Recognition: unknown
PanDA: Unsupervised Domain Adaptation for Multimodal 3D Panoptic Segmentation in Autonomous Driving
Pith reviewed 2026-05-10 02:09 UTC · model grok-4.3
The pith
PanDA is the first unsupervised domain adaptation framework for multimodal 3D panoptic segmentation in autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
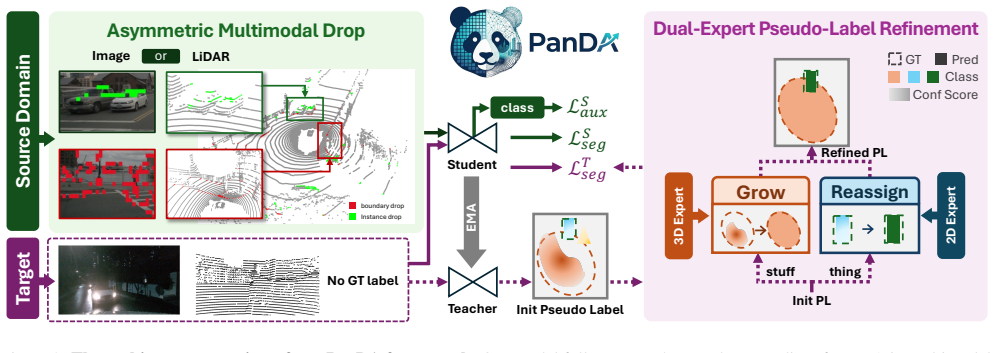
PanDA is the first UDA framework specifically designed for multimodal 3D panoptic segmentation. It improves robustness to single-modality degradation with an asymmetric multimodal augmentation that selectively drops regions to simulate domain shifts. It also produces more complete and reliable pseudo labels with a dual-expert refinement module that extracts domain-invariant priors from both 2D and 3D modalities. Experiments across diverse domain shifts in time, weather, location and sensors show consistent gains over state-of-the-art UDA baselines for 3D semantic segmentation.
What carries the argument
asymmetric multimodal augmentation that drops regions from one modality to simulate degradation, together with a dual-expert pseudo-label refinement module that merges 2D and 3D domain-invariant priors
Load-bearing premise
Existing multimodal 3D panoptic segmentation models are fragile when one sensor input degrades and conventional high-confidence pseudo-labeling produces fragmented masks, yet the proposed augmentation and dual-expert steps fix these issues without creating new failure modes.
What would settle it
Apply PanDA to a strong single-modality degradation shift such as camera failure in heavy fog and measure whether panoptic quality metrics remain higher than those from a plain high-confidence pseudo-label baseline.
Figures



read the original abstract
This paper presents the first study on Unsupervised Domain Adaptation (UDA) for multimodal 3D panoptic segmentation (mm-3DPS), aiming to improve generalization under domain shifts commonly encountered in real-world autonomous driving. A straightforward solution is to employ a pseudo-labeling strategy, which is widely used in UDA to generate supervision for unlabeled target data, combined with an mm-3DPS backbone. However, existing supervised mm-3DPS methods rely heavily on strong cross-modal complementarity between LiDAR and RGB inputs, making them fragile under domain shifts where one modality degrades (e.g., poor lighting or adverse weather). Moreover, conventional pseudo-labeling typically retains only high-confidence regions, leading to fragmented masks and incomplete object supervision, which are issues particularly detrimental to panoptic segmentation. To address these challenges, we propose PanDA, the first UDA framework specifically designed for multimodal 3D panoptic segmentation. To improve robustness against single-sensor degradation, we introduce an asymmetric multimodal augmentation that selectively drops regions to simulate domain shifts and improve robust representation learning. To enhance pseudo-label completeness and reliability, we further develop a dual-expert pseudo-label refinement module that extracts domain-invariant priors from both 2D and 3D modalities. Extensive experiments across diverse domain shifts, spanning time, weather, location, and sensor variations, significantly surpass state-of-the-art UDA baselines for 3D semantic segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PanDA, the first unsupervised domain adaptation (UDA) framework for multimodal 3D panoptic segmentation (mm-3DPS) in autonomous driving. It identifies that existing supervised mm-3DPS methods are fragile under single-modality degradation due to reliance on cross-modal complementarity, and that standard pseudo-labeling yields fragmented masks detrimental to panoptic tasks. PanDA introduces asymmetric multimodal augmentation (selectively dropping regions to simulate shifts) for robust representation learning and a dual-expert pseudo-label refinement module that extracts domain-invariant priors from 2D and 3D modalities. Extensive experiments across time, weather, location, and sensor domain shifts are claimed to significantly outperform state-of-the-art UDA baselines for 3D semantic segmentation.
