Recognition: unknown
Multiscale Cochran-Mantel-Haenszel Scanning for Conditional Dependency
Pith reviewed 2026-05-10 02:43 UTC · model grok-4.3
The pith
A multiscale scanning procedure generalizes the Cochran-Mantel-Haenszel test to continuous data, yielding consistent tests of conditional independence without requiring large stratum sizes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
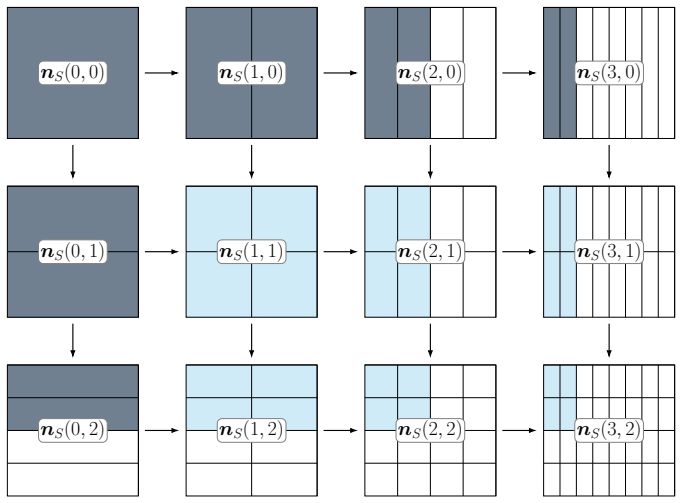
By applying a multiscale scanning approach to decompose the continuous sample space into a cascade of 2×2×T tables and then conditioning on the marginal order statistics, which are almost ancillary for conditional dependency, the generalized CMH procedure produces test statistics with a known asymptotic null distribution under the conditional sampling model. This yields consistency for detecting conditional dependencies without requiring stratum sample sizes to grow to infinity and supports nearly linear computational scaling with sample size.
What carries the argument
The multiscale scanning decomposition of continuous observations into a hierarchy of stratified 2x2xT tables that lets the CMH conditioning strategy remain valid.
If this is right
- Reliable type I error control holds even for small samples and high-dimensional conditioning variables.
- The method supplies summary statistics that indicate both the strength and the direction of local conditional associations.
- Computation of the test scales almost linearly with sample size.
- The approach identifies the nature of inferred associations in applications such as ride-share data analysis.
Where Pith is reading between the lines
- The same multiscale conditioning device might adapt to other stratified nonparametric tests for dependence.
- Local association summaries could feed into algorithms for building conditional independence graphs.
- Linear scaling opens the possibility of routine dependency screening on very large continuous datasets.
Load-bearing premise
The marginal order statistics remain almost ancillary to the conditional dependency even after the multiscale partitioning into tables.
What would settle it
A large sample with fixed small stratum sizes in which the test statistic deviates from its claimed asymptotic null distribution or fails to control type I error at the nominal level.
Figures




read the original abstract
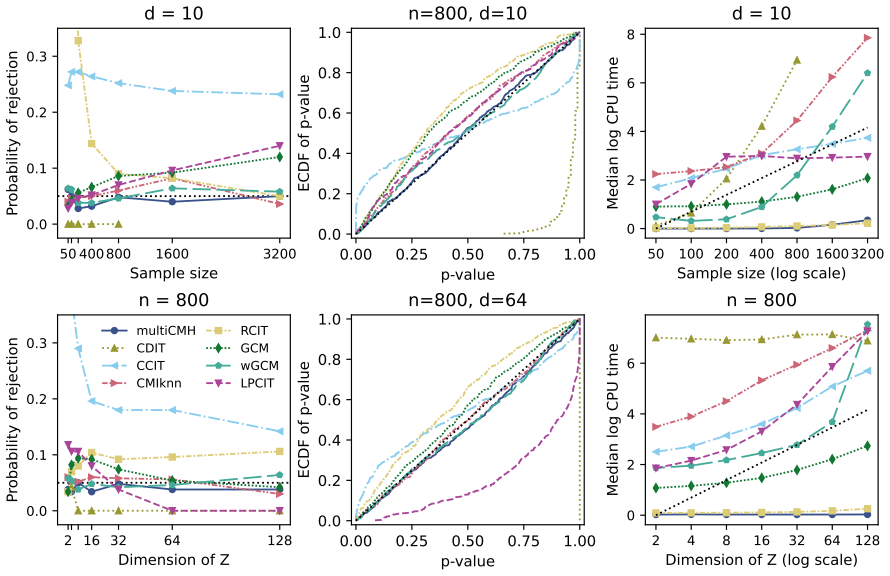
We propose a nonparametric approach to testing conditional independence and estimating conditional association, generalizing the Cochran-Mantel-Haenszel (CMH) test and odds-ratio estimator to continuous sample spaces. It leverages a multiscale scanning approach to decompose the sample space into a cascade of $2\times 2 \times T$ tables. Following the CMH test, we condition on the marginal order statistics, which are "almost ancillary" regarding conditional dependency. This strategy helps overcome a key challenge faced by other methods that discretize the sample space: we achieve consistency without requiring stratum sample sizes to grow to infinity, a constraint often difficult to satisfy in practice. Our method produces easy-to-compute test statistics with a known asymptotic null distribution under the conditional sampling model, scaling almost linearly with the sample size. Our simulation results demonstrate reliable Type I error control, even with small samples and high-dimensional conditioning, and competitive power compared to state-of-the-art tests. Finally, a case study on Uber ride-share data highlights the method's unique dual capability, inherited from the CMH, to both test and identify the nature of the inferred conditional association. By providing summary statistics that capture the strength and direction of local