Recognition: unknown
CASCADE: Detecting Inconsistencies between Code and Documentation with Automatic Test Generation
Pith reviewed 2026-05-10 02:43 UTC · model grok-4.3
The pith
CASCADE reports code-documentation inconsistencies only when tests from the docs fail on the real code but pass on code generated from the docs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An inconsistency is reported only when two conditions are met: the existing code fails a test, while the code generated from the documentation passes the same test.
What carries the argument
The dual-execution verification step that requires tests derived from documentation to fail on the actual implementation yet succeed on documentation-derived code.
If this is right
- The approach can be applied across Java, C#, and Rust codebases to surface maintenance issues.
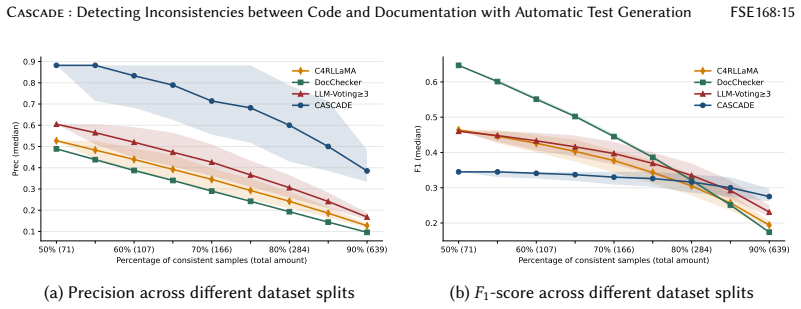
- On a dataset of 71 inconsistent and 814 consistent pairs it demonstrated usable precision.
- Real-world use on open-source repositories uncovered 13 new inconsistencies, 10 of which were fixed.
- The precision focus aims to make automated reports practical enough for routine developer adoption.
Where Pith is reading between the lines
- If LLM quality continues to improve, the same dual-check pattern could extend to larger or more complex documentation without added human review.
- Embedding the technique in continuous-integration pipelines would let teams catch drift as soon as documentation or code changes.
- Analogous dual-verification ideas might transfer to other forms of specification such as API contracts or inline comments.
Load-bearing premise
LLM-generated tests and code from natural-language documentation accurately and completely capture the intended behavior without introducing their own errors or omissions.
What would settle it
A concrete set of code-documentation pairs where the method reports inconsistencies that manual inspection shows do not exist, or where it misses known real inconsistencies.
Figures




read the original abstract
Maintaining consistency between code and documentation is a crucial yet frequently overlooked aspect of software development. Even minor mismatches can confuse API users, introduce new bugs, and increase overall maintenance effort. This creates demand for automated solutions that can assist developers in identifying code-documentation inconsistencies. However, since automatic reports still require human confirmation, false positives carry serious consequences: wasting developer time and discouraging practical adoption. We introduce CASCADE (Consistency Analysis for Source Code And Documentation through Execution), a novel tool for detecting inconsistencies with a strong emphasis on reducing false positives. CASCADE leverages Large Language Models (LLMs) to generate unit tests directly from natural-language documentation. Since these tests are derived from the documentation, any failure during execution indicates a potential mismatch between the documented and actual behavior of the code. To minimize false positives, CASCADE also generates code from the documentation to cross-check the generated tests. By design, an inconsistency is reported only when two conditions are met: the existing code fails a test, while the code generated from the documentation passes the same test. We evaluated CASCADE on a novel dataset of 71 inconsistent and 814 consistent code-documentation pairs drawn from open-source Java projects. Further, we applied CASCADE to additional Java, C#, and Rust repositories, where we uncovered 13 previously unknown inconsistencies, of which 10 have subsequently been fixed, demonstrating both CASCADE's precision and its applicability to real-world codebases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CASCADE, a tool that leverages LLMs to generate unit tests directly from natural-language documentation. Inconsistencies are reported only when the existing code fails such a test while an LLM-generated implementation from the same documentation passes it. The approach is evaluated on a novel dataset of 71 inconsistent and 814 consistent code-documentation pairs from open-source Java projects and applied to additional Java, C#, and Rust repositories, where it identified 13 previously unknown inconsistencies (10 subsequently fixed).