Significance. If the quantitative results and ablations hold, this addresses a clear gap in UDA for panoptic segmentation, a task central to autonomous driving perception. The targeted modules directly map to identified weaknesses (fragility to modality drop and incomplete pseudo-labels), and the multi-shift evaluation protocol provides a useful benchmark. Credit is due for focusing on panoptic-specific issues rather than reducing to semantic segmentation and for the reproducible experimental design across diverse shifts.
major comments (2)
- [§3.2] §3.2 (Asymmetric Multimodal Augmentation): the mechanism for selective region dropping is described at a high level, but the manuscript does not specify how drop probabilities or region selection criteria are determined across different shift types (e.g., weather vs. sensor); without this, it is unclear whether the robustness gains are due to the asymmetry or to implicit hyperparameter tuning that could be replicated by stronger baselines.
- [§4.3] §4.3 and Table 4 (Dual-Expert Refinement Ablation): the panoptic quality (PQ) gains are attributed to the dual-expert module, yet the reported numbers show only marginal improvement in thing-class PQ under severe weather shifts; this weakens the central claim that the module reliably produces complete masks without introducing new fragmentation, and requires a per-class breakdown or failure-case analysis to confirm.
minor comments (3)
- [Abstract] Abstract: the superiority claim is stated only for 3D semantic segmentation baselines, while the paper targets panoptic segmentation; add a sentence clarifying whether panoptic metrics (PQ, SQ, RQ) also improve or if semantic mIoU is used as the primary proxy.
- [§5] §5 (Experiments): several tables report mean results over three runs but omit standard deviations; include error bars or variance to support the 'significantly surpass' claim.
- [Related Work] Related Work: recent multimodal UDA papers (post-2023) on LiDAR-camera fusion are under-cited; add 2-3 references to contextualize the novelty of the dual-expert design.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, recognition of the novelty in UDA for multimodal 3D panoptic segmentation, and recommendation for minor revision. The comments are constructive and we address each one below, committing to revisions that strengthen reproducibility and evidence.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Asymmetric Multimodal Augmentation): the mechanism for selective region dropping is described at a high level, but the manuscript does not specify how drop probabilities or region selection criteria are determined across different shift types (e.g., weather vs. sensor); without this, it is unclear whether the robustness gains are due to the asymmetry or to implicit hyperparameter tuning that could be replicated by stronger baselines.
Authors: We agree that §3.2 provides only a high-level description of the selective region dropping and that explicit details on probabilities and selection criteria per shift type are needed for full reproducibility. In the revised manuscript we will expand this section to specify the criteria (region selection based on modality-specific uncertainty and variance maps) and how probabilities are set differently for weather, sensor, time, and location shifts to simulate the corresponding degradations. We will also add an ablation isolating the asymmetric design against a symmetric counterpart to confirm that the robustness improvements derive from the asymmetry rather than generic tuning. revision: yes
-
Referee: [§4.3] §4.3 and Table 4 (Dual-Expert Refinement Ablation): the panoptic quality (PQ) gains are attributed to the dual-expert module, yet the reported numbers show only marginal improvement in thing-class PQ under severe weather shifts; this weakens the central claim that the module reliably produces complete masks without introducing new fragmentation, and requires a per-class breakdown or failure-case analysis to confirm.
