Recognition: unknown
Community Detection with the Canonical Ensemble
Pith reviewed 2026-05-10 01:08 UTC · model grok-4.3
The pith
Community detection is reframed as testing specific hypothesized structures against entropy-maximized null models using a z-score-like statistic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that evidence for specific community structure in a network can be assessed by comparing the observed network to null models constructed via entropy maximization under chosen constraints in the canonical ensemble, using a test statistic analogous to a z-score to measure the deviation.
What carries the argument
A z-score-like test statistic together with canonical ensemble null models derived from entropy maximization under different constraints.
If this is right
- Analysts obtain statistical evidence for or against specific community structures rather than generic partitions.
- The method applies directly to both real networks and synthetic benchmarks.
- Concrete questions about community presence receive yes-or-no style answers with a quantitative score.
- It serves as an alternative to Bayesian inference on the stochastic block model for the same networks.
Where Pith is reading between the lines
- The same entropy-maximization approach could test for other hypothesized network features such as degree correlations or motifs.
- Choosing different sets of constraints might isolate distinct kinds of structure within the same network.
- The test statistic could be used to validate or reject outputs produced by standard community detection algorithms.
Load-bearing premise
The entropy-maximizing constraints selected for the null models accurately encode the network features that would be present without the hypothesized community structure.
What would settle it
Finding that the test statistic distribution under the null models fails to match the expected behavior on networks known to lack any community structure would show the method does not correctly represent the absence of community.
Figures






read the original abstract
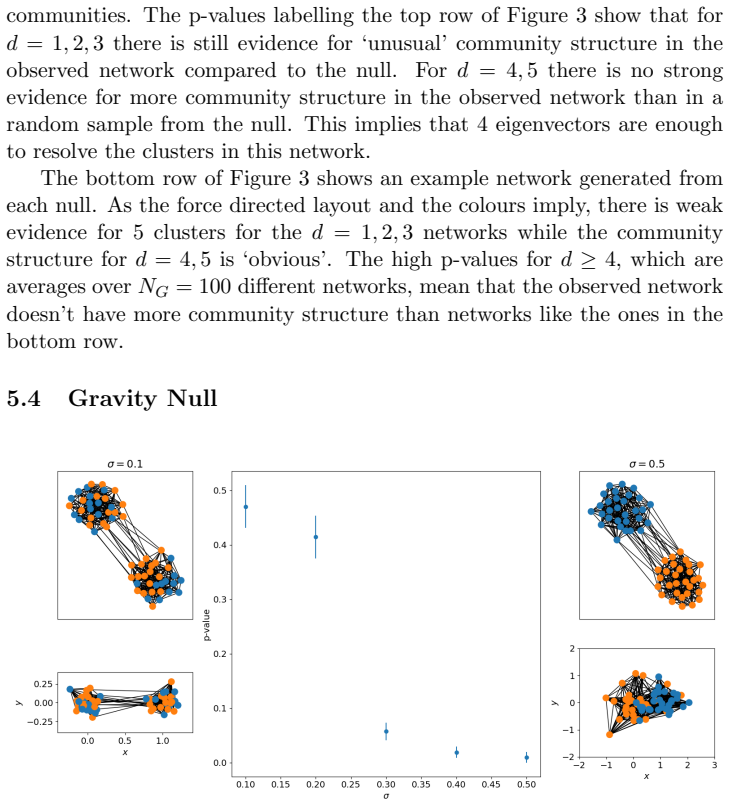
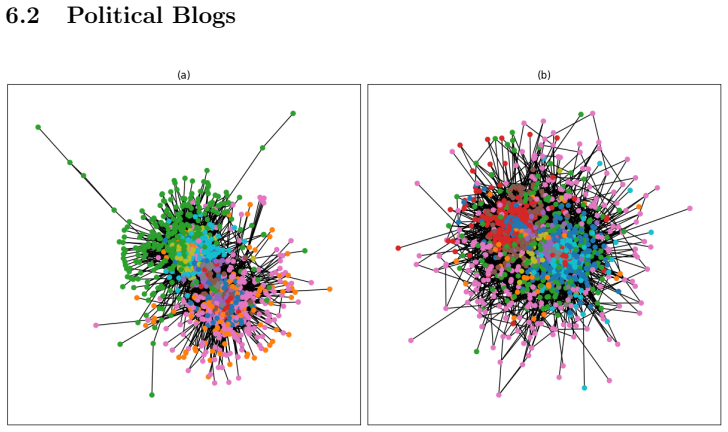
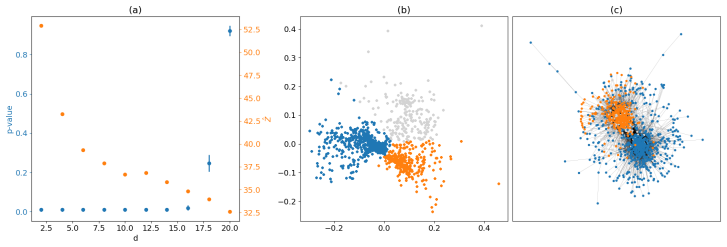
Network community detection is usually considered as an unsupervised learning problem. Given a network, the aim is to partition it using some general purpose algorithm. In this paper we instead treat community detection as a hypothesis testing problem. Given a network, we examine the evidence for specific community structure in the observed network compared to a null model. To do this we define an appropriate test statistic, analogous to a z-score, and several null models derived from maximising entropy under different constraints in the canonical ensemble. We demonstrate the application of this method on real and synthetic data and contrast our method to Bayesian approaches based on the stochastic block model. We demonstrate that this method gives definitive answers to concrete questions, which can be more useful to analysts than the output of a generic algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reframes community detection as a hypothesis-testing problem rather than unsupervised partitioning. For a hypothesized partition of a given network, it defines a z-score-like test statistic and constructs several null models by maximizing entropy in the canonical ensemble subject to different constraints (such as degree sequence or total edges). The method is applied to real and synthetic networks and contrasted with Bayesian stochastic block model inference, with the claim that it yields more definitive answers to concrete questions about the presence of specific community structure.