associations, our method offers practitioners a useful tool for learning conditional dependencies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a nonparametric multiscale scanning generalization of the Cochran-Mantel-Haenszel (CMH) test and odds-ratio estimator for conditional independence and association in continuous spaces. The approach decomposes the sample into a cascade of 2×2×T tables, conditions on marginal order statistics claimed to be almost ancillary for the conditional dependency, and asserts consistency without requiring per-stratum sample sizes to diverge to infinity, together with an asymptotic null distribution under the conditional model, near-linear computational scaling, reliable Type I error control in simulations (including small samples and high-dimensional conditioning), competitive power, and interpretable local association summaries illustrated on Uber ride-share data.
Significance. If the consistency result and the claimed asymptotic null distribution hold, the work would offer a practical and interpretable extension of the classical CMH framework to continuous data, sidestepping the stratum-size requirement that limits many discretization-based competitors. The computational efficiency, dual testing/estimation capability, and robustness to small samples/high dimensions are clear strengths, as are the simulation evidence for Type I error control and the case-study demonstration of local association identification.
major comments (3)
- [Abstract] Abstract: the central claim that the procedure 'produces easy-to-compute test statistics with a known asymptotic null distribution under the conditional sampling model' is load-bearing for the method's practicality and for the assertion of linear scaling, yet no derivation, limiting distribution, or set of regularity conditions is supplied; this must be provided (with explicit reference to the multiscale decomposition) to substantiate the claim.
- [Abstract] Abstract: the consistency result without requiring stratum sample sizes to grow to infinity rests on the assertion that marginal order statistics are 'almost ancillary' regarding conditional dependency and that the multiscale decomposition into 2×2×T tables preserves CMH validity; a formal argument or explicit verification of this ancillary property (including any approximation error) is required, as it is identified as the weakest assumption.
- [Abstract] Abstract: the statement that the method 'achieves consistency without requiring stratum sample sizes to grow to infinity' is presented as a key practical advantage, but the manuscript must delineate the precise conditions on the multiscale scanning and the continuous-space conditioning under which this holds, since the ancillary property is only approximate.
minor comments (1)
- [Abstract] Abstract: the phrase 'cascade of 2×2×T tables' and the precise definition of the multiscale decomposition would benefit from a short clarifying sentence or forward reference to the relevant section for readers new to scanning procedures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We agree that the abstract claims require additional substantiation and will revise the manuscript to provide the requested derivations, formal arguments, and precise conditions. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the procedure 'produces easy-to-compute test statistics with a known asymptotic null distribution under the conditional sampling model' is load-bearing for the method's practicality and for the assertion of linear scaling, yet no derivation, limiting distribution, or set of regularity conditions is supplied; this must be provided (with explicit reference to the multiscale decomposition) to substantiate the claim.
