Recognition: unknown
TEMPO: Scaling Test-time Training for Large Reasoning Models
Pith reviewed 2026-05-10 02:36 UTC · model grok-4.3
The pith
TEMPO scales test-time training for large reasoning models by interleaving policy refinement with periodic critic recalibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that test-time training can be formalized as an EM algorithm that alternates policy refinement on unlabeled data with critic recalibration on labeled data. Prior methods are incomplete because they skip the recalibration step, allowing the self-reward signal to drift and causing performance to plateau along with loss of solution diversity. Reintroducing periodic recalibration tightens the evidence lower bound and enables sustained improvement with extra test-time compute.
What carries the argument
The EM-formalized alternating procedure in which policy refinement on unlabeled questions is periodically interrupted by critic recalibration on a labeled dataset, correcting reward drift.
If this is right
- Performance on reasoning tasks scales with additional test-time compute instead of plateauing.
- Accuracy on benchmarks such as AIME 2024 rises substantially for both 7B and 14B models across different families.
- Solution diversity remains high rather than collapsing as the policy evolves.
- Prior test-time training methods can be viewed as incomplete EM variants missing the recalibration step.
Where Pith is reading between the lines
- The requirement for occasional labeled recalibration suggests that future test-time systems may need to reserve a small calibration buffer for ongoing use.
- The same alternating structure could be tested in other domains where self-generated signals drift, such as code generation or scientific reasoning.
- Purely unsupervised test-time adaptation may face inherent limits without some form of periodic external correction.
Load-bearing premise
A modest labeled dataset remains available and representative enough for periodic critic recalibration during inference, and the EM formalization accurately captures the self-reward dynamics without introducing new drift.
What would settle it
An experiment that runs the same unlabeled reasoning questions with and without the recalibration step and checks whether accuracy keeps rising after many iterations only when recalibration is included.
Figures


read the original abstract
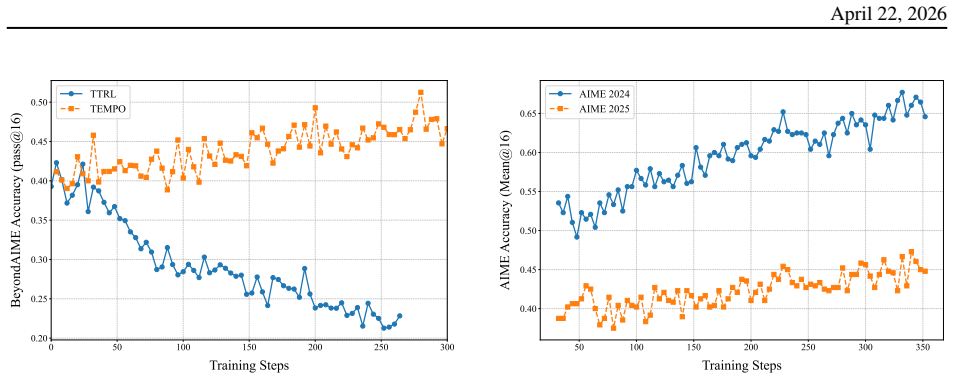
Test-time training (TTT) adapts model parameters on unlabeled test instances during inference time, which continuously extends capabilities beyond the reach of offline training. Despite initial gains, existing TTT methods for LRMs plateau quickly and do not benefit from additional test-time compute. Without external calibration, the self-generated reward signal increasingly drifts as the policy model evolves, leading to both performance plateaus and diversity collapse. We propose TEMPO, a TTT framework that interleaves policy refinement on unlabeled questions with periodic critic recalibration on a labeled dataset. By formalizing this alternating procedure through the Expectation-Maximization (EM) algorithm, we reveal that prior methods can be interpreted as incomplete variants that omit the crucial recalibration step. Reintroducing this step tightens the evidence lower bound (ELBO) and enables sustained improvement. Across diverse model families (Qwen3 and OLMO3) and reasoning tasks, TEMPO improves OLMO3-7B on AIME 2024 from 33.0% to 51.1% and Qwen3-14B from 42.3% to 65.8%, while maintaining high diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing test-time training (TTT) methods for large reasoning models plateau due to drifting self-generated reward signals and diversity collapse. It proposes TEMPO, which interleaves policy refinement on unlabeled test questions with periodic critic recalibration on a labeled dataset. By formalizing the alternating procedure as an instance of the Expectation-Maximization (EM) algorithm, prior TTT methods are interpreted as incomplete variants omitting the recalibration (M-step); reintroducing it is said to tighten the evidence lower bound (ELBO) and enable sustained gains. Concrete improvements are reported on AIME 2024 (OLMO3-7B: 33.0% to 51.1%; Qwen3-14B: 42.3% to 65.8%) while preserving diversity.