Significance. If the central assumption holds, the work would supply a frequentist, constraint-based alternative to generative models for validating specific community hypotheses. The maximum-entropy construction allows flexible null models that fix only low-order statistics, which could be valuable for interpretable, question-driven analysis in network science when the nulls are provably free of the tested structure.
major comments (3)
- [§3] §3 (Null models via entropy maximization): The manuscript derives null models by maximizing entropy under constraints such as expected degrees and total edges, yet provides no derivation or verification that the resulting distributions have zero excess intra-community edge probability for the hypothesized partition. This property is load-bearing for interpreting the test statistic as evidence of community structure; if the constraints still permit or induce positive intra-community density, the z-score does not isolate the hypothesized feature.
- [§5] §5 (Demonstrations on data): The applications to synthetic and real networks are described qualitatively, but no quantitative validation is reported (e.g., type-I error rates under the null, statistical power for planted communities, or error bars on the test statistic). Without these, the claim that the method 'gives definitive answers' cannot be assessed.
- [§4] §4 (Test statistic): The statistic is introduced as analogous to a z-score, but the manuscript does not detail the explicit computation of its mean and variance from the canonical-ensemble distributions. This leaves open whether the statistic is properly normalized and comparable across different null models.
minor comments (3)
- [Abstract] Abstract: The phrase 'several null models derived from maximising entropy under different constraints' should list the specific constraint sets used, to allow immediate evaluation of the approach.
- [References] References: Foundational citations to maximum-entropy network ensembles (e.g., Park & Newman) and to prior hypothesis-testing methods for communities are missing or incomplete.
- [Figures] Figures: Captions should explicitly state which null model and which hypothesized partition are used in each panel, and should report the numerical value of the test statistic.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and constructive feedback on our manuscript. Their comments highlight important aspects that require clarification and additional material to strengthen the presentation. Below, we provide point-by-point responses to the major comments and outline the revisions we intend to make in the updated version of the paper.
read point-by-point responses
-
Referee: [§3] §3 (Null models via entropy maximization): The manuscript derives null models by maximizing entropy under constraints such as expected degrees and total edges, yet provides no derivation or verification that the resulting distributions have zero excess intra-community edge probability for the hypothesized partition. This property is load-bearing for interpreting the test statistic as evidence of community structure; if the constraints still permit or induce positive intra-community density, the z-score does not isolate the hypothesized feature.