Authors: We agree that the abstract would benefit from explicit substantiation of this claim. In the revised manuscript, we will update the abstract to reference the relevant theorem establishing the asymptotic null distribution under the conditional sampling model and will add an explicit pointer to the derivation in the main text, including the regularity conditions and their connection to the multiscale decomposition into a cascade of 2×2×T tables. revision: yes
-
Referee: [Abstract] Abstract: the consistency result without requiring stratum sample sizes to grow to infinity rests on the assertion that marginal order statistics are 'almost ancillary' regarding conditional dependency and that the multiscale decomposition into 2×2×T tables preserves CMH validity; a formal argument or explicit verification of this ancillary property (including any approximation error) is required, as it is identified as the weakest assumption.
Authors: The referee correctly highlights this as the key supporting assumption. We will add a formal argument, either as a new subsection or appendix, that verifies the almost ancillary property of the marginal order statistics for conditional dependency. This will include an explicit treatment of the approximation error and how the multiscale decomposition preserves the validity of the CMH conditioning procedure. revision: yes
-
Referee: [Abstract] Abstract: the statement that the method 'achieves consistency without requiring stratum sample sizes to grow to infinity' is presented as a key practical advantage, but the manuscript must delineate the precise conditions on the multiscale scanning and the continuous-space conditioning under which this holds, since the ancillary property is only approximate.
Authors: We will revise the manuscript to delineate the precise conditions. This will include a clear statement of the requirements on the multiscale scanning scales and the assumptions on the continuous distributions of the conditioning variables under which consistency holds, with explicit bounds that account for the approximate nature of the ancillarity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a multiscale scanning procedure that decomposes the sample space into cascades of 2x2xT tables and conditions on marginal order statistics described as almost ancillary. This yields test statistics with an asymptotic null distribution under the conditional model and consistency without requiring per-stratum sample sizes to diverge. No step reduces by construction to a fitted parameter, self-definition, or load-bearing self-citation; the central claims follow from the nonparametric generalization of the CMH conditioning strategy applied to the new decomposition, which remains independent of the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Marginal order statistics are almost ancillary regarding conditional dependency
Reference graph
Works this paper leans on
-
[1]
Biometrics , volume=
Some methods for strengthening the common ^2 tests , author=. Biometrics , volume=. 1954 , publisher=
1954
-
[2]
Journal of the National Cancer Institute , volume=
Statistical aspects of the analysis of data from retrospective studies of disease , author=. Journal of the National Cancer Institute , volume=. 1959 , publisher=
1959
-
[3]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
The detection of partial association, I: the 2 2 case , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=. 1964 , publisher=
1964
-
[4]
Journal of the American Statistical Association , volume =
Zbyněk Šidák , title =. Journal of the American Statistical Association , volume =. 1967 , publisher =
1967
-
[5]
Plackett, R. L. , title =. 1974 , address =
1974
-
[6]
Communications of the ACM , volume=
Multidimensional binary search trees used for associative searching , author=. Communications of the ACM , volume=. 1975 , publisher=
1975
-
[7]
Columbia University Technical Report No
On the power of the Cochran-Mantel-Haenszel test and of other approximately optimal tests for partial association , author=. Columbia University Technical Report No. B-03 , year=
-
[8]
, author=
Minimum expected cell size requirements for the Mantel-Haenszel one-degree-of-freedom chi-square test and a related rapid procedure. , author=. American Journal of Epidemiology , volume=
-
[9]
Biometrika , volume=
Partial association measures and an application to qualitative regression , author=. Biometrika , volume=. 1980 , publisher=
1980
-
[10]
Biometrics , pages=
Power and sample size for a collection of 2 x 2 tables , author=. Biometrics , pages=. 1984 , publisher=
1984
-
[11]
Estimators of the variance of the
Phillips, Abraham and Holland, Paul W , journal=. Estimators of the variance of the. 1987 , publisher=
1987
-
[12]
Journal of the American Statistical Association , volume=
The power of the mantel--haenszel test , author=. Journal of the American Statistical Association , volume=. 1987 , publisher=
1987
-
[13]
Lecture Notes-Monograph Series , volume=
The Likelihood Principle , author=. Lecture Notes-Monograph Series , volume=. 1988 , publisher=
1988
-
[14]
