Recognition: unknown
Audio Spoof Detection with GaborNet
Pith reviewed 2026-05-10 02:01 UTC · model grok-4.3
The pith
Gabor filter banks serve as an ingestion layer for raw audio in neural networks built for spoof detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An ingestion layer built from a bank of Gabor filters, named GaborNet, together with the required modifications for complex-valued outputs, can be integrated into the RawNet2 and RawGAT-ST architectures for audio spoof detection, and standard audio augmentation techniques using codecs, room impulse responses, and additive noises further support training of these models.
What carries the argument
GaborNet: a neural ingestion layer that convolves the raw input waveform with a bank of Gabor filters and applies post-processing (squared modulus or Gaussian lowpass pooling) to convert the complex results into real-valued features suitable for subsequent network stages.
If this is right
- Frequency-domain distortions caused by truncating sinc functions are reduced when Gabor filters are used instead.
- Raw audio can be processed directly inside established spoof-detection networks without intermediate hand-crafted features.
- Augmenting training data with codec conversions, reverberation, and noise improves the robustness of the resulting detectors.
- The same GaborNet front-end can be dropped into both RawNet2 and RawGAT-ST, showing architectural flexibility.
Where Pith is reading between the lines
- The approach may transfer to other raw-audio tasks such as speaker verification or environmental sound classification.
- Because Gabor filters are complex, they implicitly retain phase information that purely real-valued filters discard, which could help against phase-manipulated spoofs.
- Direct head-to-head accuracy and latency comparisons against SincNet baselines on multiple datasets would clarify whether the gains are consistent.
Load-bearing premise
That Gabor filters, after the modifications needed to handle their complex outputs, extract features from raw audio that are more useful and less distorted than those produced by sinc filters for the task of identifying spoofs.
What would settle it
A controlled experiment in which the GaborNet versions of RawNet2 or RawGAT-ST achieve equal or higher equal-error rates than the original sinc-based versions on a standard benchmark such as ASVspoof would show that the filter replacement does not deliver the intended improvement.
Figures




read the original abstract
An direction of development in the extraction of features from audio signals is based on processing raw samples in the time domain. Such an approach appears to be effective, especially in the era of neural networks. An example is SincNet. In this solution, the core of the neural network layer is a set of sinc functions that are convolved with the input signal. Due to the finite length of sinc functions, distortions appear in the frequency domain of the convolved signal, the same as in the case of windowing the signal. Recently, a new approach has been developed that uses Gabor filters to replace sinc functions. Due to the complex results, further modifications had to be applied, such as squared modulus or Gaussian Lowpass Pooling. In this work, an ingestion layer based on a bank of Gabor filters, named GaborNet, and its modifications are intensively examined within the popular RawNet2 and RawGAT- ST architectures. These have been developed for the purpose of audio spoof detection. Another issue that has been investigated was audio augmentation using codec conversions, room responses, and additive noises.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GaborNet, an ingestion layer consisting of a bank of Gabor filters for raw time-domain audio processing in spoof detection. It replaces sinc functions from prior work like SincNet, applies post-processing modifications (squared modulus or Gaussian Lowpass Pooling) to address complex-valued outputs, integrates the layer into RawNet2 and RawGAT-ST backbones, and evaluates the resulting systems together with standard audio augmentations (codec conversion, room impulse responses, additive noise). The central contribution is framed as an intensive empirical examination rather than a theoretical derivation.
Significance. If the reported experiments demonstrate competitive or improved equal error rates on standard spoof detection benchmarks relative to sinc-based baselines, the work would provide a practical alternative for learnable filter banks in raw-audio anti-spoofing pipelines. The explicit treatment of complex-output handling and the combination with established augmentation pipelines add incremental engineering value, though the absence of any numerical results in the abstract limits immediate assessment of impact.
major comments (1)
- [Abstract] Abstract: the claim of an 'intensive examination' is not supported by any reported metrics, baselines, or error bars, so the soundness of the empirical conclusions cannot be evaluated from the provided summary.
minor comments (2)
- [Abstract] The abstract and introduction should explicitly state the datasets (e.g., ASVspoof 2019/2021), evaluation metrics, and number of runs to allow readers to gauge reproducibility.
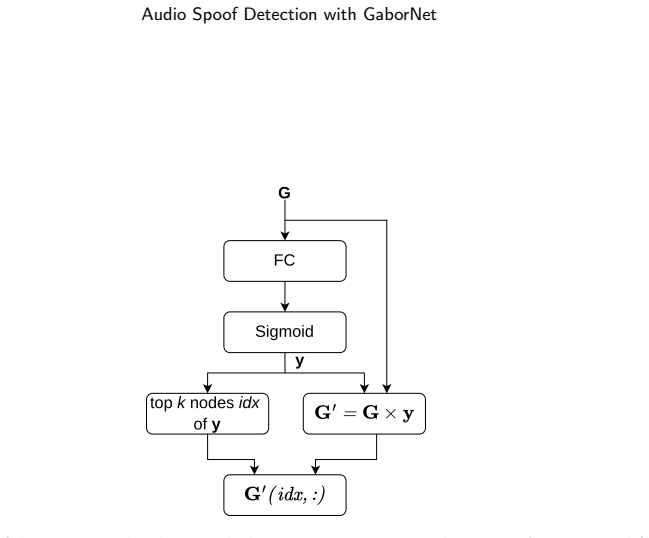
- [Methods] Notation for the Gabor filter parameters (center frequency, bandwidth, etc.) and the exact form of the squared-modulus and Gaussian Lowpass Pooling operations should be given in a dedicated methods subsection with equations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: Abstract: the claim of an 'intensive examination' is not supported by any reported metrics, baselines, or error bars, so the soundness of the empirical conclusions cannot be evaluated from the provided summary.
