Recognition: unknown
Allo{SR}²: Rectifying One-Step Super-Resolution to Stay Real via Allomorphic Generative Flows
Pith reviewed 2026-05-10 03:38 UTC · model grok-4.3
The pith
Allo{SR}^2 rectifies one-step super-resolution trajectories using allomorphic generative flows to avoid prior collapse and trajectory drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
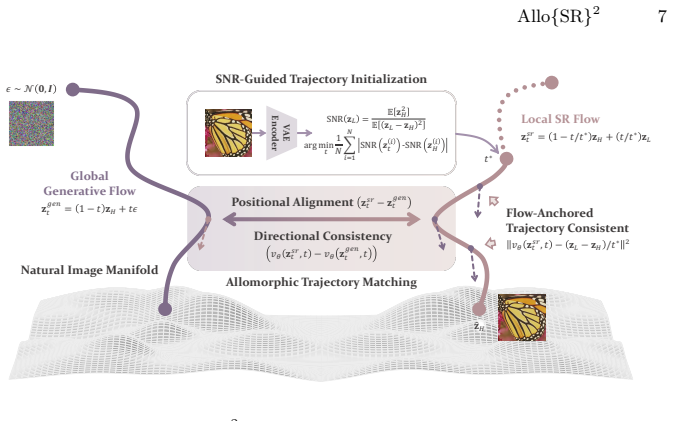
The central claim is that one-step real-world super-resolution can be performed by treating the process as an allomorphic generative flow that shares the same underlying vector field as a pre-trained generative flow model. This is achieved by initializing the trajectory at an SNR-aligned timestep so the starting degradation matches the pre-trained model's anchoring point, by applying Flow-Anchored Trajectory Consistency to supervise velocities at intermediate states and keep the path curvature-free, and by using Allomorphic Trajectory Matching to minimize the distributional gap between the super-resolution flow and the generative flow through a self-adversarial alignment in the unified field
What carries the argument
Allomorphic generative flows, a construction that aligns the super-resolution trajectory with a pre-trained generative flow through SNR-guided initialization, velocity-level consistency supervision, and distributional trajectory matching in a shared vector field.
If this is right
- One-step inference becomes practical for real-world super-resolution while preserving both pixel-level fidelity and generative detail richness.
- The framework achieves leading results on standard synthetic and real-world super-resolution test sets without multi-step refinement.
- Computational cost stays low enough for applications that require near real-time processing.
- Prior collapse is avoided even when the pre-trained model is adapted only to small paired datasets.
Where Pith is reading between the lines
- The same trajectory-alignment idea could be tested on other single-pass generative tasks such as image denoising or inpainting where drift from pre-trained priors is also common.
- If the allomorphic matching proves stable, it may allow domain adaptation of large flow models using far fewer paired examples than currently required.
- The approach points toward checking whether similar rectification can maintain consistency when extending one-step generation to video sequences.
Load-bearing premise
The assumption that SNR-guided initialization, flow-anchored velocity supervision, and allomorphic distributional alignment will together prevent prior collapse and trajectory drift on limited LR-HR data without introducing new instabilities or needing heavy retuning.
What would settle it
Running the method on a new collection of real-world low-resolution images and finding that the outputs contain more visible artifacts or lower perceptual realism scores than a multi-step baseline would show the rectification does not hold.
Figures



read the original abstract
Real-world image super-resolution (Real-SR) has been revolutionized by leveraging the powerful generative priors of large-scale diffusion and flow-based models. However, fine-tuning these models on limited LR-HR pairs often precipitates "prior collapse" that the model sacrifices its inherent generative richness to overfit specific training degradations. This issue is further exacerbated in one-step generation, where the absence of multi-step refinement leads to significant trajectory drift and artifact generation. In this paper, we propose Allo{SR}$^2$, a novel framework that rectifies one-step SR trajectories via allomorphic generative flows to maintain high-fidelity generative realism. Specifically, we utilize Signal-to-Noise Ratio (SNR) Guided Trajectory Initialization to establish a physically grounded starting state by aligning the degradation level of LR latent features with the optimal anchoring timestep of the pre-trained flow. To ensure a stable, curvature-free path for one-step inference, we propose Flow-Anchored Trajectory Consistency (FATC), which enforces velocity-level supervision across intermediate states. Furthermore, we develop Allomorphic Trajectory Matching (ATM), a self-adversarial alignment strategy that minimizes the distributional discrepancy between the SR flow and the generative flow in a unified vector field. Extensive experiments on both synthetic and real-world benchmarks demonstrate that Allo{SR}$^2$ achieves state-of-the-art performance in one-step Real-SR, offering a superior balance between restoration fidelity and generative realism while maintaining extreme efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Allo{SR}^2, a framework for one-step real-world super-resolution that rectifies trajectories in generative flows to avoid prior collapse and drift. It uses SNR-guided initialization to match LR degradation to flow timesteps, FATC for enforcing consistent velocity in one-step paths, and ATM for self-adversarial matching of distributions in a shared vector field. Experiments on synthetic and real benchmarks are said to show SOTA performance balancing fidelity and realism with high efficiency.
