Recognition: unknown
SketchFaceGS: Real-Time Sketch-Driven Face Editing and Generation with Gaussian Splatting
Pith reviewed 2026-05-10 01:32 UTC · model grok-4.3
The pith
SketchFaceGS turns 2D sketches into real-time editable photorealistic 3D Gaussian head models via a feed-forward coarse-to-fine pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SketchFaceGS is the first sketch-driven framework for real-time generation and editing of photorealistic 3D Gaussian head models from 2D sketches using a feed-forward coarse-to-fine architecture. A Transformer-based UV feature-prediction module first reconstructs a coarse but geometrically consistent UV feature map from the input sketch, and then a 3D UV feature enhancement module refines it with high-frequency, photorealistic detail to produce a high-fidelity 3D head. For editing, UV Mask Fusion combined with layer-by-layer feature-fusion enables precise, real-time, free-viewpoint modifications.
What carries the argument
The Transformer-based UV feature-prediction module that reconstructs coarse geometrically consistent UV feature maps from sparse sketches, paired with UV Mask Fusion for targeted editing.
If this is right
- Users can generate and edit high-fidelity 3D heads from sketches in a single forward pass at real-time speeds.
- Edits remain consistent under free-viewpoint rendering without requiring model retraining.
- The method outperforms prior sketch-to-3D approaches in both visual fidelity and editing precision.
- Interactive conceptual design of 3D faces becomes feasible in applications needing instant feedback.
Where Pith is reading between the lines
- The UV-based pipeline might generalize to sketch-driven modeling of other objects if the feature prediction scales beyond heads.
- Integration with real-time capture devices could allow iterative refinement where users sketch corrections directly on rendered views.
- The approach suggests that sparse inputs suffice for 3D reconstruction when the output representation is overparameterized like Gaussians.
Load-bearing premise
That a transformer can reliably turn sparse and depth-ambiguous 2D sketches into dense, geometrically consistent 3D Gaussian structures without any depth or multi-view data.
What would settle it
Generate heads from a set of sketches with deliberate geometric ambiguities such as unusual face proportions or extreme angles, then compare the resulting 3D models against ground-truth 3D scans of the same subjects for shape accuracy across unseen views.
Figures


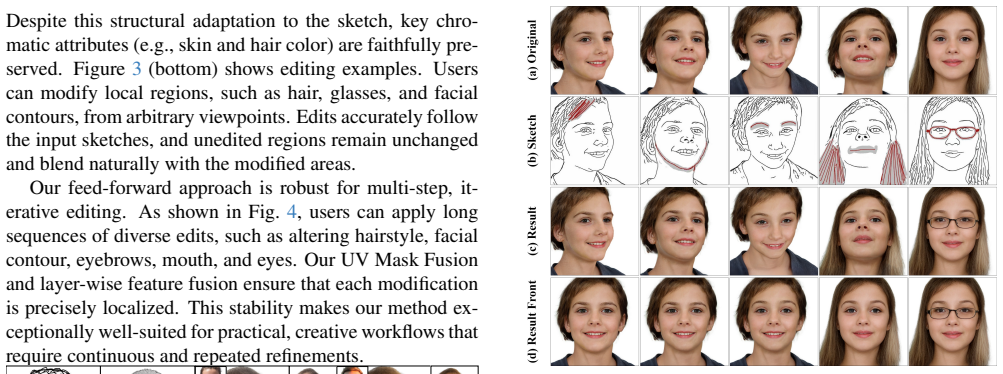





read the original abstract
3D Gaussian representations have emerged as a powerful paradigm for digital head modeling, achieving photorealistic quality with real-time rendering. However, intuitive and interactive creation or editing of 3D Gaussian head models remains challenging. Although 2D sketches provide an ideal interaction modality for fast, intuitive conceptual design, they are sparse, depth-ambiguous, and lack high-frequency appearance cues, making it difficult to infer dense, geometrically consistent 3D Gaussian structures from strokes - especially under real-time constraints. To address these challenges, we propose SketchFaceGS, the first sketch-driven framework for real-time generation and editing of photorealistic 3D Gaussian head models from 2D sketches. Our method uses a feed-forward, coarse-to-fine architecture. A Transformer-based UV feature-prediction module first reconstructs a coarse but geometrically consistent UV feature map from the input sketch, and then a 3D UV feature enhancement module refines it with high-frequency, photorealistic detail to produce a high-fidelity 3D head. For editing, we introduce a UV Mask Fusion technique combined with a layer-by-layer feature-fusion strategy, enabling precise, real-time, free-viewpoint modifications. Extensive experiments show that SketchFaceGS outperforms existing methods in both generation fidelity and editing flexibility, producing high-quality, editable 3D heads from sketches in a single forward pass.