Recognition: unknown
TS-Attn: Temporal-wise Separable Attention for Multi-Event Video Generation
Pith reviewed 2026-05-10 02:42 UTC · model grok-4.3
The pith
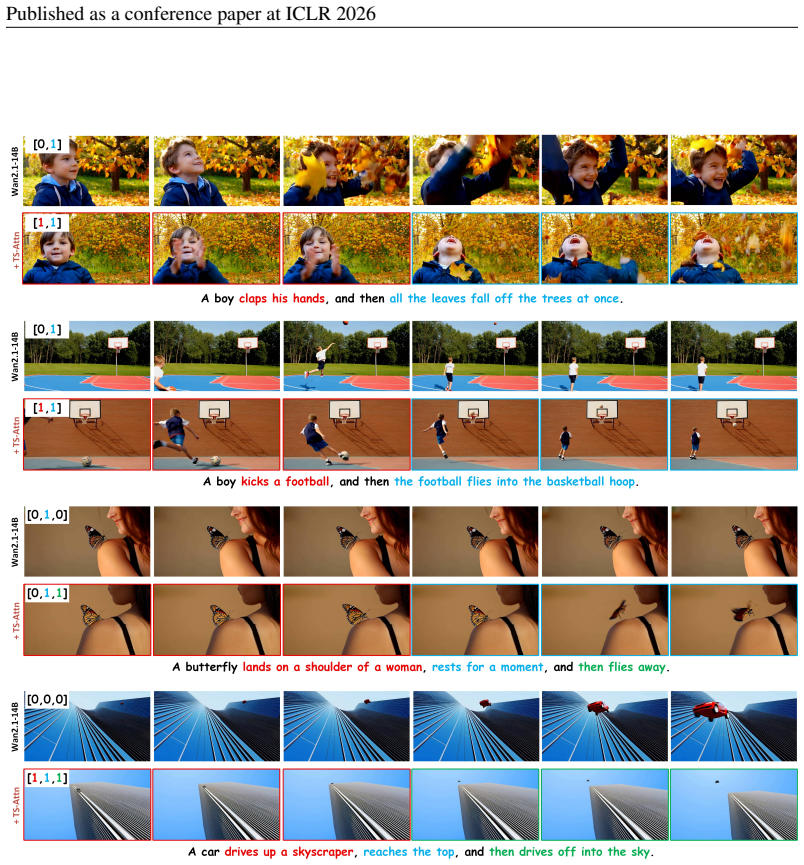
TS-Attn separates attention across time to resolve misalignment and conflicts when generating videos from multi-event text prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Temporal-wise Separable Attention dynamically rearranges attention distribution across frames so that each time step aligns correctly with its corresponding text condition and motion objects do not compete for the same attention slots, thereby restoring both prompt fidelity and temporal consistency in multi-event generation.
What carries the argument
Temporal-wise Separable Attention (TS-Attn), which factors attention into separate temporal and spatial components and re-weights them per frame to enforce temporal awareness and global coherence.
If this is right
- Pre-trained text-to-video models can generate coherent multi-event videos from a single complex prompt without retraining or sequential prompting.
- The same module works for image-to-video tasks that contain multiple sequential actions.
- Inference cost rises by only about two percent while benchmark scores rise substantially on two different large models.
- The method can be inserted into a variety of existing diffusion-based text-to-video pipelines.
Where Pith is reading between the lines
- The result suggests that attention coupling is a primary bottleneck for long-horizon video generation and may be easier to fix than retraining entire models.
- Future work could test whether the same separation principle improves consistency in longer videos or in models that also generate audio.
- If the gains hold across many base models, prompt engineering for story videos might become less necessary.
- An ablation that disables only the temporal re-weighting while keeping other changes would isolate exactly how much the separation contributes.
Load-bearing premise
That the measured gains on StoryEval-Bench arise specifically from fixing temporal misalignment and attention coupling rather than from other side effects of the method.
What would settle it
Run the identical prompts and base models with and without the TS-Attn rearrangement and measure whether the StoryEval-Bench improvement disappears when the temporal separation is removed.