Significance. This work could be significant if validated, as one-step Real-SR is important for practical applications. By building on pre-trained flows and adding targeted supervision without full retraining, it offers a way to maintain generative capabilities while adapting to real degradations. The efficiency of one-step inference is a strong point, and the approach may generalize to other generative tasks.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Allo{SR}^2 and the recommendation for minor revision. The feedback highlights the practical importance of one-step Real-SR and the efficiency of our approach, which aligns with our goals.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core claims rest on three explicitly proposed mechanisms—SNR-guided trajectory initialization to align LR latents with a pre-trained flow's anchoring timestep, FATC for velocity-level supervision enforcing curvature-free paths, and ATM for self-adversarial distributional matching in a unified vector field—introduced to mitigate prior collapse and trajectory drift in one-step inference. These are defined functionally and independently on top of existing pre-trained models rather than by construction from fitted parameters, self-referential equations, or load-bearing self-citations. No equations reduce the claimed SOTA balance of fidelity and realism to the inputs themselves, and the approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Agustsson, E., Timofte, R.: Ntire 2017 challenge on single image super-resolution: Dataset and study. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 126–135 (2017)
2017
-
[2]
Ad- vances in Neural Information Processing Systems37, 55443–55469 (2024)
Ai, Y., Zhou, X., Huang, H., Han, X., Chen, Z., You, Q., Yang, H.: Dreamclear: High-capacity real-world image restoration with privacy-safe dataset curation. Ad- vances in Neural Information Processing Systems37, 55443–55469 (2024)
2024
-
[3]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Albergo,M.S.,Boffi,N.M.,Vanden-Eijnden,E.:Stochasticinterpolants:Aunifying framework for flows and diffusions, 2023. URL https://arxiv. org/abs/2303.08797 3, 1 (2023)
work page internal anchor Pith review arXiv 2023
-
[4]
Building Normalizing Flows with Stochastic Interpolants
Albergo, M.S., Vanden-Eijnden, E.: Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571 (2022)
work page internal anchor Pith review arXiv 2022
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cai, J., Zeng, H., Yong, H., Cao, Z., Zhang, L.: Toward real-world single im- age super-resolution: A new benchmark and a new model. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3086–3095 (2019)
2019
-
[6]
Cheng, Z., Sun, P., Li, J., Lin, T.: Twinflow: Realizing one-step generation on large models with self-adversarial flows. arXiv preprint arXiv:2512.05150 (2025)
-
[7]
(No Title) (2014)
Diederik, K.: Adam: A method for stochastic optimization. (No Title) (2014)
2014
-
[8]
IEEE transactions on pattern analysis and machine intelligence44(5), 2567–2581 (2020)
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unify- ing structure and texture similarity. IEEE transactions on pattern analysis and machine intelligence44(5), 2567–2581 (2020)
2020
-
[9]
In: European conference on computer vision
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: European conference on computer vision. pp. 184–199. Springer (2014)
2014
-
[10]
IEEE transactions on pattern analysis and machine intelligence 38(2), 295–307 (2015)
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convo- lutional networks. IEEE transactions on pattern analysis and machine intelligence 38(2), 295–307 (2015)
2015
-
[11]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Dong, L., Fan, Q., Guo, Y., Wang, Z., Zhang, Q., Chen, J., Luo, Y., Zou, C.: Tsd-sr: One-step diffusion with target score distillation for real-world image super- resolution. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 23174–23184 (2025)
2025
-
[12]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[13]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[14]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[15]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019)
2019
-
[17]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ke, J., Wang, Q., Wang, Y., Milanfar, P., Yang, F.: Musiq: Multi-scale image quality transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5148–5157 (2021)
2021
-
[18]
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, March 2024
Kim, D., Lai, C.H., Liao, W.H., Murata, N., Takida, Y., Uesaka, T., He, Y., Mitsu- fuji, Y., Ermon, S.: Consistency trajectory models: Learning probability flow ode trajectory of diffusion. arXiv preprint arXiv:2310.02279 (2023) 16 Z. Wang et al
-
[19]