Significance. If the cross-check reliably filters false positives without introducing correlated LLM errors, the work would offer a practical advance in automated consistency checking between code and documentation, addressing a common maintenance pain point. The real-world findings with confirmed fixes provide initial evidence of utility beyond synthetic datasets. However, the absence of detailed validation on test quality, false-positive rates on consistent pairs, and baselines limits the strength of the precision claims.
major comments (3)
- [Evaluation] Evaluation section (dataset and results): the central claim that the cross-check reduces false positives rests on the assumption that LLM-generated tests and code do not share misinterpretations of ambiguous documentation. No ablation or analysis isolates cases of correlated errors (e.g., underspecified edge cases), and the evaluation on the 71 inconsistent pairs does not report how many would have been falsely triggered by such shared misreadings. The 814 consistent pairs likewise lack reported false-positive rates or validation of test correctness.
- [Approach] Approach description: the two-condition reporting rule (existing code fails test, generated code passes) is presented as sufficient to minimize false positives, but no quantitative assessment of LLM prompt sensitivity or documentation ambiguity is provided. This is load-bearing because the method has no independent oracle for test fidelity.
- [Real-world evaluation] Real-world application: while 13 inconsistencies were reported with 10 fixes, the manuscript provides no count of total checks performed, false positives encountered, or developer confirmation effort, preventing assessment of precision in practice.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief example showing a generated test, the generated code, and the failing original code to illustrate the cross-check.
- [Related work] No comparison to prior inconsistency-detection tools or baselines (e.g., static analysis or simpler LLM prompting) is included, which would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments on our manuscript. We have carefully considered each point and provide point-by-point responses below, along with our plans for revisions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (dataset and results): the central claim that the cross-check reduces false positives rests on the assumption that LLM-generated tests and code do not share misinterpretations of ambiguous documentation. No ablation or analysis isolates cases of correlated errors (e.g., underspecified edge cases), and the evaluation on the 71 inconsistent pairs does not report how many would have been falsely triggered by such shared misreadings. The 814 consistent pairs likewise lack reported false-positive rates or validation of test correctness.
Authors: We agree that this is a key assumption underlying our approach and that the evaluation would be strengthened by an analysis of potential correlated errors. The manuscript does not include an ablation study or report the number of the 71 inconsistent pairs that might have been affected by shared LLM misinterpretations of ambiguous documentation. Similarly, false-positive rates on the 814 consistent pairs and independent validation of test correctness are not reported. We will revise the evaluation section to explicitly discuss this assumption and its implications. Additionally, we will include a manual analysis of a sample from the dataset to assess the likelihood of such correlated errors. A full quantitative ablation study may be beyond the scope of this revision but will be noted as future work. revision: partial
-
Referee: [Approach] Approach description: the two-condition reporting rule (existing code fails test, generated code passes) is presented as sufficient to minimize false positives, but no quantitative assessment of LLM prompt sensitivity or documentation ambiguity is provided. This is load-bearing because the method has no independent oracle for test fidelity.
Authors: The two-condition rule is meant to mitigate false positives by requiring that the LLM-generated implementation from the documentation passes the test derived from the same documentation. This should catch cases where the documentation is ambiguous or misinterpreted, as the generated code would then fail the test. We acknowledge the lack of quantitative assessment regarding prompt sensitivity and documentation ambiguity. We will add to the approach section (or a new subsection) results from experiments varying the LLM prompts on a subset of the data to demonstrate the stability of the method. revision: yes
-
Referee: [Real-world evaluation] Real-world application: while 13 inconsistencies were reported with 10 fixes, the manuscript provides no count of total checks performed, false positives encountered, or developer confirmation effort, preventing assessment of precision in practice.
Authors: We agree that providing these details would help readers assess the practical utility and precision of CASCADE. The real-world application section reports the inconsistencies found and the fixes, but does not include the total number of pairs checked or a full accounting of false positives and confirmation effort. We will revise this section to report the total checks performed and any available information on false positives encountered and the developer confirmation process. revision: yes
- Specific quantification of how many of the 71 inconsistent pairs might be due to correlated errors, as this was not analyzed.
- False-positive rates on the 814 consistent pairs and full validation of test correctness.