Significance. If the EM formalization is non-circular and the recalibration step proves practical, the work could meaningfully advance scalable inference-time adaptation for reasoning models by directly addressing reward drift, a recognized bottleneck in current TTT approaches. The reported accuracy lifts across two model families provide a concrete empirical anchor, though their attribution to the proposed mechanism remains to be verified.
major comments (3)
- [Abstract and Methods] Abstract and Methods: The claim that reintroducing the recalibration step tightens the ELBO (relative to prior incomplete TTT variants) is load-bearing for the central theoretical contribution. No explicit derivation, update equations, or proof is supplied showing that the M-step produces a strict improvement independent of the fitted quantities, leaving open the possibility that the EM lens is applied post-hoc rather than deriving the result.
- [Methods] Methods: The procedure requires a modest labeled dataset for periodic critic recalibration at inference time. The manuscript provides no protocol for dataset size, selection, or verification that it remains distributionally close to the evolving unlabeled test questions; without this, the method collapses to the incomplete variants it criticizes and the ELBO-tightening argument does not apply.
- [Experiments] Experiments: The abstract reports accuracy lifts on AIME 2024 for two model families but supplies no implementation details, baseline comparisons, statistical significance tests, ablation results on recalibration frequency, or controls for the labeled dataset, making it impossible to assess whether the gains are attributable to the EM-motivated procedure.
minor comments (1)
- [Abstract] Abstract: The claim of 'maintaining high diversity' is stated without quantitative metrics, comparison tables, or definitions of the diversity measure used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications on the manuscript's content and committing to revisions that strengthen the presentation and rigor of the work.
read point-by-point responses
-
Referee: [Abstract and Methods] The claim that reintroducing the recalibration step tightens the ELBO (relative to prior incomplete TTT variants) is load-bearing for the central theoretical contribution. No explicit derivation, update equations, or proof is supplied showing that the M-step produces a strict improvement independent of the fitted quantities, leaving open the possibility that the EM lens is applied post-hoc rather than deriving the result.
Authors: We appreciate this observation on the theoretical presentation. The manuscript frames the alternating procedure as an EM algorithm where policy refinement corresponds to the E-step and critic recalibration to the M-step, invoking the standard EM guarantee that the M-step increases the ELBO. However, no explicit derivation or update equations are provided. To address this directly, we will add a new subsection to the Methods with the full ELBO derivation, the critic update equations, and a proof sketch demonstrating the non-decrease (and strict improvement under non-degenerate conditions) independent of specific fitted values. This will make the theoretical contribution self-contained and clarify that the EM view motivates the procedure. revision: yes
-
Referee: [Methods] The procedure requires a modest labeled dataset for periodic critic recalibration at inference time. The manuscript provides no protocol for dataset size, selection, or verification that it remains distributionally close to the evolving unlabeled test questions; without this, the method collapses to the incomplete variants it criticizes and the ELBO-tightening argument does not apply.
Authors: This is a fair critique regarding reproducibility and the conditions under which the ELBO argument holds. The manuscript describes the use of a labeled dataset for recalibration but does not specify size, selection, or verification. In the revision we will add a dedicated paragraph in Methods detailing the protocol: a fixed set of 128 examples drawn randomly from the training split of each benchmark, chosen to match the task domain. We will also include a verification procedure based on embedding cosine similarity (threshold > 0.85) between the labeled set and incoming test questions, with a note on how to detect and handle significant distributional shift. These additions will prevent the method from reducing to prior incomplete variants. revision: yes
-
Referee: [Experiments] The abstract reports accuracy lifts on AIME 2024 for two model families but supplies no implementation details, baseline comparisons, statistical significance tests, ablation results on recalibration frequency, or controls for the labeled dataset, making it impossible to assess whether the gains are attributable to the EM-motivated procedure.
