Recognition: unknown
PortraitDirector: A Hierarchical Disentanglement Framework for Controllable and Real-time Facial Reenactment
Pith reviewed 2026-05-10 03:26 UTC · model grok-4.3
The pith
PortraitDirector splits facial motion into physical movements and emotional content to achieve controllable high-fidelity reenactment at 20 frames per second.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate face reenactment as a hierarchical composition task. Facial motion is deconstructed into a Spatial Layer containing global head pose and spatially separated local expressions purged of emotional cues, plus a Semantic Layer containing derived global emotion. The disentangled components are recomposed into an expressive motion latent. Engineering optimizations including diffusion distillation, causal attention and VAE acceleration enable streaming 512 by 512 reenactment at 20 FPS with 800 ms end-to-end latency on a single consumer GPU.
What carries the argument
Hierarchical Motion Disentanglement and Composition strategy that separates physical motion components from emotional content and then recombines them into a controllable latent representation.
If this is right
- Granular control becomes possible over head pose, local expressions, and global emotion independently without sacrificing overall fidelity.
- The same pipeline runs in streaming mode at 20 FPS with sub-second latency on a single 5090 GPU.
- Diffusion distillation combined with causal attention and VAE acceleration removes the usual speed-quality trade-off for this task.
- The compositional structure supports swapping or editing one layer while leaving the others fixed.
Where Pith is reading between the lines
- The same layering idea could apply to full-body reenactment or hand animation where physical pose and expressive intent also need separation.
- Live applications such as virtual meetings or game avatars could use the low latency to let users steer their digital face in real time.
- If the emotion purge works reliably, the framework might allow emotion transfer across identities without altering the target's underlying motion style.
Load-bearing premise
The information bottleneck in the Emotion-Filtering Module can remove all emotional cues from cropped local expression regions while still keeping every physical motion detail needed for accurate recomposition.
What would settle it
Run the system on a test set where the driving video has strong emotional expressions but the target must preserve a neutral expression; if the output face shows unwanted emotion transfer or if physical motion accuracy drops below baseline methods, the claim does not hold.
Figures




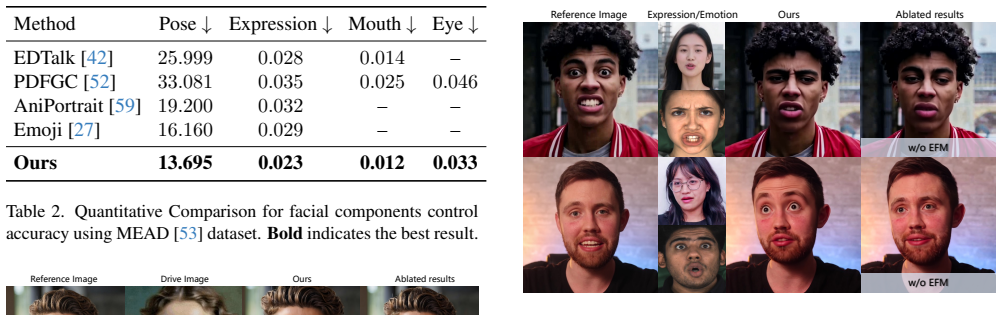

read the original abstract
Existing facial reenactment methods struggle with a trade-off between expressiveness and fine-grained controllability. Holistic facial reenactment models often sacrifice granular control for expressiveness, while methods designed for control may struggle with fidelity and robust disentanglement. Instead of treating facial motion as a monolithic signal, we explore an alternative compositional perspective. In this paper, we introduce PortraitDirector, a novel framework that formulates face reenactment as a hierarchical composition task, achieving high-fidelity and controllable results. We employ a Hierarchical Motion Disentanglement and Composition strategy, deconstructing facial motion into a Spatial Layer for physical movements and a Semantic Layer for emotional content. The Spatial Layer comprises: (i) global head pose, managed via a dedicated representation and injection pathway; (ii) spatially separated local facial expressions, distilled from cropped facial regions and purged of emotional cues via Emotion-Filtering Module leveraging an information bottleneck. The Semantic Layer contains a derived global emotion. The disentangled components are then recomposed into an expressive motion latent. Furthermore, we engineer the framework for real-time performance through a suite of optimizations, including diffusion distillation, causal attention and VAE acceleration. PortraitDirector achieves streaming, high-fidelity, controllable 512 x 512 face reenactment at 20 FPS with a end-to-end 800 ms latency on a single 5090 GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PortraitDirector, a hierarchical disentanglement framework for facial reenactment. It decomposes facial motion into a Spatial Layer (global head pose plus spatially cropped local expressions purged of emotional content via an Emotion-Filtering Module that uses an information bottleneck) and a Semantic Layer (global emotion), which are recomposed into an expressive motion latent. The architecture is further optimized with diffusion distillation, causal attention, and VAE acceleration to enable real-time streaming at 512x512 resolution, 20 FPS, and 800 ms end-to-end latency on a single RTX 5090 GPU.