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SketchFaceGS, the first sketch-driven framework for real-time generation and editing of photorealistic 3D Gaussian head models from 2D sketches. It uses a feed-forward coarse-to-fine architecture: a Transformer-based UV feature-prediction module reconstructs a coarse geometrically consistent UV feature map from the input sketch, followed by a 3D UV feature enhancement module to add high-frequency photorealistic details. For editing, UV Mask Fusion combined with layer-by-layer feature-fusion enables precise real-time free-viewpoint modifications. The authors claim that extensive experiments demonstrate outperformance over existing methods in generation fidelity and editing flexibility, all in a single forward pass.
Significance. If the empirical claims hold, this would represent a meaningful advance in intuitive 3D head modeling by enabling real-time sketch-based interaction with Gaussian splatting representations, which are valued for photorealism and rendering speed. The combination of coarse Transformer prediction with fine enhancement and mask-based editing could lower barriers for conceptual design in animation, VR, and digital content creation. The real-time constraint and free-viewpoint guarantee are practically significant if geometric consistency is reliably achieved.
major comments (2)
- [Method description (Transformer-based UV feature-prediction module)] The central claim of geometrically consistent 3D Gaussian structures from depth-ambiguous 2D sketches rests on the Transformer UV module learning a sufficiently strong 3D prior without explicit depth or multi-view supervision. This assumption is load-bearing for the photorealism and free-viewpoint editing guarantees, yet the abstract provides no quantitative evidence (e.g., multi-view normal consistency, artifact counts, or ablation on ambiguous inputs) to substantiate it. Specific failure cases for out-of-distribution sketches should be analyzed.
- [Abstract and Experiments section] The abstract asserts that 'extensive experiments show that SketchFaceGS outperforms existing methods in both generation fidelity and editing flexibility,' but supplies no baselines, metrics (PSNR, LPIPS, user study scores), or error analysis. Without these, the outperformance claim cannot be verified and undermines assessment of the feed-forward pipeline's practical advantage.
minor comments (2)
- [Abstract] The abstract would be strengthened by briefly stating one or two key quantitative results (e.g., 'achieves X dB PSNR improvement over baseline Y') to support the fidelity claims.
- [Method] Notation for the UV feature map and mask fusion could be introduced more explicitly with a diagram or equation reference to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the content of the full manuscript while proposing targeted revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Method description (Transformer-based UV feature-prediction module)] The central claim of geometrically consistent 3D Gaussian structures from depth-ambiguous 2D sketches rests on the Transformer UV module learning a sufficiently strong 3D prior without explicit depth or multi-view supervision. This assumption is load-bearing for the photorealism and free-viewpoint editing guarantees, yet the abstract provides no quantitative evidence (e.g., multi-view normal consistency, artifact counts, or ablation on ambiguous inputs) to substantiate it. Specific failure cases for out-of-distribution sketches should be analyzed.
