong generalization capabilities in cross-dataset task. The code is available at https://github.com/Zhaoshuyuan0246/STK-Adapter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Spatial-Temporal Knowledge Adapter (STK-Adapter) for temporal knowledge graph (TKG) extrapolation. It integrates an evolving graph encoder with large language models (LLMs) using three Mixture-of-Experts (MoE) components: a Spatial-Temporal MoE to capture spatial structures and temporal patterns in TKGs, an Event-Aware MoE to model temporal semantics dependencies in event chains, and a Cross-Modality Alignment MoE with TKG-guided attention experts to achieve deep cross-modality alignment. The approach targets two challenges—loss of spatial-temporal information from shallow alignment and progressive dilution of evolving structural features during LLM fine-tuning—and reports that extensive experiments on benchmark datasets show significant outperformance over state-of-the-art methods along with strong cross-dataset generalization. Code is released at the provided GitHub link.
Significance. If the empirical claims hold with adequate mechanistic support, the work would offer a modular adapter architecture that better preserves graph evolution when interfacing TKGs with LLMs, potentially improving extrapolation accuracy and generalization in temporal reasoning tasks. The open-sourcing of code supports reproducibility, which strengthens the contribution if the MoE routing and alignment mechanisms prove robust.
major comments (2)
- [Methods (MoE subsections)] Methods section describing the three MoE modules: the central claim that Spatial-Temporal MoE, Event-Aware MoE, and Cross-Modality Alignment MoE (with TKG-guided attention experts) resolve shallow alignment and feature dilution rests on an assertion that expert routing and attention prevent LLM overwriting of graph structure, but no equations for routing functions, attention computation, or training objectives are supplied to demonstrate this mechanistically.
- [Experiments] Experimental results and ablation sections: the abstract states that STK-Adapter 'significantly outperforms' SOTA methods and shows 'strong generalization' in cross-dataset tasks, yet no quantitative metrics, ablation tables isolating each MoE's contribution, error bars, or details on how the experts are trained appear in the provided description, leaving the load-bearing empirical support unverified.
minor comments (1)
- [Abstract] The abstract refers to 'benchmark datasets' without naming them or the specific metrics used; adding these would improve clarity even if they appear later in the paper.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We will revise the manuscript to strengthen the methodological rigor and empirical presentation as outlined below.
read point-by-point responses
-
Referee: [Methods (MoE subsections)] Methods section describing the three MoE modules: the central claim that Spatial-Temporal MoE, Event-Aware MoE, and Cross-Modality Alignment MoE (with TKG-guided attention experts) resolve shallow alignment and feature dilution rests on an assertion that expert routing and attention prevent LLM overwriting of graph structure, but no equations for routing functions, attention computation, or training objectives are supplied to demonstrate this mechanistically.
Authors: We acknowledge that the current Methods section provides high-level descriptions of the three MoE modules without the explicit mathematical formulations. In the revised manuscript we will add the equations for the expert routing functions (including the gating mechanism), the TKG-guided attention computation within the Cross-Modality Alignment MoE, and the composite training objective. These additions will directly illustrate how the routing and attention mechanisms are designed to preserve evolving graph structure and prevent overwriting during LLM fine-tuning. revision: yes
-
Referee: [Experiments] Experimental results and ablation sections: the abstract states that STK-Adapter 'significantly outperforms' SOTA methods and shows 'strong generalization' in cross-dataset tasks, yet no quantitative metrics, ablation tables isolating each MoE's contribution, error bars, or details on how the experts are trained appear in the provided description, leaving the load-bearing empirical support unverified.
Authors: The full manuscript reports experimental results on standard TKG benchmarks and cross-dataset generalization. To make the empirical support fully verifiable, we will expand the Experiments section with complete quantitative tables (including exact metric values), ablation studies that isolate the contribution of each MoE component, error bars computed over multiple random seeds, and additional details on expert training procedures and routing statistics. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmarks rather than any derivation chain.
full rationale
The paper introduces the STK-Adapter architecture with Spatial-Temporal MoE, Event-Aware MoE, and Cross-Modality Alignment MoE to integrate TKG evolving graphs and event chains into LLMs. Its central claims of outperformance and cross-dataset generalization are asserted via experimental results on benchmark datasets, with no mathematical derivation, first-principles equations, or predictive steps that reduce by construction to fitted inputs, self-citations, or ansatzes. The work contains no load-bearing uniqueness theorems, self-definitional relations, or renamed known results; it is a standard empirical architecture proposal whose validity is externally falsifiable through replication of the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mixture-of-experts routing can selectively preserve structural features that would otherwise be diluted during LLM fine-tuning.