Significance. If the hierarchical separation of physical motion from emotional content can be reliably achieved and validated, the work would offer a principled alternative to monolithic reenactment models, potentially improving fine-grained controllability while preserving expressiveness. The reported real-time performance optimizations would constitute a practical engineering contribution for live applications.
major comments (2)
- [Abstract] Abstract: The central claim of high-fidelity, controllable reenactment rests on the Emotion-Filtering Module successfully using an information bottleneck to purge emotional cues from spatially cropped local expressions while retaining all necessary physical motion information for recomposition. No ablations, disentanglement metrics (e.g., emotion classification accuracy on the filtered latents or motion reconstruction error), or baseline comparisons are reported to demonstrate that this separation occurs.
- [Abstract] Abstract: The performance claims (20 FPS at 512x512 with 800 ms latency) are stated without any quantitative results, error bars, implementation details, or hardware-specific measurements, preventing assessment of whether the optimizations actually deliver the stated real-time behavior.
minor comments (1)
- [Abstract] The phrase 'a end-to-end' should be corrected to 'an end-to-end'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the validation of our hierarchical disentanglement claims and real-time performance assertions. We will revise the manuscript to incorporate additional empirical evidence and detailed reporting as outlined below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of high-fidelity, controllable reenactment rests on the Emotion-Filtering Module successfully using an information bottleneck to purge emotional cues from spatially cropped local expressions while retaining all necessary physical motion information for recomposition. No ablations, disentanglement metrics (e.g., emotion classification accuracy on the filtered latents or motion reconstruction error), or baseline comparisons are reported to demonstrate that this separation occurs.
Authors: We acknowledge that the current manuscript does not include dedicated ablations or quantitative disentanglement metrics for the Emotion-Filtering Module, which limits direct validation of the information bottleneck's role in separating emotional content from physical motion. In the revised version, we will add: (i) emotion classification accuracy results on the filtered spatial latents versus unfiltered ones to quantify purged emotional cues, (ii) motion reconstruction errors to confirm preservation of necessary physical information, and (iii) baseline comparisons (e.g., without the bottleneck) showing impacts on controllability and fidelity. These will be presented in a new ablation study subsection to empirically support the hierarchical separation. revision: yes
-
Referee: [Abstract] Abstract: The performance claims (20 FPS at 512x512 with 800 ms latency) are stated without any quantitative results, error bars, implementation details, or hardware-specific measurements, preventing assessment of whether the optimizations actually deliver the stated real-time behavior.