Circularity Check
No circularity: empirical heuristic with external evaluation
full rationale
The paper presents CASCADE as an operational procedure: LLM-generated tests from documentation are executed against both the original code and an LLM-generated implementation from the same documentation; an inconsistency is reported only on the conjunction of failure on original code and success on generated code. This definition is stated directly in the abstract without equations, fitted parameters, or predictions that reduce to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes appear in the provided text. Evaluation uses a novel external dataset of 71 inconsistent pairs plus real-world repositories, making the claims falsifiable outside any internal loop. The potential for correlated LLM misinterpretations is a correctness risk, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can translate natural-language documentation into correct unit tests and equivalent code implementations
Reference graph
Works this paper leans on
-
[1]
Saranya Alagarsamy, Chakkrit Tantithamthavorn, Wannita Takerngsaksiri, Chetan Arora, and Aldeida Aleti. 2025. Enhancing large language models for text-to-testcase generation.J. Syst. Softw.230 (2025), 112531. doi:10.1016/J.JSS. 2025.112531
-
[2]
Ernst, Mauro Pezzè, and Sergio Del- gado Castellanos
Arianna Blasi, Alberto Goffi, Konstantin Kuznetsov, Alessandra Gorla, Michael D. Ernst, Mauro Pezzè, and Sergio Del- gado Castellanos. 2018. Translating code comments to procedure specifications. InProceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2018, Amsterdam, The Netherlands, July 16-21, 2018, Frank T...
-
[3]
Ravishankar Boddu, Lan Guo, Supratik Mukhopadhyay, and Bojan Cukic. 2004. RETNA: From Requirements to Testing in a Natural Way. In12th IEEE International Conference on Requirements Engineering (RE 2004), 6-10 September 2004, Kyoto, Japan. IEEE Computer Society, 262–271. doi:10.1109/RE.2004.46
-
[4]
Gustavo Carvalho, Diogo Falcão, Flávia de Almeida Barros, Augusto Sampaio, Alexandre Mota, Leonardo Motta, and Mark R. Blackburn. 2014. NAT2TESTSCR: Test case generation from natural language requirements based on SCR specifications.Sci. Comput. Program.95 (2014), 275–297. doi:10.1016/J.SCICO.2014.06.007
-
[5]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2023. CodeT: Code Generation with Generated Tests. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/forum?id=ktrw68Cmu9c
2023
-
[6]
Rudrajit Choudhuri, Bianca Trinkenreich, Rahul Pandita, Eirini Kalliamvakou, Igor Steinmacher, Marco Aurélio Gerosa, Christopher Sanchez, and Anita Sarma. 2025. What Guides Our Choices? Modeling Developers’ Trust and Behavioral Intentions Towards Genai. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April ...
-
[7]
Roland Croft, Dominic Newlands, Ziyu Chen, and Muhammad Ali Babar. 2021. An Empirical Study of Rule-Based and Learning-Based Approaches for Static Application Security Testing. InESEM ’21: ACM / IEEE International Symposium on Empirical Software Engineering and Measurement, Bari, Italy, October 11-15, 2021, Filippo Lanubile, Marcos Kalinowski, and Maria T...
-
[8]
Anh T. V. Dau, Nghi D. Q. Bui, and Jin L. C. Guo. 2023. Bootstrapping Code-Text Pretrained Language Model to Detect Inconsistency Between Code and Comment.CoRRabs/2306.06347 (2023). arXiv:2306.06347 doi:10.48550/ARXIV.2306. 06347
-
[9]
de Souza, Nicolas Anquetil, and Káthia Marçal de Oliveira
Sergio Cozzetti B. de Souza, Nicolas Anquetil, and Káthia Marçal de Oliveira. 2005. A study of the documentation essential to software maintenance. InProceedings of the 23rd Annual International Conference on Design of Communica- tion: documenting & Designing for Pervasive Information, SIGDOC 2005, Coventry, UK, September 21-23, 2005, Scott R. Tilley and ...
-
[10]
Jannik Fischbach, Julian Frattini, Andreas Vogelsang, Daniel Méndez, Michael Unterkalmsteiner, Andreas Wehrle, Pablo Restrepo Henao, Parisa Yousefi, Tedi Juricic, Jeannette Radduenz, and Carsten Wiecher. 2023. Automatic creation of acceptance tests by extracting conditionals from requirements: NLP approach and case study.J. Syst. Softw.197 (2023), 111549....
-
[11]
Gordon Fraser and Andrea Arcuri. 2011. EvoSuite: automatic test suite generation for object-oriented software. In SIGSOFT/FSE’11 19th ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE-19) and ESEC’11: 13th European Software Engineering Conference (ESEC-13), Szeged, Hungary, September 5-9, 2011, Tibor Gyimóthy and Andreas Zeller (Eds.)....