Authors: We thank the referee for pointing this out. In the canonical ensemble with constraints on the degree sequence, the probability of an edge between nodes i and j is p_{ij} = d_i d_j / (2m) (for the configuration model approximation in the large network limit), which depends only on the degrees and not on the community labels. Therefore, the expected number of intra-community edges for a given partition is exactly the sum of p_{ij} over pairs within communities, which is the same as the expectation under a null without community structure. This ensures zero excess intra-community probability due to the hypothesized partition. We acknowledge that this derivation was implicit rather than explicit in the original text. In the revised manuscript, we will include a detailed derivation in §3 showing that the null models are free of the tested community structure by construction, as the constraints do not involve community assignments. revision: yes
-
Referee: [§4] §4 (Test statistic): The statistic is introduced as analogous to a z-score, but the manuscript does not detail the explicit computation of its mean and variance from the canonical-ensemble distributions. This leaves open whether the statistic is properly normalized and comparable across different null models.
Authors: This is a fair observation. The test statistic is defined as a normalized count of intra-community edges, but the explicit expressions for its expectation and variance under each null model were not provided. For the Erdős–Rényi null model, the mean and variance follow directly from the binomial distribution. For the degree-constrained model, the variance can be calculated using the formula for the variance of the sum of dependent Bernoulli random variables with known covariances. We will add these explicit computations and derivations to §4 in the revision to confirm proper normalization and allow comparison across models. revision: yes
-
Referee: [§5] §5 (Demonstrations on data): The applications to synthetic and real networks are described qualitatively, but no quantitative validation is reported (e.g., type-I error rates under the null, statistical power for planted communities, or error bars on the test statistic). Without these, the claim that the method 'gives definitive answers' cannot be assessed.
Authors: We agree that quantitative validation would strengthen the empirical section. Although we presented results on both synthetic networks with known community structure and real-world networks, we did not include systematic assessments of type-I error or statistical power. In the revised manuscript, we will expand §5 to include Monte Carlo simulations on synthetic networks generated under the null models, reporting empirical type-I error rates and power curves for varying community strengths. We will also add error bars to the test statistic values computed on real data where feasible. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via independent maximum-entropy construction.
full rationale
The paper defines a z-score-like test statistic and derives null models by maximizing entropy subject to explicit constraints (e.g., expected degrees plus total edges) in the canonical ensemble. These steps are performed independently of the observed community partition and do not reduce to fitted parameters of the target data by construction. No self-citations appear in the load-bearing steps, and the entropy-maximization procedure is a standard, externally verifiable technique that does not presuppose the community structure being tested. The central claim therefore remains non-circular even if the chosen constraints are later shown to be insufficiently community-free.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the national academy of sciences , volume=
Defining and identifying communities in networks , author=. Proceedings of the national academy of sciences , volume=. 2004 , publisher=
2004
-
[2]
Proceedings of the 2005 SIAM international conference on data mining , pages=
A spectral clustering approach to finding communities in graphs , author=. Proceedings of the 2005 SIAM international conference on data mining , pages=. 2005 , organization=
2005
-
[3]
Statistics and computing , volume=
A tutorial on spectral clustering , author=. Statistics and computing , volume=. 2007 , publisher=
2007
-
[4]
Physical Review E , volume=
Finding multiple core-periphery pairs in networks , author=. Physical Review E , volume=. 2017 , publisher=
2017
-
[5]
Information Sciences , volume=
Anti-modularity and anti-community detecting in complex networks , author=. Information Sciences , volume=. 2014 , publisher=
2014
-
[6]
Physical Review X , volume=
Hierarchical block structures and high-resolution model selection in large networks , author=. Physical Review X , volume=. 2014 , publisher=
2014
-
[7]
PNAS nexus , volume=