Authors: The performance numbers in the abstract are based on our end-to-end measurements, but we agree the manuscript lacks sufficient supporting details for full assessment. In the revision, we will expand the implementation and experiments sections with: specific details on diffusion distillation, causal attention, and VAE acceleration; quantitative FPS and latency results including error bars from repeated runs; and hardware-specific benchmarks on the RTX 5090. This will allow readers to evaluate the optimizations' effectiveness for real-time streaming. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an architectural framework for hierarchical motion disentanglement in facial reenactment, with components like the Spatial Layer, Semantic Layer, and Emotion-Filtering Module using an information bottleneck. No equations, mathematical derivations, or predictive claims appear in the abstract or described text that reduce to fitted inputs or self-referential definitions by construction. Performance results (20 FPS, 800 ms latency) are reported as empirical achievements from implementation and optimization (diffusion distillation, causal attention, VAE acceleration), not as model-derived predictions. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the provided content. The central claims rest on the proposed composition strategy and engineering optimizations, which remain independent of any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hyperreenact: One-shot reenactment via jointly learning to refine and retar- get faces
Stella Bounareli, Christos Tzelepis, Vasileios Argyriou, Ioannis Patras, and Georgios Tzimiropoulos. Hyperreenact: One-shot reenactment via jointly learning to refine and retar- get faces. InIEEE/CVF International Conference on Com- puter Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 7115–7125. IEEE, 2023. 3
2023
-
[2]
Uni- facegan: a unified framework for temporally consistent facial video editing.IEEE Transactions on Image Processing, 30: 6107–6116, 2021
Meng Cao, Haozhi Huang, Hao Wang, Xuan Wang, Li Shen, Sheng Wang, Linchao Bao, Zhifeng Li, and Jiebo Luo. Uni- facegan: a unified framework for temporally consistent facial video editing.IEEE Transactions on Image Processing, 30: 6107–6116, 2021. 3
2021
-
[3]
Magicpose: Realistic human poses and facial expressions retargeting with identity-aware diffusion
Di Chang, Yichun Shi, Quankai Gao, Hongyi Xu, Jessica Fu, Guoxian Song, Qing Yan, Yizhe Zhu, Xiao Yang, and Mo- hammad Soleymani. Magicpose: Realistic human poses and facial expressions retargeting with identity-aware diffusion. InForty-first International Conference on Machine Learn- ing, ICML 2024, Vienna, Austria, July 21-27, 2024. Open- Review.net, 2024. 3
2024
-
[4]
Maddox, Zhiyao Duan, and Chenliang Xu
Lele Chen, Zhiheng Li, Ross K. Maddox, Zhiyao Duan, and Chenliang Xu. Lip movements generation at a glance. In Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part VII, pages 538–553. Springer, 2018. 2
2018
-
[5]
Gang Cheng, Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Ju Li, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, Ke Sun, Linrui Tian, Feng Wang, Guangyuan Wang, Qi Wang, Zhongjian Wang, Jiayu Xiao, Sheng Xu, Bang Zhang, Peng Zhang, Xindi Zhang, Zhe Zhang, Jingren Zhou, and Lian Zhuo. Wan-animate: Uni- fied character animation and repl...
-
[6]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InIEEE Conference on Computer Vi- sion and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 4690–4699. Computer Vision Foundation / IEEE, 2019. 8
2019
-
[7]
Megaportraits: One-shot megapixel neural head avatars
Nikita Drobyshev, Jenya Chelishev, Taras Khakhulin, Alek- sei Ivakhnenko, Victor Lempitsky, and Egor Zakharov. Megaportraits: One-shot megapixel neural head avatars. In MM ’22: The 30th ACM International Conference on Multi- media, Lisboa, Portugal, October 10 - 14, 2022, pages 2663–
2022
-
[8]
Emoportraits: Emotion-enhanced multimodal one-shot head avatars
Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos V ougioukas, Zoe Landgraf, Stavros Petridis, and Maja Pan- tic. Emoportraits: Emotion-enhanced multimodal one-shot head avatars. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 8498–8507. IEEE, 2024. 2, 3
2024
-
[9]
Efficient emotional adaptation for audio-driven talking-head generation
Yuan Gan, Zongxin Yang, Xihang Yue, Lingyun Sun, and Yi Yang. Efficient emotional adaptation for audio-driven talking-head generation. InIEEE/CVF International Con- ference on Computer Vision, ICCV 2023, Paris, France, Oc- tober 1-6, 2023, pages 22577–22588. IEEE, 2023. 3
2023
-
[10]
Stylesync: High-fidelity generalized and personalized lip sync in style- based generator
Jiazhi Guan, Zhanwang Zhang, Hang Zhou, Tianshu Hu, Kaisiyuan Wang, Dongliang He, Haocheng Feng, Jingtuo Liu, Errui Ding, Ziwei Liu, and Jingdong Wang. Stylesync: High-fidelity generalized and personalized lip sync in style- based generator. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2...