Authors: We acknowledge that the thing-class PQ gains under severe weather shifts are marginal in the current Table 4 ablation and that this limits the strength of the claim about reliable mask completion. In the revised manuscript we will add a per-class PQ breakdown (separating thing and stuff categories) to Table 4 and include a short failure-case analysis with qualitative examples illustrating how the dual-expert module reduces fragmentation on challenging thing instances without introducing new errors. These additions will provide direct evidence supporting the module's contribution to pseudo-label completeness. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces PanDA as a methodological framework for unsupervised domain adaptation in multimodal 3D panoptic segmentation. It identifies limitations in prior pseudo-labeling and cross-modal methods (fragility to single-modality degradation and incomplete masks) and proposes asymmetric augmentation plus dual-expert refinement to address them. No mathematical derivations, equations, fitted parameters, or predictions appear in the text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on empirical motivation and component design rather than reducing to inputs by construction or self-referential fitting. This is a standard non-circular proposal of a new combination of techniques.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Domain shifts in autonomous driving commonly arise from variations in time, weather, location, and sensors, causing single-modality degradation.
- domain assumption Strong cross-modal complementarity is required by existing supervised mm-3DPS methods, making them fragile when one modality degrades.
Reference graph
Works this paper leans on
-
[1]
4d- former: Multimodal 4d panoptic segmentation
Ali Athar, Enxu Li, Sergio Casas, and Raquel Urtasun. 4d- former: Multimodal 4d panoptic segmentation. InProceed- ings of The 7th Conference on Robot Learning, pages 2151–
-
[2]
Behley, M
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall. SemanticKITTI: A Dataset for Se- mantic Scene Understanding of LiDAR Sequences. InProc. of the IEEE/CVF International Conf. on Computer Vision (ICCV), 2019. 6
2019
-
[3]
Behley, M
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, J. Gall, and C. Stachniss. Towards 3D LiDAR-based semantic scene understanding of 3D point cloud sequences: The Se- manticKITTI Dataset.The International Journal on Robotics Research, 40(8-9):959–967, 2021. 6
2021
-
[4]
Unsupervised domain adaptation for lidar panoptic segmentation.IEEE Robotics and Automation Letters, 7(2): 3404–3411, 2022
Borna Besic, Nikhil Gosala, Daniele Cattaneo, and Abhinav Valada. Unsupervised domain adaptation for lidar panoptic segmentation.IEEE Robotics and Automation Letters, 7(2): 3404–3411, 2022. 2
2022
-
[5]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020. 6
2020
-
[6]
A computational approach to edge detection
John Canny. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, PAMI-8(6):679–698, 1986. 4
1986
-
[7]
Pasco: Urban 3d panoptic scene completion with uncertainty aware- ness
Anh-Quan Cao, Angela Dai, and Raoul de Charette. Pasco: Urban 3d panoptic scene completion with uncertainty aware- ness. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024. 1
2024
-
[8]
Mopa: Multi-modal prior aided domain adaptation for 3d semantic segmentation
Haozhi Cao, Yuecong Xu, Jianfei Yang, Pengyu Yin, Sheng- hai Yuan, and Lihua Xie. Mopa: Multi-modal prior aided domain adaptation for 3d semantic segmentation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 9463–9470, 2024. 2, 5