Authors: The Transformer-based UV feature-prediction module learns the 3D prior implicitly through supervised training on paired sketch-UV data derived from a large corpus of 3D head models. Section 4 of the manuscript reports quantitative support for geometric consistency, including multi-view normal consistency metrics, ablation studies on ambiguous inputs, and comparisons demonstrating reduced artifacts relative to baselines. We agree that the abstract would benefit from explicit mention of these results and that a dedicated analysis of out-of-distribution failure cases would strengthen the paper. We will revise the abstract to include representative quantitative metrics and add a new subsection in the experiments or limitations section that presents failure cases, artifact counts, and qualitative examples for OOD sketches. revision: yes
-
Referee: [Abstract and Experiments section] The abstract asserts that 'extensive experiments show that SketchFaceGS outperforms existing methods in both generation fidelity and editing flexibility,' but supplies no baselines, metrics (PSNR, LPIPS, user study scores), or error analysis. Without these, the outperformance claim cannot be verified and undermines assessment of the feed-forward pipeline's practical advantage.
Authors: The full experiments section (Section 4) details the baselines, reports PSNR, LPIPS, and user-study scores, and includes error analysis and ablation studies that substantiate the outperformance claims. The abstract provides a concise summary of these findings. To make the claims immediately verifiable without requiring readers to consult the full experiments, we will expand the abstract to incorporate specific quantitative results (e.g., representative PSNR/LPIPS improvements and user-study outcomes) while retaining its brevity. revision: yes
Circularity Check
No circularity: architectural pipeline with independent empirical validation
full rationale
The paper describes a feed-forward coarse-to-fine network architecture (Transformer UV feature prediction followed by enhancement and UV Mask Fusion) for generating 3D Gaussian heads from sketches. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or self-citations. The central claims concern the empirical performance of the proposed system on generation and editing tasks, which are evaluated externally via experiments rather than being forced by internal definitions or renamings. This is a standard methodological contribution without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Autodesk Maya.https : / / www
Autodesk, Inc. Autodesk Maya.https : / / www . autodesk.com/maya, 2019. 2
2019
-
[2]
Generative neu- ral articulated radiance fields.NeurIPS, 35:19900–19916,
Alexander Bergman, Petr Kellnhofer, Wang Yifan, Eric Chan, David Lindell, and Gordon Wetzstein. Generative neu- ral articulated radiance fields.NeurIPS, 35:19900–19916,
-
[3]
pi-gan: Periodic implicit genera- tive adversarial networks for 3d-aware image synthesis
Eric R Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-gan: Periodic implicit genera- tive adversarial networks for 3d-aware image synthesis. In CVPR, pages 5799–5809, 2021. 2
2021
-
[4]
Effi- cient geometry-aware 3d generative adversarial networks
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Effi- cient geometry-aware 3d generative adversarial networks. In CVPR, pages 16123–16133, 2022. 2
2022
-
[5]
Deepfacedrawing: deep generation of face im- ages from sketches.ACM TOG, 39(4):72, 2020
Shu-Yu Chen, Wanchao Su, Lin Gao, Shihong Xia, and Hongbo Fu. Deepfacedrawing: deep generation of face im- ages from sketches.ACM TOG, 39(4):72, 2020. 3