2023
-
[11]
arXiv preprint arXiv:2407.03168 , year =
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, and Di Zhang. Livepor- trait: Efficient portrait animation with stitching and retarget- ing control.CoRR, abs/2407.03168, 2024. 3
-
[12]
Ad-nerf: Audio driven neural ra- diance fields for talking head synthesis
Yudong Guo, Keyu Chen, Sen Liang, Yong-Jin Liu, Hujun Bao, and Juyong Zhang. Ad-nerf: Audio driven neural ra- diance fields for talking head synthesis. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 5764–
2021
-
[13]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.CoRR, abs/2506.08009,
work page internal anchor Pith review arXiv
-
[14]
Controllable and expressive one-shot video head swapping.CoRR, abs/2506.16852, 2025
Chaonan Ji, Jinwei Qi, Peng Zhang, Bang Zhang, and Liefeng Bo. Controllable and expressive one-shot video head swapping.CoRR, abs/2506.16852, 2025. 2
-
[15]
EAMM: one-shot emotional talking face via audio-based emotion-aware motion model
Xinya Ji, Hang Zhou, Kaisiyuan Wang, Qianyi Wu, Wayne Wu, Feng Xu, and Xun Cao. EAMM: one-shot emotional talking face via audio-based emotion-aware motion model. InSIGGRAPH ’22: Special Interest Group on Computer Graphics and Interactive Techniques Conference, Vancouver, BC, Canada, August 7 - 11, 2022, pages 61:1–61:10. ACM,
2022
-
[16]
Realistic one-shot mesh-based head avatars
Taras Khakhulin, Vanessa Sklyarova, Victor Lempitsky, and Egor Zakharov. Realistic one-shot mesh-based head avatars. InComputer Vision - ECCV 2022 - 17th European Confer- ence, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part II, pages 345–362. Springer, 2022. 3
2022
-
[17]
Taekyung Ki, Dongchan Min, and Gyeongsu Chae. FLOAT: generative motion latent flow matching for audio-driven talk- ing portrait.CoRR, abs/2412.01064, 2024. 2, 3
-
[18]
Deep video portraits.ACM Trans
Hyeongwoo Kim, Pablo Garrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Nießner, Patrick P´erez, Christian Richardt, Michael Zollh ¨ofer, and Christian Theobalt. Deep video portraits.ACM Trans. Graph., 37(4):163, 2018. 3
2018
-
[19]
Neural style-preserving visual dubbing
Hyeongwoo Kim, Mohamed Elgharib, Michael Zollh ¨ofer, Hans-Peter Seidel, Thabo Beeler, Christian Richardt, and Christian Theobalt. Neural style-preserving visual dubbing. ACM Trans. Graph., 38(6):178:1–178:13, 2019. 3
2019
-
[20]
Nersemble: Multi-view ra- diance field reconstruction of human heads.ACM Trans
Tobias Kirschstein, Shenhan Qian, Simon Giebenhain, Tim Walter, and Matthias Nießner. Nersemble: Multi-view ra- diance field reconstruction of human heads.ACM Trans. Graph., 42(4):161:1–161:14, 2023. 6
2023
-
[21]
Obamanet: Photo-realistic lip-sync from text.CoRR, abs/1801.01442, 2018
Rithesh Kumar, Jose Sotelo, Kundan Kumar, Alexandre de Br´ebisson, and Yoshua Bengio. Obamanet: Photo-realistic lip-sync from text.CoRR, abs/1801.01442, 2018. 2
-
[22]
Expressive talking head generation with granular audio-visual control
Borong Liang, Yan Pan, Zhizhi Guo, Hang Zhou, Zhibin Hong, Xiaoguang Han, Junyu Han, Jingtuo Liu, Errui Ding, and Jingdong Wang. Expressive talking head generation with granular audio-visual control. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, 9 New Orleans, LA, USA, June 18-24, 2022, pages 3377–3386. IEEE, 2022
2022
-
[23]
Anitalker: Animate vivid and di- verse talking faces through identity-decoupled facial motion encoding
Tao Liu, Feilong Chen, Shuai Fan, Chenpeng Du, Qi Chen, Xie Chen, and Kai Yu. Anitalker: Animate vivid and di- verse talking faces through identity-decoupled facial motion encoding. InProceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Aus- tralia, 28 October 2024 - 1 November 2024, pages 6696–