2024
-
[9]
Exploiting the complementarity of 2d and 3d networks to address domain-shift in 3d semantic segmentation
Adriano Cardace, Pierluigi Zama Ramirez, Samuele Salti, and Luigi Di Stefano. Exploiting the complementarity of 2d and 3d networks to address domain-shift in 3d semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 98–109,
-
[10]
Cmt: Co-training mean-teacher for unsupervised domain adapta- tion on 3d object detection
Shijie Chen, Junbao Zhuo, Xin Li, Haizhuang Liu, Rongquan Wang, Jiansheng Chen, and Huimin Ma. Cmt: Co-training mean-teacher for unsupervised domain adapta- tion on 3d object detection. InProceedings of the 32nd ACM International Conference on Multimedia, page 4738–4747,
-
[11]
Cross-modal & cross- domain learning for unsupervised lidar semantic segmenta- tion
Yiyang Chen, Shanshan Zhao, Changxing Ding, Liyao Tang, Chaoyue Wang, and Dacheng Tao. Cross-modal & cross- domain learning for unsupervised lidar semantic segmenta- tion. InProceedings of the 31st ACM International Confer- ence on Multimedia, page 3866–3875, 2023. 2
2023
-
[12]
Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking
Whye Kit Fong, Rohit Mohan, Juana Valeria Hurtado, Lub- ing Zhou, Holger Caesar, Oscar Beijbom, and Abhinav Val- ada. Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking. InIEEE International Conference on Robotics and Automation (ICRA), 2022. 6
2022
-
[13]
Yinjuan Gu, Yuming Huang, Chengzhong Xu, and Hui Kong. Maskrange: A mask-classification model for range- view based lidar segmentation.ArXiv, abs/2206.12073,
-
[14]
Dual-perspective knowledge enrichment for semi-supervised 3d object detection
Yucheng Han, Na Zhao, Weiling Chen, Keng Teck Ma, and Hanwang Zhang. Dual-perspective knowledge enrichment for semi-supervised 3d object detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2049– 2057, 2024. 3
2049
-
[15]
LiDAR-based Panoptic Segmentation via Dy- namic Shifting Network
Fangzhou Hong, Hui Zhou, Xinge Zhu, Hongsheng Li, and Ziwei Liu. LiDAR-based Panoptic Segmentation via Dy- namic Shifting Network. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13085–13094, Nashville, TN, USA, 2021. IEEE. 2
2021
-
[16]
Mic: Masked image consistency for context-enhanced domain adaptation
Lukas Hoyer, Dengxin Dai, Haoran Wang, and Luc Van Gool. Mic: Masked image consistency for context-enhanced domain adaptation. 2, 4
-
[17]
Density-insensitive unsupervised domain adaption on 3d object detection
Qianjiang Hu, Daizong Liu, and Wei Hu. Density-insensitive unsupervised domain adaption on 3d object detection. In 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 17556–17566. IEEE. 2
2023
-
[18]
xMUDA: Cross-modal unsuper- vised domain adaptation for 3D semantic segmentation
Maximilian Jaritz, Tuan-Hung Vu, Raoul de Charette, Emilie Wirbel, and Patrick P ´erez. xMUDA: Cross-modal unsuper- vised domain adaptation for 3D semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, 2020. 2, 3, 5, 6, 7
2020
-
[19]
Cross-modal learning for domain adaptation in 3D semantic segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Maximilian Jaritz, Tuan-Hung Vu, Raoul de Charette, Emilie Wirbel, and Patrick P´erez. Cross-modal learning for domain adaptation in 3D semantic segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022. 5, 6
2022
-
[20]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.Computer Science Research Repos- itory, abs/1412.6980, 2014. 6
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
Girshick, Carsten Rother, and Piotr Doll ´ar