2020
-
[6]
Rosin, Chunpeng Li, Hongbo Fu, and Lin Gao
Shu-Yu Chen, Feng-Lin Liu, Yu-Kun Lai, Paul L. Rosin, Chunpeng Li, Hongbo Fu, and Lin Gao. Deepfaceediting: deep face generation and editing with disentangled geome- try and appearance control.ACM TOG, 40(4), 2021. 3
2021
-
[7]
3D face reconstruction and gaze tracking in the hmd for virtual interaction.IEEE TMM, 25:3166–3179,
Shu-Yu Chen, Yu-Kun Lai, Shihong Xia, Paul L Rosin, and Lin Gao. 3D face reconstruction and gaze tracking in the hmd for virtual interaction.IEEE TMM, 25:3166–3179,
-
[8]
Deepfacereshaping: Interac- tive deep face reshaping via landmark manipulation.Com- putational Visual Media, 10(5):949–963, 2024
Shu-Yu Chen, Yue-Ren Jiang, Hongbo Fu, Xinyang Han, Zi- tao Liu, Rong Li, and Lin Gao. Deepfacereshaping: Interac- tive deep face reshaping via landmark manipulation.Com- putational Visual Media, 10(5):949–963, 2024. 3
2024
-
[9]
Learning implicit fields for generative shape modeling
Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. InCVPR, pages 5939–5948,
-
[10]
Controllable face sketch-photo synthesis with flexible generative priors
Kun Cheng, Mingrui Zhu, Nannan Wang, Guozhang Li, Xi- aoyu Wang, and Xinbo Gao. Controllable face sketch-photo synthesis with flexible generative priors. InACM MM, pages 6959–6968, 2023. 3
2023
-
[11]
Generalizable and an- imatable gaussian head avatar.NeurIPS, 37:57642–57670,
Xuangeng Chu and Tatsuya Harada. Generalizable and an- imatable gaussian head avatar.NeurIPS, 37:57642–57670,
-
[12]
3d-aware conditional image synthesis
Kangle Deng, Gengshan Yang, Deva Ramanan, and Jun-Yan Zhu. 3d-aware conditional image synthesis. InCVPR, pages 4434–4445, 2023. 3
2023
-
[13]
Sanihead: Sketching animal-like 3D character heads using a view-surface collab- orative mesh generative network.IEEE TVCG, 28(6):2415– 2429, 2020
Dong Du, Xiaoguang Han, Hongbo Fu, Feiyang Wu, Yizhou Yu, Shuguang Cui, and Ligang Liu. Sanihead: Sketching animal-like 3D character heads using a view-surface collab- orative mesh generative network.IEEE TVCG, 28(6):2415– 2429, 2020. 3
2020
-
[14]
Introducing Gemini 2.5 Flash Image, our state-of-the-art image model.https://developers
Alisa Fortin, Guillaume Vernade, Kat Kampf, and Am- maar Reshi. Introducing Gemini 2.5 Flash Image, our state-of-the-art image model.https://developers. googleblog . com / introducing - gemini - 2 - 5 - flash-image/, 2025. 6
2025
-
[15]
3d shape induction from 2d views of multiple objects
Matheus Gadelha, Subhransu Maji, and Rui Wang. 3d shape induction from 2d views of multiple objects. In2017 in- ternational conference on 3d vision (3DV), pages 402–411. IEEE, 2017. 2
2017
-
[16]
SketchFaceNeRF: Sketch-based facial generation and editing in neural radiance fields.ACM TOG, 42(4), 2023
Lin Gao, Feng-Lin Liu, Shu-Yu Chen, Kaiwen Jiang, Chun- peng Li, Yukun Lai, and Hongbo Fu. SketchFaceNeRF: Sketch-based facial generation and editing in neural radiance fields.ACM TOG, 42(4), 2023. 2, 3, 6
2023
-
[17]
Learning multi-grained interpretable latent representation for 3D face manipulation.Computational Visual Media, 2025
Wenjing Gao, Naye Ji, Xi Li, and Dingguo Yu. Learning multi-grained interpretable latent representation for 3D face manipulation.Computational Visual Media, 2025. 2
2025
-
[18]
Generative adversarial nets.NeurIPS, 27,
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.NeurIPS, 27,
-
[19]
StyleNeRF: A style-based 3D aware generator for high- resolution image synthesis
