Recognition: unknown
Understanding the Mechanism of Altruism in Large Language Models
Pith reviewed 2026-05-10 01:31 UTC · model grok-4.3
The pith
A small set of sparse autoencoder features encodes altruism in large language models and can be steered to change allocation behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
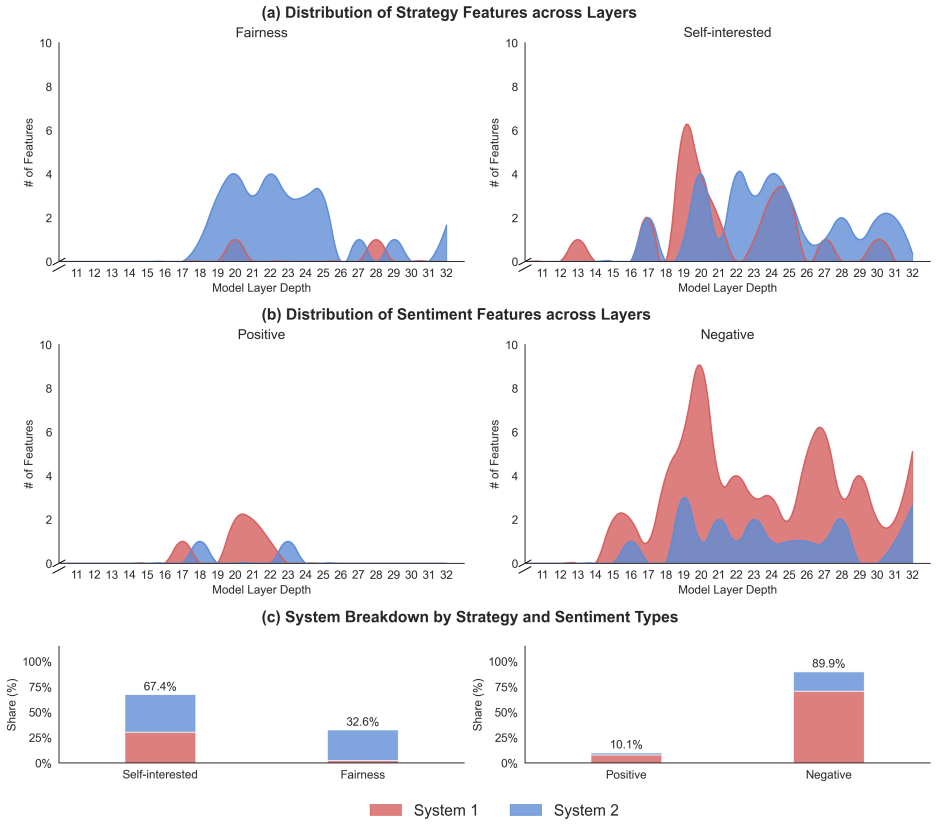
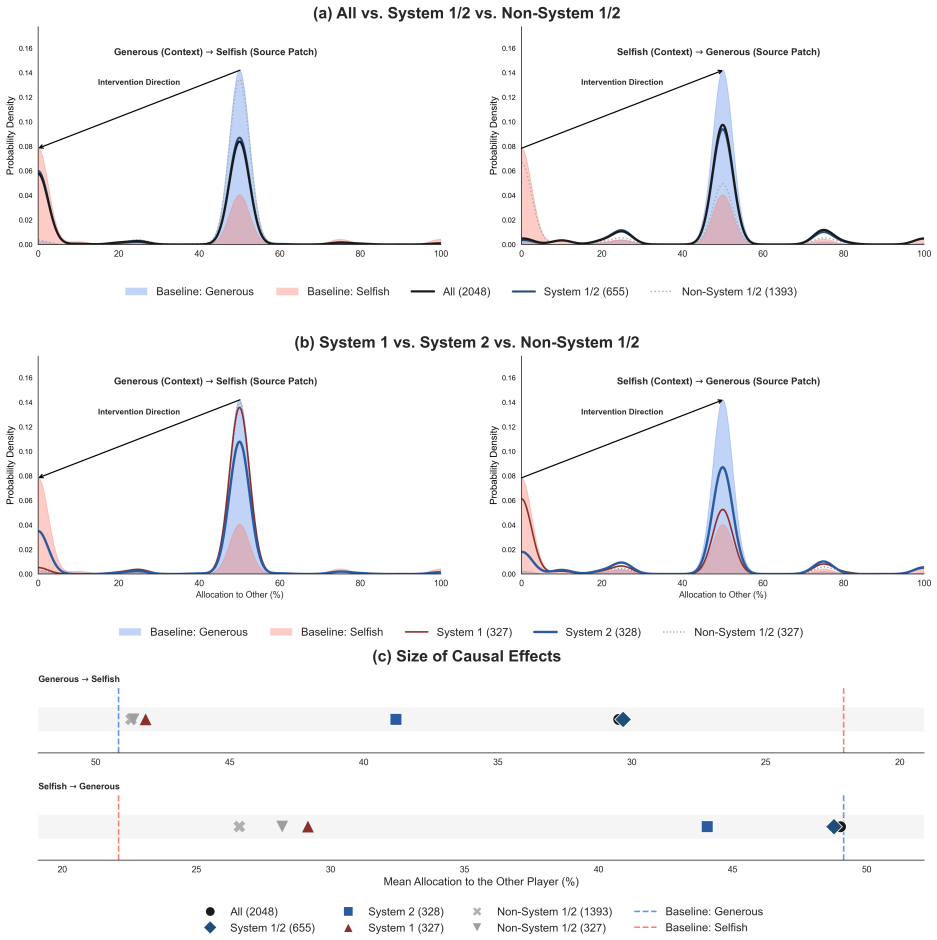
Minimal-pair prompts that differ only in social stance induce economically meaningful allocation shifts; a sparse set of SAE features (0.024 percent of total) activates in correspondence with this shift; activation patching and continuous steering of the identified feature direction reliably alter allocations, with System 2 features exerting more proximal control than System 1 features; the same steering direction generalizes across multiple social-preference games.
What carries the argument
Sparse autoencoder features whose activations distinguish generous from selfish prompts, classified as heuristic (System 1) or deliberative (System 2) via benchmark tasks and then subjected to causal interventions.
If this is right
- Steering the identified feature direction generalizes across multiple social-preference games beyond the Dictator Game.
- System 2 features exert a more proximal influence on the model's final output than System 1 features.
- The results supply a concrete mapping from altruistic behavior to identifiable network states that can be used for targeted alignment.
Where Pith is reading between the lines
- Similar contrast-and-steer methods could be applied to locate internal representations of other social preferences such as fairness or reciprocity.
- Feature-level editing might allow value alignment adjustments without full model retraining.
- The distinction between System 1 and System 2 features suggests LLMs may internally simulate both fast heuristic and slow deliberative routes when making social decisions.
Load-bearing premise
The prompts that differ only in social stance isolate the altruism mechanism without introducing other internal confounds, and the benchmark tasks correctly classify the features as heuristic versus deliberative.
What would settle it