Nonassortative relationships between groups of nodes are typical in complex networks , author=. PNAS nexus , volume=. 2023 , publisher=
2023
-
[8]
Plos one , volume=
Detectability constraints on meso-scale structure in complex networks , author=. Plos one , volume=. 2025 , publisher=
2025
-
[9]
Proceedings of ICML workshop on unsupervised and transfer learning , pages=
Clustering: Science or art? , author=. Proceedings of ICML workshop on unsupervised and transfer learning , pages=. 2012 , organization=
2012
-
[10]
Advances in neural information processing systems , volume=
An impossibility theorem for clustering , author=. Advances in neural information processing systems , volume=
-
[11]
Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=
Statistical significance of communities in networks , author=. Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=. 2010 , publisher=
2010
-
[12]
PloS one , volume=
Finding statistically significant communities in networks , author=. PloS one , volume=. 2011 , publisher=
2011
-
[13]
Scientific reports , volume=
A generalised significance test for individual communities in networks , author=. Scientific reports , volume=. 2018 , publisher=
2018
-
[14]
Physica A: Statistical Mechanics and its Applications , volume=
Exploring network structure with the density of states , author=. Physica A: Statistical Mechanics and its Applications , volume=. 2025 , publisher=
2025
-
[15]
arXiv preprint cond-mat/0610077 , year=
Thermodynamics of community structure , author=. arXiv preprint cond-mat/0610077 , year=
-
[16]
Statistica Sinica , pages=
A hypothesis testing framework for modularity based network community detection , author=. Statistica Sinica , pages=. 2017 , publisher=
2017
-
[17]
Network Science , volume=
A generalized hypothesis test for community structure in networks , author=. Network Science , volume=. 2024 , publisher=
2024
-
[18]
The information bottleneck method
The information bottleneck method , author=. arXiv preprint physics/0004057 , year=
work page internal anchor Pith review arXiv
-
[19]
Proceedings of the national academy of sciences , volume=
Modularity and community structure in networks , author=. Proceedings of the national academy of sciences , volume=. 2006 , publisher=
2006
-
[20]
Journal of anthropological research , volume=
An information flow model for conflict and fission in small groups , author=. Journal of anthropological research , volume=. 1977 , publisher=
1977
-
[21]
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise , booktitle =
Ester, Martin and Kriegel, Hans-Peter and Sander, J. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise , booktitle =. 1996 , publisher =
1996
-
[22]
ACM Sigmod record , volume=
OPTICS: Ordering points to identify the clustering structure , author=. ACM Sigmod record , volume=. 1999 , publisher=
1999
-
[23]
Pacific-Asia conference on knowledge discovery and data mining , pages=
Density-based clustering based on hierarchical density estimates , author=. Pacific-Asia conference on knowledge discovery and data mining , pages=. 2013 , organization=
2013
-
[24]
Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=
Statistical mechanics of networks , author=. Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=. 2004 , publisher=
2004
-
[25]
Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=
Entropy of network ensembles , author=. Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=. 2009 , publisher=
2009
-
[26]
Physical review letters , volume=
Breaking of ensemble equivalence in networks , author=. Physical review letters , volume=. 2015 , publisher=
2015
-
[27]
Journal of Physics A: Mathematical and Theoretical , volume=
Ensemble nonequivalence in random graphs with modular structure , author=. Journal of Physics A: Mathematical and Theoretical , volume=. 2017 , publisher=
2017
-
[28]
Proceedings of the National Academy of Sciences , volume=
Uncovering space-independent communities in spatial networks , author=. Proceedings of the National Academy of Sciences , volume=. 2011 , publisher=
2011
-
[29]
Journal of Complex Networks , volume=
Null models for community detection in spatially embedded, temporal networks , author=. Journal of Complex Networks , volume=. 2016 , publisher=
2016
-
[30]
PloS one , volume=
Z-score-based modularity for community detection in networks , author=. PloS one , volume=. 2016 , publisher=
2016
-
[31]
inferential community detection in networks: Pitfalls, myths and half-truths , author=
Descriptive vs. inferential community detection in networks: Pitfalls, myths and half-truths , author=. 2023 , publisher=
2023
-
[32]
Physica A: Statistical Mechanics and its Applications , volume=
Discovering block structure in networks , author=. Physica A: Statistical Mechanics and its Applications , volume=. 2023 , publisher=
2023
-
[33]
New Journal of Physics , volume=