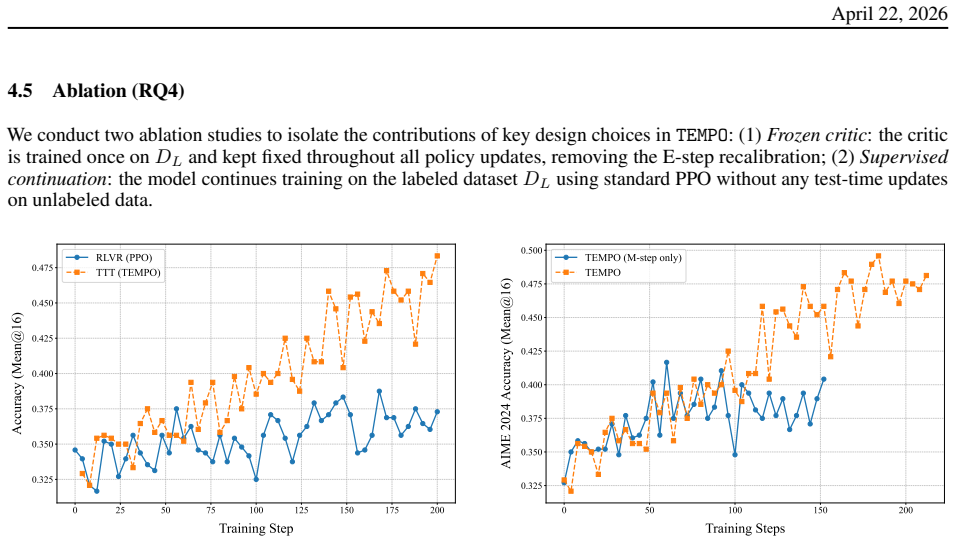
Authors: We agree that the experimental reporting requires expansion for full evaluation. The manuscript (including appendix) already contains implementation details, comparisons against prior TTT baselines, and ablations varying recalibration frequency that show sustained gains only when the M-step is included. However, statistical significance testing and explicit controls for the labeled dataset (e.g., replacing it with unlabeled data) are absent from the main text. We will revise the Experiments section to report means and standard deviations over five random seeds, include p-values from paired t-tests against baselines, and add an ablation that disables the labeled recalibration step, demonstrating reversion toward the plateau behavior of incomplete TTT. These changes will strengthen attribution to the proposed mechanism. revision: partial
Circularity Check
ELBO tightening claim reduces to EM properties by construction of the formalization
specific steps
-
self definitional
[Abstract]
"By formalizing this alternating procedure through the Expectation-Maximization (EM) algorithm, we reveal that prior methods can be interpreted as incomplete variants that omit the crucial recalibration step. Reintroducing this step tightens the evidence lower bound (ELBO) and enables sustained improvement."
The alternating procedure is defined first; casting it as EM then makes the ELBO tightening a direct, automatic consequence of EM's E/M-step guarantee rather than a derived property shown from the specific policy and critic updates. Prior methods are labeled 'incomplete' solely because they lack the recalibration step that completes the EM pair, rendering the superiority tautological to the chosen formalization.
full rationale
The paper's central theoretical contribution is the claim that formalizing the alternating policy refinement + critic recalibration procedure as EM reveals prior TTT methods as incomplete and that reintroducing recalibration tightens the ELBO. This reduction is exhibited directly in the abstract: the benefit is asserted as a consequence of the EM framing itself rather than an independent derivation from the method's update rules or reward dynamics. While the empirical gains on AIME and other tasks are reported separately and could be non-circular, the load-bearing 'why it works' argument collapses to the known monotonicity property of EM once the procedure is cast in that form. No other circular steps are identifiable from the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The alternating policy refinement and critic recalibration procedure can be formalized as an EM algorithm whose M-step corresponds to recalibration on labeled data.
