Recognition: unknown
Divide-and-Conquer Approach to Holistic Cognition in High-Similarity Contexts with Limited Data
Pith reviewed 2026-05-10 02:55 UTC · model grok-4.3
The pith
DHCNet decomposes holistic cues into subtle local discrepancies to recognize ultra-similar categories with limited training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DHCNet implements a divide-and-conquer strategy by decomposing holistic cues into spatially-associated subtle discrepancies and progressively establishing the holistic cognition process. It begins by progressively analyzing subtle discrepancies from smaller local patches to larger ones using a self-shuffling operation on local regions. Simultaneously it leverages the unaffected local regions to guide the perception of the original topological structure among the shuffled patches. DHCNet incorporates online refinement of these holistic cues discovered from local regions into the training process to iteratively improve their quality and uses the resulting cues as supervisory signals to fine-t1
What carries the argument
The divide-and-conquer holistic cognition process in DHCNet that decomposes holistic cues into spatially-associated subtle discrepancies via progressive local-patch analysis, self-shuffling, guidance from unaffected regions, and online refinement.
Load-bearing premise
Self-shuffling local regions together with guidance from unaffected areas and online refinement can reliably extract usable holistic cues as supervisory signals without creating artifacts that reduce recognition accuracy.
What would settle it
Running DHCNet on one of the five Ultra-FGVC datasets while disabling the self-shuffling step or the unaffected-region guidance and observing no drop in accuracy relative to the full model would show that the proposed decomposition does not drive the performance gains.
Figures


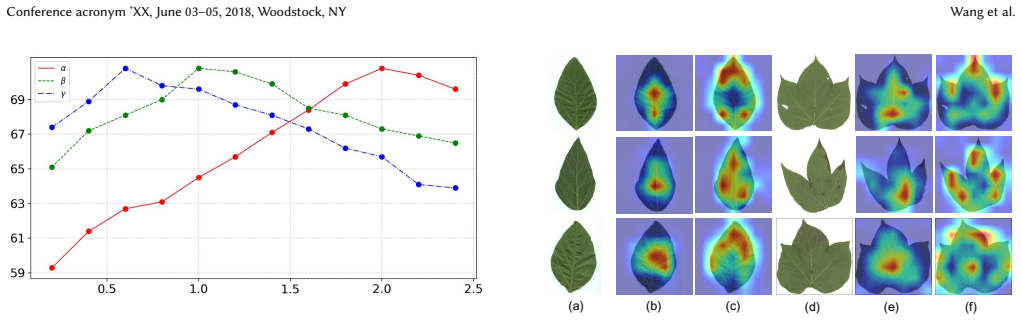
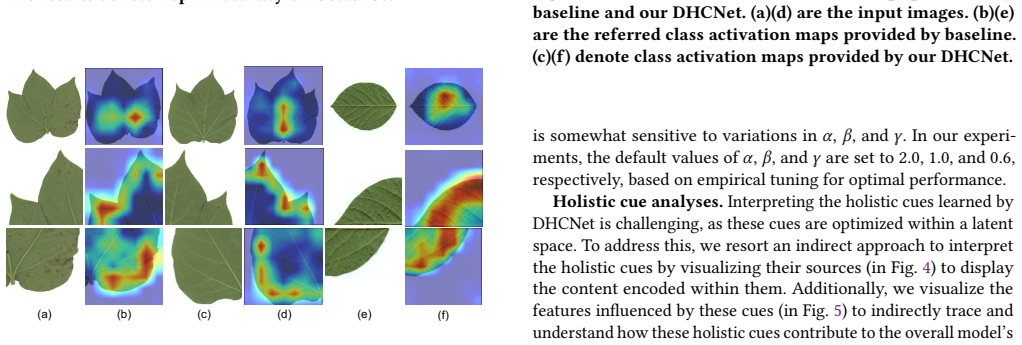
read the original abstract
Ultra-fine-grained visual categorization (Ultra-FGVC) aims to classify highly similar subcategories within fine-grained objects using limited training samples. However, holistic yet discriminative cues, such as leaf contours in extremely similar cultivars, remain under-explored in current studies, thereby limiting recognition performance. Though crucial, modeling holistic cues with complex morphological structures typically requires massive training samples, posing significant challenges in data-limited scenarios. To address this challenge, we propose a novel Divide-and-Conquer Holistic Cognition Network (DHCNet) that implements a divide-and-conquer strategy by decomposing holistic cues into spatially-associated subtle discrepancies and progressively establishing the holistic cognition process, significantly simplifying holistic cognition while reducing dependency on training data. Technically, DHCNet begins by progressively analyzing subtle discrepancies, transitioning from smaller local patches to larger ones using a self-shuffling operation on local regions. Simultaneously, it leverages the unaffected local regions to potentially guide the perception of the original topological structure among the shuffled patches, thereby aiding in the establishment of spatial associations for these discrepancies. Additionally, DHCNet incorporates the online refinement of these holistic cues discovered from local regions into the training process to iteratively improve their quality. As a result, DHCNet uses these holistic cues as supervisory signals to fine-tune the parameters of the recognition model, thus improving its sensitivity to holistic cues across the entire objects. Extensive evaluations demonstrate that DHCNet achieves remarkable performance on five widely-used Ultra-FGVC datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DHCNet, a Divide-and-Conquer Holistic Cognition Network for ultra-fine-grained visual categorization (Ultra-FGVC) under limited training data. It decomposes holistic cues into spatially-associated subtle discrepancies via progressive self-shuffling of local patches (small to large), uses guidance from unaffected regions to establish topological associations, incorporates online refinement of these cues, and employs them as supervisory signals to fine-tune the recognition model for improved sensitivity to holistic features across objects. The approach is claimed to achieve remarkable performance on five widely-used Ultra-FGVC datasets.