Alexander Kirillov, Kaiming He, Ross B. Girshick, Carsten Rother, and Piotr Doll ´ar. Panoptic segmentation.2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9396–9405, 2018. 6
2019
-
[22]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. In2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 3992–4003, 2023. 3, 5
2023
-
[23]
Largead: Large-scale cross-sensor data pretraining for au- tonomous driving, 2025
Lingdong Kong, Xiang Xu, Youquan Liu, Jun Cen, Runnan Chen, Wenwei Zhang, Liang Pan, Kai Chen, and Ziwei Liu. Largead: Large-scale cross-sensor data pretraining for au- tonomous driving, 2025. 5
2025
-
[24]
Lion-xa: Unsupervised domain adapta- tion via lidar-only cross-modal adversarial training
Thomas Kreutz, Jens Lemke, Max M ¨uhlh¨auser, and Alejan- dro Sanchez Guinea. Lion-xa: Unsupervised domain adapta- tion via lidar-only cross-modal adversarial training. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8875–8881. 2
-
[25]
Jinke Li, Xiao He, Yang Wen, Yuan Gao, Xiaoqiang Cheng, and Dan Zhang. Panoptic-phnet: Towards real-time and high-precision lidar panoptic segmentation via clustering pseudo heatmap.2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 11799– 11808, 2022. 2
2022
-
[26]
End-to-end semi-supervised 3d instance segmentation with pcteacher
Linfeng Li and Na Zhao. End-to-end semi-supervised 3d instance segmentation with pcteacher. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 5352–5358. IEEE, 2024. 3
2024
-
[27]
Unsupervised do- main adaptation for monocular 3d object detection via self- training
Zhenyu Li, Zehui Chen, Ang Li, Liangji Fang, Qinhong Jiang, Xianming Liu, and Junjun Jiang. Unsupervised do- main adaptation for monocular 3d object detection via self- training. InEuropean Conference on Computer Vision, pages 245–262. 4
-
[28]
Unidxmd: Towards unified represen- tation for cross-modal unsupervised domain adaptation in 3d semantic segmentation
Zhengyin Liang, Hui Yin, Min Liang, Qianqian Du, Ying Yang, and Hua Huang. Unidxmd: Towards unified represen- tation for cross-modal unsupervised domain adaptation in 3d semantic segmentation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 20346– 20356. 2
-
[29]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023. 5
work page internal anchor Pith review arXiv 2023
-
[30]
Dualcross: Cross-modality cross-domain adaptation for monocular bev perception
Yunze Man, Liangyan Gui, and Yu-Xiong Wang. Dualcross: Cross-modality cross-domain adaptation for monocular bev perception. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10910–10917,
-
[31]
Language-guided instance-aware domain-adaptive panoptic segmentation
Elham Amin Mansour, Ozan Unal, Suman Saha, Benjamin Bejar, and Luc Van Gool. Language-guided instance-aware domain-adaptive panoptic segmentation. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV), 2025. 2
2025
-
[32]
Marcuzzi, L
R. Marcuzzi, L. Nunes, L. Wiesmann, J. Behley, and C. Stachniss. Mask-Based Panoptic LiDAR Segmentation for Autonomous Driving. 8(2):1141–1148, 2023. 2
2023
-
[33]
Mc-panda: Mask confidence for panoptic domain adaptation
Ivan Martinovi ´c, Josip ˇSari´c, and Siniˇsa ˇSegvi´c. Mc-panda: Mask confidence for panoptic domain adaptation. InEuro- pean Conference on Computer Vision, page 167–185, 2024. 2
2024
-
[34]
How do images align and complement lidar? towards a harmonized multi-modal 3d panoptic segmentation
Yining Pan, Qiongjie Cui, Xulei Yang, and Na Zhao. How do images align and complement lidar? towards a harmonized multi-modal 3d panoptic segmentation. InProceedings of the 42st International Conference on Machine Learning, 2025. 1, 2, 3, 4, 6
2025
-
[35]
