Recognition: unknown
DebugRepair: Enhancing LLM-Based Automated Program Repair via Self-Directed Debugging
Pith reviewed 2026-05-10 02:19 UTC · model grok-4.3
The pith
By simulating its own debugging steps, DebugRepair lets LLMs gather intermediate runtime states to produce more accurate program patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
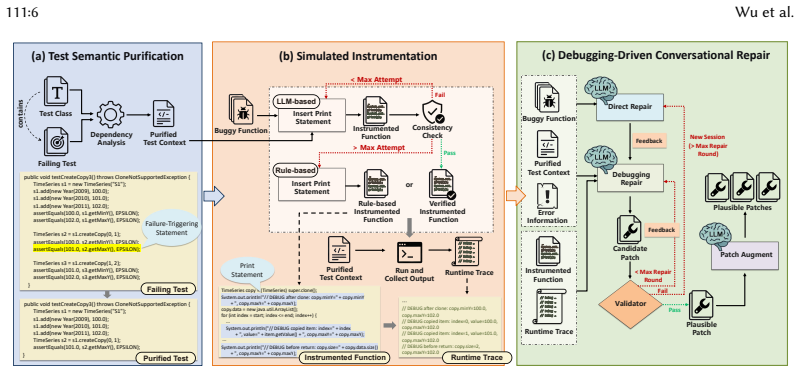
DebugRepair improves LLM-based automated program repair by replacing sole reliance on test-failure outcomes with self-directed debugging that collects intermediate runtime states. The framework comprises test semantic purification to strip irrelevant context, simulated instrumentation that adds debugging statements and falls back to rule-based traces when needed, and debugging-driven conversational repair that iteratively updates candidate patches using both earlier attempts and newly observed states. On Defects4J this produces 224 correct fixes with GPT-3.5 (26.2 percent above prior best LLM methods) and 295 fixes with DeepSeek-V3 (59 above the next baseline), with similar relative gains on
What carries the argument
Simulated instrumentation combined with debugging-driven conversational repair, which inserts targeted statements to expose intermediate runtime states and feeds those states back into patch refinement.
If this is right
- LLM repair performance rises by 51.3 percent over vanilla settings across five additional backbone models.
- The method reaches state-of-the-art results against 15 prior approaches on three benchmarks spanning Java and Python.
- With GPT-3.5 it fixes 224 Defects4J bugs, exceeding the previous best LLM-based result by 26.2 percent.
- With DeepSeek-V3 it fixes 295 Defects4J bugs, exceeding the second-best baseline by 59 bugs.
Where Pith is reading between the lines
- The same intermediate-state collection strategy could be applied to non-LLM repair systems that currently use only test outcomes.
- Models may benefit further if the simulation is replaced by actual debugger attachment that records richer execution traces.
- The conversational refinement loop suggests a general pattern for improving LLM code generation tasks that require diagnosis rather than one-shot synthesis.
Load-bearing premise
The simulated instrumentation and rule-based debugging statements capture relevant intermediate runtime states without altering program semantics or injecting misleading artifacts.
What would settle it
Remove the simulated instrumentation component from DebugRepair and measure whether the number of correctly fixed bugs on Defects4J drops below the full system's count for the same backbone model.
Figures








read the original abstract
Automated Program Repair (APR) has benefited from the code understanding and generation capabilities of Large Language Models (LLMs). Existing feedback-based APR methods iteratively refine candidate patches using test execution feedback and have shown promising results. However, most rely on outcome-level failure symptoms, such as stack traces, which show how failures are observed but fail to expose the intermediate runtime states critical for root-cause analysis. As a result, LLMs often infer bug causes without sufficient runtime evidence, leading to incorrect patches. To address this limitation, we propose DebugRepair, a self-directed debugging framework for LLM-based APR. DebugRepair enhances patch refinement with intermediate runtime evidence collected through simulated debugging. It consists of three components: test semantic purification, simulated instrumentation, and debugging-driven conversational repair. Together, they reduce noisy test context, collect runtime traces through targeted debugging statements with rule-based fallback, and progressively refine candidate patches using prior attempts and newly observed runtime states. We evaluate DebugRepair on three benchmarks across Java and Python. Experiments show that DebugRepair achieves state-of-the-art performance against 15 approaches. With GPT-3.5, it correctly fixes 224 bugs on Defects4J, outperforming prior SOTA LLM-based methods by 26.2%. With DeepSeek-V3, it correctly fixes 295 Defects4J bugs, surpassing the second-best baseline by 59 bugs. Across five additional backbone LLMs, DebugRepair improves repair performance by 51.3% over vanilla settings. Ablation studies further confirm the effectiveness of all components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DebugRepair, a self-directed debugging framework for LLM-based automated program repair. It comprises test semantic purification to reduce noisy test context, simulated instrumentation to collect intermediate runtime traces via targeted debugging statements with rule-based fallback, and debugging-driven conversational repair to iteratively refine patches using prior attempts and observed runtime states. Evaluations on Defects4J and two additional Java/Python benchmarks against 15 baselines claim SOTA results, including 224 fixed bugs on Defects4J with GPT-3.5 (26.2% over prior LLM-based SOTA), 295 with DeepSeek-V3 (59 more than second-best), and 51.3% average improvement across five other backbone LLMs, supported by ablations.