-
[12]
Zhipeng Gao, Xin Xia, David Lo, John C. Grundy, and Thomas Zimmermann. 2021. Automating the removal of obsolete TODO comments. InESEC/FSE ’21: 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, August 23-28, 2021, Diomidis Spinellis, Georgios Gousios, Marsha Chechik, and Massim...
-
[13]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Trans. Inf. Syst.43, 2 (2025), 42:1–42:55. doi:10.1145/3703155
-
[14]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum? id=VTF8yNQM66
2024
-
[15]
René Just, Darioush Jalali, and Michael D. Ernst. 2014. Defects4J: a database of existing faults to enable controlled testing studies for Java programs. InInternational Symposium on Software Testing and Analysis, ISSTA ’14, San Jose, CA, USA - July 21 - 26, 2014, Corina S. Pasareanu and Darko Marinov (Eds.). ACM, 437–440. doi:10.1145/2610384.2628055
-
[16]
Sungmin Kang, Louis Milliken, and Shin Yoo. 2024. Identifying Inaccurate Descriptions in LLM-generated Code Comments via Test Execution.CoRRabs/2406.14836 (2024). arXiv:2406.14836 doi:10.48550/ARXIV.2406.14836 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE168. Publication date: July 2026. FSE168:22 Tobias Kiecker, Jan Arne Sparka, Martin Reuter, Albe...
-
[17]
Anant Kharkar, Roshanak Zilouchian Moghaddam, Matthew Jin, Xiaoyu Liu, Xin Shi, Colin B. Clement, and Neel Sundaresan. 2022. Learning to Reduce False Positives in Analytic Bug Detectors. In44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 1307–1316. doi:10.1145/ 3510003.3510153
-
[18]
Exploiting Unintended Feature Leakage in Collaborative Learning
Rohan Krishnamurthy, Thomas S. Heinze, Carina Haupt, Andreas Schreiber, and Michael Meinel. 2019. Scientific developers v/s static analysis tools: vision and position paper. InProceedings of the 12th International Workshop on Cooperative and Human Aspects of Software Engineering, CHASE@ICSE 2019, Montréal, QC, Canada, 27 May 2019, Yvonne Dittrich, Fabian ...
-
[19]
Hyeonseok Lee, Gabin An, and Shin Yoo. 2025. Metamon: Finding Inconsistencies between Program Documentation and Behavior using Metamorphic LLM Queries. InIEEE/ACM International Workshop on Large Language Models for Code, LLM4Code@ICSE 2025, Ottawa, ON, Canada, May 3, 2025. IEEE, 120–127. doi:10.1109/LLM4CODE66737.2025.00020
-
[20]
Jörg Lenhard, Martin Blom, and Sebastian Herold. 2019. Exploring the suitability of source code metrics for indicating architectural inconsistencies.Softw. Qual. J.27, 1 (2019), 241–274. doi:10.1007/S11219-018-9404-Z
-
[21]
Zhongxin Liu, Xin Xia, David Lo, Meng Yan, and Shanping Li. 2023. Just-In-Time Obsolete Comment Detection and Update.IEEE Trans. Software Eng.49, 1 (2023), 1–23. doi:10.1109/TSE.2021.3138909
-
[22]
Zhongxin Liu, Xin Xia, Meng Yan, and Shanping Li. 2020. Automating Just-In-Time Comment Updating. In35th IEEE/ACM International Conference on Automated Software Engineering, ASE 2020, Melbourne, Australia, September 21-25, 2020. IEEE, 585–597. doi:10.1145/3324884.3416581
-
[23]
David Lo. 2023. Trustworthy and Synergistic Artificial Intelligence for Software Engineering: Vision and Roadmaps. In IEEE/ACM International Conference on Software Engineering: Future of Software Engineering, ICSE-FoSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 69–85. doi:10.1109/ICSE-FOSE59343.2023.00010
-
[24]
Tatwadarshi P. Nagarhalli, Vinod Vaze, and N. K. Rana. 2021. Impact of Machine Learning in Natural Language Processing: A Review. In2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV). 1529–1534. doi:10.1109/ICICV50876.2021.9388380
-
[25]
Wang, and Xi Victoria Lin
Ansong Ni, Srini Iyer, Dragomir Radev, Veselin Stoyanov, Wen-Tau Yih, Sida I. Wang, and Xi Victoria Lin. 2023. LEVER: Learning to Verify Language-to-Code Generation with Execution. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research), Andreas Krause, Emma Brunskill, Ky...