- domain assumption Deep cross-modality alignment via TKG-guided attention experts is feasible and superior to shallow alignment.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI conference on artificial intelligence , volume=
Learning from history: Modeling temporal knowledge graphs with sequential copy-generation networks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[2]
Proceedings of the AAAI conference on artificial intelligence , volume=
Temporal knowledge graph reasoning with historical contrastive learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[3]
Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
Temporal knowledge graph reasoning based on evolutional representation learning , author=. Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[4]
The semantic web: 15th international conference, ESWC 2018, Heraklion, Crete, Greece, June 3--7, 2018, proceedings 15 , pages=
Modeling relational data with graph convolutional networks , author=. The semantic web: 15th international conference, ESWC 2018, Heraklion, Crete, Greece, June 3--7, 2018, proceedings 15 , pages=. 2018 , organization=
2018
-
[5]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Empirical evaluation of gated recurrent neural networks on sequence modeling , author=. arXiv preprint arXiv:1412.3555 , year=
work page internal anchor Pith review arXiv
-
[6]
International conference on learning representations , year=
Explainable subgraph reasoning for forecasting on temporal knowledge graphs , author=. International conference on learning representations , year=
-
[7]
, author=
TiRGN: Time-Guided Recurrent Graph Network with Local-Global Historical Patterns for Temporal Knowledge Graph Reasoning. , author=. IJCAI , pages=
-
[8]
2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=
Local-global history-aware contrastive learning for temporal knowledge graph reasoning , author=. 2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=. 2024 , organization=
2024
-
[9]
arXiv preprint arXiv:2109.04101 , year=
Timetraveler: Reinforcement learning for temporal knowledge graph forecasting , author=. arXiv preprint arXiv:2109.04101 , year=
-
[10]
Proceedings of the AAAI conference on artificial intelligence , volume=
Tlogic: Temporal logical rules for explainable link forecasting on temporal knowledge graphs , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
CognTKE: A Cognitive Temporal Knowledge Extrapolation Framework , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[12]
ACM transactions on intelligent systems and technology , volume=
A survey on evaluation of large language models , author=. ACM transactions on intelligent systems and technology , volume=. 2024 , publisher=
2024
-
[13]
arXiv preprint arXiv:2305.07912 , year=
Pre-trained language model with prompts for temporal knowledge graph completion , author=. arXiv preprint arXiv:2305.07912 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Large language models-guided dynamic adaptation for temporal knowledge graph reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the ACM Web Conference 2024 , pages=
Graphtranslator: Aligning graph model to large language model for open-ended tasks , author=. Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[19]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
KG-adapter: Enabling knowledge graph integration in large language models through parameter-efficient fine-tuning , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[21]
arXiv preprint arXiv:1904.05530 , year=
Recurrent event network: Autoregressive structure inference over temporal knowledge graphs , author=. arXiv preprint arXiv:1904.05530 , year=
-
[22]
arXiv preprint arXiv:2203.07782 , year=
Complex evolutional pattern learning for temporal knowledge graph reasoning , author=. arXiv preprint arXiv:2203.07782 , year=
-
[23]
arXiv preprint arXiv:2210.09708 , year=
Hismatch: Historical structure matching based temporal knowledge graph reasoning , author=. arXiv preprint arXiv:2210.09708 , year=
-
[24]
2023 IEEE 39th international conference on data engineering (ICDE) , pages=
RETIA: relation-entity twin-interact aggregation for temporal knowledge graph extrapolation , author=. 2023 IEEE 39th international conference on data engineering (ICDE) , pages=. 2023 , organization=
2023
-
[26]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Hyte: Hyperplane-based temporally aware knowledge graph embedding , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[28]
Advances in Neural Information Processing Systems , volume=
Are language models actually useful for time series forecasting? , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs , booktitle =
Yimin Deng and Yuxia Wu and Yejing Wang and Guoshuai Zhao and Li Zhu and Qidong Liu and Derong Xu and Zichuan Fu and Xian Wu and Yefeng Zheng and Xiangyu Zhao and Xueming Qian , editor =. A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs , booktitle =. 2025 , url =