Jiatao Gu, Lingjie Liu, Peng Wang, and Christian Theobalt. StyleNeRF: A style-based 3D aware generator for high- resolution image synthesis. InICLR. OpenReview.net, 2022. 2
2022
-
[20]
Deeps- ketch2face: a deep learning based sketching system for 3D face and caricature modeling.ACM TOG, 36(4):1–12, 2017
Xiaoguang Han, Chang Gao, and Yizhou Yu. Deeps- ketch2face: a deep learning based sketching system for 3D face and caricature modeling.ACM TOG, 36(4):1–12, 2017. 3
2017
-
[21]
Caricatureshop: Personalized and photorealistic caricature sketching.IEEE TVCG, 26(7):2349–2361, 2018
Xiaoguang Han, Kangcheng Hou, Dong Du, Yuda Qiu, Shuguang Cui, Kun Zhou, and Yizhou Yu. Caricatureshop: Personalized and photorealistic caricature sketching.IEEE TVCG, 26(7):2349–2361, 2018. 3
2018
-
[22]
LAM: large avatar model for one-shot animatable gaus- sian head
Yisheng He, Xiaodong Gu, Xiaodan Ye, Chao Xu, Zhengyi Zhao, Yuan Dong, Weihao Yuan, Zilong Dong, and Liefeng Bo. LAM: large avatar model for one-shot animatable gaus- sian head. InProc. ACM SIGGRAPH, pages 1–13, 2025. 3, 4, 6
2025
-
[23]
Escap- ing plato’s cave: 3d shape from adversarial rendering
Philipp Henzler, Niloy J Mitra, and Tobias Ritschel. Escap- ing plato’s cave: 3d shape from adversarial rendering. In ICCV, pages 9984–9993, 2019. 2
2019
-
[24]
Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020. 2
2020
-
[25]
LRM: large reconstruction model for single image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: large reconstruction model for single image to 3D. InICLR. OpenReview.net, 2024. 3
2024
-
[26]
Gsgan: Adversarial learning for hierarchical generation of 3d gaussian splats.NeurIPS, 37:67987–68012, 2024
Sangeek Hyun and Jae-Pil Heo. Gsgan: Adversarial learning for hierarchical generation of 3d gaussian splats.NeurIPS, 37:67987–68012, 2024. 2
2024
-
[27]
Nerf- facelighting: Implicit and disentangled face lighting rep- resentation leveraging generative prior in neural radiance fields.ACM TOG, 42(3):1–18, 2023
Kaiwen Jiang, Shu-Yu Chen, Hongbo Fu, and Lin Gao. Nerf- facelighting: Implicit and disentangled face lighting rep- resentation leveraging generative prior in neural radiance fields.ACM TOG, 42(3):1–18, 2023. 2
2023
-
[28]
SC-FEGAN: Face editing generative adversarial network with user’s sketch and color
Youngjoo Jo and Jongyoul Park. SC-FEGAN: Face editing generative adversarial network with user’s sketch and color. InICCV, pages 1745–1753, 2019. 3
2019
-
[29]
Learning category-specific mesh reconstruc- tion from image collections
Angjoo Kanazawa, Shubham Tulsiani, Alexei A Efros, and Jitendra Malik. Learning category-specific mesh reconstruc- tion from image collections. InECCV, pages 371–386, 2018. 2
2018
-
[30]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, pages 4401–4410, 2019. 2, 5
2019
-
[31]
Analyzing and improving the image quality of stylegan
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. InCVPR, pages 8110–8119,
-
[32]
3D gaussian splatting for real-time radiance field rendering.ACM TOG, 42(4):139:1–139:14,
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3D gaussian splatting for real-time radiance field rendering.ACM TOG, 42(4):139:1–139:14,
-
[33]
Gghead: Fast and generalizable 3d gaussian heads
Tobias Kirschstein, Simon Giebenhain, Jiapeng Tang, Markos Georgopoulos, and Matthias Nießner. Gghead: Fast and generalizable 3d gaussian heads. InProc. ACM SIG- GRAPH, pages 1–11, 2024. 2, 3, 5
2024
-
[34]
Rgbavatar: Reduced gaussian blendshapes for online modeling of head avatars
Linzhou Li, Yumeng Li, Yanlin Weng, Youyi Zheng, and Kun Zhou. Rgbavatar: Reduced gaussian blendshapes for online modeling of head avatars. InCVPR, pages 10747– 10757, 2025. 2