2023
-
[26]
Wanrong Ouyang and Baojian Hua. 2021. ’R: Towards Detecting and Understanding Code-Document Violations in Rust. InIEEE International Symposium on Software Reliability Engineering, ISSRE 2021 - Workshops, Wuhan, China, October 25-28, 2021. IEEE, 189–197. doi:10.1109/ISSREW53611.2021.00063
-
[27]
Carlos Pacheco and Michael D. Ernst. 2007. Randoop: feedback-directed random testing for Java. InCompanion to the 22nd Annual ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA 2007, October 21-25, 2007, Montreal, Quebec, Canada, Richard P. Gabriel, David F. Bacon, Cristina Videira Lopes, and Guy L. Steele ...
-
[28]
Sheena Panthaplackel, Junyi Jessy Li, Milos Gligoric, and Raymond J. Mooney. 2021. Deep Just-In-Time Inconsistency Detection Between Comments and Source Code. InThirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational ...
-
[29]
Sheena Panthaplackel, Pengyu Nie, Milos Gligoric, Junyi Jessy Li, and Raymond J. Mooney. 2020. Learning to Update Natural Language Comments Based on Code Changes. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault (E...
-
[30]
Pooja Rani, Arianna Blasi, Nataliia Stulova, Sebastiano Panichella, Alessandra Gorla, and Oscar Nierstrasz. 2023. A decade of code comment quality assessment: A systematic literature review.J. Syst. Softw.195 (2023), 111515. doi:10.1016/J.JSS.2022.111515
-
[31]
Inderjot Kaur Ratol and Martin P. Robillard. 2017. Detecting fragile comments. InProceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering, ASE 2017, Urbana, IL, USA, October 30 - November 03, 2017, Grigore Rosu, Massimiliano Di Penta, and Tien N. Nguyen (Eds.). IEEE Computer Society, 112–122. doi:10.1109/ASE. 2017.8115624
work page doi:10.1109/ase 2017
-
[32]
Steven P. Reiss. 2006. Incremental Maintenance of Software Artifacts.IEEE Trans. Software Eng.32, 9 (2006), 682–697. doi:10.1109/TSE.2006.91
-
[33]
Guoping Rong, Yongda Yu, Song Liu, Xin Tan, Tianyi Zhang, Haifeng Shen, and Jidong Hu. 2025. Code Comment Inconsistency Detection and Rectification Using a Large Language Model. In47th IEEE/ACM International Conference Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE168. Publication date: July 2026. Cascade: Detecting Inconsistencies between Code and D...
-
[34]
Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2024. An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation.IEEE Trans. Software Eng.50, 1 (2024), 85–105. doi:10.1109/TSE.2023.3334955
-
[35]
Haihao Shen, Jianhong Fang, and Jianjun Zhao. 2011. EFindBugs: Effective Error Ranking for FindBugs. InFourth IEEE International Conference on Software Testing, Verification and Validation, ICST 2011, Berlin, Germany, March 21-25, 2011. IEEE Computer Society, 299–308. doi:10.1109/ICST.2011.51
-
[36]
Devika Sondhi and Rahul Purandare. 2019. SEGATE: Unveiling Semantic Inconsistencies between Code and Specifica- tion of String Inputs. In34th IEEE/ACM International Conference on Automated Software Engineering, ASE 2019, San Diego, CA, USA, November 11-15, 2019. IEEE, 200–212. doi:10.1109/ASE.2019.00028
-
[37]
Nataliia Stulova, Arianna Blasi, Alessandra Gorla, and Oscar Nierstrasz. 2020. Towards Detecting Inconsistent Comments in Java Source Code Automatically. In20th IEEE International Working Conference on Source Code Analysis and Manipulation, SCAM 2020, Adelaide, Australia, September 28 - October 2, 2020. IEEE, 65–69. doi:10.1109/SCAM51674. 2020.00012
-
[38]
Wannita Takerngsaksiri, Rujikorn Charakorn, Chakkrit Tantithamthavorn, and Yuan-Fang Li. 2025. Pytester: Deep reinforcement learning for text-to-testcase generation.J. Syst. Softw.224 (2025), 112381. doi:10.1016/J.JSS.2025.112381
-
[39]
Lin Tan, Ding Yuan, Gopal Krishna, and Yuanyuan Zhou. 2007. /*icomment: bugs or bad comments?*/. InProceedings of the 21st ACM Symposium on Operating Systems Principles 2007, SOSP 2007, Stevenson, Washington, USA, October 14-17, 2007, Thomas C. Bressoud and M. Frans Kaashoek (Eds.). ACM, 145–158. doi:10.1145/1294261.1294276
-
[40]
Shin Hwei Tan, Darko Marinov, Lin Tan, and Gary T. Leavens. 2012. @tComment: Testing Javadoc Comments to Detect Comment-Code Inconsistencies. InFifth IEEE International Conference on Software Testing, Verification and Validation, ICST 2012, Montreal, QC, Canada, April 17-21, 2012, Giuliano Antoniol, Antonia Bertolino, and Yvan Labiche (Eds.). IEEE Compute...