Unbiased sampling of network ensembles , author=. New Journal of Physics , volume=. 2015 , publisher=
2015
-
[34]
, title =
Owen, Art B. , title =. Annals of Statistics , volume =. 2009 , doi =
2009
-
[35]
Proceedings of the national academy of sciences , volume=
Resolution limit in community detection , author=. Proceedings of the national academy of sciences , volume=. 2007 , publisher=
2007
-
[36]
International workshop on algorithms and models for the web-graph , pages=
Random dot product graph models for social networks , author=. International workshop on algorithms and models for the web-graph , pages=. 2007 , organization=
2007
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Maximum likelihood embedding of logistic random dot product graphs , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[38]
Random Structures & Algorithms , volume=
Algorithms for graph partitioning on the planted partition model , author=. Random Structures & Algorithms , volume=. 2001 , publisher=
2001
-
[39]
Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=
Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications , author=. Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=. 2011 , publisher=
2011
-
[40]
The Annals of Mathematical Statistics , volume=
A limit theorem for multidimensional Galton-Watson processes , author=. The Annals of Mathematical Statistics , volume=. 1966 , publisher=
1966
-
[41]
Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=
Stochastic blockmodels and community structure in networks , author=. Physical Review E—Statistical, Nonlinear, and Soft Matter Physics , volume=. 2011 , publisher=
2011
-
[42]
An impossibility result for reconstruction in the degree-corrected stochastic block model , journal =
Gulikers, Lennart and Lelarge, Marc and Massouli. An impossibility result for reconstruction in the degree-corrected stochastic block model , journal =. 2018 , doi =
2018
-
[43]
IEEE INFOCOM 2018-IEEE Conference on Computer Communications , pages=
Spectral graph forge: graph generation targeting modularity , author=. IEEE INFOCOM 2018-IEEE Conference on Computer Communications , pages=. 2018 , organization=
2018
-
[44]
Physical review letters , volume=
Fitness-dependent topological properties of the world trade web , author=. Physical review letters , volume=. 2004 , publisher=
2004
-
[45]
Physical Review Research , volume=
Gravity models of networks: Integrating maximum-entropy and econometric approaches , author=. Physical Review Research , volume=. 2022 , publisher=
2022
-
[46]
Experimental mathematics , volume=
A random graph model for power law graphs , author=. Experimental mathematics , volume=. 2001 , publisher=
2001
-
[47]
Advances in network clustering and blockmodeling , pages=
Bayesian stochastic blockmodeling , author=. Advances in network clustering and blockmodeling , pages=. 2019 , publisher=
2019
-
[48]
Nature Communications , volume=
Statistical inference links data and theory in network science , author=. Nature Communications , volume=. 2022 , publisher=
2022
-
[49]
The Annals of statistics , volume=
A universal prior for integers and estimation by minimum description length , author=. The Annals of statistics , volume=. 1983 , publisher=
1983
-
[50]
Physical Review E , volume=
Nonparametric Bayesian inference of the microcanonical stochastic block model , author=. Physical Review E , volume=. 2017 , publisher=
2017
-
[51]
Physical Review Research , volume=
Description length of canonical and microcanonical models , author=. Physical Review Research , volume=. 2025 , publisher=
2025
-
[52]
Proceedings of the 3rd international workshop on Link discovery , pages=
The political blogosphere and the 2004 US election: divided they blog , author=. Proceedings of the 3rd international workshop on Link discovery , pages=
2004
-
[53]
science , volume=
A global geometric framework for nonlinear dimensionality reduction , author=. science , volume=. 2000 , publisher=
2000
-
[54]
Mathematical programming , volume=
On the limited memory BFGS method for large scale optimization , author=. Mathematical programming , volume=. 1989 , publisher=
1989
-
[55]
Proceedings of the national academy of sciences , volume=
Maps of random walks on complex networks reveal community structure , author=. Proceedings of the national academy of sciences , volume=. 2008 , publisher=
2008
-
[56]
Physical review E , volume=
Finding and evaluating community structure in networks , author=. Physical review E , volume=. 2004 , publisher=
2004
-
[57]
Science advances , volume=
The ground truth about metadata and community detection in networks , author=. Science advances , volume=. 2017 , publisher=
2017
-
[58]
Physical Review E , volume=
Map equation with metadata: Varying the role of attributes in community detection , author=. Physical Review E , volume=. 2019 , publisher=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.