Recognition: unknown
Thinking Before Matching: A Reinforcement Reasoning Paradigm Towards General Person Re-Identification
Pith reviewed 2026-05-10 02:17 UTC · model grok-4.3
The pith
ReID-R identifies people across scenes by reasoning through chain-of-thought and reinforcement learning rather than fitting massive annotated data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReID-R establishes that incorporating chain-of-thought reasoning into the ReID pipeline enables explicit identity understanding and accurate matching. The method trains via a discriminative reasoning warm-up stage in a CoT label-free manner to acquire identity-aware feature understanding, followed by efficient reinforcement learning that applies non-trivial sampling to build scene-generalizable data. High-quality reward signals then guide the model to prioritize ID-related cues, yielding correct responses and built-in interpretations. Experiments across multiple benchmarks show this reaches performance levels of leading methods while using substantially less data.
What carries the argument
ReID-R, a two-stage framework with a chain-of-thought discriminative reasoning warm-up followed by reinforcement learning driven by non-trivial sampling and reward signals that reinforce focus on identity-causal cues.
If this is right
- ReID systems can reach competitive identity discrimination on benchmarks while training on roughly one-fifth the usual data volume.
- Built-in reasoning produces high-quality interpretations that explain why particular matches are selected.
- Focus on identity-causal cues improves robustness against scene disruptions such as lighting or background changes.
- The reinforcement stage with non-trivial sampling yields more generalizable representations than perception-only training.
Where Pith is reading between the lines
- Similar reasoning pipelines could reduce annotation demands in related tasks like multi-object tracking or cross-camera vehicle re-identification.
- The interpretable outputs might support human-in-the-loop verification in security applications where explanations are required.
- If reward quality remains high across domains, the method could serve as a template for data-efficient training in other vision problems that currently demand massive labeled sets.
Load-bearing premise
The chain-of-thought warm-up combined with reinforcement learning and non-trivial sampling will steer the model toward identity-causal cues rather than scene-specific artifacts, and the resulting reward signals will prove high-quality enough for generalizable reasoning.
What would settle it
Train ReID-R on standard benchmarks then evaluate on a new multi-scene test set containing the same identities but substantially altered backgrounds and viewpoints; if matching accuracy falls below conventional methods or the generated interpretations cite scene elements instead of identity features, the central claim is falsified.
Figures






read the original abstract
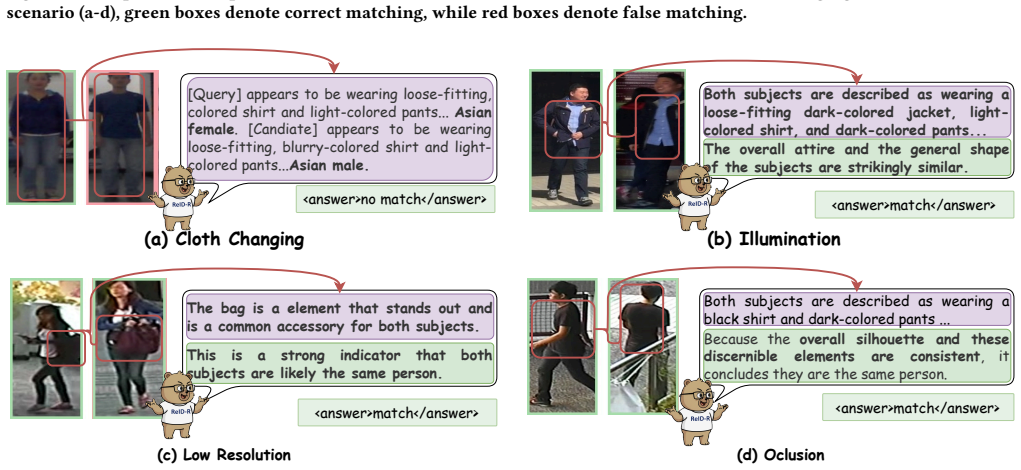
Learning identity-discriminative representations with multi-scene generality has become a critical objective in person re-identification (ReID). However, mainstream perception-driven paradigms tend to identify fitting from massive annotated data rather than identity-causal cues understanding, which presents a fragile representation against multiple disruptions. In this work, ReID-R is proposed as a novel reasoning-driven paradigm that achieves explicit identity understanding and reasoning by incorporating chain-of-thought into the ReID pipeline. Specifically, ReID-R consists of a two-stage contribution: (i) Discriminative reasoning warm-up, where a model is trained in a CoT label-free manner to acquire identity-aware feature understanding; and (ii) Efficient reinforcement learning, which proposes a non-trivial sampling to construct scene-generalizable data. On this basis, ReID-R leverages high-quality reward signals to guide the model toward focusing on ID-related cues, achieving accurate reasoning and correct responses. Extensive experiments on multiple ReID benchmarks demonstrate that ReID-R achieves competitive identity discrimination as superior methods using only 14.3K non-trivial data (20.9% of the existing data scale). Furthermore, benefit from inherent reasoning, ReID-R can provide high-quality interpretation for results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReID-R, a reasoning-driven paradigm for person re-identification that integrates chain-of-thought warm-up for identity-aware feature understanding followed by reinforcement learning with non-trivial sampling to construct scene-generalizable data and high-quality rewards focused on ID-related cues. It claims this achieves competitive identity discrimination on multiple ReID benchmarks using only 14.3K non-trivial samples (20.9% of standard data scale) while also enabling high-quality result interpretation.
Significance. If the central claims hold with rigorous validation, the work could meaningfully advance data-efficient and interpretable ReID by shifting from perception-driven fitting on massive datasets to explicit reasoning over identity-causal features, addressing fragility to disruptions like scene changes. The two-stage pipeline and emphasis on reduced data scale represent a potentially valuable direction, though the absence of detailed metrics, baselines, and ablations in the abstract prevents assessing the practical magnitude or robustness of gains.
major comments (2)
- [Abstract] Abstract: the headline claim of competitive ReID performance with 14.3K non-trivial samples (20.9% data scale) is presented without any quantitative metrics, baseline comparisons, ablation studies, or implementation specifics, rendering the central data-efficiency result unverifiable and load-bearing for the paper's contribution.
- [Method (RL stage)] Reinforcement learning stage (non-trivial sampling): the method asserts that non-trivial sampling plus CoT warm-up produces reward signals based on identity-causal cues rather than dataset-specific artifacts (background, camera, lighting), but no explicit validation, parameter-free derivation, or safeguard against spurious correlations is described; this is the least secure link for the reduced-data claim and requires concrete tests (e.g., cross-dataset generalization or artifact ablation) to confirm it is not selection bias.
minor comments (2)
- [Abstract] Abstract: minor grammatical issue in 'benefit from inherent reasoning' should read 'benefiting from inherent reasoning'.
- [Abstract] Abstract: no mention of specific ReID benchmarks, evaluation protocols, or reward formulation details, which would improve clarity even at high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications and commitments to revisions where the manuscript can be strengthened without altering its core claims or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of competitive ReID performance with 14.3K non-trivial samples (20.9% data scale) is presented without any quantitative metrics, baseline comparisons, ablation studies, or implementation specifics, rendering the central data-efficiency result unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract's high-level claim would be more verifiable with key quantitative support. The full manuscript reports these details in Section 4 (Experiments), including direct comparisons to SOTA methods on multiple benchmarks (e.g., Market-1501, DukeMTMC-reID, MSMT17) with specific Rank-1 and mAP values achieved using the 14.3K samples, plus ablations on the two-stage pipeline. Due to abstract length limits, we will revise it to include one or two representative metrics (e.g., competitive performance figures) and a brief reference to the data scale reduction, while directing readers to the experimental section for full baselines and implementation details. revision: yes
-
Referee: [Method (RL stage)] Reinforcement learning stage (non-trivial sampling): the method asserts that non-trivial sampling plus CoT warm-up produces reward signals based on identity-causal cues rather than dataset-specific artifacts (background, camera, lighting), but no explicit validation, parameter-free derivation, or safeguard against spurious correlations is described; this is the least secure link for the reduced-data claim and requires concrete tests (e.g., cross-dataset generalization or artifact ablation) to confirm it is not selection bias.