2025
-
[35]
Linestofacephoto: Face photo generation from lines with conditional self-attention generative adversarial networks
Yuhang Li, Xuejin Chen, Feng Wu, and Zheng-Jun Zha. Linestofacephoto: Face photo generation from lines with conditional self-attention generative adversarial networks. In ACM MM. ACM, 2019. 3
2019
-
[36]
Deepfacepencil: Creating face images from freehand sketches
Yuhang Li, Xuejin Chen, Binxin Yang, Zihan Chen, Zhihua Cheng, and Zheng-Jun Zha. Deepfacepencil: Creating face images from freehand sketches. InACM MM, pages 991–
-
[37]
Magicquill: An intelligent interactive image editing system
Zichen Liu, Yue Yu, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Wen Wang, Zhiheng Liu, Qifeng Chen, and Yujun Shen. Magicquill: An intelligent interactive image editing system. InCVPR, pages 13072–13082, 2025. 6
2025
-
[38]
Simpmodeling: Sketching implicit field to guide mesh modeling for 3d animalmorphic head de- sign
Zhongjin Luo, Jie Zhou, Heming Zhu, Dong Du, Xiaoguang Han, and Hongbo Fu. Simpmodeling: Sketching implicit field to guide mesh modeling for 3d animalmorphic head de- sign. InThe 34th annual ACM symposium on user interface software and technology, pages 854–863, 2021. 3
2021
-
[39]
3d gaussian blendshapes for head avatar animation
Shengjie Ma, Yanlin Weng, Tianjia Shao, and Kun Zhou. 3d gaussian blendshapes for head avatar animation. InProc. ACM SIGGRAPH, pages 1–10, 2024. 2
2024
-
[40]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 3
2021
-
[41]
Hologan: Unsupervised learning of 3d representations from natural images
Thu Nguyen-Phuoc, Chuan Li, Lucas Theis, Christian Richardt, and Yong-Liang Yang. Hologan: Unsupervised learning of 3d representations from natural images. InICCV, pages 7588–7597, 2019. 2
2019
-
[42]
Giraffe: Represent- ing scenes as compositional generative neural feature fields
Michael Niemeyer and Andreas Geiger. Giraffe: Represent- ing scenes as compositional generative neural feature fields. InCVPR, pages 11453–11464, 2021. 2
2021
-
[43]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rab- bat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e J´egou, Julien Mairal, P...
2024
-
[44]
Stylesdf: High-resolution 3d-consistent image and geometry generation
Roy Or-El, Xuan Luo, Mengyi Shan, Eli Shecht- man, Jeong Joon Park, and Ira Kemelmacher-Shlizerman. Stylesdf: High-resolution 3d-consistent image and geometry generation. InCVPR, pages 13503–13513, 2022. 2
2022
-
[45]
Humansplat: Generalizable single-image human gaus- sian splatting with structure priors.NeurIPS, 37:74383– 74410, 2024
Panwang Pan, Zhuo Su, Chenguo Lin, Zhen Fan, Yongjie Zhang, Zeming Li, Tingting Shen, Yadong Mu, and Yebin Liu. Humansplat: Generalizable single-image human gaus- sian splatting with structure priors.NeurIPS, 37:74383– 74410, 2024. 3
2024
-
[46]
Faceshop: deep sketch-based face image editing.ACM TOG, 37(4):99, 2018
Tiziano Portenier, Qiyang Hu, Attila Szab ´o, Siavash Ar- jomand Bigdeli, Paolo Favaro, and Matthias Zwicker. Faceshop: deep sketch-based face image editing.ACM TOG, 37(4):99, 2018. 2
2018
-
[47]
Graf: Generative radiance fields for 3d-aware image synthesis.NeurIPS, 33:20154–20166, 2020
Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. Graf: Generative radiance fields for 3d-aware image synthesis.NeurIPS, 33:20154–20166, 2020. 2
2020
-
[48]
S3d: Sketch-driven 3d model generation.arXiv preprint arXiv:2505.04185, 2025
Hail Song, Wonsik Shin, Naeun Lee, Soomin Chung, Nojun Kwak, and Woontack Woo. S3d: Sketch-driven 3d model generation.arXiv preprint arXiv:2505.04185, 2025. 3, 6