If activation patching or continuous steering of the candidate features produces no measurable shift in Dictator Game allocations, or if the features activate identically under generous and selfish prompts, the claimed causal role would be falsified.
Figures





read the original abstract
Altruism is fundamental to human societies, fostering cooperation and social cohesion. Recent studies suggest that large language models (LLMs) can display human-like prosocial behavior, but the internal computations that produce such behavior remain poorly understood. We investigate the mechanisms underlying LLM altruism using sparse autoencoders (SAEs). In a standard Dictator Game, minimal-pair prompts that differ only in social stance (generous versus selfish) induce large, economically meaningful shifts in allocations. Leveraging this contrast, we identify a set of SAE features (0.024% of all features across the model's layers) whose activations are strongly associated with the behavioral shift. To interpret these features, we use benchmark tasks motivated by dual-process theories to classify a subset as primarily heuristic (System 1) or primarily deliberative (System 2). Causal interventions validate their functional role: activation patching and continuous steering of this feature direction reliably shift allocation distributions, with System 2 features exerting a more proximal influence on the model's final output than System 1 features. The same steering direction generalizes across multiple social-preference games. Together, these results enhance our understanding of artificial cognition by translating altruistic behaviors into identifiable network states and provide a framework for aligning LLM behavior with human values, thereby informing more transparent and value-aligned deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sparse autoencoders can identify a small set (0.024%) of features in LLMs whose activations correlate with altruism in the Dictator Game, identified via minimal-pair prompts contrasting generous vs. selfish social stances. A subset is classified as System 1 (heuristic) or System 2 (deliberative) using dual-process benchmark tasks. Causal validation via activation patching and continuous steering shows these features shift allocation distributions, with System 2 features having more proximal influence on outputs, and the steering generalizes across other social-preference games.