2024
-
[24]
Chetwin Low and Weimin Wang. Talkingmachines: Real- time audio-driven facetime-style video via autoregressive diffusion models.CoRR, abs/2506.03099, 2025. 3, 6
-
[25]
Mediapipe: A framework for building perception pipelines,
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris Mc- Clanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo- Ling Chang, Ming Guang Yong, Juhyun Lee, Wan-Teh Chang, Wei Hua, Manfred Georg, and Matthias Grundmann. Mediapipe: A framework for building perception pipelines,
-
[26]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.CoRR, abs/2310.04378, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[27]
Follow-your-emoji: Fine- controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, and Qifeng Chen. Follow-your-emoji: Fine- controllable and expressive freestyle portrait animation. In SIGGRAPH Asia 2024 Conference Papers, SA 2024, Tokyo, Japan, December 3-6, 2024, pages 110:1–110:12. ACM,
2024
-
[28]
Kazuaki Mishima, Antoni Bigata Casademunt, Stavros Petridis, Maja Pantic, and Kenji Suzuki. Facecrafter: Identity-conditional diffusion with disentangled control over facial pose, expression, and emotion.CoRR, abs/2505.15313, 2025. 3
-
[29]
One-shot face video re- enactment using hybrid latent spaces of stylegan2, 2023
Trevine Oorloff and Yaser Yacoob. One-shot face video re- enactment using hybrid latent spaces of stylegan2, 2023. 3
2023
-
[30]
DPE: disen- tanglement of pose and expression for general video portrait editing
Youxin Pang, Yong Zhang, Weize Quan, Yanbo Fan, Xi- aodong Cun, Ying Shan, and Dong-Ming Yan. DPE: disen- tanglement of pose and expression for general video portrait editing. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 427–436. IEEE, 2023. 2, 3
2023
-
[31]
Neural emotion director: Speech-preserving semantic control of facial expressions in” in-the-wild” videos
Foivos Paraperas Papantoniou, Panagiotis P Filntisis, Petros Maragos, and Anastasios Roussos. Neural emotion director: Speech-preserving semantic control of facial expressions in” in-the-wild” videos. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 18781–18790, 2022. 3
2022
-
[32]
Synctalkface: Talking face generation with precise lip-syncing via audio-lip memory
Se Jin Park, Minsu Kim, Joanna Hong, Jeongsoo Choi, and Yong Man Ro. Synctalkface: Talking face generation with precise lip-syncing via audio-lip memory. InThirty- Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Ar- tificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational A...
2022
-
[33]
Mask- facegan: High-resolution face editing with masked gan latent code optimization.IEEE Transactions on Image Processing, 32:5893–5908, 2023
Martin Pernu ˇs, Vitomir ˇStruc, and Simon Dobri ˇsek. Mask- facegan: High-resolution face editing with masked gan latent code optimization.IEEE Transactions on Image Processing, 32:5893–5908, 2023. 3
2023
-
[34]
Nambood- iri, and C.V
K R Prajwal, Rudrabha Mukhopadhyay, Vinay P. Nambood- iri, and C.V . Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. InProceedings of the 28th ACM International Conference on Multimedia, page 484–492, New York, NY , USA, 2020. Association for Com- puting Machinery. 2
2020
-
[35]
Ganimation: One-shot anatomically consistent facial animation.Interna- tional Journal of Computer Vision, 128(3):698–713, 2020
Albert Pumarola, Antonio Agudo, Aleix M Martinez, Al- berto Sanfeliu, and Francesc Moreno-Noguer. Ganimation: One-shot anatomically consistent facial animation.Interna- tional Journal of Computer Vision, 128(3):698–713, 2020. 3
2020
-
[36]