Significance. If the performance claims and the attribution to holistic cue modeling hold, the work would be significant for data-scarce fine-grained recognition tasks such as plant cultivar classification, where holistic morphological structures are discriminative but hard to learn without large datasets. It addresses an under-explored limitation in current Ultra-FGVC methods by simplifying holistic cognition through divide-and-conquer.
major comments (1)
- [Approach description (post-abstract technical paragraph)] The technical description of the self-shuffling operation on local regions combined with unaffected-region guidance (detailed in the approach paragraph following the abstract) provides no reconstruction objective, topological consistency loss, or verification mechanism to confirm that the derived supervisory signals recover true global holistic topology rather than re-assembled local statistics. This is load-bearing for the central claim that the strategy reduces training data dependency via reliable holistic cognition in high-similarity regimes; without it, performance gains cannot be confidently attributed to the proposed mechanism.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We address the major comment point by point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: The technical description of the self-shuffling operation on local regions combined with unaffected-region guidance (detailed in the approach paragraph following the abstract) provides no reconstruction objective, topological consistency loss, or verification mechanism to confirm that the derived supervisory signals recover true global holistic topology rather than re-assembled local statistics. This is load-bearing for the central claim that the strategy reduces training data dependency via reliable holistic cognition in high-similarity regimes; without it, performance gains cannot be confidently attributed to the proposed mechanism.
Authors: We agree that the high-level paragraph following the abstract does not explicitly introduce a reconstruction objective, topological consistency loss, or separate verification step. The approach instead relies on progressive self-shuffling (small-to-large patches) together with guidance from unaffected regions to establish spatial associations, followed by online refinement that iteratively improves cue quality before these cues are used as supervisory signals. This design intentionally simplifies holistic cognition rather than adding an auxiliary reconstruction task. Nevertheless, the referee is correct that the current description leaves the precise mechanism for recovering global topology somewhat implicit. We will therefore revise Section 3 to provide a clearer algorithmic description (including pseudocode) of how unaffected-region guidance and online refinement together constrain the derived signals, and we will add a targeted ablation that isolates the contribution of the holistic supervisory signals versus purely local re-assembly. These changes will make the attribution of performance gains more transparent while preserving the divide-and-conquer philosophy. revision: partial
Circularity Check
No circularity: purely descriptive method with no derivations or self-referential reductions
full rationale
The provided paper text consists entirely of a high-level description of the DHCNet architecture and its divide-and-conquer strategy, including operations such as self-shuffling on local regions and online refinement. No equations, first-principles derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or surrounding text. The central claims are framed as a proposed technical approach rather than a mathematical result that reduces to its own inputs by construction. This is the normal case of a self-contained empirical method description with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, and Mohammad Norouzi. 2021. Big Self-Supervised Models Advance Medical Image Classification. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, ...