Significance. If the causal claims hold after addressing confounds, the work would provide a mechanistic, feature-level account of prosocial behavior in LLMs, linking it to dual-process distinctions and enabling targeted interventions for alignment. The empirical focus on patching, steering, and cross-game generalization is a strength, offering falsifiable tests rather than purely correlational evidence.
major comments (3)
- [Methods (prompt construction and feature selection)] The central claim that minimal-pair prompts isolate the altruism mechanism rests on the assumption that generous vs. selfish stance prompts differ only in social content without altering prompt length, token distributions, or implied context that could engage unrelated circuits. This is load-bearing for interpreting the selected SAE features as the mechanism rather than downstream correlates, and for the causal interpretation of patching/steering results.
- [Feature interpretation and classification] Classification of SAE features as primarily System 1 (heuristic) or System 2 (deliberative) relies on benchmark tasks motivated by dual-process theories, but the paper provides no validation that these features implement heuristic vs. deliberative computations inside the model rather than merely correlating with surface behavior on the benchmarks. This directly affects the claim that System 2 features exert more proximal influence.
- [Results (interventions and generalization)] The manuscript lacks detail on statistical controls (e.g., multiple-testing correction across features), baseline comparisons (e.g., random or non-altruism-related features), and exact model/layer specifications, which limits evaluation of whether the reported allocation shifts and proximal influence differences are robust.
minor comments (1)
- [Abstract and Methods] The abstract and methods should explicitly state the base LLM, SAE training details, and number of layers/features examined to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript accordingly to improve methodological transparency and interpretive clarity.
read point-by-point responses
-
Referee: [Methods (prompt construction and feature selection)] The central claim that minimal-pair prompts isolate the altruism mechanism rests on the assumption that generous vs. selfish stance prompts differ only in social content without altering prompt length, token distributions, or implied context that could engage unrelated circuits. This is load-bearing for interpreting the selected SAE features as the mechanism rather than downstream correlates, and for the causal interpretation of patching/steering results.
Authors: We agree that prompt construction details are critical for causal attribution. The minimal-pair prompts were designed to hold all non-stances elements fixed (identical sentence structure, length, and preceding context), differing solely in the social stance phrase. In the revision we have added a dedicated subsection on prompt construction that reports: (i) exact token-length statistics showing no systematic difference, (ii) token-distribution overlap metrics, and (iii) the complete set of prompt pairs in the appendix. These additions directly support the claim that the selected SAE features track the altruism-relevant computation rather than extraneous prompt features. revision: yes
-
Referee: [Feature interpretation and classification] Classification of SAE features as primarily System 1 (heuristic) or System 2 (deliberative) relies on benchmark tasks motivated by dual-process theories, but the paper provides no validation that these features implement heuristic vs. deliberative computations inside the model rather than merely correlating with surface behavior on the benchmarks. This directly affects the claim that System 2 features exert more proximal influence.
Authors: We accept that the System 1/2 labels are behavioral classifications derived from activation correlations on established dual-process benchmarks rather than direct circuit-level proof of heuristic versus deliberative algorithms. The proximal-influence claim, however, rests on the independent causal evidence from activation patching, which shows larger output shifts when System 2 features are intervened upon. In the revised manuscript we have (a) clarified the language to describe the labels as “benchmark-derived” rather than “mechanistically verified,” (b) added a limitations paragraph acknowledging the correlational nature of the classification, and (c) emphasized that the differential proximal effects are measured directly via patching, independent of the label interpretation. revision: partial
-
Referee: [Results (interventions and generalization)] The manuscript lacks detail on statistical controls (e.g., multiple-testing correction across features), baseline comparisons (e.g., random or non-altruism-related features), and exact model/layer specifications, which limits evaluation of whether the reported allocation shifts and proximal influence differences are robust.