2025
-
[31]
and Jordan, Michael I
Jacobs, Robert A. and Jordan, Michael I. and Nowlan, Steven J. and Hinton, Geoffrey E. , journal=. Adaptive Mixtures of Local Experts , year=
-
[32]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
2022
-
[33]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Spatial-Temporal Knowledge Distillation for Takeaway Recommendation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
Advances in neural information processing systems , volume=
Sequence to sequence learning with neural networks , author=. Advances in neural information processing systems , volume=
-
[39]
arXiv preprint arXiv:2503.20633 , year=
Enhancing Multi-modal Models with Heterogeneous MoE Adapters for Fine-tuning , author=. arXiv preprint arXiv:2503.20633 , year=
-
[40]
Proceedings of the 32nd ACM international conference on information and knowledge management , pages=
St-moe: Spatio-temporal mixture-of-experts for debiasing in traffic prediction , author=. Proceedings of the 32nd ACM international conference on information and knowledge management , pages=
-
[43]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[44]
The Thirteenth International Conference on Learning Representations , year=
HMoRA: Making LLMs more effective with hierarchical mixture of loRA experts , author=. The Thirteenth International Conference on Learning Representations , year=
-
[45]
Advances in Neural Information Processing Systems , volume=
Fusemoe: Mixture-of-experts transformers for fleximodal fusion , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[48]
ArXiv , year=
Mistral 7B , author=. ArXiv , year=
-
[49]
Wang, Jing and Zhang, Shuo and Li, Runzhi , Title =. DATA INTELLIGENCE , Year =. doi:10.3724/2096-7004.di.2024.0023 , Keywords =
-
[50]
Xiao, Peng and Liu, Chao and Jia, Wei and Dong, Lijun , Title =. DATA INTELLIGENCE , Year =. doi:10.3724/2096-7004.di.2025.0023 , Keywords =
-
[54]
Knowledge-Based Systems , pages=
Dual-view Temporal Knowledge Graph Reasoning , author=. Knowledge-Based Systems , pages=. 2025 , publisher=
2025
-
[55]
IEEE Transactions on Knowledge and Data Engineering , year=
Next-POI Recommendation via Spatial-Temporal Knowledge Graph Contrastive Learning and Trajectory Prompt , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[56]
Applied Intelligence , volume=
Exploiting multi-attention network with contextual influence for point-of-interest recommendation , author=. Applied Intelligence , volume=. 2021 , publisher=
2021
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Think How Your Teammates Think: Active Inference Can Benefit Decentralized Execution , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[59]
Pattern Recognition , pages=
PUA: Pseudo-Features Made Useful Again for Robust Graph Node Classification under Distribution Shift , author=. Pattern Recognition , pages=. 2026 , publisher=
2026
-
[60]
AI@Meta. 2024. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md Llama 3 model card
2024
-
[61]
Elizabeth Boschee, Jennifer Lautenschlager, Sean O'Brien, Steve Shellman, James Starz, and Michael Ward. 2015. https://doi.org/10.7910/DVN/28075 ICEWS Coded Event Data
- [62]
-
[63]
Huajun Chen. 2024. https://doi.org/10.3724/2096-7004.di.2024.0001 Large knowledge model: Perspectives and challenges . DATA INTELLIGENCE, 6(3):587--620
-
[64]
Wei Chen, Haoyu Huang, Zhiyu Zhang, Tianyi Wang, Youfang Lin, Liang Chang, and Huaiyu Wan. 2025 a . Next-poi recommendation via spatial-temporal knowledge graph contrastive learning and trajectory prompt. IEEE Transactions on Knowledge and Data Engineering
2025
-
[65]
Wei Chen, Huaiyu Wan, Yuting Wu, Shuyuan Zhao, Jiayaqi Cheng, Yuxin Li, and Youfang Lin. 2024. Local-global history-aware contrastive learning for temporal knowledge graph reasoning. In 2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 733--746. IEEE
2024
-
[66]
Wei Chen, Yuting Wu, Shengnan Guo, Shuhan Wu, Zhishu Jiang, Youfang Lin, and Huaiyu Wan. 2025 b . Dual-view temporal knowledge graph reasoning. Knowledge-Based Systems, page 114330
2025
-
[67]
Wei Chen, Yuting Wu, Shuhan Wu, Zhiyu Zhang, Mengqi Liao, Youfang Lin, and Huaiyu Wan. 2025 c . Cogntke: A cognitive temporal knowledge extrapolation framework. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14815--14823
2025
- [68]
-
[69]
Shib Sankar Dasgupta, Swayambhu Nath Ray, and Partha Talukdar. 2018. Hyte: Hyperplane-based temporally aware knowledge graph embedding. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 2001--2011
2018
-
[70]
Yimin Deng, Yuxia Wu, Yejing Wang, Guoshuai Zhao, Li Zhu, Qidong Liu, Derong Xu, Zichuan Fu, Xian Wu, Yefeng Zheng, Xiangyu Zhao, and Xueming Qian. 2025. https://aclanthology.org/2025.findings-acl.1056/ A multi-expert structural-semantic hybrid framework for unveiling historical patterns in temporal knowledge graphs . In Findings of the Association for Co...