The American Statistician , volume=
Ignoring a covariate: An example of Simpson's paradox , author=. The American Statistician , volume=. 1996 , publisher=
1996
-
[15]
Statistica Sinica , pages=
Asymptotics for a 2 2 table with fixed margins , author=. Statistica Sinica , pages=. 1996 , publisher=
1996
-
[16]
Microsoft Research, Redmond , volume=
Constrained k-means clustering , author=. Microsoft Research, Redmond , volume=
-
[17]
International conference on database theory , pages=
On the surprising behavior of distance metrics in high dimensional space , author=. International conference on database theory , pages=. 2001 , organization=
2001
-
[18]
2002 , publisher=
Statistical Inference , author=. 2002 , publisher=
2002
-
[19]
2003 , publisher=
Nonparametric Goodness-of-Fit Testing Under Gaussian Models , author=. 2003 , publisher=
2003
-
[20]
Journal of Machine Learning Research , volume=
Dimensionality reduction for supervised learning with reproducing kernel Hilbert spaces , author=. Journal of Machine Learning Research , volume=
-
[21]
AAAI , volume=
Distribution-free learning of Bayesian network structure in continuous domains , author=. AAAI , volume=
-
[22]
, author=
Estimating high-dimensional directed acyclic graphs with the PC-algorithm. , author=. Journal of Machine Learning Research , volume=
-
[23]
Advances in neural information processing systems , volume=
Kernel measures of conditional dependence , author=. Advances in neural information processing systems , volume=
-
[24]
Introduction to Nonparametric Estimation , pages=
Nonparametric estimators , author=. Introduction to Nonparametric Estimation , pages=. 2008 , publisher=
2008
-
[25]
, author=
Using markov blankets for causal structure learning. , author=. Journal of Machine Learning Research , volume=
-
[26]
Bach and Michael I
Kenji Fukumizu and Francis R. Bach and Michael I. Jordan , title =. The Annals of Statistics , number =. 2009 , doi =
2009
-
[27]
Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (UAI) , volume=
On the identifiability of the post-nonlinear causal model , author=. Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (UAI) , volume=. 2009 , organization=
2009
-
[28]
The Annals of Statistics , number =
Tzee-Ming Huang , title =. The Annals of Statistics , number =. 2010 , doi =
2010
-
[29]
Journal of statistical software , volume=
Learning Bayesian networks with the bnlearn R package , author=. Journal of statistical software , volume=
-
[30]
Modern hierarchical, agglomerative clustering algorithms
Modern hierarchical, agglomerative clustering algorithms , author=. arXiv preprint arXiv:1109.2378 , year=
-
[31]
arXiv preprint arXiv:1202.3775 , year=
Kernel-based conditional independence test and application in causal discovery , author=. arXiv preprint arXiv:1202.3775 , year=
-
[32]
2013 , publisher=
Categorical data analysis , author=. 2013 , publisher=
2013
-
[33]
, author=
A Permutation-Based Kernel Conditional Independence Test. , author=. UAI , pages=
-
[34]
, author=
Order-independent constraint-based causal structure learning. , author=. J. Mach. Learn. Res. , volume=
-
[35]
Journal of the American Statistical Association , volume=
Conditional distance correlation , author=. Journal of the American Statistical Association , volume=. 2015 , publisher=
2015
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
On the decreasing power of kernel and distance based nonparametric hypothesis tests in high dimensions , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
arXiv preprint arXiv:1711.05869 , year=
Predictive independence testing, predictive conditional independence testing, and predictive graphical modelling , author=. arXiv preprint arXiv:1711.05869 , year=
-
[38]
Advances in neural information processing systems , volume=
Model-powered conditional independence test , author=. Advances in neural information processing systems , volume=
-
[39]
Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence (UAI) , year =
Feature-to-feature regression for a two-step conditional independence test , author =. Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence (UAI) , year =
-
[40]
Proceedings of the AAAI conference on artificial intelligence , volume=
Causal discovery using regression-based conditional independence tests , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[41]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Panning for gold:‘model-X’knockoffs for high dimensional controlled variable selection , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2018 , publisher=
2018
-
[42]
Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing , pages=
Testing conditional independence of discrete distributions , author=. Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing , pages=
-
[43]
Proceedings of the AAAI conference on artificial intelligence , volume=
Measuring conditional independence by independent residuals: Theoretical results and application in causal discovery , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[44]
Journal of Causal Inference , volume=