Figures




















read the original abstract
Generating high-quality videos from complex temporal descriptions that contain multiple sequential actions is a key unsolved problem. Existing methods are constrained by an inherent trade-off: using multiple short prompts fed sequentially into the model improves action fidelity but compromises temporal consistency, while a single complex prompt preserves consistency at the cost of prompt-following capability. We attribute this problem to two primary causes: 1) temporal misalignment between video content and the prompt, and 2) conflicting attention coupling between motion-related visual objects and their associated text conditions. To address these challenges, we propose a novel, training-free attention mechanism, Temporal-wise Separable Attention (TS-Attn), which dynamically rearranges attention distribution to ensure temporal awareness and global coherence in multi-event scenarios. TS-Attn can be seamlessly integrated into various pre-trained text-to-video models, boosting StoryEval-Bench scores by 33.5% and 16.4% on Wan2.1-T2V-14B and Wan2.2-T2V-A14B with only a 2% increase in inference time. It also supports plug-and-play usage across models for multi-event image-to-video generation. The source code and project page are available at https://github.com/Hong-yu-Zhang/TS-Attn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Temporal-wise Separable Attention (TS-Attn), a training-free plug-and-play attention module for pre-trained text-to-video diffusion models. It targets two issues in multi-event generation—temporal misalignment between video frames and complex prompts, and conflicting attention between motion objects and text conditions—by dynamically rearranging attention distributions. The authors report that TS-Attn integrates into models such as Wan2.1-T2V-14B and Wan2.2-T2V-A14B, yielding 33.5% and 16.4% gains on StoryEval-Bench while adding only 2% inference time, and extends the approach to image-to-video settings. Code is released at the provided GitHub link.
Significance. If the reported benchmark lifts can be shown to arise specifically from TS-Attn’s temporal rearrangement rather than confounding factors, the method would offer a lightweight, training-free route to improve temporal coherence and prompt adherence in existing large video models. The open-source code release is a clear strength that supports reproducibility and adoption.
major comments (2)
- [§4 (Experiments), main results table] §4 (Experiments), main results table: The 33.5% and 16.4% StoryEval-Bench improvements on Wan2.1-T2V-14B and Wan2.2-T2V-A14B are presented without ablations that hold prompt phrasing, integration layer, and random attention baselines fixed. This leaves open the possibility that equivalent gains could arise from any attention perturbation or model-specific prompt sensitivity rather than the claimed temporal-wise separability and resolution of conflicting attention coupling.
- [§3 (Method)] §3 (Method): The description of TS-Attn as dynamically rearranging attention to ensure temporal awareness lacks a precise algorithmic specification or pseudocode that would allow readers to verify how the rearrangement differs from standard cross-attention and directly corrects the two stated failure modes.
minor comments (2)
- [Abstract / §1] The abstract and introduction refer to StoryEval-Bench without providing its definition, task construction, or citation; a brief description or reference should be added for readers unfamiliar with the benchmark.
- [Figures] Figure captions for attention visualizations (if present) should explicitly label which maps correspond to baseline vs. TS-Attn and which frames illustrate the claimed reduction in temporal misalignment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation of results and methodological details.
read point-by-point responses
-
Referee: [§4 (Experiments), main results table] The 33.5% and 16.4% StoryEval-Bench improvements on Wan2.1-T2V-14B and Wan2.2-T2V-A14B are presented without ablations that hold prompt phrasing, integration layer, and random attention baselines fixed. This leaves open the possibility that equivalent gains could arise from any attention perturbation or model-specific prompt sensitivity rather than the claimed temporal-wise separability and resolution of conflicting attention coupling.
Authors: We agree that controlled ablations are necessary to isolate the specific contribution of the temporal-wise separable rearrangement. The current experiments demonstrate gains relative to the base models and other approaches, but we acknowledge the absence of the suggested fixed-prompt, fixed-layer, and random-perturbation controls. In the revised manuscript we will add these ablations, keeping prompt phrasing and integration layers identical while comparing against a random attention baseline. This will provide direct evidence that the reported improvements arise from the targeted correction of temporal misalignment and conflicting attention coupling rather than generic perturbations. revision: yes
-
Referee: [§3 (Method)] The description of TS-Attn as dynamically rearranging attention to ensure temporal awareness lacks a precise algorithmic specification or pseudocode that would allow readers to verify how the rearrangement differs from standard cross-attention and directly corrects the two stated failure modes.