Learning to adapt sam for segmenting cross-domain point clouds
Xidong Peng, Runnan Chen, Feng Qiao, Lingdong Kong, Youquan Liu, Yujing Sun, Tai Wang, Xinge Zhu, and Yuexin Ma. Learning to adapt sam for segmenting cross-domain point clouds. InEuropean Conference on Computer Vision, page 54–71, 2024. 2
2024
-
[36]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 6
2021
-
[37]
Gp-s3net: Graph-based panop- tic sparse semantic segmentation network.2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 16056–16065, 2021
Ryan Razani, Ran Cheng, Enxu Li, Ehsan Moeen Taghavi, Yuan Ren, and Bingbing Liu. Gp-s3net: Graph-based panop- tic sparse semantic segmentation network.2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 16056–16065, 2021. 2
2021
-
[38]
Edaps: Enhanced domain-adaptive panoptic segmentation
Suman Saha, Lukas Hoyer, Anton Obukhov, Dengxin Dai, and Luc Van Gool. Edaps: Enhanced domain-adaptive panoptic segmentation. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 19177– 19188, 2023. 2
2023
-
[39]
Cosmix: Compositional semantic mix for domain adaptation in 3d lidar segmenta- tion
Cristiano Saltori, Fabio Galasso, Giuseppe Fiameni, Nicu Sebe, Elisa Ricci, and Fabio Poiesi. Cosmix: Compositional semantic mix for domain adaptation in 3d lidar segmenta- tion. InEuropean Conference on Computer Vision, pages 586–602, 2022. 3
2022
-
[40]
Mm-tta: Multi-modal test-time adaptation for 3d semantic segmentation
Inkyu Shin, Yi-Hsuan Tsai, Bingbing Zhuang, Samuel Schulter, Buyu Liu, Sparsh Garg, In So Kweon, and Kuk- Jin Yoon. Mm-tta: Multi-modal test-time adaptation for 3d semantic segmentation. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16907–16916. IEEE, 2022. 2, 3
2022
-
[41]
Raychaudhuri, Sk Miraj Ahmed, Suya You, Konstantinos Karydis, and Amit K
Cody Simons, Dripta S. Raychaudhuri, Sk Miraj Ahmed, Suya You, Konstantinos Karydis, and Amit K. Roy- Chowdhury. Summit: Source-free adaptation of uni-modal models to multi-modal targets. In2023 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 1239–
-
[42]
Efficientlps: Efficient lidar panoptic segmentation.IEEE Transactions on Robotics, 38: 1894–1914, 2021
Kshitij Sirohi, Rohit Mohan, Daniel Buscher, Wolfram Bur- gard, and Abhinav Valada. Efficientlps: Efficient lidar panoptic segmentation.IEEE Transactions on Robotics, 38: 1894–1914, 2021. 2
1914
-
[43]
Panoptic-fusionnet: Camera-lidar fusion-based point cloud panoptic segmentation for autonomous driving.Ex- pert Syst
Hamin Song, Jieun Cho, Jinsu Ha, Jaehyun Park, and Kichun Jo. Panoptic-fusionnet: Camera-lidar fusion-based point cloud panoptic segmentation for autonomous driving.Ex- pert Syst. Appl., 251(C), 2024. 1, 2, 6
2024
-
[44]
Jehanzeb Mirza
Johannes Spoecklberger, Wei Lin, Pedro Hermosilla, Sivan Doveh, Horst Possegger, and M. Jehanzeb Mirza. Explor- ing modality guidance to enhance vfm-based feature fusion for uda in 3d semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4798–4807. 2
-
[45]
Johannes Spoecklberger, Wei Lin, Pedro Hermosilla, Sivan Doveh, Horst Possegger, and M. Mirza. Exploring modality guidance to enhance vfm-based feature fusion for uda in 3d semantic segmentation. pages 4789–4798, 2025. 2
2025
-
[46]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. InProceedings of the 31st International Conference on Neural Information Pro- cessing Systems, page 1195–1204, 2017. 2
2017
-
[47]
Affordbot: 3d fine-grained embodied reason- ing via multimodal large language models
Xinyi Wang, Xun Yang, Yanlong Xu, Yuchen Wu, Zhen Li, and Na Zhao. Affordbot: 3d fine-grained embodied reason- ing via multimodal large language models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. 1