Authors: We have expanded the Results and Methods sections to include the requested details: Bonferroni correction for multiple comparisons across the tested features, baseline experiments with randomly sampled SAE features and with features previously identified as unrelated to social preferences (showing null effects), and precise model/layer specifications (Llama-3-8B, layers 8–24 for the SAE, 12 altruism-related features). These additions confirm that the reported allocation shifts and proximal-influence differences are statistically robust and specific to the identified features. revision: yes
Circularity Check
No circularity: results rest on independent causal interventions and generalization tests.
full rationale
The paper's central claims derive from empirical steps—minimal-pair prompt contrasts to surface SAE features, dual-process benchmark classification, activation patching, continuous steering, and cross-game generalization—none of which reduce by construction to fitted parameters, self-definitions, or self-citation chains. Feature selection uses observable allocation shifts; interventions then test functional causality separately; no equations or uniqueness theorems are invoked that loop back to the inputs. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dual-process theories of cognition distinguish heuristic (System 1) from deliberative (System 2) processing
Reference graph
Works this paper leans on
-
[1]
author Trivers, R. L. title The evolution of reciprocal altruism . journal Quarterly Review of Biology volume 46 , pages 35--57 ( year 1971 )
1971
-
[2]
& author Hamilton, W
author Axelrod, R. & author Hamilton, W. D. title The evolution of cooperation . journal Science volume 211 , pages 1390--1396 ( year 1981 )
1981
-
[3]
& author Fischbacher, U
author Fehr, E. & author Fischbacher, U. title The nature of human altruism . journal Nature volume 425 , pages 785--791 ( year 2003 )
2003
-
[4]
author Nowak, M. A. title Five rules for the evolution of cooperation . journal Science volume 314 , pages 1560--1563 ( year 2006 )
2006
-
[5]
author Awad, E. et al. title The moral machine experiment . journal Nature volume 563 , pages 59--64 ( year 2018 )
2018
-
[6]
author Binz, M. et al. title A foundation model to predict and capture human cognition . journal Nature volume 644 , pages 1002--1009 ( year 2025 )
2025
-
[7]
author Brosnan, S. F. & author De Waal, F. B. title Monkeys reject unequal pay . journal Nature volume 425 , pages 297--299 ( year 2003 )
2003
-
[8]
author Harbaugh, W. T. , author Mayr, U. & author Burghart, D. R. title Neural responses to taxation and voluntary giving reveal motives for charitable donations . journal Science volume 316 , pages 1622--1625 ( year 2007 )
2007
-
[9]
author Henrich, J. et al. title Markets, religion, community size, and the evolution of fairness and punishment . journal Science volume 327 , pages 1480--1484 ( year 2010 )
2010
-
[10]
, author Rangel, A
author Tricomi, E. , author Rangel, A. , author Camerer, C. F. & author O’Doherty, J. P. title Neural evidence for inequality-averse social preferences . journal Nature volume 463 , pages 1089--1091 ( year 2010 )
2010
-
[11]
, author Jakiela, P
author Fisman, R. , author Jakiela, P. , author Kariv, S. & author Markovits, D. title The distributional preferences of an elite . journal Science volume 349 , pages aab0096 ( year 2015 )
2015
-
[12]
author Sáez, I. et al. title Dopamine modulates egalitarian behavior in humans . journal Current Biology volume 25 , pages 912--919 ( year 2015 )
2015
-
[13]
& author Mitchell, T
author Brynjolfsson, E. & author Mitchell, T. title What can machine learning do? W orkforce implications . journal Science volume 358 , pages 1530--1534 ( year 2017 )
2017
-
[14]
author Brinkmann, L. et al. title Machine culture . journal Nature Human Behaviour volume 7 , pages 1855--1868 ( year 2023 )
2023
-
[15]
& author Zhang, W
author Noy, S. & author Zhang, W. title Experimental evidence on the productivity effects of generative artificial intelligence . journal Science volume 381 , pages 187--192 ( year 2023 )
2023
-
[16]
author Burton, J. W. et al. title How large language models can reshape collective intelligence . journal Nature Human Behaviour volume 8 , pages 1643--1655 ( year 2024 )
2024
-
[17]
, author Li, D