Authors: This is a fair observation on the need for stronger safeguards. The manuscript validates the approach through extensive cross-benchmark experiments (Section 4.2) showing generalization across scene variations and ablations (Section 4.3) isolating the contribution of non-trivial sampling and CoT warm-up to ID-focused rewards. However, we acknowledge the absence of a dedicated artifact-specific ablation (e.g., explicit background/lighting perturbation tests). We will add such an analysis in the revised manuscript, including quantitative results on how performance holds when artifacts are controlled, to directly rule out selection bias and strengthen the reduced-data claim. revision: partial
Circularity Check
No circularity: empirical method proposal with no reducing derivations
full rationale
The paper introduces ReID-R as a two-stage reasoning-driven paradigm (CoT warm-up followed by RL with non-trivial sampling) and supports its claims via experimental results on ReID benchmarks showing competitive performance with reduced data. No equations, derivations, or self-citations are referenced in the provided text that reduce the identity discrimination claims or data-efficiency results to quantities defined by the method's own fitted inputs or prior self-work. The central claims rest on empirical validation rather than any self-definitional, fitted-prediction, or uniqueness-imported structure. This is the expected non-finding for a method paper whose load-bearing steps are experimental rather than deductive.
Axiom & Free-Parameter Ledger
free parameters (2)
- non-trivial sampling parameters
- reward signal formulation
axioms (1)
- domain assumption Identity-causal cues can be explicitly understood and reasoned about via chain-of-thought in a label-free warm-up phase.
invented entities (1)
-
ReID-R paradigm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A frontier large vision- language model with versatile abilities.arXiv preprint arXiv:2308.12966(2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Yang Bai, Yucheng Ji, Min Cao, Jinqiao Wang, and Mang Ye. 2025. Chat-based Person Retrieval via Dialogue-Refined Cross-Modal Alignment. InCVPR. 3952– 3962
2025
-
[4]
Min Cao, Xinyu Zhou, Ding Jiang, Bo Du, Mang Ye, and Min Zhang. 2025. Multi- lingual Text-to-Image Person Retrieval via Bidirectional Relation Reasoning and Aligning.IEEE TPAMI(2025), 1–18
2025
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Yongxing Dai, Yifan Sun, Jun Liu, Zekun Tong, and Ling-Yu Duan. 2025. Bridging the source-to-target gap for cross-domain person re-identification with interme- diate domains.IJCV133, 1 (2025), 410–434
2025
-
[7]
Mengying Duan, He Li, and Mang Ye. 2025. MLLMs Meet Person Re-identification. InACMMM. 12247–12256
2025
-
[8]
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. 2025. Video- R1: Reinforcing Video Reasoning in MLLMs. InNIPS. https://openreview.net/ forum?id=a2JTVVvcEl
2025
-
[9]
Xinqian Gu, Hong Chang, Bingpeng Ma, Shutao Bai, Shiguang Shan, and Xilin Chen. 2022. Clothes-changing person re-identification with rgb modality only. InCVPR. 1060–1069
2022
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1 incen- tivizes reasoning in llms through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[11]
Shuting He, Hao Luo, Pichao Wang, Fan Wang, Hao Li, and Wei Jiang. 2021. TransReID: Transformer-based object re-identification. InCVPR. 15013–15022
2021
-
[12]
Weizhen He, Yiheng Deng, Shixiang Tang, Qihao Chen, Qingsong Xie, Yizhou Wang, Lei Bai, Feng Zhu, Rui Zhao, Wanli Ouyang, et al. 2024. Instruct-ReID: A multi-purpose person re-identification task with instructions. InCVPR. 17521– 17531