Significance. If the results hold, this would be a solid contribution to APR by moving beyond outcome-level feedback (e.g., stack traces) to intermediate runtime evidence, enabling better root-cause analysis by LLMs. The consistent gains across multiple LLMs and the ablation support for each component indicate practical utility and generalizability within the current LLM-APR paradigm.
major comments (2)
- [§3.2] §3.2 (Simulated Instrumentation): No verification is reported that instrumented executions produce identical test-suite outcomes to the original programs. This check is required to confirm that rule-based debugging-statement insertion neither alters observable behavior nor injects spurious values, which is load-bearing for the claim that the collected states enable correct patches.
- [§4] §4 (Evaluation and Ablations): The ablation studies show component contributions but do not test whether the captured runtime states are causally tied to the bug root cause (versus incidental) or whether the conversational refinement would succeed without them; this weakens attribution of the 26.2% and 51.3% gains specifically to the debugging mechanism.
minor comments (2)
- The abstract states results on 'three benchmarks' but only names Defects4J explicitly; listing the other two (with sizes and bug counts) would improve clarity.
- [Figure 1] Figure 1 (framework overview) would benefit from explicit arrows showing how runtime states feed back into the conversational repair loop.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, acknowledging valid points where the manuscript can be strengthened and outlining planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Simulated Instrumentation): No verification is reported that instrumented executions produce identical test-suite outcomes to the original programs. This check is required to confirm that rule-based debugging-statement insertion neither alters observable behavior nor injects spurious values, which is load-bearing for the claim that the collected states enable correct patches.
Authors: We agree this verification is important. The manuscript does not report an explicit check confirming that instrumented executions produce identical test-suite outcomes. Our rule-based insertion targets non-intrusive debugging statements (e.g., prints for intermediate values) designed to avoid altering control flow or data, with fallback to original execution on failure. To address this, we will add a verification experiment in the revised manuscript, measuring outcome equivalence rates across Defects4J and the other benchmarks before and after instrumentation. This will directly support the fidelity of the collected runtime states. revision: yes
-
Referee: [§4] §4 (Evaluation and Ablations): The ablation studies show component contributions but do not test whether the captured runtime states are causally tied to the bug root cause (versus incidental) or whether the conversational refinement would succeed without them; this weakens attribution of the 26.2% and 51.3% gains specifically to the debugging mechanism.
Authors: The ablation studies demonstrate the contribution of each component, with the largest gains tied to the debugging-driven conversational repair that incorporates observed runtime states alongside prior attempts. However, we acknowledge the comment's validity: the current ablations do not isolate whether the specific runtime states are causally linked to root causes versus incidental, nor do they directly compare conversational success with versus without those states. We will add a targeted analysis in the revision, such as an additional ablation within the conversational repair phase that masks or removes the runtime state information, to better attribute the reported improvements (26.2% and 51.3%) to the debugging mechanism. revision: yes
Circularity Check
No circularity in empirical claims or derivations
full rationale
The paper is an empirical study proposing a debugging framework for LLM-based APR and reporting success rates on public benchmarks (Defects4J and others) via direct comparison to external baselines. No equations, fitted parameters, or self-referential normalizations appear in the provided text; performance numbers are obtained from standard experimental runs rather than any derivation that reduces outputs to inputs by construction. Self-citations, if present, are not load-bearing for any central premise, and the method description relies on explicit components (test purification, simulated instrumentation, conversational repair) whose validity is assessed externally rather than defined circularly.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can leverage intermediate runtime states for more accurate root-cause diagnosis and patch refinement than outcome-level failure symptoms alone
invented entities (4)
-
DebugRepair framework
no independent evidence
-
test semantic purification
no independent evidence
-
simulated instrumentation
no independent evidence
-
debugging-driven conversational repair
no independent evidence
Forward citations
Cited by 1 Pith paper
-
PYTHALAB-MERA: Validation-Grounded Memory, Retrieval, and Acceptance Control for Frozen-LLM Coding Agents
An external controller for frozen LLMs raises strict validation success on three RL coding tasks from 0/9 to 8/9 by selecting memory records and skills, running fail-fast checks, and propagating credit via eligibility traces.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Models | OpenAI API. https://platform.openai.com/docs/models#gpt-3-5-turbo [Online; accessed 2026-01-20]
2026
-
[2]
[n. d.]. SiliconFlow – AI Infrastructure for LLMs & Multimodal Models. https://www.siliconflow.com/ [Online; accessed 2026-01-20]