2025
-
[48]
Syn-to-real un- supervised domain adaptation for indoor 3d object detection
Yunsong Wang, Na Zhao, and Gim Hee Lee. Syn-to-real un- supervised domain adaptation for indoor 3d object detection. InBritish Machine Vision Conference, 2024. 2
2024
-
[49]
Cross-modal unsu- pervised domain adaptation for 3d semantic segmentation via bidirectional fusion-then-distillation
Yao Wu, Mingwei Xing, Yachao Zhang, Yuan Xie, Jianping Fan, Zhongchao Shi, and Yanyun Qu. Cross-modal unsu- pervised domain adaptation for 3d semantic segmentation via bidirectional fusion-then-distillation. InProceedings of the 31st ACM International Conference on Multimedia, page 490–498, 2023. 2
2023
-
[50]
Unidseg: Unified cross-domain 3d semantic segmentation via visual foundation models prior
Yao Wu, Mingwei Xing, Yachao Zhang, Xiaotong Luo, Yuan Xie, and Yanyun Qu. Unidseg: Unified cross-domain 3d semantic segmentation via visual foundation models prior. In Proceedings of the 38th International Conference on Neural In- formation Processing Systems, 2024. 2, 5, 6, 7
2024
-
[51]
Position-Guided Point Cloud Panoptic Segmentation Transformer.International Journal of Computer Vision, 133(1):275–290, 2025
Zeqi Xiao, Wenwei Zhang, Tai Wang, Chen Change Loy, Dahua Lin, and Jiangmiao Pang. Position-Guided Point Cloud Panoptic Segmentation Transformer.International Journal of Computer Vision, 133(1):275–290, 2025. 2, 6
2025
-
[52]
Cross-modal contrastive learning for domain adaptation in 3d semantic segmentation.Proceedings of the AAAI Conference on Artificial Intelligence, 37(3):2974– 2982, 2023
Bowei Xing, Xianghua Ying, Ruibin Wang, Jinfa Yang, and Taiyan Chen. Cross-modal contrastive learning for domain adaptation in 3d semantic segmentation.Proceedings of the AAAI Conference on Artificial Intelligence, 37(3):2974– 2982, 2023. 2
2023
-
[53]
Visual foundation models boost cross-modal unsupervised domain adaptation for 3d semantic segmenta- tion.IEEE Transactions on Intelligent Transportation Sys- tems, pages 1–15, 2025
Jingyi Xu, Weidong Yang, Lingdong Kong, Youquan Liu, Qingyuan Zhou, Rui Zhang, Zhijun Li, Wen-Ming Chen, and Ben Fei. Visual foundation models boost cross-modal unsupervised domain adaptation for 3d semantic segmenta- tion.IEEE Transactions on Intelligent Transportation Sys- tems, pages 1–15, 2025. 2, 3
2025
-
[54]
Sparse cross-scale attention network for ef- ficient lidar panoptic segmentation
Shuangjie Xu, Rui Wan, Maosheng Ye, Xiaoyi Zou, and Tongyi Cao. Sparse cross-scale attention network for ef- ficient lidar panoptic segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2920– 2928, 2022. 2
2022
-
[55]
Aop-net: All-in-one perception network for lidar-based joint 3d object detection and panoptic segmentation
Yixuan Xu, Hamidreza Fazlali, Yuan Ren, and Bingbing Liu. Aop-net: All-in-one perception network for lidar-based joint 3d object detection and panoptic segmentation. In2023 IEEE Intelligent Vehicles Symposium (IV), pages 1–7, 2023. 2
2023
-
[56]
4d panoptic scene graph generation
Jingkang Yang, Jun Cen, Wenxuan Peng, Shuai Liu, Fangzhou Hong, Xiangtai Li, Kaiyang Zhou, Qifeng Chen, and Ziwei Liu. 4d panoptic scene graph generation. InPro- ceedings of the 37th International Conference on Neural In- formation Processing Systems, 2023. 1
2023
-
[57]
Micdrop: Masking image and depth features via complementary dropout for domain- adaptive semantic segmentation