2021
-
[2]
Editing conditional radiance fields
IEEE, 3458–3468. doi:10.1109/ICCV48922.2021.00346
-
[3]
Yuchen Che, Ryo Furukawa, and Asako Kanezaki. 2024. OP-Align: Object-Level and Part-Level Alignment for Self-supervised Category-Level Articulated Object Pose Estimation. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXXV (Lecture Notes in Computer Science, Vol. 15133), Ales Leonard...
2024
-
[4]
Qiupu Chen, Lin Jiao, Fenmei Wang, Jianming Du, Haiyun Liu, Xue Wang, and Rujing Wang. 2024. Integrating foreground-background feature distillation and contrastive feature learning for ultra-fine-grained visual classification.Pattern Recognit.150 (2024), 110339. doi:10.1016/J.PATCOG.2024.110339
-
[5]
Qi Chen, Lingxiao Yang, Jianhuang Lai, and Xiaohua Xie. 2022. Self-supervised Image-specific Prototype Exploration for Weakly Supervised Semantic Seg- mentation. InIEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 4278–4288. doi:10.1109/CVPR52688.2022.00425
-
[6]
Shi Chen and Qi Zhao. 2023. Divide and Conquer: Answering Questions with Object Factorization and Compositional Reasoning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. IEEE, 6736–6745. doi:10.1109/CVPR52729.2023.00651
-
[7]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. 2020. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119). PMLR, 1597–1607
2020
-
[9]
Junsuk Choe, Seungho Lee, and Hyunjung Shim. 2021. Attention-Based Dropout Layer for Weakly Supervised Single Object Localization and Semantic Seg- mentation.IEEE Trans. Pattern Anal. Mach. Intell.43, 12 (2021), 4256–4271. doi:10.1109/TPAMI.2020.2999099
-
[10]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Ima- geNet: A large-scale hierarchical image database. In2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA. IEEE Computer Society, 248–255. doi:10.1109/CVPR. 2009.5206848
-
[11]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In9th Interna- tional Conference on Learning Representations, IC...
2021
-
[12]
Linus Ericsson, Henry Gouk, and Timothy M. Hospedales. 2021. How Well Do Self-Supervised Models Transfer?. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. Computer Vision Foundation / IEEE, 5414–5423. doi:10.1109/CVPR46437.2021.00537
- [13]
-
[14]
Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Ávila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Ávila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. 2020. Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning. InAdvances in Neural Information Pr...
2020
-
[15]
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, and Dacheng Tao. 2024. A Survey on Self-Supervised Learning: Algorithms, Applications, and Future Trends.IEEE Trans. Pattern Anal. Mach. Intell.46, 12 (2024), 9052–9071. doi:10.1109/TPAMI.2024.3415112
-
[16]
Lanqing Guo, Chong Wang, Wenhan Yang, Yufei Wang, and Bihan Wen. 2023. Boundary-Aware Divide and Conquer: A Diffusion-based Solution for Un- supervised Shadow Removal. InIEEE/CVF International Conference on Com- puter Vision, ICCV 2023, Paris, France, October 1-6, 2023. IEEE, 12999–13008. doi:10.1109/ICCV51070.2023.01199
-
[17]
Ju He, Jieneng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, and Changhu Wang. 2022. TransFG: A Transformer Architecture for Fine-Grained Recognition. InThirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educat...