2026
-
[3]
[n. d.]. tree-sitter/tree-sitter: An incremental parsing system for programming tools. https://github.com/tree-sitter/tree- sitter [Online; accessed 2026-03-13]
2026
- [4]
-
[5]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Zimin Chen, Steve Kommrusch, Michele Tufano, Louis-Noël Pouchet, Denys Poshyvanyk, and Martin Monperrus. 2019. Sequencer: Sequence-to-sequence learning for end-to-end program repair.IEEE Transactions on Software Engineering 47, 9 (2019), 1943–1959
2019
-
[7]
Xiang Gao, Bo Wang, Gregory J Duck, Ruyi Ji, Yingfei Xiong, and Abhik Roychoudhury. 2021. Beyond tests: Program vulnerability repair via crash constraint extraction.ACM Transactions on Software Engineering and Methodology (TOSEM)30, 2 (2021), 1–27
2021
-
[8]
Luca Gazzola, Daniela Micucci, and Leonardo Mariani. 2018. Automatic software repair: A survey. InProceedings of the 40th International Conference on Software Engineering. 1219–1219
2018
-
[9]
Ali Ghanbari, Samuel Benton, and Lingming Zhang. 2019. Practical program repair via bytecode mutation. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis. 19–30. J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. 111:26 Wu et al
2019
- [11]
-
[12]
Jinru Hua, Mengshi Zhang, Kaiyuan Wang, and Sarfraz Khurshid. 2018. Sketchfix: a tool for automated program repair approach using lazy candidate generation. InProceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 888–891
2018
-
[13]
Jiajun Jiang, Yingfei Xiong, Hongyu Zhang, Qing Gao, and Xiangqun Chen. 2018. Shaping program repair space with existing patches and similar code. InProceedings of the 27th ACM SIGSOFT international symposium on software testing and analysis. 298–309
2018
-
[14]
Nan Jiang, Kevin Liu, Thibaud Lutellier, and Lin Tan. 2023. Impact of code language models on automated program repair. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1430–1442
2023
-
[15]
Nan Jiang, Thibaud Lutellier, Yiling Lou, Lin Tan, Dan Goldwasser, and Xiangyu Zhang. 2023. Knod: Domain knowledge distilled tree decoder for automated program repair. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1251–1263
2023
-
[16]
Nan Jiang, Thibaud Lutellier, and Lin Tan. 2021. Cure: Code-aware neural machine translation for automatic program repair. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1161–1173
2021
-
[17]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review arXiv 2023
-
[18]
René Just, Darioush Jalali, and Michael D Ernst. 2014. Defects4J: A database of existing faults to enable controlled testing studies for Java programs. InProceedings of the 2014 international symposium on software testing and analysis. 437–440
2014
-
[19]
Jiaolong Kong, Xiaofei Xie, Mingfei Cheng, Shangqing Liu, Xiaoning Du, and Qi Guo. 2025. Contrastrepair: Enhancing conversation-based automated program repair via contrastive test case pairs.ACM Transactions on Software Engineering and Methodology34, 8 (2025), 1–31
2025
-
[20]
Xuan-Bach D Le, Duc-Hiep Chu, David Lo, Claire Le Goues, and Willem Visser. 2017. S3: syntax-and semantic-guided repair synthesis via programming by examples. InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering. 593–604
2017
-
[21]
Xuan Bach D Le, David Lo, and Claire Le Goues. 2016. History driven program repair. In2016 IEEE 23rd international conference on software analysis, evolution, and reengineering (SANER), Vol. 1. IEEE, 213–224
2016
-
[22]
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. 2011. Genprog: A generic method for automatic software repair.Ieee transactions on software engineering38, 1 (2011), 54–72
2011
-
[23]
Claire Le Goues, Michael Pradel, and Abhik Roychoudhury. 2019. Automated program repair.Commun. ACM62, 12 (2019), 56–65
2019
-
[24]
Yi Li, Shaohua Wang, and Tien N Nguyen. 2020. Dlfix: Context-based code transformation learning for automated program repair. InProceedings of the ACM/IEEE 42nd international conference on software engineering. 602–614
2020
-
[25]
Yi Li, Shaohua Wang, and Tien N Nguyen. 2022. Dear: A novel deep learning-based approach for automated program repair. InProceedings of the 44th international conference on software engineering. 511–523
2022
-
[26]
Derrick Lin, James Koppel, Angela Chen, and Armando Solar-Lezama. 2017. QuixBugs: A multi-lingual program repair benchmark set based on the Quixey Challenge. InProceedings Companion of the 2017 ACM SIGPLAN international conference on systems, programming, languages, and applications: software for humanity. 55–56
2017
-
[27]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. Avatar: Fixing semantic bugs with fix patterns of static analysis violations. In2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 1–12
2019
-
[28]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. TBar: Revisiting template-based automated program repair. InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis. 31–42
2019
-
[29]
Fan Long and Martin Rinard. 2015. Staged program repair with condition synthesis. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. 166–178
2015
-
[30]
Matias Martinez and Martin Monperrus. 2016. Astor: A program repair library for java. InProceedings of the 25th international symposium on software testing and analysis. 441–444
2016
-
[31]
Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2016. Angelix: Scalable multiline program patch synthesis via symbolic analysis. InProceedings of the 38th international conference on software engineering. 691–701
2016
-
[32]
Weishi Wang, Yue Wang, Shafiq Joty, and Steven CH Hoi. 2023. Rap-gen: Retrieval-augmented patch generation with codet5 for automatic program repair. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 146–158. J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 20...