Reference graph
Works this paper leans on
-
[1]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
P1: Mastering physics olympiads with reinforcement learning.arXiv preprint arXiv:2511.13612, 2025
Jiacheng Chen, Qianjia Cheng, Fangchen Yu, Haiyuan Wan, Yuchen Zhang, Shenghe Zheng, Junchi Yao, Qingyang Zhang, Haonan He, Yun Luo, et al. P1: Mastering physics olympiads with reinforcement learning.arXiv preprint arXiv:2511.13612, 2025
-
[3]
Yun Luo, Futing Wang, Qianjia Cheng, Fangchen Yu, Haodi Lei, Jianhao Yan, Chenxi Li, Jiacheng Chen, Yufeng Zhao, Haiyuan Wan, et al. P1-vl: Bridging visual perception and scientific reasoning in physics olympiads.arXiv preprint arXiv:2602.09443, 2026
-
[4]
Right question is already half the answer: Fully unsupervised llm reasoning incentivization.Advances in neural information processing systems, 2025
Qingyang Zhang, Haitao Wu, Changqing Zhang, Peilin Zhao, and Yatao Bian. Right question is already half the answer: Fully unsupervised llm reasoning incentivization.Advances in neural information processing systems, 2025
2025
-
[5]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Shang Qu, Li Sheng, Xuekai Zhu, Biqing Qi, Youbang Sun, Ganqu Cui, Ning Ding, and Bowen Zhou. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025
work page Pith review arXiv 2025
-
[6]
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, Hao Cheng, Pengcheng He, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. Thetaevolve: Test-time learning on open problems.arXiv preprint 2511.23473, 2025
-
[7]
Improving composer through real-time rl
Jacob Jackson, Ben Trapani, Nathan Wang, and Wanqi Zhu. Improving composer through real-time rl. https: //cursor.com/blog/real-time-rl-for-composer, March 2026. Accessed: 2026-04-12
2026
-
[8]
How far can unsupervised RLVR scale LLM training? InThe Fourteenth International Conference on Learning Representations, 2026
Yuxin Zuo, Bingxiang He, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, Cheng Qian, Xiusi Chen, Youbang Sun, Xingtai Lv, Xuekai Zhu, Li Sheng, Ran Li, Huan ang Gao, Yuchen Zhang, Lifan Yuan, Zhiyuan Liu, Bowen Zhou, and Ning Ding. How far can unsupervised RLVR scale LLM training? InThe Fourteenth International Con...
2026
-
[9]
No free lunch: Rethinking internal feedback for llm reasoning, 2025
Yanzhi Zhang, Zhaoxi Zhang, Haoxiang Guan, Yilin Cheng, Yitong Duan, Chen Wang, Yue Wang, Shuxin Zheng, and Jiyan He. No free lunch: Rethinking internal feedback for llm reasoning, 2025
2025
-
[10]
Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Hajishirz...
2024
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
One- shot entropy minimization,
Zitian Gao, Lynx Chen, Haoming Luo, Joey Zhou, and Bryan Dai. One-shot entropy minimization.arXiv preprint arXiv:2505.20282, 2025
-
[14]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
-
[15]
Yifan Wang, Bolian Li, David Cho, Ruqi Zhang, Fanping Sui, and Ananth Grama. Sarl: Label-free reinforcement learning by rewarding reasoning topology.arXiv preprint arXiv:2603.27977, 2026
work page internal anchor Pith review arXiv 2026
-
[16]
Laser: Reinforcement learning with last-token self-rewarding
Wenkai Yang, Weijie Liu, Ruobing Xie, Yiju Guo, Lulu Wu, Saiyong Yang, and Yankai Lin. Laser: Reinforcement learning with last-token self-rewarding. InInternation Conference on Learning Representations, 2026
2026
-
[17]
Semi-supervised learning by entropy minimization.Advances in neural information processing systems, 17, 2004
Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization.Advances in neural information processing systems, 17, 2004
2004
-
[18]
Tent: Fully test-time adaptation by entropy minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations, 2021. April 22, 2026
2021
-
[19]
Come: Test-time adaption by conservatively minimizing entropy
Qingyang Zhang, Yatao Bian, Xinke Kong, Peilin Zhao, and Changqing Zhang. Come: Test-time adaption by conservatively minimizing entropy. InInternational Conference on Learning Representations, 2025
2025
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Team Olmo, Allyson Ettinger, et al. Olmo 3.arXiv preprint arXiv:2512.13961, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Beyondaime: Advancing math reasoning evaluation beyond high school olympiads
[ByteDance-Seed]. Beyondaime: Advancing math reasoning evaluation beyond high school olympiads. [https://huggingface.co/datasets/ByteDance-Seed/BeyondAIME](https://huggingface.co/ datasets/ByteDance-Seed/BeyondAIME), 2025
2025
-
[24]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Beichen Zhang, Haoxiang Sun, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, Zheng Liu, Zhongyuan Wang, Lei Fang, and Ji-Rong Wen. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models.arXiv preprint arXiv:2503.21380, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
2023
-
[27]
Agieval: A human-centric benchmark for evaluating foundation models
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. InFindings of the association for computational linguistics: NAACL 2024, pages 2299–2314, 2024
2024
-
[28]
Zebralogic: On the scaling limits of llms for logical reasoning
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of llms for logical reasoning. InInternational Conference on Machine Learning, pages 37889–37905. PMLR, 2025
2025
-
[29]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
2024
-
[30]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.