Labs, B.F.: Flux.https://github.com/black- forest- labs/flux(2024), ac- cessed: 2024-11-14
2024
-
[20]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., et al.: Photo-realistic single image super- resolution using a generative adversarial network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4681–4690 (2017)
2017
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Y., Zhang, K., Liang, J., Cao, J., Liu, C., Gong, R., Zhang, Y., Tang, H., Liu, Y., Demandolx, D., et al.: Lsdir: A large scale dataset for image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1775–1787 (2023)
2023
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liang, J., Zeng, H., Zhang, L.: Details or artifacts: A locally discriminative learning approach to realistic image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5657–5666 (2022)
2022
-
[23]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1833–1844 (2021)
2021
-
[24]
In: European conference on computer vision
Lin, X., He, J., Chen, Z., Lyu, Z., Dai, B., Yu, F., Qiao, Y., Ouyang, W., Dong, C.: Diffbir: Toward blind image restoration with generative diffusion prior. In: European conference on computer vision. pp. 430–448. Springer (2024)
2024
-
[25]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review arXiv 2022
-
[27]
In: The Twelfth Interna- tional Conference on Learning Representations (2023)
Liu, X., Zhang, X., Ma, J., Peng, J., et al.: Instaflow: One step is enough for high-quality diffusion-based text-to-image generation. In: The Twelfth Interna- tional Conference on Learning Representations (2023)
2023
-
[28]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency mod- els: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023)
work page internal anchor Pith review arXiv 2023
-
[29]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Meng, C., Rombach, R., Gao, R., Kingma, D., Ermon, S., Ho, J., Salimans, T.: On distillation of guided diffusion models. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 14297–14306 (2023)
2023
-
[30]
In: International conference on machine learning
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: International conference on machine learning. pp. 8162–8171. PMLR (2021)
2021
-
[31]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[33]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512 (2022)
work page internal anchor Pith review arXiv 2022
-
[34]
In: Proceed- ings of the 40th International Conference on Machine Learning
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: Proceed- ings of the 40th International Conference on Machine Learning. pp. 32211–32252 (2023)
2023
-
[35]
Advances in neural information processing systems32(2019)
Song, Y., Ermon, S.: Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems32(2019)
2019
-
[36]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) Allo{SR}2 17
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sun,L.,Wu,R.,Ma,Z.,Liu,S.,Yi,Q.,Zhang,L.:Pixel-levelandsemantic-levelad- justable super-resolution: A dual-lora approach. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2333–2343 (2025)
2025
-
[38]
In: Proceedings of the AAAI conference on artificial intelligence
Wang, J., Chan, K.C., Loy, C.C.: Exploring clip for assessing the look and feel of images. In: Proceedings of the AAAI conference on artificial intelligence. vol. 37, pp. 2555–2563 (2023)
2023
-
[39]
International Journal of Computer Vision 132(12), 5929–5949 (2024)
Wang, J., Yue, Z., Zhou, S., Chan, K.C., Loy, C.C.: Exploiting diffusion prior for real-world image super-resolution. International Journal of Computer Vision 132(12), 5929–5949 (2024)
2024
-
[40]
In: Proceedings of the IEEE/CVF in- ternational conference on computer vision
Wang, X., Xie, L., Dong, C., Shan, Y.: Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In: Proceedings of the IEEE/CVF in- ternational conference on computer vision. pp. 1905–1914 (2021)
1905
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, X., Yu, K., Dong, C., Tang, X., Loy, C.C.: Deep network interpolation for continuous imagery effect transition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1692–1701 (2019)
2019
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Y., Yang, W., Chen, X., Wang, Y., Guo, L., Chau, L.P., Liu, Z., Qiao, Y., Kot, A.C., Wen, B.: Sinsr: diffusion-based image super-resolution in a single step. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 25796–25805 (2024)
2024
-
[43]
Advances in neural information processing systems36, 8406–8441 (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems36, 8406–8441 (2023)
2023
-
[44]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[45]
In: European conference on computer vision