2023
-
[33]
Yunkun Wang, Yue Zhang, Guochang Li, Chen Zhi, Binhua Li, Fei Huang, Yongbin Li, and Shuiguang Deng. 2026. InspectCoder: Dynamic Analysis-Driven Self Repair through Interactive LLM-Debugger Collaboration.Proceedings of the ACM on Programming Languages10, OOPSLA1 (2026), 1041–1069
2026
-
[34]
Ming Wen, Junjie Chen, Rongxin Wu, Dan Hao, and Shing-Chi Cheung. 2018. Context-aware patch generation for better automated program repair. InProceedings of the 40th international conference on software engineering. 1–11
2018
-
[35]
Chunqiu Steven Xia, Yifeng Ding, and Lingming Zhang. 2023. The plastic surgery hypothesis in the era of large language models. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 522–534
2023
-
[36]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
-
[37]
Chunqiu Steven Xia and Lingming Zhang. 2022. Less training, more repairing please: revisiting automated program repair via zero-shot learning. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 959–971
2022
-
[38]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 819–831
2024
-
[39]
Pengyu Xue, Linhao Wu, Zhen Yang, Chengyi Wang, Xiang Li, Yuxiang Zhang, Jia Li, Ruikai Jin, Yifei Pei, Zhaoyan Shen, et al. 2025. ClassEval-T: Evaluating Large Language Models in Class-Level Code Translation.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 1421–1444
2025
-
[40]
Pengyu Xue, Linhao Wu, Zhen Yang, Zhongxing Yu, Zhi Jin, Ge Li, Yan Xiao, Shuo Liu, Xinyi Li, Hongyi Lin, et al
-
[41]
arXiv preprint arXiv:2410.07516(2024)
Exploring and Lifting the Robustness of LLM-powered Automated Program Repair with Metamorphic Testing. arXiv preprint arXiv:2410.07516(2024)
-
[42]
Pengyu Xue, Linhao Wu, Zhongxing Yu, Zhi Jin, Zhen Yang, Xinyi Li, Zhenyu Yang, and Yue Tan. 2024. Automated commit message generation with large language models: An empirical study and beyond.IEEE Transactions on Software Engineering(2024)
2024
- [43]
-
[44]
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, and Ge Li
-
[45]
Exploring and unleashing the power of large language models in automated code translation.Proceedings of the ACM on Software Engineering1, FSE (2024), 1585–1608
2024
-
[46]
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. 2024. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing4, 2 (2024), 100211
2024
-
[47]
He Ye, Matias Martinez, Xiapu Luo, Tao Zhang, and Martin Monperrus. 2022. Selfapr: Self-supervised program repair with test execution diagnostics. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–13
2022
-
[48]
He Ye, Matias Martinez, and Martin Monperrus. 2022. Neural program repair with execution-based backpropagation. InProceedings of the 44th international conference on software engineering. 1506–1518
2022
-
[49]
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang. 2024. Thinkrepair: Self-directed automated program repair. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1274–1286
2024
- [50]
-
[51]
Quanjun Zhang, Chunrong Fang, Yuxiang Ma, Weisong Sun, and Zhenyu Chen. 2023. A survey of learning-based automated program repair.ACM Transactions on Software Engineering and Methodology33, 2 (2023), 1–69
2023
-
[52]
Qihao Zhu, Zeyu Sun, Yuan-an Xiao, Wenjie Zhang, Kang Yuan, Yingfei Xiong, and Lu Zhang. 2021. A syntax-guided edit decoder for neural program repair. InProceedings of the 29th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering. 341–353. Received 20 February 2007; revised 12 March 2009; a...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.