-
[41]
Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Haotian Hui, Weichuan Liu, Zhiyuan Liu, and Maosong Sun. 2024. DebugBench: Evaluating Debugging Capability of Large Language Models. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 (Findings of ACL)...
-
[42]
Kristín Fjóla Tómasdóttir, Mauricio Finavaro Aniche, and Arie van Deursen. 2020. The Adoption of JavaScript Linters in Practice: A Case Study on ESLint.IEEE Trans. Software Eng.46, 8 (2020), 863–891. doi:10.1109/TSE.2018.2871058
-
[43]
Robillard
Gias Uddin and Martin P. Robillard. 2015. How API Documentation Fails.IEEE Softw.32, 4 (2015), 68–75. doi:10.1109/ MS.2014.80
2015
-
[44]
Yue Wang, Weishi Wang, Shafiq R. Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, Marie-Fran...
-
[45]
Fengcai Wen, Csaba Nagy, Gabriele Bavota, and Michele Lanza. 2019. A large-scale empirical study on code-comment inconsistencies. InProceedings of the 27th International Conference on Program Comprehension, ICPC 2019, Montreal, QC, Canada, May 25-31, 2019, Yann-Gaël Guéhéneuc, Foutse Khomh, and Federica Sarro (Eds.). IEEE / ACM, 53–64. doi:10.1109/ICPC.2019.00019
-
[46]
Measuring program comprehension: a large-scale field study with professionals,
Xin Xia, Lingfeng Bao, David Lo, Zhenchang Xing, Ahmed E. Hassan, and Shanping Li. 2018. Measuring program comprehension: a large-scale field study with professionals. (2018), 584. doi:10.1145/3180155.3182538
-
[47]
Wentao Ye, Mingfeng Ou, Tianyi Li, Yipeng Chen, Xuetao Ma, Yifan Yanggong, Sai Wu, Jie Fu, Gang Chen, Haobo Wang, and Junbo Zhao. 2023. Assessing Hidden Risks of LLMs: An Empirical Study on Robustness, Consistency, and Credibility.CoRRabs/2305.10235 (2023). arXiv:2305.10235 doi:10.48550/ARXIV.2305.10235
-
[48]
Yichi Zhang, Zixi Liu, Yang Feng, and Baowen Xu. 2024. Leveraging Large Language Model to Assist Detecting Rust Code Comment Inconsistency. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE 2024, Sacramento, CA, USA, October 27 - November 1, 2024, Vladimir Filkov, Baishakhi Ray, and Minghui Zhou (Eds.). ACM...
-
[49]
Hao Zhong, Lu Zhang, Tao Xie, and Hong Mei. 2009. Inferring Resource Specifications from Natural Language API Documentation. InASE 2009, 24th IEEE/ACM International Conference on Automated Software Engineering, Auckland, New Zealand, November 16-20, 2009. IEEE Computer Society, 307–318. doi:10.1109/ASE.2009.94
-
[50]
Yuxiang Zhu and Minxue Pan. 2019. Automatic Code Summarization: A Systematic Literature Review.CoRR abs/1909.04352 (2019). arXiv:1909.04352 http://arxiv.org/abs/1909.04352 Received 2026-02-25; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE168. Publication date: July 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.