Linyan Yang, Lukas Hoyer, Mark Weber, Tobias Fischer, Dengxin Dai, Laura Leal-Taix ´e, Marc Pollefeys, Daniel Cremers, and Luc Van Gool. Micdrop: Masking image and depth features via complementary dropout for domain- adaptive semantic segmentation. InEuropean Conference on Computer Vision, pages 329–346. 2025. 2, 4
2025
-
[58]
Sam-guided pseudo label enhancement for multi-modal 3d semantic seg- mentation
Mingyu Yang, Jitong Lu, and Hun-Seok Kim. Sam-guided pseudo label enhancement for multi-modal 3d semantic seg- mentation. pages 11133–11140, 2025. 3
2025
-
[59]
Lidarmultinet: to- wards a unified multi-task network for lidar perception
Dongqiangzi Ye, Zixiang Zhou, Weijia Chen, Yufei Xie, Yu Wang, Panqu Wang, and Hassan Foroosh. Lidarmultinet: to- wards a unified multi-task network for lidar perception. In Proceedings of the Thirty-Seventh AAAI Conference on Arti- ficial Intelligence, 2023. 2
2023
-
[60]
Mx2m: Masked cross-modality modeling in domain adaptation for 3d se- mantic segmentation
Boxiang Zhang, Zunran Wang, Yonggen Ling, Yuanyuan Guan, Shenghao Zhang, and Wenhui Li. Mx2m: Masked cross-modality modeling in domain adaptation for 3d se- mantic segmentation. InProceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, pages 3401– 3409, 2023. 2, 4
2023
-
[61]
Self-supervised ex- clusive learning for 3d segmentation with cross-modal unsu- pervised domain adaptation
Yachao Zhang, Miaoyu Li, Yuan Xie, Cuihua Li, Cong Wang, Zhizhong Zhang, and Yanyun Qu. Self-supervised ex- clusive learning for 3d segmentation with cross-modal unsu- pervised domain adaptation. InProceedings of the 30th ACM International Conference on Multimedia, page 3338–3346,
-
[62]
Pseudo label refinery for unsupervised do- main adaptation on cross-dataset 3d object detection
Zhanwei Zhang, Minghao Chen, Shuai Xiao, Liang Peng, Hengjia Li, Binbin Lin, Ping Li, Wenxiao Wang, Boxi Wu, and Deng Cai. Pseudo label refinery for unsupervised do- main adaptation on cross-dataset 3d object detection. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15291–15300. 2
-
[63]
Lidar-camera panoptic segmenta- tion via geometry-consistent and semantic-aware alignment
Zhiwei Zhang, Zhizhong Zhang, Qian Yu, Ran Yi, Yuan Xie, and Lizhuang Ma. Lidar-camera panoptic segmenta- tion via geometry-consistent and semantic-aware alignment. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3662–3671, 2023. 1, 2, 6
2023
-
[64]
Dong Zhao, Qi Zang, Nan Pu, Shuang Wang, Nicu Sebe, and Zhun Zhong. Secov2: Semantic connectivity-driven pseudo-labeling for robust cross-domain semantic segmen- tation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(11):10378–10395, 2025. 3
2025
-
[65]
Sess: Self- ensembling semi-supervised 3d object detection
Na Zhao, Tat-Seng Chua, and Gim Hee Lee. Sess: Self- ensembling semi-supervised 3d object detection. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11079–11087, 2020. 3
2020
-
[66]
Panoptic- PolarNet: Proposal-free LiDAR Point Cloud Panoptic Seg- mentation
Zixiang Zhou, Yang Zhang, and Hassan Foroosh. Panoptic- PolarNet: Proposal-free LiDAR Point Cloud Panoptic Seg- mentation . In2021 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 13189–13198,
-
[67]
Segment everything everywhere all at once
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. InPro- ceedings of the 37th International Conference on Neural In- formation Processing Systems, 2023. 3
2023
-
[68]
Col- laborative tree search for enhancing embodied multi-agent collaboration
Lizheng Zu, Lin Lin, Song Fu, Na Zhao, and Pan Zhou. Col- laborative tree search for enhancing embodied multi-agent collaboration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29513–29522, 2025. 1
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.