Wei, P., Xie, Z., Lu, H., Zhan, Z., Ye, Q., Zuo, W., Lin, L.: Component divide- and-conquer for real-world image super-resolution. In: European conference on computer vision. pp. 101–117. Springer (2020)
2020
-
[46]
Advances in Neural Information Processing Systems 37, 92529–92553 (2024)
Wu, R., Sun, L., Ma, Z., Zhang, L.: One-step effective diffusion network for real- world image super-resolution. Advances in Neural Information Processing Systems 37, 92529–92553 (2024)
2024
-
[47]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Wu, R., Yang, T., Sun, L., Zhang, Z., Li, S., Zhang, L.: Seesr: Towards semantics- aware real-world image super-resolution. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 25456–25467 (2024)
2024
-
[48]
arXiv preprint arXiv:2508.08227 (2025)
Wu, Z., Sun, Z., Zhou, T., Fu, B., Cong, J., Dong, Y., Zhang, H., Tang, X., Chen, M., Wei, X.: Omgsr: You only need one mid-timestep guidance for real-world image super-resolution. arXiv preprint arXiv:2508.08227 (2025)
-
[49]
arXiv preprint arXiv:2307.02457 (2023)
Xie, L., Wang, X., Chen, X., Li, G., Shan, Y., Zhou, J., Dong, C.: Desra: detect and delete the artifacts of gan-based real-world super-resolution models. arXiv preprint arXiv:2307.02457 (2023)
-
[50]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xu, J., Li, W., Sun, H., Li, F., Wang, Z., Peng, L., Ren, J., Yang, H., Hu, X., Pei, R., et al.: Fast image super-resolution via consistency rectified flow. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11755–11765 (2025)
2025
-
[51]
arXiv preprint arXiv:2407.02398 , year=
Yang, L., Zhang, Z., Zhang, Z., Liu, X., Xu, M., Zhang, W., Meng, C., Ermon, S., Cui, B.: Consistency flow matching: Defining straight flows with velocity consis- tency. arXiv preprint arXiv:2407.02398 (2024)
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Yang, S., Wu, T., Shi, S., Lao, S., Gong, Y., Cao, M., Wang, J., Yang, Y.: Maniqa: Multi-dimension attention network for no-reference image quality assessment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 1191–1200 (2022) 18 Z. Wang et al
2022
-
[53]
In: European conference on computer vision
Yang, T., Wu, R., Ren, P., Xie, X., Zhang, L.: Pixel-aware stable diffusion for real- istic image super-resolution and personalized stylization. In: European conference on computer vision. pp. 74–91. Springer (2024)
2024
-
[54]
Advances in neural information processing systems37, 47455–47487 (2024)
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024)
2024
-
[55]
One-step diffusion with distribution matching distillation.arXiv preprint arXiv:2311.18828, 2023
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation, 2024. URL https://arxiv. org/abs/2311.18828
-
[56]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
You, W., Zhang, M., Zhang, L., Zhou, X., Shi, K., Gu, S.: Consistency trajec- tory matching for one-step generative super-resolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12747–12756 (2025)
2025
-
[57]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu,F.,Gu,J.,Li,Z.,Hu,J.,Kong,X.,Wang,X.,He,J.,Qiao,Y.,Dong,C.:Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 25669–25680 (2024)
2024
-
[58]
Advances in neural information processing systems 36, 13294–13307 (2023)
Yue, Z., Wang, J., Loy, C.C.: Resshift: Efficient diffusion model for image super- resolution by residual shifting. Advances in neural information processing systems 36, 13294–13307 (2023)
2023
-
[59]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, K., Liang, J., Van Gool, L., Timofte, R.: Designing a practical degradation model for deep blind image super-resolution. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4791–4800 (2021)
2021
-
[60]
In: Proceedings of the Computer Vision and Pat- tern Recognition Conference
Zhang, L., You, W., Shi, K., Gu, S.: Uncertainty-guided perturbation for image super-resolution diffusion model. In: Proceedings of the Computer Vision and Pat- tern Recognition Conference. pp. 17980–17989 (2025)
2025
-
[61]
IEEE Transactions on Image Processing24(8), 2579–2591 (2015)
Zhang, L., Zhang, L., Bovik, A.C.: A feature-enriched completely blind image qual- ity evaluator. IEEE Transactions on Image Processing24(8), 2579–2591 (2015)
2015
-
[62]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[63]
In: European Conference on Computer Vision
Zhang, Y., Ji, B., Hao, J., Yao, A.: Perception-distortion balanced admm opti- mization for single-image super-resolution. In: European Conference on Computer Vision. pp. 108–125. Springer (2022)
2022
-
[64]
In: Proceedings of the IEEE interna- tional conference on computer vision
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 2223–2232 (2017) Allo{SR}2 19 A Algorithm of Allo{SR} 2 The pseudo-code of Allo{SR}2 training Scheme is summarized as Algorithm 1. Algorithm 1Training S...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.