-
[49]
Recent advances in im- plicit representation-based 3d shape generation.Visual Intel- ligence, 2(1):9, 2024
Jia-Mu Sun, Tong Wu, and Lin Gao. Recent advances in im- plicit representation-based 3d shape generation.Visual Intel- ligence, 2(1):9, 2024. 2
2024
-
[50]
Instruct-gs2gs: Editing 3d gaussian splats with instructions, 2024
Cyrus Vachha and Ayaan Haque. Instruct-gs2gs: Editing 3d gaussian splats with instructions, 2024. 2
2024
-
[51]
Gaussianeditor: Editing 3d gaussians delicately with text instructions
Junjie Wang, Jiemin Fang, Xiaopeng Zhang, Lingxi Xie, and Qi Tian. Gaussianeditor: Editing 3d gaussians delicately with text instructions. InCVPR, pages 20902–20911, 2024. 2, 5
2024
-
[52]
To- wards real-world blind face restoration with generative facial prior
Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. To- wards real-world blind face restoration with generative facial prior. InCVPR, pages 9168–9178, 2021. 4
2021
-
[53]
Template-free single-view 3D human digitalization with diffusion-guided lrm
Zhenzhen Weng, Jingyuan Liu, Hao Tan, Zhan Xu, Yang Zhou, Serena Yeung-Levy, and Jimei Yang. Template-free single-view 3D human digitalization with diffusion-guided lrm. 2024. 3
2024
-
[54]
Gaussctrl: Multi-view consistent text-driven 3d gaussian splatting edit- ing
Jing Wu, Jia-Wang Bian, Xinghui Li, Guangrun Wang, Ian Reid, Philip Torr, and Victor Adrian Prisacariu. Gaussctrl: Multi-view consistent text-driven 3d gaussian splatting edit- ing. InECCV, pages 55–71. Springer, 2024. 2
2024
-
[55]
Recent advances in 3d gaussian splatting.Computational Visual Media, 10(4):613– 642, 2024
Tong Wu, Yu-Jie Yuan, Ling-Xiao Zhang, Jie Yang, Yan- Pei Cao, Ling-Qi Yan, and Lin Gao. Recent advances in 3d gaussian splatting.Computational Visual Media, 10(4):613– 642, 2024. 2
2024
-
[56]
Giraffe hd: A high-resolution 3d-aware generative model
Yang Xue, Yuheng Li, Krishna Kumar Singh, and Yong Jae Lee. Giraffe hd: A high-resolution 3d-aware generative model. InCVPR, pages 18440–18449, 2022. 2
2022
-
[57]
Learning 3D face reconstruction from a single sketch
Li Yang, Jing Wu, Jing Huo, Yu-Kun Lai, and Yang Gao. Learning 3D face reconstruction from a single sketch. Graphical Models, 115:101102, 2021. 3
2021
-
[58]
Deep plastic surgery: Robust and controllable image editing with human-drawn sketches
Shuai Yang, Zhangyang Wang, Jiaying Liu, and Zongming Guo. Deep plastic surgery: Robust and controllable image editing with human-drawn sketches. InECCV, pages 601–
-
[59]
Sketchedit: Mask- free local image manipulation with partial sketches
Yu Zeng, Zhe Lin, and Vishal M Patel. Sketchedit: Mask- free local image manipulation with partial sketches. In CVPR, pages 5951–5961, 2022. 3
2022
-
[60]
Real- time high-fidelity gaussian human avatars with position- based interpolation of spatially distributed mlps
Youyi Zhan, Tianjia Shao, Yin Yang, and Kun Zhou. Real- time high-fidelity gaussian human avatars with position- based interpolation of spatially distributed mlps. InCVPR, pages 26297–26307, 2025. 2
2025
-
[61]
Magictalk: Implicit and explicit cor- relation learning for diffusion-based emotional talking face generation.Computational Visual Media, 2025
Chenxu Zhang, Chao Wang, Jianfeng Zhang, Hongyi Xu, Guoxian Song, You Xie, Linjie Luo, Yapeng Tian, Jiashi Feng, and Xiaohu Guo. Magictalk: Implicit and explicit cor- relation learning for diffusion-based emotional talking face generation.Computational Visual Media, 2025. 2
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.