Recognition: unknown
When Can We Trust Deep Neural Networks? Towards Reliable Industrial Deployment with an Interpretability Guide
Pith reviewed 2026-05-10 02:30 UTC · model grok-4.3
The pith
A post-hoc reliability score from the IoU difference between class-specific and class-agnostic heatmaps can detect false negatives in binary defect detection networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
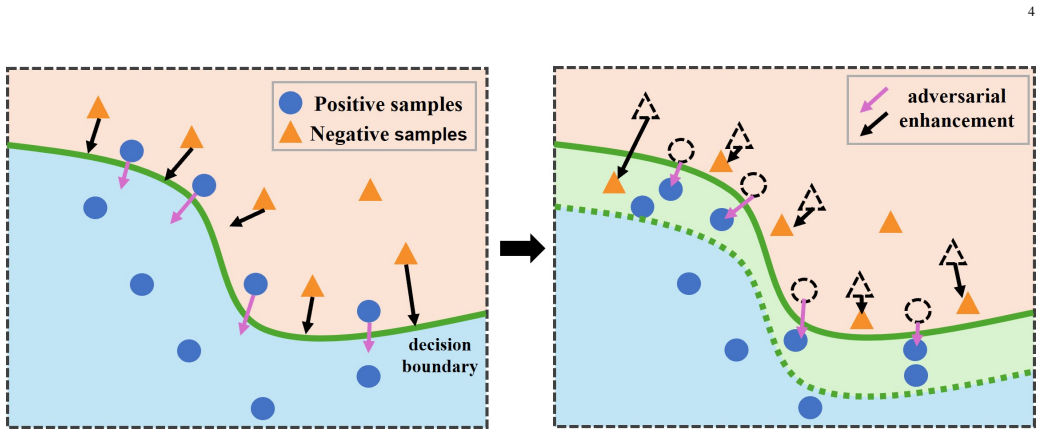
The central claim is that the difference in intersection over union between class-specific discriminative heatmaps and class-agnostic heatmaps supplies a usable reliability score for spotting false negatives in binary defect detection. An adversarial enhancement step is added to widen the separation between the two heatmaps, allowing the score to reach 100 percent recall on false negatives across the evaluated industrial datasets, although some true negatives are then also flagged. This moves deployment away from end-to-end trust toward a data-model-explanation-output sequence that supplies an explicit safeguard before an output is accepted.
What carries the argument
The IoU difference between class-specific discriminative heatmaps and class-agnostic heatmaps, used as a reliability score and enlarged by adversarial enhancement.
If this is right
- False negatives can be flagged after the network has already produced its output, without needing ground-truth labels at inference time.
- Adversarial enhancement raises recall on false negatives to 100 percent on the two reported benchmarks.
- The method supports a deployment workflow that inserts an explanation step between model output and final decision.
- Operators gain a concrete signal to distrust a prediction even when the network assigns high confidence.
Where Pith is reading between the lines
- The same heatmap-difference check could be tested on other binary vision tasks where missing a positive instance carries high cost, such as medical screening.
- Combining the IoU score with existing uncertainty estimates might reduce the rate at which true negatives are rejected.
- The approach implies that post-hoc explanations can be repurposed from diagnostic tools into runtime reliability filters.
Load-bearing premise
The IoU difference between class-specific and class-agnostic heatmaps, after adversarial amplification, separates false negatives from true negatives without domain-specific tuning or new undetected failure modes on the tested data.
What would settle it
On a fresh industrial defect dataset, false-negative images show IoU differences no smaller than those of true-negative images at the operating threshold, so the reliability score misses a substantial fraction of the errors.