author Brynjolfsson, E. , author Li, D. & author Raymond, L. title Generative AI at work . journal Quarterly Journal of Economics volume 140 , pages 889--942 ( year 2025 )
2025
-
[18]
author K \"o bis, N. et al. title Delegation to artificial intelligence can increase dishonest behaviour . journal Nature volume 646 , pages 126--134 ( year 2025 )
2025
-
[19]
, author Liu, T
author Chen, Y. , author Liu, T. X. , author Shan, Y. & author Zhong, S. title The emergence of economic rationality of GPT . journal Proceedings of the National Academy of Sciences volume 120 , pages e2316205120 ( year 2023 )
2023
-
[20]
, author Xie, Y
author Mei, Q. , author Xie, Y. , author Yuan, W. & author Jackson, M. O. title A T uring test of whether AI chatbots are behaviorally similar to humans . journal Proceedings of the National Academy of Sciences volume 121 , pages e2313925121 ( year 2024 )
2024
-
[21]
author Akata, E. et al. title Playing repeated games with large language models . journal Nature Human Behaviour pages 1--11 ( year 2025 )
2025
-
[22]
& author Obradovich, N
author Johnson, T. & author Obradovich, N. title Testing for completions that simulate altruism in early language models . journal Nature Human Behaviour volume 9 , pages 1861--1870 ( year 2025 )
2025
-
[23]
, author Mei, Q
author Xie, Y. , author Mei, Q. , author Yuan, W. & author Jackson, M. O. title Using large language models to categorize strategic situations and decipher motivations behind human behaviors . journal Proceedings of the National Academy of Sciences volume 122 , pages e2512075122 ( year 2025 )
2025
-
[25]
author Bender, E. M. , author Gebru, T. , author McMillan-Major, A. & author Shmitchell, S. title On the dangers of stochastic parrots: Can language models be too big? howpublished Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2021) ( year 2021 )
2021
-
[26]
author Haas, J. et al. title A roadmap for evaluating moral competence in large language models . journal Nature volume 650 , pages 565--573 ( year 2026 )
2026
-
[27]
author Elhage, N. et al. title Toy models of superposition . journal Transformer Circuits Thread ( year 2022 ). ://transformer-circuits.pub/2022/toy\_model/index.html
2022
-
[28]
author Bricken, T. et al. title Towards monosemanticity: Decomposing language models with dictionary learning . journal Transformer Circuits Thread ( year 2023 ). ://transformer-circuits.pub/2023/monosemantic-features/index.html
2023
-
[29]
author Olah, C. et al. title Zoom in: An introduction to circuits . journal Distill volume 5 , pages e00024--001 ( year 2020 )
2020
-
[30]
, author Cunningham, H
author Huben, R. , author Cunningham, H. , author Smith, L. R. , author Ewart, A. & author Sharkey, L. title Sparse autoencoders find highly interpretable features in language models . howpublished The Eleventh International Conference on Learning Representations (ICLR 2023) ( year 2023 )
2023
-
[31]
author Wang, K. R. , author Variengien, A. , author Conmy, A. , author Shlegeris, B. & author Steinhardt, J. title Interpretability in the wild: A circuit for indirect object identification in GPT-2 small . howpublished The Eleventh International Conference on Learning Representations (ICLR 2023) ( year 2023 )
2023
-
[32]
& author Tegmark, M
author Gurnee, W. & author Tegmark, M. title Language models represent space and time . howpublished The Twelfth International Conference on Learning Representations (ICLR 2024) ( year 2024 )
2024
-
[33]
author Templeton, A. et al. title Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet . journal Transformer Circuits Thread ( year 2024 ). ://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
2024
-
[34]
author Chen, H. , author Didisheim, A. , author Somoza, L. & author Tian, H. title A financial brain scan of the LLM . journal arXiv preprint arXiv:2508.21285 ( year 2025 )
-
[35]
, author Horowitz, J
author Forsythe, R. , author Horowitz, J. L. , author Savin, N. E. & author Sefton, M. title Fairness in simple bargaining experiments . journal Games and Economic Behavior volume 6 , pages 347--369 ( year 1994 )
1994
-
[36]
title Behavioral game theory: Experiments in strategic interaction ( publisher Princeton University Press , year 2003 )
author Camerer, C. title Behavioral game theory: Experiments in strategic interaction ( publisher Princeton University Press , year 2003 )
2003
-
[37]