Authors: We agree that the abstract does not currently include numerical results, which limits immediate assessment of the empirical claims. In the revised manuscript we will update the abstract to report key equal error rates (EER) achieved by the GaborNet variants within RawNet2 and RawGAT-ST, together with direct comparisons to the corresponding SincNet baselines and a brief indication of the augmentation pipeline. This change will allow readers to evaluate the strength of the empirical examination from the abstract itself. revision: yes
Circularity Check
No significant circularity: purely empirical examination
full rationale
The paper describes an empirical study replacing the sinc layer in RawNet2 and RawGAT-ST with a Gabor-filter bank (GaborNet) plus documented post-processing (squared modulus or Gaussian low-pass pooling) and standard audio augmentations. No equations, derivations, predictions, or first-principles claims are present; performance numbers are obtained from experiments on spoof-detection benchmarks. No self-citation is used to justify a uniqueness theorem or to force a result by construction. The central claim is limited to 'intensive examination' of the modified architectures, which is self-contained against external benchmarks and does not reduce to any fitted input or renamed ansatz.
Axiom & Free-Parameter Ledger
invented entities (1)
-
GaborNet
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Andén,J.,Mallat,S.,2014. Deepscatteringspectrum. IEEETransactionsonSignalProcessing62,4114–4128. doi:10.1109/TSP.2014.2326991. Brümmer, N., de Villiers, E.,
-
[2]
The bosaris toolkit: Theory, algorithms and code for surviving the new dcf,
The bosaris toolkit: Theory, algorithms and code for surviving the new dcf. ArXiv abs/1304.2865. URL: https://api.semanticscholar.org/CorpusID:14392885. Cohen, A., Rimon, I., Aflalo, E., Permuter, H.H.,
-
[3]
Alain de Cheveigné and Hideki Kawahara
Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech, and Signal Processing 28, 357–366. doi:10.1109/TASSP.1980.1163420. Gao,H.,Ji,S.,2022. Graphu-nets. IEEETransactionsonPatternAnalysisandMachineIntelligence44,4948–4960. doi:10.1109/TPAMI.2021. 3081010. Gupta, ...
-
[4]
EURASIP Journal on Audio, Speech,and MusicProcessing2024
Vulnerability issues in Automatic Speaker Verification (ASV) systems. EURASIP Journal on Audio, Speech,and MusicProcessing2024. URL:http://dx.doi.org/10.1186/s13636-024-00328-8, doi:10.1186/s13636-024-00328-8. He, K., Zhang, X., Ren, S., Sun, J.,
-
[5]
Improved rawnet with filter-wise rescaling for text-independent speaker verification using raw waveforms. ArXiv abs/2004.00526. URL:https://api.semanticscholar.org/CorpusID:226202021. Knyazev, B., Taylor, G.W., Amer, M.R.,
-
[6]
URL:https://api.semanticscholar.org/CorpusID:195069083
Understanding attention and generalization in graph neural networks, in: Neural Information Processing Systems. URL:https://api.semanticscholar.org/CorpusID:195069083. Ko,T.,Peddinti,V.,Povey,D.,Seltzer,M.L.,Khudanpur,S.,2017.Astudyondataaugmentationofreverberantspeechforrobustspeechrecognition, in: 2017 IEEE International Conference on Acoustics, Speech ...
-
[7]
Vggsound: A Large-Scale Audio-Visual Dataset
Cgcnn: Complex gabor convolutional neural network on raw speech, in: ICASSP 2020 - 2020 IEEE InternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP),pp.7724–7728. doi:10.1109/ICASSP40776.2020.9054220. Oppenheim, A.V., Schafer, R.W.,
-
[8]
Speaker recognition from raw waveform with sincnet, in: 2018 IEEE Spoken Language Technology Workshop (SLT), pp. 1021–1028. doi:10.1109/SLT.2018.8639585. Snyder, D., Chen, G., Povey, D.,
-
[9]
Audioclip: Extending clip to image, text and audio
Musan: A music, speech, and noise corpus. ArXiv abs/1510.08484. URL:https://api. semanticscholar.org/CorpusID:15676318. Tak, H., Jee-weon Jung, Patino, J., Kamble, M.R., Todisco, M., Evans, N.W.D., 2021a. End-to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection. ArXiv abs/2107.12710. URL:htt...
-
[10]
Computer Speech & Language 64, 101114
Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech. Computer Speech & Language 64, 101114. URL:https: //www.sciencedirect.com/science/article/pii/S0885230820300474, doi:https://doi.org/10.1016/j.csl.2020.101114. Wang, Y., Getreuer, P., Hughes, T., Lyon, R.F., Saurous, R.A.,
-
[11]
2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 5670–5674URL:https://api.semanticscholar.org/ CorpusID:3100199
Trainable frontend for robust and far-field keyword spotting. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 5670–5674URL:https://api.semanticscholar.org/ CorpusID:3100199. Zeghidour, N., Teboul, O., de Chaumont Quitry, F., Tagliasacchi, M.,
2017
-
[12]
Leaf: A learnable frontend for audio classification. ArXiv abs/2101.08596. URL:https://api.semanticscholar.org/CorpusID:231662084. Zeghidour, N., Usunier, N., Kokkinos, I., Schaiz, T., Synnaeve, G., Dupoux, E.,
-
[13]
Learning filterbanks from raw speech for phone recognition, in: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5509–5513. doi:10.1109/ICASSP.2018. 8462015. Waldemar Maciejko Page 10 of 10 Audio Spoof Detection with GaborNet Figure 1:Three examples of sinc functions at the training stage across three epochs:0𝑡ℎ,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.