-
[18]
Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross B. Girshick. 2017. Mask R-CNN. InIEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEEE Computer Society, 2980–2988. doi:10.1109/ICCV. 2017.322
-
[19]
Xiangteng He and Yuxin Peng. 2017. Fine-Grained Image Classification via Combining Vision and Language. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 7332–7340. doi:10.1109/CVPR.2017.775
-
[20]
Rong-Xiang Hu, Wei Jia, Haibin Ling, and Deshuang Huang. 2012. Multiscale Distance Matrix for Fast Plant Leaf Recognition.IEEE Trans. Image Process.21, 11 (2012), 4667–4672
2012
-
[21]
Siyuan Huang, Yichen Xie, Song-Chun Zhu, and Yixin Zhu. 2021. Spatio-temporal Self-Supervised Representation Learning for 3D Point Clouds. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, 6515–6525. doi:10.1109/ICCV48922.2021.00647
- [22]
-
[23]
Chenyi Jiang, Shidong Wang, Yang Long, Zechao Li, Haofeng Zhang, and Ling Shao. 2025. Imaginary-Connected Embedding in Complex Space for Unseen Attribute-Object Discrimination.IEEE Trans. Pattern Anal. Mach. Intell.47, 3 (2025), 1395–1413
2025
-
[24]
Xin Jiang, Hao Tang, and Zechao Li. 2024. Global Meets Local: Dual Activation Hashing Network for Large-Scale Fine-Grained Image Retrieval.IEEE Trans. Knowl. Data Eng.36, 11 (2024), 6266–6279
2024
-
[25]
Gregory Kahn, Pieter Abbeel, and Sergey Levine. 2021. BADGR: An Autonomous Self-Supervised Learning-Based Navigation System.IEEE Robotics Autom. Lett.6, 2 (2021), 1312–1319. doi:10.1109/LRA.2021.3057023
-
[26]
Haibin Ling and David W. Jacobs. 2007. Shape Classification Using the Inner- Distance.IEEE Trans. Pattern Anal. Mach. Intell.29, 2 (2007), 286–299
2007
-
[27]
Yu Liu, Yaqi Cai, Qi Jia, Binglin Qiu, Weimin Wang, and Nan Pu. 2024. Novel Class Discovery for Ultra-Fine-Grained Visual Categorization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2024. IEEE, 17679–17688. doi:10.1109/CVPR52733.2024.01674
-
[28]
Yixin Liu, Ming Jin, Shirui Pan, Chuan Zhou, Yu Zheng, Feng Xia, and Philip S. Yu. 2023. Graph Self-Supervised Learning: A Survey.IEEE Trans. Knowl. Data Eng.35, 6 (2023), 5879–5900. doi:10.1109/TKDE.2022.3172903
-
[29]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, 9992–10002. doi:10.1109/ICCV48922.2021.00986
-
[30]
Ishan Misra and Laurens van der Maaten. 2020. Self-Supervised Learning of Pretext-Invariant Representations. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, W A, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 6706–6716. doi:10.1109/CVPR42600.2020. 00674
-
[31]
Zanlin Ni, Yulin Wang, Jiangwei Yu, Haojun Jiang, Yue Cao, and Gao Huang
-
[32]
Deep Incubation: Training Large Models by Divide-and-Conquering. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. IEEE, 17289–17299. doi:10.1109/ICCV51070.2023.01590
-
[33]
Zicheng Pan, Xiaohan Yu, Miaohua Zhang, and Yongsheng Gao. 2023. SSFE- Net: Self-Supervised Feature Enhancement for Ultra-Fine-Grained Few-Shot Class Incremental Learning. InIEEE/CVF Winter Conference on Applications of Computer Vision, W ACV 2023, Waikoloa, HI, USA, January 2-7, 2023. IEEE, 6264–
2023
-
[34]
doi:10.1109/WACV56688.2023.00621
-
[35]
Massimiliano Patacchiola and Amos J. Storkey. 2020. Self-Supervised Relational Reasoning for Representation Learning. InAdvances in Neural Information Pro- cessing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balca...
2020
-
[36]
Yuxin Peng, Xiangteng He, and Junjie Zhao. 2018. Object-Part Attention Model for Fine-Grained Image Classification.IEEE Trans. Image Process.27, 3 (2018), 1487–1500
2018
-
[37]
Matin Qaim. 2020. Role of new plant breeding technologies for food security and sustainable agricultural development.Applied Economic Perspectives and Policy 42, 2 (2020), 129–150
2020
-
[38]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Conference acronym ’XX, June 03–05, 2018, Woodstock, N...