FSRT: facial scene representation transformer for face reenactment from factorized appearance, head-pose, and facial expression features
Andre Rochow, Max Schwarz, and Sven Behnke. FSRT: facial scene representation transformer for face reenactment from factorized appearance, head-pose, and facial expression features. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 7716–7726. IEEE, 2024. 3
2024
-
[37]
Nataniel Ruiz, Eunji Chong, and James M. Rehg. Fine- grained head pose estimation without keypoints. In2018 IEEE Conference on Computer Vision and Pattern Recogni- tion Workshops, CVPR Workshops 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 2074–2083. Computer Vision Foundation / IEEE Computer Society, 2018. 5, 8
2018
-
[38]
Everybody’s talkin’: Let me talk as you want.IEEE Trans
Linsen Song, Wayne Wu, Chen Qian, Ran He, and Chen Change Loy. Everybody’s talkin’: Let me talk as you want.IEEE Trans. Inf. Forensics Secur., 17:585–598, 2022. 2
2022
-
[39]
Talking face generation by conditional recurrent adversarial network
Yang Song, Jingwen Zhu, Dawei Li, Andy Wang, and Hairong Qi. Talking face generation by conditional recurrent adversarial network. InProceedings of the Twenty-Eighth In- ternational Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, pages 919–925. ijcai.org, 2019
2019
-
[40]
Speech2talking-face: Inferring and driving a face with syn- chronized audio-visual representation
Yasheng Sun, Hang Zhou, Ziwei Liu, and Hideki Koike. Speech2talking-face: Inferring and driving a face with syn- chronized audio-visual representation. InProceedings of the Thirtieth International Joint Conference on Artificial Intelli- gence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021, pages 1018–1024. ijcai.org, 2021
2021
-
[41]
Edtalk++: Full disentanglement for controllable talking head synthesis.CoRR, abs/2508.13442,
Shuai Tan and Bin Ji. Edtalk++: Full disentanglement for controllable talking head synthesis.CoRR, abs/2508.13442,
-
[42]
Edtalk: Effi- cient disentanglement for emotional talking head synthesis
Shuai Tan, Bin Ji, Mengxiao Bi, and Ye Pan. Edtalk: Effi- cient disentanglement for emotional talking head synthesis. InComputer Vision - ECCV 2024 - 18th European Confer- ence, Milan, Italy, September 29-October 4, 2024, Proceed- ings, Part VI, pages 398–416. Springer, 2024. 2, 3, 4, 5, 6, 7, 8
2024
-
[43]
Flowvqtalker: High-quality emotional talking face generation through normalizing flow and quantization
Shuai Tan, Bin Ji, and Ye Pan. Flowvqtalker: High-quality emotional talking face generation through normalizing flow and quantization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 26307–26317. IEEE, 2024. 10
2024
-
[44]
Shuai Tan, Bill Gong, Bin Ji, and Ye Pan. Fixtalk: Taming identity leakage for high-quality talking head generation in extreme cases.CoRR, abs/2507.01390, 2025. 2
-
[45]
Animate-x: Universal character image ani- mation with enhanced motion representation
Shuai Tan, Biao Gong, Xiang Wang, Shiwei Zhang, Dandan Zheng, Ruobing Zheng, Kecheng Zheng, Jingdong Chen, and Ming Yang. Animate-x: Universal character image ani- mation with enhanced motion representation. InThe Thir- teenth International Conference on Learning Representa- tions, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net, 2025. 3
2025
-
[46]
Stylerig: Rigging style- gan for 3d control over portrait images
Ayush Tewari, Mohamed Elgharib, Gaurav Bharaj, Flo- rian Bernard, Hans-Peter Seidel, Patrick P ´erez, Michael Zollh¨ofer, and Christian Theobalt. Stylerig: Rigging style- gan for 3d control over portrait images. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 6141–6150. Computer V...