Figures

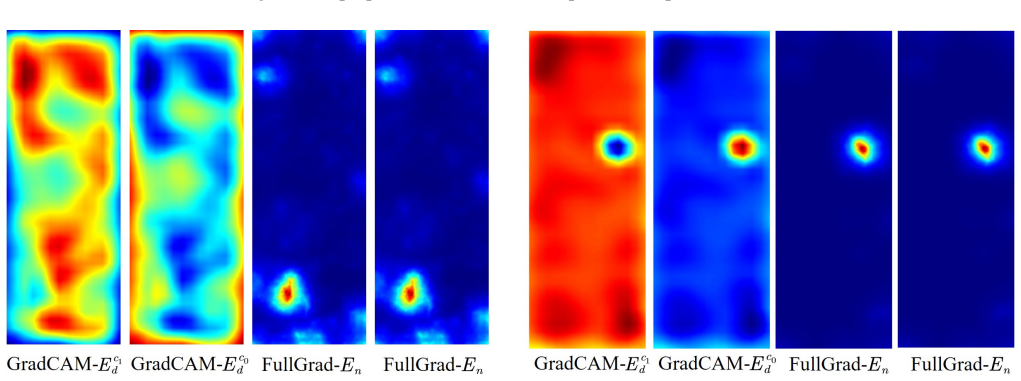
read the original abstract
The deployment of AI systems in safety-critical domains, such as industrial defect inspection, autonomous driving, and medical diagnosis, is severely hampered by their lack of reliability. A single undetected erroneous prediction can lead to catastrophic outcomes. Unfortunately, there is often no alternative but to place trust in the outputs of a trained AI system, which operates without an internal safeguard to flag unreliable predictions, even in cases of high accuracy. We propose a post-hoc explanation-based indicator to detect false negatives in binary defect detection networks. To our knowledge, this is the first method to proactively identify potentially erroneous network outputs. Our core idea leverages the difference between class-specific discriminative heatmaps and class-agnostic ones. We compute the difference in their intersection over union (IoU) as a reliability score. An adversarial enhancement method is further introduced to amplify this disparity. Evaluations on two industrial defect detection benchmarks show our method effectively identifies false negatives. With adversarial enhancement, it achieves 100\% recall, albeit with a trade-off for true negatives. Our work thus advocates for a new and trustworthy deployment paradigm: data-model-explanation-output, moving beyond conventional end-to-end systems to provide critical support for reliable AI in real-world applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a post-hoc explanation-based indicator to detect false negatives in binary defect detection DNNs for industrial applications. It defines a reliability score as the IoU difference between class-specific discriminative heatmaps and class-agnostic heatmaps, introduces an adversarial enhancement to amplify this difference, and claims that the resulting method achieves 100% recall on two industrial defect detection benchmarks while advocating for a data-model-explanation-output deployment paradigm.
Significance. If the central claim holds after proper validation, the work could offer a practical safeguard for flagging unreliable predictions in safety-critical settings by integrating interpretability directly into the output pipeline, potentially improving trustworthiness without retraining models. It provides a concrete example of leveraging explanation faithfulness for reliability scoring in defect detection.
major comments (2)
- [Experiments] Experiments section: The abstract and results claim 100% recall with adversarial enhancement on two benchmarks, yet the manuscript supplies no quantitative baselines, ablation results on the adversarial component, error analysis, or description of how false negatives were identified in the test sets. This directly prevents verification of the central claim that the IoU-based reliability score reliably detects false negatives.
- [Method] Method section (reliability score definition): The score is computed directly from post-hoc heatmap IoU differences (plus adversarial amplification). No ablations are presented on alternative explanation techniques, low-contrast or subtle defects, or variations in background texture/lighting to test whether the IoU disparity is driven primarily by missed defects rather than explanation-method artifacts or dataset-specific features. This leaves the weakest assumption untested and makes the 100% recall potentially non-generalizable.
minor comments (2)
- [Abstract] Abstract: The phrase 'albeit with a trade-off for true negatives' is stated without any accompanying precision, false-positive rate, or quantitative characterization of the trade-off.