2021
-
[39]
Artsiom Sanakoyeu, Pingchuan Ma, Vadim Tschernezki, and Björn Ommer. 2022. Improving Deep Metric Learning by Divide and Conquer.IEEE Trans. Pattern Anal. Mach. Intell.44, 11 (2022), 8306–8320. doi:10.1109/TPAMI.2021.3113270
-
[40]
Corentin Sautier, Gilles Puy, Spyros Gidaris, Alexandre Boulch, Andrei Bursuc, and Renaud Marlet. 2022. Image-to-Lidar Self-Supervised Distillation for Au- tonomous Driving Data. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 9881–9891. doi:10.1109/CVPR52688.2022.00966
-
[41]
Qi Song, Qingyong Hu, Chi Zhang, Yongquan Chen, and Rui Huang. 2024. Divide and Conquer: Improving Multi-Camera 3D Perception With 2D Semantic-Depth Priors and Input-Dependent Queries.IEEE Trans. Image Process.33 (2024), 897–
2024
-
[42]
doi:10.1109/TIP.2024.3352808
- [43]
-
[44]
Aiham Taleb, Winfried Loetzsch, Noel Danz, Julius Severin, Thomas Gärtner, Benjamin Bergner, and Christoph Lippert. 2020. 3D Self-Supervised Methods for Medical Imaging. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, Hugo Larochelle, Marc’...
2020
-
[45]
Mahendar Thudi, Ramesh Palakurthi, James C Schnable, Annapurna Chitikineni, Susanne Dreisigacker, Emma Mace, Rakesh K Srivastava, C Tara Satyavathi, Damaris Odeny, Vijay K Tiwari, et al. 2021. Genomic resources in plant breeding for sustainable agriculture.Journal of Plant Physiology257 (2021), 153351
2021
-
[46]
Yanling Tian, Di Chen, Yunan Liu, Jian Yang, and Shanshan Zhang. 2024. Divide and Conquer: Hybrid Pre-training for Person Search. InThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Inno- vative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intel...
-
[47]
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. Training data-efficient image transformers & distillation through attention. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event (Proceedings of Machine Learning Research, Vol. 139), Mar...
2021
-
[48]
Bin Wang and Yongsheng Gao. 2014. Hierarchical String Cuts: A Translation, Rotation, Scale, and Mirror Invariant Descriptor for Fast Shape Retrieval.IEEE Trans. Image Process.23, 9 (2014), 4101–4111
2014
-
[49]
Chengyao Wang, Li Jiang, Xiaoyang Wu, Zhuotao Tian, Bohao Peng, Hengshuang Zhao, and Jiaya Jia. 2024. GroupContrast: Semantic-Aware Self-Supervised Rep- resentation Learning for 3D Understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2024. IEEE, 4917–4928. doi:10.1109/CVPR52733.2024.00470
-
[50]
Yanhui Wang, Jianmin Bao, Wenming Weng, Ruoyu Feng, Dacheng Yin, Tao Yang, Jingxu Zhang, Qi Dai, Zhiyuan Zhao, Chunyu Wang, Kai Qiu, Yuhui Yuan, Xiaoyan Sun, Chong Luo, and Baining Guo. 2024. MicroCinema: A Divide-and- Conquer Approach for Text-to-Video Generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, W A, ...
2024
-
[51]
In: 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
IEEE, 8414–8424. doi:10.1109/CVPR52733.2024.00804
-
[52]
Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. 2020. Self- Supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, W A, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 12272–12281. doi:10.1109/CVPR42600.2020.01229
-
[53]
Zhenyu Wang, Enze Xie, Aoxue Li, Zhongdao Wang, Xihui Liu, and Zhenguo Li
-
[54]
arXiv preprint arXiv:2401.15688 (2024) 5
Divide and Conquer: Language Models can Plan and Self-Correct for Compo- sitional Text-to-Image Generation.CoRRabs/2401.15688 (2024). arXiv:2401.15688 doi:10.48550/ARXIV.2401.15688
-
[55]
Yunqian Wen, Bo Liu, Jingyi Cao, Rong Xie, and Li Song. 2023. Divide and Conquer: a Two-Step Method for High Quality Face De-identification with Model Explainability. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. IEEE, 5125–5134. doi:10.1109/ICCV51070. 2023.00475
-
[56]
Zhiliang Wu, Changchang Sun, Hanyu Xuan, Kang Zhang, and Yan Yan. 2023. Divide-and-Conquer Completion Network for Video Inpainting.IEEE Trans. Circuits Syst. Video Technol.33, 6 (2023), 2753–2766. doi:10.1109/TCSVT.2022. 3225911
-
[57]
Jie Xiao, Xueyang Fu, Man Zhou, Hongjian Liu, and Zheng-Jun Zha. 2023. Ran- dom Shuffle Transformer for Image Restoration. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceed- ings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato,...