Authors: We accept that a more formal specification would improve verifiability. Section 3 currently describes the dynamic rearrangement process at a conceptual level. In the revised manuscript we will insert explicit pseudocode that details the separation of temporal attention maps, the event-aligned reordering step, and the subsequent fusion, together with a side-by-side comparison to standard cross-attention. This will make clear how the mechanism directly mitigates the two identified failure modes. revision: yes
Circularity Check
No significant circularity; empirical module proposal stands independently
full rationale
The paper introduces TS-Attn as a training-free attention rearrangement module to mitigate temporal misalignment and conflicting coupling in multi-event video generation. Its core claims consist of a descriptive mechanism plus measured benchmark lifts (33.5% and 16.4% on StoryEval-Bench) when plugged into existing pre-trained models. No equations, uniqueness theorems, or first-principles derivations are presented that reduce by construction to fitted parameters, self-citations, or renamed inputs. The reported gains are external empirical outcomes rather than statistical artifacts of the method's own definition, and no load-bearing self-citation chain or ansatz smuggling is required for the central argument. The derivation chain is therefore self-contained against the provided benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard scaled dot-product attention can be rearranged along the temporal axis without breaking the model's learned weights.
Forward citations
Cited by 1 Pith paper
-
Delta Forcing: Trust Region Steering for Interactive Autoregressive Video Generation
Delta Forcing uses latent trajectory deltas to adaptively limit unreliable teacher guidance while enforcing monotonic continuity, improving temporal consistency in interactive autoregressive video generation.
Reference graph
Works this paper leans on
-
[1]
URLhttps:// arxiv.org/abs/2405.04682. Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023a. Andreas Blattmann, Robin Rombach, Huan Li...
-
[2]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074,
work page internal anchor Pith review arXiv
-
[3]
Gaussian splatting: 3d reconstruction and novel view synthesis – a review,
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models.arXiv preprint arXiv:2401.09047,
-
[4]
Yufan Deng, Xun Guo, Yizhi Wang, Jacob Zhiyuan Fang, Angtian Wang, Shenghai Yuan, Yiding Yang, Bo Liu, Haibin Huang, and Chongyang Ma. Cinema: Coherent multi-subject video gener- ation via mllm-based guidance.arXiv preprint arXiv:2503.10391, 2025a. Yufan Deng, Yuanyang Yin, Xun Guo, Yizhi Wang, Jacob Zhiyuan Fang, Shenghai Yuan, Yiding Yang, Angtian Wang,...
-
[5]
Vchitect-2.0: Parallel transformer for scaling up video diffusion models,
Weichen Fan, Chenyang Si, Junhao Song, Zhenyu Yang, Yinan He, Long Zhuo, Ziqi Huang, Ziyue Dong, Jingwen He, Dongwei Pan, et al. Vchitect-2.0: Parallel transformer for scaling up video diffusion models.arXiv preprint arXiv:2501.08453,
-
[6]
I2v-adapter: A general image-to-video adapter for diffusion models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, et al. I2v-adapter: A general image-to-video adapter for diffusion models. InACM SIGGRAPH 2024 Conference Papers, pp. 1–12,
2024
-
[7]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review arXiv
-
[8]
Hailuo.https://hailuoai.video/,
10 Published as a conference paper at ICLR 2026 HailuoAI. Hailuo.https://hailuoai.video/,
2026
-
[9]
doi:10.48550/arXiv.2502.04320 , urldate =
Alec Helbling, Tuna Han Salih Meral, Ben Hoover, Pinar Yanardag, and Duen Horng Chau. Conceptattention: Diffusion transformers learn highly interpretable features.arXiv preprint arXiv:2502.04320,
-
[10]
URL https://arxiv.org/abs/2505.04512. Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. arXiv preprint arXiv:2410.05954,
-
[11]
Subin Kim, Seoung Wug Oh, Jui-Hsien Wang, Joon-Young Lee, and Jinwoo Shin. Tuning- free multi-event long video generation via synchronized coupled sampling.arXiv preprint arXiv:2503.08605,
-
[12]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
-
[14]
Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131,
-
[15]
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning.arXiv preprint arXiv:2309.15091,
-
[16]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048,
work page internal anchor Pith review arXiv
-
[17]
U-net: Convolutional networks for biomed- ical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomed- ical image segmentation. InMedical Image Computing and Computer-Assisted Intervention– MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceed- ings, Part III 18, pp. 234–241. Springer,
2015
-
[18]
Longcat-video technical report,
11 Published as a conference paper at ICLR 2026 Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, and Tong Zhang. Longcat-video technical report,
2026
-
[19]
Longcat-video technical report
URLhttps://arxiv.org/abs/2510.22200. Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211,
-
[20]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025a. Fu-Yun Wang, Wenshuo Chen, Guanglu Song, Han-Jia Ye, Yu Liu, and Hongsheng Li. Gen-l-video: Multi-text to long video generation via ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yiping Wang, Xuehai He, Kuan Wang, Luyao Ma, Jianwei Yang, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. Is your world simulator a good story presenter? a consecutive events-based benchmark for future long video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 13629–13638, 2025b. Zun Wang, Jialu Li, Han Lin, Jae...