title OpenSAE : Open-sourced sparse auto-encoder towards interpreting large language models ( year 2025 )
author THU-KEG . title OpenSAE : Open-sourced sparse auto-encoder towards interpreting large language models ( year 2025 ). ://github.com/THU-KEG/OpenSAE
2025
-
[38]
author Kirshner, S. N. , author Pan, Y. & author Wu, J. X. title Prosocial when simple and cold-hearted when complex: How task difficulty shapes LLM behavior . journal Decision Analysis volume forthcoming ( year 2025 )
2025
-
[39]
, author Das, D
author Tenney, I. , author Das, D. & author Pavlick, E. title BERT rediscovers the classical NLP pipeline . howpublished Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019) ( year 2019 )
2019
-
[40]
, author Kovaleva, O
author Rogers, A. , author Kovaleva, O. & author Rumshisky, A. title A primer in BERTology : What we know about how BERT works . journal Transactions of the Association for Computational Linguistics volume 8 , pages 842--866 ( year 2020 )
2020
-
[41]
author Stanovich, K. E. & author West, R. F. title Advancing the rationality debate . journal Behavioral and Brain Sciences volume 23 , pages 701--717 ( year 2000 )
2000
-
[42]
title Thinking, fast and slow
author Kahneman, D. title Thinking, fast and slow . journal Farrar, Straus and Giroux ( year 2011 )
2011
-
[43]
author Rand, D. G. , author Greene, J. D. & author Nowak, M. A. title Spontaneous giving and calculated greed . journal Nature volume 489 , pages 427--430 ( year 2012 )
2012
-
[44]
, author Bau, D
author Meng, K. , author Bau, D. , author Andonian, A. & author Belinkov, Y. title Locating and editing factual associations in GPT . howpublished Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS 2022) ( year 2022 )
2022
-
[45]
title Interpreting GPT : The logit lens ( year 2020 )
author nostalgebraist . title Interpreting GPT : The logit lens ( year 2020 ). ://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens. note LessWrong post. Accessed: 2025-12-06
2020
-
[46]
& author Schmidt, K
author Fehr, E. & author Schmidt, K. M. title A theory of fairness, competition, and cooperation . journal Quarterly Journal of Economics volume 114 , pages 817--868 ( year 1999 )
1999
-
[47]
author Bolton, G. E. & author Ockenfels, A. title ERC : A theory of equity, reciprocity, and competition . journal American Economic Review volume 91 , pages 166--193 ( year 2000 )
2000
-
[48]
& author Dufwenberg, M
author Battigalli, P. & author Dufwenberg, M. title Guilt in games . journal American Economic Review volume 97 , pages 170--176 ( year 2007 )
2007
-
[49]
, author Mark, D
author Chapman, J. , author Mark, D. , author Pietro, O. , author Erik, S. & author Colin, C. title Econographics . journal Journal of Political Economy Microeconomics volume 1 , pages 115--161 ( year 2023 )
2023
-
[50]
author Falk, A. et al. title Global evidence on economic preferences . journal Quarterly Journal of Economics volume 133 , pages 1645--1692 ( year 2018 )
2018
-
[51]
title Cognitive reflection and decision making
author Frederick, S. title Cognitive reflection and decision making . journal Journal of Economic Perspectives volume 19 , pages 25--42 ( year 2005 )
2005
-
[52]
, author Fabi, S
author Hagendorff, T. , author Fabi, S. & author Kosinski, M. title Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT . journal Nature Computational Science volume 3 , pages 833--838 ( year 2023 )
2023
-
[53]
& author Singh, A
author Goli, A. & author Singh, A. title Frontiers: Can large language models capture human preferences? journal Marketing Science volume 43 , pages 709--722 ( year 2024 )
2024
-
[54]
author Salecha, A. et al. title Large language models display human-like social desirability biases in big five personality surveys . journal PNAS Nexus volume 3 , pages pgae533 ( year 2024 )
2024
-
[55]
& author Musolesi, M
author Macmillan-Scott, O. & author Musolesi, M. title ( I r)rationality and cognitive biases in large language models . journal Royal Society Open Science volume 11 , pages 240255 ( year 2024 )
2024
-
[56]
, author Cong, L
author Bini, P. , author Cong, L. W. , author Huang, X. & author Jin, L. J. title Behavioral economics of AI : LLM biases and corrections . journal SSRN 5213130 ( year 2025 )
2025
- [57]
-
[58]
author Hare, T. A. , author Camerer, C. F. & author Rangel, A. title Self-control in decision-making involves modulation of the vm PFC valuation system . journal Science volume 324 , pages 646--648 ( year 2009 )