2025
-
[71]
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Wei Shen, Limao Xiong, Yuhao Zhou, Xiao Wang, Zhiheng Xi, Xiaoran Fan, Shiliang Pu, Jiang Zhu, Rui Zheng, Tao Gui, Qi Zhang, and Xuanjing Huang. 2024. https://doi.org/10.18653/V1/2024.ACL-LONG.106 Loramoe: Alleviating world knowledge forgetting in large language models via moe-style plugin . In Proceedings of ...
- [72]
-
[73]
Xing Han, Huy Nguyen, Carl Harris, Nhat Ho, and Suchi Saria. 2024. Fusemoe: Mixture-of-experts transformers for fleximodal fusion. Advances in Neural Information Processing Systems, 37:67850--67900
2024
-
[74]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790--2799. PMLR
2019
-
[75]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lora: Low-rank adaptation of large language models . In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net
2022
- [76]
-
[77]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. 1991. https://doi.org/10.1162/neco.1991.3.1.79 Adaptive mixtures of local experts . Neural Computation, 3(1):79--87
-
[78]
Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L \'e lio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth \'e e Lacroix, and William El Sayed. 2023. https://api.sem...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [79]
-
[80]
Yujia Li, Shiliang Sun, and Jing Zhao. 2022. Tirgn: Time-guided recurrent graph network with local-global historical patterns for temporal knowledge graph reasoning. In IJCAI, pages 2152--2158
2022
-
[81]
Zixuan Li, Xiaolong Jin, Wei Li, Saiping Guan, Jiafeng Guo, Huawei Shen, Yuanzhuo Wang, and Xueqi Cheng. 2021. Temporal knowledge graph reasoning based on evolutional representation learning. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, pages 408--417
2021
-
[82]
Mengqi Liao, Wei Chen, Junfeng Shen, Shengnan Guo, and Huaiyu Wan. 2025. Hmora: Making llms more effective with hierarchical mixture of lora experts. In The Thirteenth International Conference on Learning Representations
2025
- [83]
-
[84]
Yushan Liu, Yunpu Ma, Marcel Hildebrandt, Mitchell Joblin, and Volker Tresp. 2022. Tlogic: Temporal logical rules for explainable link forecasting on temporal knowledge graphs. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 4120--4127
2022
- [85]
-
[86]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[87]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27
2014
-
[88]
Jiapu Wang, Sun Kai, Linhao Luo, Wei Wei, Yongli Hu, Alan Wee-Chung Liew, Shirui Pan, and Baocai Yin. 2024 a . Large language models-guided dynamic adaptation for temporal knowledge graph reasoning. Advances in Neural Information Processing Systems, 37:8384--8410
2024
-
[89]
Keyu Wang, Guilin Qi, Jiaoyan Chen, Yi Huang, and Tianxing Wu. 2024 b . https://doi.org/10.3724/2096-7004.di.2024.0088 Embedding ontologies via incorporating extensional and intensional knowledge . DATA INTELLIGENCE, 6(4):1222--1241
- [90]
-
[91]
Hao Wu, Shoucheng Song, Chang Yao, Sheng Han, Huaiyu Wan, Youfang Lin, and Kai Lv. 2026. Think how your teammates think: Active inference can benefit decentralized execution. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29749--29757
2026
-
[92]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, and 40 others. 2024. Qwen2 technical report. arXiv preprint arXiv:2407.10671
work page internal anchor Pith review arXiv 2024
- [93]
-
[94]
Zihao Yin, Zhihai Wang, Haiyang Liu, Chuanlan Li, Muyun Yao, Shijiang Li, Fangjing Li, Jia Ren, and Yanchao Yang. 2026. Pua: Pseudo-features made useful again for robust graph node classification under distribution shift. Pattern Recognition, page 113185
2026
- [95]
- [96]
-
[97]
Shuyuan Zhao, Wei Chen, Boyan Shi, Liyong Zhou, Shuohao Lin, and Huaiyu Wan. 2025. Spatial-temporal knowledge distillation for takeaway recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 13365--13373
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.