-
[22]
Bowen Zhang, Xiaofei Xie, Haotian Lu, Na Ma, Tianlin Li, and Qing Guo. Mavin: Multi- action video generation with diffusion models via transition video infilling.arXiv preprint arXiv:2405.18003,
-
[23]
Magiccomp: Training-free dual-phase refinement for compositional video generation
Hongyu Zhang, Yufan Deng, Shenghai Yuan, Peng Jin, Zesen Cheng, Yian Zhao, Chang Liu, and Jie Chen. Magiccomp: Training-free dual-phase refinement for compositional video generation. arXiv preprint arXiv:2503.14428, 2025a. Lvmin Zhang and Maneesh Agrawala. Packing input frame context in next-frame prediction models for video generation.arXiv preprint arXi...
-
[24]
Open-Sora: Democratizing Efficient Video Production for All
Shiyi Zhang, Junhao Zhuang, Zhaoyang Zhang, Ying Shan, and Yansong Tang. Flexiact: Towards flexible action control in heterogeneous scenarios. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pp. 1–11, 2025b. 12 Published as a conference paper at ICLR 2026 Zangwei Zheng, Xiangyu Peng...
work page internal anchor Pith review arXiv 2026
-
[25]
Therefore, this section provides a supplementary explanation for scenarios involving multiple subjects
13 Published as a conference paper at ICLR 2026 TS-Attn: Temporal-wise Separable Attention for Multi-Event Video Generation Appendix A TS-ATTN FORMULTIPLESUBJECTS For brevity of description, we introduce TS-Attn in the main text using a single subject and its cor- responding event list. Therefore, this section provides a supplementary explanation for scen...
2026
-
[26]
Relying solely on attention reinforcement reduces TS-Attn to a mere attention enhancement mechanism for event tokens, lacking temporal correspondence
It can be observed that removing attention rearrangement leads to a significant performance drop, further demonstrating that the more critical aspect of TS-Attn is the temporal redistribution of cross-attention distributions. Relying solely on attention reinforcement reduces TS-Attn to a mere attention enhancement mechanism for event tokens, lacking tempo...
2026
-
[27]
As shown in Figure 9, the attention distributions of different actions in TS-Attn are clearly separated along the temporal sequence
F MOREATTENTIONVISUALIZATIONRESULTS We present additional attention analysis to further elaborate on the insights of TS-Attn. As shown in Figure 9, the attention distributions of different actions in TS-Attn are clearly separated along the temporal sequence. Meanwhile, each event exhibits a strong response to the motion regions of its corresponding frames...
2026
-
[28]
I MOREDIVERSEAPPLICATIONS OFTS-ATTN In this section, we present more potential application scenarios of TS-Attn, including multi-event generation involving multiple subjects, scene-level multi-event generation, and enhancing the po- tential for interactive long-video generation. Multi-subject multi-event generation.As shown in Figure 19, multi-event gener...
2026
-
[29]
(2025), which natively supports video continuity
To handle more events, we applied TS-Attn to the recently proposed LongCat-Video-13.6B model Team et al. (2025), which natively supports video continuity. This enables us to distribute a larger number of events across multiple clips. For example, 9 events can be divided into 3 clips for generation while maintaining temporal consistency. As illustrated in ...
2025
-
[30]
These results highlight the potential of TS-Attn for both interactive and long-form video generation
For a fixed number of clips, TS-Attn effectively manages more intri- cate temporal descriptions. These results highlight the potential of TS-Attn for both interactive and long-form video generation. J THEUSE OFLARGELANGUAGEMODELS We use large language models (LLMs) solely for polishing sentence structures and refining the lan- guage throughout the manuscr...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.