Invariant causal prediction for nonlinear models , author=. Journal of Causal Inference , volume=. 2018 , publisher=
2018
-
[45]
International Conference on Artificial Intelligence and Statistics , pages=
Conditional independence testing based on a nearest-neighbor estimator of conditional mutual information , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2018 , organization=
2018
-
[46]
arXiv preprint arXiv:1804.02747 , year=
Fast conditional independence test for vector variables with large sample sizes , author=. arXiv preprint arXiv:1804.02747 , year=
-
[47]
Journal of Machine Learning Research , volume=
The reduced PC-algorithm: Improved causal structure learning in large random networks , author=. Journal of Machine Learning Research , volume=
-
[48]
Journal of Causal Inference , volume=
Approximate kernel-based conditional independence tests for fast non-parametric causal discovery , author=. Journal of Causal Inference , volume=. 2019 , publisher=
2019
-
[49]
Journal of the American Statistical Association , volume=
Fisher exact scanning for dependency , author=. Journal of the American Statistical Association , volume=. 2019 , publisher=
2019
-
[50]
Advances in neural information processing systems , volume=
Conditional independence testing using generative adversarial networks , author=. Advances in neural information processing systems , volume=
-
[51]
The Annals of Statistics , volume=
The hardness of conditional independence testing and the generalised covariance measure , author=. The Annals of Statistics , volume=
-
[52]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
The conditional permutation test for independence while controlling for confounders , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2020 , publisher=
2020
-
[53]
Wiley Interdisciplinary Reviews: Computational Statistics , volume=
On nonparametric conditional independence tests for continuous variables , author=. Wiley Interdisciplinary Reviews: Computational Statistics , volume=. 2020 , publisher=
2020
-
[54]
Journal of Multivariate Analysis , volume=
Test for conditional independence with application to conditional screening , author=. Journal of Multivariate Analysis , volume=. 2020 , publisher=
2020
-
[55]
The Annals of Statistics , volume=
Minimax optimal conditional independence testing , author=. The Annals of Statistics , volume=. 2021 , publisher=
2021
-
[56]
The Annals of Statistics , volume=
A simple measure of conditional dependence , author=. The Annals of Statistics , volume=. 2021 , publisher=
2021
-
[57]
Journal of Machine Learning Research , volume=
Testing conditional independence via quantile regression based partial copulas , author=. Journal of Machine Learning Research , volume=
-
[58]
Molecular Genetics & Genomic Medicine , volume=
A review of causal discovery methods for molecular network analysis , author=. Molecular Genetics & Genomic Medicine , volume=. 2022 , publisher=
2022
-
[59]
Proceedings of the AAAI conference on artificial intelligence , volume=
Residual similarity based conditional independence test and its application in causal discovery , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[60]
Journal of Machine Learning Research , volume=
Kernel Partial Correlation Coefficient---a Measure of Conditional Dependence , author=. Journal of Machine Learning Research , volume=
-
[61]
Multi-scale
Gorsky, S and Ma, L , journal=. Multi-scale. 2022 , publisher=
2022
-
[62]
The Annals of Statistics , volume=
Local permutation tests for conditional independence , author=. The Annals of Statistics , volume=. 2022 , publisher=
2022
-
[63]
Local permutation tests for conditional independence
Supplement to "Local permutation tests for conditional independence" , author=. 2022 , publisher=
2022
-
[64]
Journal of Machine Learning Research , volume=
The weighted generalised covariance measure , author=. Journal of Machine Learning Research , volume=
-
[65]
International Conference on Machine Learning , pages=
An asymptotic test for conditional independence using analytic kernel embeddings , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[66]
Advances in Neural Information Processing Systems , volume=
K-nearest-neighbor local sampling based conditional independence testing , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
arXiv preprint arXiv:2411.06140 , year=
Deep nonparametric conditional independence tests for images , author=. arXiv preprint arXiv:2411.06140 , year=
-
[68]
arXiv preprint arXiv:2403.05407 , year=
Algorithmic identification of essential exogenous nodes for causal sufficiency in brain networks , author=. arXiv preprint arXiv:2403.05407 , year=
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Conditional diffusion models based conditional independence testing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Score-based Generative Modeling for Conditional Independence Testing , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[71]
2023 , note =
samplesizeCMH: Power and Sample Size Calculation for the Cochran-Mantel-Haenszel Test , author =. 2023 , note =
2023
-
[72]
Polyanskiy, Yury , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.