2020
-
[47]
Neural voice puppetry: Audio-driven facial reenactment
Justus Thies, Mohamed Elgharib, Ayush Tewari, Christian Theobalt, and Matthias Nießner. Neural voice puppetry: Audio-driven facial reenactment. InComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, Au- gust 23-28, 2020, Proceedings, Part XVI, pages 716–731. Springer, 2020. 2
2020
-
[48]
Naftali Tishby, Fernando C. N. Pereira, and William Bialek. The information bottleneck method.CoRR, physics/0004057, 2000. 6
work page internal anchor Pith review arXiv 2000
-
[49]
VOODOO 3d: V olumetric portrait disentanglement for one-shot 3d head reenactment
Phong Tran, Egor Zakharov, Long-Nhat Ho, Anh Tuan Tran, Liwen Hu, and Hao Li. VOODOO 3d: V olumetric portrait disentanglement for one-shot 3d head reenactment. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 10336–10348. IEEE, 2024. 3
2024
-
[50]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Xiaofeng Meng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, Tianxing Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Baiqin Wang, Xiangyu Zhu, Fan Shen, Hao Xu, and Zhen Lei. Pc-talk: Precise facial animation control for audio- driven talking face generation.CoRR, abs/2503.14295, 2025. 2
-
[52]
Progressive disentangled representation learning for fine-grained controllable talking head synthesis
Duomin Wang, Yu Deng, Zixin Yin, Heung-Yeung Shum, and Baoyuan Wang. Progressive disentangled representation learning for fine-grained controllable talking head synthesis. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17- 24, 2023, pages 17979–17989. IEEE, 2023. 2, 3, 4, 5, 6, 7, 8
2023
-
[53]
MEAD: A large-scale audio-visual dataset for emo- tional talking-face generation
Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. MEAD: A large-scale audio-visual dataset for emo- tional talking-face generation. InComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23- 28, 2020, Proceedings, Part XXI, pages 700–717. Springer,
2020
-
[54]
Faceverse: a fine-grained and detail- controllable 3d face morphable model from a hybrid dataset
Lizhen Wang, Zhiyuan Chen, Tao Yu, Chenguang Ma, Liang Li, and Yebin Liu. Faceverse: a fine-grained and detail- controllable 3d face morphable model from a hybrid dataset. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18- 24, 2022, pages 20301–20310. IEEE, 2022. 3
2022
-
[55]
Stylea- vatar: Real-time photo-realistic portrait avatar from a sin- gle video
Lizhen Wang, Xiaochen Zhao, Jingxiang Sun, Yuxiang Zhang, Hongwen Zhang, Tao Yu, and Yebin Liu. Stylea- vatar: Real-time photo-realistic portrait avatar from a sin- gle video. InACM SIGGRAPH 2023 Conference Proceed- ings, SIGGRAPH 2023, Los Angeles, CA, USA, August 6-10, 2023, pages 67:1–67:10. ACM, 2023. 2, 3
2023
-
[56]
Qiang Wang, Mengchao Wang, Fan Jiang, Yaqi Fan, Yong- gang Qi, and Mu Xu. Fantasyportrait: Enhancing multi- character portrait animation with expression-augmented dif- fusion transformers.CoRR, abs/2507.12956, 2025. 2, 3, 7
-
[57]
One-shot free-view neural talking-head synthesis for video conferenc- ing
Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferenc- ing. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 10039–10049. Computer Vision Foundation / IEEE, 2021. 3
2021
-
[58]
LIA: latent image animator.IEEE Trans
Yaohui Wang, Di Yang, Franc ¸ois Br ´emond, and Antitza Dantcheva. LIA: latent image animator.IEEE Trans. Pat- tern Anal. Mach. Intell., 46(12):10829–10844, 2024. 3
2024
-
[59]
Aniportrait: Audio-driven synthesis of photorealistic portrait animation
Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. CoRR, abs/2403.17694, 2024. 2, 3, 6, 7, 8
-
[60]
Imitating arbitrary talking style for re- alistic audio-driven talking face synthesis
Haozhe Wu, Jia Jia, Haoyu Wang, Yishun Dou, Chao Duan, and Qingshan Deng. Imitating arbitrary talking style for re- alistic audio-driven talking face synthesis. InMM ’21: ACM Multimedia Conference, Virtual Event, China, October 20 - 24, 2021, pages 1478–1486. ACM, 2021. 2
2021
-
[61]
Poce: Pose-controllable ex- pression editing.IEEE Transactions on Image Processing, 32:6210–6222, 2023
Rongliang Wu, Yingchen Yu, Fangneng Zhan, Jiahui Zhang, Shengcai Liao, and Shijian Lu. Poce: Pose-controllable ex- pression editing.IEEE Transactions on Image Processing, 32:6210–6222, 2023. 3
2023
-
[62]
VFHQ: A high-quality dataset and bench- mark for video face super-resolution
Liangbin Xie, Xintao Wang, Honglun Zhang, Chao Dong, and Ying Shan. VFHQ: A high-quality dataset and bench- mark for video face super-resolution. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022, pages 656–665. IEEE, 2022. 6, 7
2022
-
[63]
X-portrait: Expressive portrait anima- tion with hierarchical motion attention
You Xie, Hongyi Xu, Guoxian Song, Chao Wang, Yichun Shi, and Linjie Luo. X-portrait: Expressive portrait anima- tion with hierarchical motion attention. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH 2024, Denver, CO, USA, 27 July 2024- 1 August 2024, page 115. ACM, 2024. 3
2024
-
[64]
V ASA-1: lifelike audio-driven talking faces generated in real time
Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, and 11 Baining Guo. V ASA-1: lifelike audio-driven talking faces generated in real time. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Infor- mation Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, Decembe...
