Recognition: unknown
Deep sprite-based image models: An analysis
Pith reviewed 2026-05-10 02:37 UTC · model grok-4.3
The pith
A deep sprite-based model matches state-of-the-art unsupervised segmentation on CLEVR while scaling linearly with objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
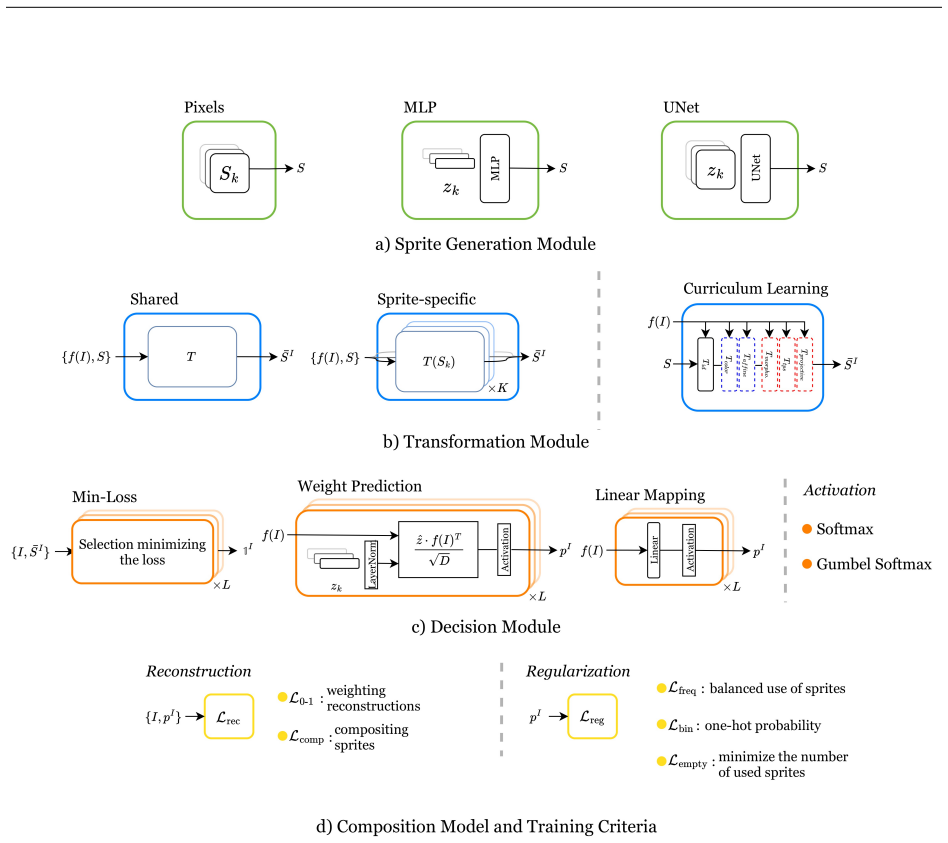
Through analysis of sprite-based models, the authors identify their essential components and construct a deep sprite-based image decomposition method. This method performs on par with state-of-the-art unsupervised class-aware image segmentation methods on the standard CLEVR benchmark, scales linearly with the number of objects, identifies explicitly object categories, and fully models images in an easily interpretable way.
What carries the argument
The deep sprite-based decomposition method, assembled from the core components isolated in the analysis of prior sprite models, which handles object clustering, category assignment, and full image reconstruction.
If this is right
- The method achieves accuracy on par with leading unsupervised class-aware segmentation on CLEVR.
- Computation scales linearly with the number of objects present in an image.
- Object categories are identified explicitly rather than only through implicit clustering.
- The full image is modeled in a form that remains directly interpretable by inspection.
Where Pith is reading between the lines
- The linear scaling property could support application to scenes containing more objects than typical CLEVR examples without quadratic slowdown.
- Explicit category outputs may simplify integration with downstream tasks that require semantic labels but lack supervision.
- If the identified components transfer, similar constructions could be tried on other synthetic or real-image collections that feature recurrent visual patterns.
Load-bearing premise
The core components identified through analysis of existing sprite-based models suffice to build a deep model that generalizes to on-par performance without post-hoc tuning or dataset-specific adjustments.
What would settle it
A direct test on the CLEVR benchmark where the proposed deep sprite-based method falls substantially below the accuracy of current state-of-the-art unsupervised segmentation methods or shows super-linear growth in computation with object count would falsify the central claim.