2023
-
[58]
Haipeng Xiong, Hao Lu, Chengxin Liu, Liang Liu, Chunhua Shen, and Zhiguo Cao
-
[59]
From Open Set to Closed Set: Supervised Spatial Divide-and-Conquer for Object Counting.Int. J. Comput. Vis.131, 7 (2023), 1722–1740. doi:10.1007/S11263- 023-01782-1
-
[60]
Jinyu Yang, Jiali Duan, Son Tran, Yi Xu, Sampath Chanda, Liqun Chen, Belinda Zeng, Trishul Chilimbi, and Junzhou Huang. 2022. Vision-Language Pre-Training with Triple Contrastive Learning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 15650–15659. doi:10.1109/CVPR52688.2022.01522
-
[61]
Muli Yang, Yuehua Zhu, Jiaping Yu, Aming Wu, and Cheng Deng. 2022. Divide and Conquer: Compositional Experts for Generalized Novel Class Discovery. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 14248–14257. doi:10.1109/CVPR52688. 2022.01387
-
[62]
Zhengwei Yang, Meng Lin, Xian Zhong, Yu Wu, and Zheng Wang. 2023. Good is Bad: Causality Inspired Cloth-debiasing for Cloth-changing Person Re-identification. InIEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. IEEE, 1472–1481. doi:10.1109/CVPR52729.2023.00148
-
[63]
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiao- dan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. 2022. FILIP: Fine-grained Interactive Language-Image Pre-Training. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenRe- view.net
2022
-
[64]
Xiaohan Yu, Jun Wang, and Yongsheng Gao. 2023. CLE-ViT: Contrastive Learn- ing Encoded Transformer for Ultra-Fine-Grained Visual Categorization. InPro- ceedings of the Thirty-Second International Joint Conference on Artificial Intelli- gence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China. ijcai.org, 4531–4539. doi:10.24963/IJCAI.2023/504
-
[65]
Xiaohan Yu, Yang Zhao, and Yongsheng Gao. 2022. SPARE: Self-supervised part erasing for ultra-fine-grained visual categorization.Pattern Recognit.128 (2022), 108691. doi:10.1016/J.PATCOG.2022.108691
-
[66]
Xiaohan Yu, Yang Zhao, Yongsheng Gao, and Shengwu Xiong. 2021. MaskCOV: A random mask covariance network for ultra-fine-grained visual categorization. Pattern Recognit.119 (2021), 108067. doi:10.1016/J.PATCOG.2021.108067
-
[67]
Xiaohan Yu, Yang Zhao, Yongsheng Gao, Shengwu Xiong, and Xiaohui Yuan. 2020. Patchy Image Structure Classification Using Multi-Orientation Region Transform. InThe Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educa...
-
[68]
Xiaohan Yu, Yang Zhao, Yongsheng Gao, Xiaohui Yuan, and Shengwu Xiong
-
[69]
Editing conditional radiance fields
Benchmark Platform for Ultra-Fine-Grained Visual Categorization Beyond Human Performance. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, 10265–10275. doi:10.1109/ICCV48922.2021.01012
-
[70]
Dauphin, and David Lopez-Paz
Hongyi Zhang, Moustapha Cissé, Yann N. Dauphin, and David Lopez-Paz. 2018. mixup: Beyond Empirical Risk Minimization. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net
2018
-
[71]
Jiamin Zhuang, Jing Yu, Yang Ding, Xiangyan Qu, and Yue Hu. 2024. Towards Fast and Accurate Image-Text Retrieval With Self-Supervised Fine-Grained Alignment. IEEE Trans. Multim.26 (2024), 1361–1372. doi:10.1109/TMM.2023.3280734
-
[72]
Adrian Ziegler and Yuki M. Asano. 2022. Self-Supervised Learning of Object Parts for Semantic Segmentation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 14482–14491. doi:10.1109/CVPR52688.2022.01410
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.