2024
-
[65]
Hunyuan- portrait: Implicit condition control for enhanced portrait an- imation
Zunnan Xu, Zhentao Yu, Zixiang Zhou, Jun Zhou, Xiaoyu Jin, Fa-Ting Hong, Xiaozhong Ji, Junwei Zhu, Chengfei Cai, Shiyu Tang, Qin Lin, Xiu Li, and Qinglin Lu. Hunyuan- portrait: Implicit condition control for enhanced portrait an- imation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pag...
2025
-
[66]
Face2face ρ: Real- time high-resolution one-shot face reenactment
Kewei Yang, Kang Chen, Daoliang Guo, Song-Hai Zhang, Yuan-Chen Guo, and Weidong Zhang. Face2face ρ: Real- time high-resolution one-shot face reenactment. InCom- puter Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XIII, pages 55–71. Springer, 2022. 3
2022
-
[67]
Freeman, and Taesung Park
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fr´edo Durand, William T. Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 6613–6623. IEEE, 2024. 3, 6
2024
-
[68]
Free- man, Fr´edo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Free- man, Fr´edo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion mod- els. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2025, Nashville, TN, USA, June 11- 15, 2025, pages 22963–22974. Computer Vision Foundation / IEEE, 2025. 3, 6
2025
-
[69]
Talking head generation with probabilistic audio-to-visual diffusion priors
Zhentao Yu, Zixin Yin, Deyu Zhou, Duomin Wang, Finn Wong, and Baoyuan Wang. Talking head generation with probabilistic audio-to-visual diffusion priors. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 7611–7621. IEEE,
2023
-
[70]
Realistic face reenactment via self- supervised disentangling of identity and pose
Xianfang Zeng, Yusu Pan, Mengmeng Wang, Jiangning Zhang, and Yong Liu. Realistic face reenactment via self- supervised disentangling of identity and pose. InThe Thirty- Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artifi- cial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educ...
2020
-
[71]
Metaportrait: Identity-preserving talking head gener- ation with fast personalized adaptation
Bowen Zhang, Chenyang Qi, Pan Zhang, Bo Zhang, Hsiang- Tao Wu, Dong Chen, Qifeng Chen, Yong Wang, and Fang Wen. Metaportrait: Identity-preserving talking head gener- ation with fast personalized adaptation. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 22096–22105. IEEE, 2023. 2, 3
2023
-
[72]
Personatalk: Bring attention to your persona in vi- sual dubbing
Longhao Zhang, Shuang Liang, Zhipeng Ge, and Tianshu Hu. Personatalk: Bring attention to your persona in vi- sual dubbing. InSIGGRAPH Asia 2024 Conference Papers, SA 2024, Tokyo, Japan, December 3-6, 2024, pages 108:1– 108:9. ACM, 2024
2024
-
[73]
Sadtalker: Learning realistic 3d motion coefficients for stylized audio- driven single image talking face animation
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio- driven single image talking face animation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 8652–8661. IEEE, 2023. 3
2023
-
[74]
X-nemo: Expressive neural motion reenactment via disen- tangled latent attention
Xiaochen Zhao, Hongyi Xu, Guoxian Song, You Xie, Chenxu Zhang, Xiu Li, Linjie Luo, Jinli Suo, and Yebin Liu. X-nemo: Expressive neural motion reenactment via disen- tangled latent attention. InThe Thirteenth International Con- ference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. 2, 3, 4, 5, 7, 8
2025
-
[75]
Pose-controllable talk- ing face generation by implicitly modularized audio-visual representation
Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu. Pose-controllable talk- ing face generation by implicitly modularized audio-visual representation. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19- 25, 2021, pages 4176–4186. Computer Vision Foundation / IEEE, 2021. 3 12
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.