2024
- [13]
-
[14]
Ruibing Hou, Bingpeng Ma, Hong Chang, Xinqian Gu, Shiguang Shan, and Xilin Chen. 2019. Interaction-and-aggregation network for person re-identification. In CVPR. 9317–9326
2019
-
[15]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InICLR. 1–13. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[16]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. 2025. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749(2025)
work page internal anchor Pith review arXiv 2025
-
[17]
Yan Huang, Qiang Wu, JingSong Xu, Yi Zhong, and ZhaoXiang Zhang. 2021. Clothing status awareness for long-term person re-identification. InCVPR
2021
-
[18]
Xin Jin, Cuiling Lan, Wenjun Zeng, Guoqiang Wei, and Zhibo Chen. 2020. Semantics-aligned representation learning for person re-identification. InAAAI. 11173–11180
2020
-
[19]
Siyuan Li, Li Sun, and Qingli Li. 2023. CLIP-ReID: exploiting vision-language model for image re-identification without concrete text labels. InAAAI. 1405– 1413
2023
-
[20]
Wei Li, Rui Zhao, Tong Xiao, and Xiaogang Wang. 2014. Deepreid: Deep filter pairing neural network for person re-identification. InCVPR. 152–159
2014
-
[21]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024. Visual instruc- tion tuning.NIPS36 (2024)
2024
-
[22]
Yiding Lu, Mouxing Yang, Dezhong Peng, Peng Hu, Yijie Lin, and Xi Peng
-
[23]
LLaVA-ReID: Selective Multi-image Questioner for Interactive Person Re-Identification. InICML. https://openreview.net/forum?id=c4EEnWu9FE
- [24]
-
[25]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al . 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Yifan Sun, Liang Zheng, Yi Yang, Qi Tian, and Shengjin Wang. 2018. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). InECCV. 480–496
2018
-
[27]
Shixiang Tang, Cheng Chen, Qingsong Xie, Meilin Chen, Yizhou Wang, Yuanzheng Ci, Lei Bai, Feng Zhu, Haiyang Yang, Li Yi, et al. 2023. Humanbench: Towards general human-centric perception with projector assisted pretraining. InCVPR. 21970–21982
2023
-
[28]
Fangbin Wan, Yang Wu, Xuelin Qian, Yixiong Chen, and Yanwei Fu. 2020. When person re-identification meets changing clothes. InCVPR Workshops. 830–831
2020
-
[29]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. 2025. VideoRFT: Incentivizing Video Reasoning Capability in MLLMs via Reinforced Fine-Tuning. InNIPS. https://openreview.net/forum?id=3pORFyKzh1
2025
-
[31]
Yuhao Wang, Xuehu Liu, Tianyu Yan, Yang Liu, Aihua Zheng, Pingping Zhang, and Huchuan Lu. 2025. MambaPro: Multi-modal object re-identification with mamba aggregation and synergistic prompt. InAAAI, Vol. 39. 8150–8158
2025
-
[32]
Yuhao Wang, Yongfeng Lv, Pingping Zhang, and Huchuan Lu. 2025. IDEA: Inverted text with cooperative deformable aggregation for multi-modal object re-identification. InCVPR. 29701–29710
2025
-
[33]
Yuhao Wang, Yongfeng Lv, Pingping Zhang, and Huchuan Lu. 2025. Idea: In- verted text with cooperative deformable aggregation for multi-modal object re-identification. InCVPR. 29701–29710
2025
-
[34]
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, Xiangnan Fang, Zewen He, Zhenbo Luo, Wenxuan Wang, Junqi Lin, Jian Luan, and Qin Jin. 2025. Time-R1: Post- Training Large Vision Language Model for Temporal Video Grounding. InNIPS. https://openreview.net/forum?id=gJ05Gm5VxQ
2025
-
[35]
Longhui Wei, Shiliang Zhang, Wen Gao, and Qi Tian. 2018. Person transfer gan to bridge domain gap for person re-identification. InCVPR. 79–88
2018
-
[36]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. 2025. Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence. InNIPS. https: //openreview.net/forum?id=RnXS7aK4rK
2025
-
[37]