2009
-
[59]
, author Bernhardt, B
author Steinbeis, N. , author Bernhardt, B. C. & author Singer, T. title Impulse control and underlying functions of the left DLPFC mediate age-related and age-independent individual differences in strategic social behavior . journal Neuron volume 73 , pages 1040--1051 ( year 2012 )
2012
-
[60]
author Hong, G. Z. et al. title A implies B : Circuit analysis in LLMs for propositional logical reasoning . howpublished The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025)
2025
-
[61]
author Du, C. et al. title Human-like object concept representations emerge naturally in multimodal large language models . journal Nature Machine Intelligence volume 7 , pages 860--875 ( year 2025 )
2025
-
[62]
, author Chang, P
author Vafa, K. , author Chang, P. G. , author Rambachan, A. & author Mullainathan, S. title What has a foundation model found? I nductive bias reveals world models . howpublished Forty-second International Conference on Machine Learning (ICML 2025) ( year 2025 )
2025
-
[63]
author Li, Y. et al. title The geometry of concepts: Sparse autoencoder feature structure . journal Entropy volume 27 , pages 344 ( year 2025 )
2025
-
[64]
author Gantla, S. R. title Exploring mechanistic interpretability in large language models: Challenges, approaches, and insights . howpublished The Fourth International Conference on Data Science, Agents & Artificial Intelligence (ICDSAAI 2025) ( year 2025 )
2025
-
[65]
author Lindsey, J. et al. title On the biology of a large language model . journal Transformer Circuits Thread ( year 2025 ). ://transformer-circuits.pub/2025/attribution-graphs/biology.html
2025
-
[66]
, author McDonell, K
author Shanahan, M. , author McDonell, K. & author Reynolds, L. title Role play with large language models . journal Nature volume 623 , pages 493--498 ( year 2023 )
2023
-
[67]
author Park, J. S. et al. title Generative agents: Interactive simulacra of human behavior . howpublished Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST 2023) ( year 2023 )
2023
-
[68]
author Bender, E. M. & author Koller, A. title Climbing towards NLU : On meaning, form, and understanding in the age of data . howpublished Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020) ( year 2020 )
2020
-
[69]
& author Krakauer, D
author Mitchell, M. & author Krakauer, D. C. title The debate over understanding in AI ’s large language models . journal Proceedings of the National Academy of Sciences volume 120 , pages e2215907120 ( year 2023 )
2023
-
[70]
Quarterly Journal of Economics , volume=
A theory of fairness, competition, and cooperation , author=. Quarterly Journal of Economics , volume=. 1999 , publisher=
1999
-
[71]
Quarterly Journal of Economics , volume=
Global evidence on economic preferences , author=. Quarterly Journal of Economics , volume=. 2018 , publisher=
2018
-
[72]
Current Biology , volume=
Dopamine modulates egalitarian behavior in humans , author=. Current Biology , volume=. 2015 , publisher=
2015
-
[73]
Nature , volume=
The moral machine experiment , author=. Nature , volume=. 2018 , publisher=
2018
-
[74]
Journal of Political Economy Microeconomics , volume=
Econographics , author=. Journal of Political Economy Microeconomics , volume=. 2023 , publisher=
2023
-
[75]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review arXiv
-
[76]
A Survey on Large Language Models for Code Generation
A survey on large language models for code generation , author=. arXiv preprint arXiv:2406.00515 , year=
work page internal anchor Pith review arXiv
-
[77]
arXiv preprint arXiv:2402.02392 , year=
Dellma: Decision making under uncertainty with large language models , author=. arXiv preprint arXiv:2402.02392 , year=
-
[78]
arXiv preprint arXiv:2405.16376 , year=
Stride: A tool-assisted llm agent framework for strategic and interactive decision-making , author=. arXiv preprint arXiv:2405.16376 , year=
-
[79]
arXiv preprint arXiv:2202.07785 , year=
Predictability and Surprise in Large Generative Models , author=. arXiv preprint arXiv:2202.07785 , year=
-
[80]
The ethics of
Haltaufderheide, Joschka and Ranisch, Robert , journal=. The ethics of. 2024 , publisher=
2024
-
[81]
AI Open , volume=
Large language models in law: A survey , author=. AI Open , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.