- [Method] Notation: The distinction between 'class-specific discriminative heatmaps' and 'class-agnostic ones' is introduced without a formal equation or pseudocode showing the exact computation of the IoU difference.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below. We agree that additional experimental details and ablations are needed to strengthen verifiability and will incorporate them in the revised version.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract and results claim 100% recall with adversarial enhancement on two benchmarks, yet the manuscript supplies no quantitative baselines, ablation results on the adversarial component, error analysis, or description of how false negatives were identified in the test sets. This directly prevents verification of the central claim that the IoU-based reliability score reliably detects false negatives.
Authors: We agree that the current presentation lacks sufficient supporting details for independent verification. In the revised manuscript, we will add quantitative baselines comparing our reliability score to standard uncertainty measures such as prediction confidence and entropy. We will also include ablations isolating the adversarial enhancement (with and without it) and an error analysis section with case studies of flagged false negatives. Additionally, we will describe the ground-truth annotation process used to identify false negatives in the test sets. These changes will directly address the verifiability concern. revision: yes
-
Referee: [Method] Method section (reliability score definition): The score is computed directly from post-hoc heatmap IoU differences (plus adversarial amplification). No ablations are presented on alternative explanation techniques, low-contrast or subtle defects, or variations in background texture/lighting to test whether the IoU disparity is driven primarily by missed defects rather than explanation-method artifacts or dataset-specific features. This leaves the weakest assumption untested and makes the 100% recall potentially non-generalizable.
Authors: We concur that robustness checks are essential to confirm the score reflects missed defects rather than artifacts. In the revision, we will add ablations using alternative post-hoc methods (e.g., Grad-CAM and LIME) for computing the IoU difference. We will also evaluate performance on data subsets with low-contrast defects and controlled variations in background texture and lighting. These experiments will help establish that the reliability score generalizes beyond the specific explanation technique and dataset characteristics used in the original results. revision: yes
Circularity Check
No significant circularity; reliability score is a direct definitional construction from heatmap IoU arithmetic.
full rationale
The paper's core contribution is the explicit definition of a reliability score as the IoU difference between class-specific discriminative heatmaps and class-agnostic heatmaps, followed by an adversarial amplification step. This is presented as a post-hoc indicator without any derivation chain that reduces back to fitted parameters, self-citations, or prior results by the same authors. No equations or claims in the abstract or described method invoke uniqueness theorems, ansatzes smuggled via citation, or renaming of known results. The approach is self-contained as a proposed computational procedure whose output is arithmetically determined by the chosen explanation method's heatmaps; it does not claim to predict or derive external quantities from first principles that loop back to the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Post-hoc explanation heatmaps accurately capture the features the network uses for its class decision
invented entities (1)
-
Reliability score defined as IoU difference between class-specific and class-agnostic heatmaps
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[2]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafsonet al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
A comprehensive overview of large language models,
H. Naveed, A. U. Khan, S. Qiu, M. Saqib, S. Anwar, M. Usman, N. Akhtar, N. Barnes, and A. Mian, “A comprehensive overview of large language models,”ACM Transactions on Intelligent Systems and Technology, vol. 16, no. 5, pp. 1–72, 2025
2025
-
[4]
A systematic review of deep learning approaches for surface defect detection in industrial applica- tions,