Wenyi Xiao and Leilei Gan. 2025. Fast-Slow Thinking GRPO for Large Vision-Language Model Reasoning. InNIPS. https://openreview.net/forum? id=MI1uT5rReV
2025
-
[38]
Kunlun Xu, Zichen Liu, Xu Zou, Yuxin Peng, and Jiahuan Zhou. 2025. Long Short-Term Knowledge Decomposition and Consolidation for Lifelong Person Re-Identification.IEEE TPAMI47, 9 (2025), 7796–7811
2025
-
[39]
Jinxi Yang, He Li, Bo Du, and Mang Ye. 2025. Cheb-GR: Rethinking K-nearest Neighbor Search in Re-ranking for Person Re-identification. InCVPR. 19261– 19270
2025
-
[40]
Qize Yang, Ancong Wu, and Wei-Shi Zheng. 2021. Person Re-Identification by Contour Sketch Under Moderate Clothing Change.IEEE TPAMI43, 6 (2021), 2029–2046
2021
-
[41]
Zexian Yang, Dayan Wu, Chenming Wu, Zheng Lin, Jingzi Gu, and Weiping Wang. 2024. A pedestrian is worth one prompt: Towards language guidance person re-identification. InCVPR. 17343–17353
2024
-
[42]
Mang Ye, Jianbing Shen, Gaojie Lin, Tao Xiang, Ling Shao, and Steven C. H. Hoi
-
[43]
Deep Learning for Person Re-Identification: A Survey and Outlook.IEEE TPAMI44, 6 (2022), 2872–2893
2022
-
[44]
Chenyang Yu, Xuehu Liu, Jiawen Zhu, Yuhao Wang, Pingping Zhang, and Huchuan Lu. 2025. Climb-ReID: A hybrid clip-mamba framework for person re-identification. InAAAI, Vol. 39. 9589–9597
2025
- [45]
-
[46]
Ye Yuan, Wuyang Chen, Yang Yang, and Zhangyang Wang. 2020. In defense of the triplet loss again: Learning robust person re-identification with fast approximated triplet loss and label distillation. InCVPR Workshops. 354–355
2020
-
[47]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid loss for language image pre-training. InCVPR. 11975–11986
2023
- [48]
- [49]
-
[50]
Quan Zhang, Jianhuang Lai, Zhanxiang Feng, and Xiaohua Xie. 2022. Seeing Like a Human: Asynchronous Learning With Dynamic Progressive Refinement for Person Re-Identification.IEEE TIP31 (2022), 352–365
2022
-
[51]
Quan Zhang, Jianhuang Lai, Zhanxiang Feng, and Xiaohua Xie. 2024. Uncertainty modeling for group re-identification.IJCV132, 8 (2024), 3046–3066
2024
-
[52]
Quan Zhang, Jianhuang Lai, Xiaohua Xie, Xiaofeng Jin, and Sien Huang. 2024. Separable Spatial-Temporal Residual Graph for Cloth-Changing Group Re- Identification.IEEE TPAMI46, 8 (2024), 5791–5805. , , Quan Zhang, Jingze Wu, Jialong Wang, Xiaohua Xie, Jianhuang Lai, and Hongbo Chen
2024
-
[53]
Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, Xin Jin, and Zhibo Chen. 2020. Relation-aware global attention for person re-identification. InCVPR. 3186–3195
2020
-
[54]
Yuxuan Zhao, Weijian Ruan, He Li, and Mang Ye. 2025. NightReID: A Large-Scale Nighttime Person Re-Identification Benchmark. InAAAI, Vol. 39. 10519–10527
2025
- [55]
- [56]
-
[57]
Liang Zheng, Hengheng Zhang, Shaoyan Sun, Manmohan Chandraker, Yi Yang, and Qi Tian. 2017. Person re-identification in the wild. InCVPR. 1367–1376
2017
-
[58]
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. 2025. R1-Zero’s" Aha Moment" in Visual Reasoning on a 2B Non-SFT Model.arXiv preprint arXiv:2503.05132(2025)
-
[59]
Jiahuan Zhou, Kunlun Xu, Fan Zhuo, Xu Zou, and Yuxin Peng. 2025. Distribution- Aware Knowledge Aligning and Prototyping for Non-Exemplar Lifelong Person Re-Identification.IEEE TPAMI47, 12 (2025), 10932–10948
2025
-
[60]
Kuan Zhu, Haiyun Guo, Tianyi Yan, Yousong Zhu, Jinqiao Wang, and Ming Tang
-
[61]
Pass: Part-aware self-supervised pre-training for person re-identification. InECCV. Springer, 198–214
-
[62]
Jialong Zuo, Yongtai Deng, Mengdan Tan, Rui Jin, Dongyue Wu, Nong Sang, Liang Pan, and Changxin Gao. 2025. ReID5o: Achieving Omni Multi-modal Person Re-identification in a Single Model. (2025), 1–24
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.