R. Ameri, C.-C. Hsu, and S. S. Band, “A systematic review of deep learning approaches for surface defect detection in industrial applica- tions,”Engineering Applications of Artificial Intelligence, vol. 130, p. 107717, 2024
2024
-
[5]
Surface defect inspection of industrial products with object detection deep networks: A systematic review,
Y . Ma, J. Yin, F. Huang, and Q. Li, “Surface defect inspection of industrial products with object detection deep networks: A systematic review,”Artificial Intelligence Review, vol. 57, no. 12, p. 333, 2024
2024
-
[6]
Path planning algorithms in the autonomous driving system: A comprehensive review,
M. Reda, A. Onsy, A. Y . Haikal, and A. Ghanbari, “Path planning algorithms in the autonomous driving system: A comprehensive review,” Robotics and Autonomous Systems, vol. 174, p. 104630, 2024
2024
-
[7]
Recent advances in medical imaging segmentation: A survey,
F. Bougourzi and A. Hadid, “Recent advances in medical imaging segmentation: A survey,”arXiv preprint arXiv:2505.09274, 2025
-
[8]
On interpretability of artificial neural networks: A survey,
F.-L. Fan, J. Xiong, M. Li, and G. Wang, “On interpretability of artificial neural networks: A survey,”IEEE Transactions on Radiation and Plasma Medical Sciences, vol. 5, no. 6, pp. 741–760, 2021
2021
-
[9]
A survey of uncertainty in deep neural networks,
J. Gawlikowski, C. R. N. Tassi, M. Ali, J. Lee, M. Humt, J. Feng, A. Kruspe, R. Triebel, P. Jung, R. Roscheret al., “A survey of uncertainty in deep neural networks,”Artificial Intelligence Review, vol. 56, no. Suppl 1, pp. 1513–1589, 2023
2023
-
[10]
Improving monte carlo dropout uncertainty esti- mation with stable output layers,
S. Son and J. Seok, “Improving monte carlo dropout uncertainty esti- mation with stable output layers,”Neurocomputing, vol. 661, p. 131927, 2026
2026
-
[11]
Generalized out-of-distribution detection: A survey,
J. Yang, K. Zhou, Y . Li, and Z. Liu, “Generalized out-of-distribution detection: A survey,”International Journal of Computer Vision, vol. 132, no. 12, pp. 5635–5662, 2024
2024
-
[12]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inICCV, 2017, pp. 618–626
2017
-
[13]
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods,
E. H ¨ullermeier and W. Waegeman, “Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods,”Machine learning, vol. 110, no. 3, pp. 457–506, 2021
2021
-
[14]
Aleatory and epistemic uncertainty in probability elicita- tion with an example from hazardous waste management,
S. C. Hora, “Aleatory and epistemic uncertainty in probability elicita- tion with an example from hazardous waste management,”Reliability engineering & system safety, vol. 54, no. 2-3, pp. 217–223, 1996
1996
-
[15]
Dropout: A simple way to prevent neural networks from over- fitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhut- dinov, “Dropout: A simple way to prevent neural networks from over- fitting,”Journal of Machine Learning Research, vol. 15, no. 56, pp. 1929–1958, 2014
1929
-
[16]
Interpretable by design: Learning predictors by composing interpretable queries,
A. Chattopadhyay, S. Slocum, B. D. Haeffele, R. Vidal, and D. Geman, “Interpretable by design: Learning predictors by composing interpretable queries,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 45, no. 6, pp. 7430–7443, 2022
2022
-
[17]
Optimising for interpretability: Convolutional dynamic alignment networks,
M. B ¨ohle, M. Fritz, and B. Schiele, “Optimising for interpretability: Convolutional dynamic alignment networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 7625– 7638, 2023
2023
-
[18]
B-cos alignment for inherently interpretable cnns and vision transformers,
M. B ¨ohle, N. Singh, M. Fritz, and B. Schiele, “B-cos alignment for inherently interpretable cnns and vision transformers,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 46, no. 6, pp. 4504–4518, 2024
2024
-
[19]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,
C. Rudin, “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,”Nature Machine Intelligence, vol. 1, no. 5, pp. 206–215, 2019
2019
-
[20]
Under- standing neural networks through deep visualization,
J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, and H. Lipson, “Under- standing neural networks through deep visualization,”Computer Science, 2015
2015
-
[21]
Visualizing and understanding convolutional networks,
M. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” inECCV, 2014, pp. 818–833
2014
-
[22]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” inICML, 2017, pp. 3319–3328
2017
-
[23]
SmoothGrad: removing noise by adding noise
D. Smilkov, N. Thorat, B. Kim, F. Vi ´egas, and M. Wattenberg, “Smooth- grad: removing noise by adding noise,”arXiv preprint:1706.03825, 2017
work page Pith review arXiv 2017
-
[24]
Learning deep features for discriminative localization,
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” inCVPR, 2016, pp. 2921– 2929
2016
-
[25]
Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,
A. Chattopadhay, A. Sarkar, P. Howlader, and V . N. Balasubramanian, “Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,” inWACV, 2018, pp. 839–847
2018
-
[26]
Score-cam: Score-weighted visual explanations for convo- lutional neural networks,
H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, and X. Hu, “Score-cam: Score-weighted visual explanations for convo- lutional neural networks,”arXiv preprint:1910.01279, 2019
-
[27]
Group-cam: Group score-weighted visual explanations for deep convolutional networks,
Q. Zhang, L. Rao, and Y . Yang, “Group-cam: Group score-weighted visual explanations for deep convolutional networks,”arXiv preprint arXiv:2103.13859, 2021
-
[28]
On pixel-wise explanations for non-linear classifier deci- sions by layer-wise relevance propagation,
S. Bach, A. Binder, G. Montavon, F. Klauschen, K.-R. M ¨uller, and W. Samek, “On pixel-wise explanations for non-linear classifier deci- sions by layer-wise relevance propagation,”PloS one, vol. 10, no. 7, p. e0130140, 2015
2015
-
[29]
Improving deep neural network generalization and robustness to background bias via layer-wise relevance propagation optimization,
P. R. Bassi, S. S. Dertkigil, and A. Cavalli, “Improving deep neural network generalization and robustness to background bias via layer-wise relevance propagation optimization,”Nature Communications, vol. 15, no. 1, p. 291, 2024
2024
-
[30]
Visualization of supervised and self- supervised neural networks via attribution guided factorization,
S. Gur, A. Ali, and L. Wolf, “Visualization of supervised and self- supervised neural networks via attribution guided factorization,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 13, 2021, pp. 11 545–11 554
2021
-
[31]
Full-gradient representation for neural network visualization,
S. Srinivas and F. Fleuret, “Full-gradient representation for neural network visualization,” inNeurIPS, 2019, pp. 4124–4133
2019
-
[32]
State of the art in defect detection based on machine vision,
Z. Ren, F. Fang, N. Yan, and Y . Wu, “State of the art in defect detection based on machine vision,”International Journal of Precision Engineering and Manufacturing-Green Technology, vol. 9, no. 2, pp. 661–691, 2022
2022
-
[33]
Design and application of industrial machine vision systems,
H. Golnabi and A. Asadpour, “Design and application of industrial machine vision systems,”Robotics and Computer-Integrated Manufacturing, vol. 23, no. 6, pp. 630–637, 2007, 16th International Conference on Flexible Automation and Intelligent Manufacturing. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0736584507000233
2007
-
[34]
Md-yolo: surface defect detector for industrial complex environments,
H. Zheng, X. Chen, H. Cheng, Y . Du, and Z. Jiang, “Md-yolo: surface defect detector for industrial complex environments,”Optics and Lasers in Engineering, vol. 178, p. 108170, 2024
2024
-
[35]
Railway rutting defects detection based on improved rt-detr,
C. Yu and X. Chen, “Railway rutting defects detection based on improved rt-detr,”Journal of Real-Time Image Processing, vol. 21, no. 4, p. 146, 2024
2024
-
[36]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review arXiv 2014
-
[37]
Segmentation-based deep-learning approach for surface-defect detection,
D. Tabernik, S. Sela, J. Skvarc, and D. Skocaj, “Segmentation-based deep-learning approach for surface-defect detection,”Journal of Intelli- gent Manufacturing, vol. 31, no. 3, pp. 759–776, 2020
2020
-
[38]
Mixed supervision for surface- defect detection: From weakly to fully supervised learning,
J. Bozic, D. Tabernik, and D. Skocaj, “Mixed supervision for surface- defect detection: From weakly to fully supervised learning,”Comput. Ind., vol. 129, p. 103459, 2021
2021
-
[39]
Cbam: Convolutional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.