Figures







read the original abstract
While foundation models drive steady progress in image segmentation and diffusion algorithms compose always more realistic images, the seemingly simple problem of identifying recurrent patterns in a collection of images remains very much open. In this paper, we focus on sprite-based image decomposition models, which have shown some promise for clustering and image decomposition and are appealing because of their high interpretability. These models come in different flavors, need to be tailored to specific datasets, and struggle to scale to images with many objects. We dive into the details of their design, identify their core components, and perform an extensive analysis on clustering benchmarks. We leverage this analysis to propose a deep sprite-based image decomposition method that performs on par with state-of-the-art unsupervised class-aware image segmentation methods on the standard CLEVR benchmark, scales linearly with the number of objects, identifies explicitly object categories, and fully models images in an easily interpretable way.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes sprite-based image decomposition models to identify their core components via extensive experiments on clustering benchmarks. It then proposes a deep sprite-based image decomposition architecture that, according to the abstract, matches state-of-the-art unsupervised class-aware segmentation performance on the CLEVR benchmark, scales linearly with object count, explicitly identifies object categories, and yields a fully interpretable image model.
Significance. If the experimental support is strengthened, the work would usefully demonstrate how empirical dissection of interpretable sprite models can yield a competitive deep architecture for unsupervised decomposition. The explicit category identification and claimed linear scaling address two recurring weaknesses in the literature; a reproducible implementation would further increase the result's utility for the field.
major comments (3)
- [method section / abstract] The central claim that the analysis-derived core components are sufficient to assemble a CLEVR-competitive deep model without dataset-specific tuning or post-hoc adjustments (abstract and method section) is load-bearing but under-supported. The manuscript provides no explicit mapping or ablation demonstrating that each isolated component is both necessary and jointly sufficient for the reported CLEVR results, leaving open the possibility that additional inductive biases introduced in the deep architecture are responsible for the performance.
- [experiments section] CLEVR results (experiments section): the claims of 'on par with state-of-the-art' and 'scales linearly with the number of objects' are presented without error bars, multiple random seeds, statistical tests, or controlled ablations that isolate the effect of object count while holding other factors fixed. These omissions make it impossible to assess the reliability and generality of the scaling and performance assertions.
- [analysis-to-method transition] The relationship between the clustering-benchmark analysis and the CLEVR task is not sufficiently justified. Because CLEVR consists of 3D-rendered primitives with known attribute structure, any performance gain could stem from dataset-specific design choices rather than from the preceding generic analysis; the manuscript should include a direct test of whether the same architecture, trained only on the identified core components, transfers without modification.
minor comments (2)
- [abstract] The abstract would be clearer if it named the specific clustering benchmarks used in the analysis.
- [methods] Notation for sprite components, latent variables, and loss terms should be introduced once in a dedicated notation subsection and used consistently thereafter.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [method section / abstract] The central claim that the analysis-derived core components are sufficient to assemble a CLEVR-competitive deep model without dataset-specific tuning or post-hoc adjustments (abstract and method section) is load-bearing but under-supported. The manuscript provides no explicit mapping or ablation demonstrating that each isolated component is both necessary and jointly sufficient for the reported CLEVR results, leaving open the possibility that additional inductive biases introduced in the deep architecture are responsible for the performance.
Authors: We agree that an explicit mapping and targeted ablations would make the load-bearing claim more transparent. The analysis section systematically isolates the core components via experiments on clustering benchmarks, and the method section assembles the deep architecture directly from those components with no CLEVR-specific tuning. In the revision we will add a dedicated mapping table linking each identified component to its architectural realization and include ablations on CLEVR that remove or alter individual components to demonstrate necessity and joint sufficiency. revision: yes
-
Referee: [experiments section] CLEVR results (experiments section): the claims of 'on par with state-of-the-art' and 'scales linearly with the number of objects' are presented without error bars, multiple random seeds, statistical tests, or controlled ablations that isolate the effect of object count while holding other factors fixed. These omissions make it impossible to assess the reliability and generality of the scaling and performance assertions.
Authors: We concur that statistical rigor and controlled scaling experiments are necessary. The revised manuscript will report CLEVR results averaged over multiple random seeds with error bars, include statistical significance tests against the cited SOTA methods, and add controlled ablations that vary only the number of objects while holding all other factors fixed to support the linear-scaling claim. revision: yes
-
Referee: [analysis-to-method transition] The relationship between the clustering-benchmark analysis and the CLEVR task is not sufficiently justified. Because CLEVR consists of 3D-rendered primitives with known attribute structure, any performance gain could stem from dataset-specific design choices rather than from the preceding generic analysis; the manuscript should include a direct test of whether the same architecture, trained only on the identified core components, transfers without modification.
Authors: The clustering benchmarks used for the analysis are generic 2D datasets that do not exploit 3D rendering or known attribute structure, and the deep architecture applies only the identified core components without CLEVR-specific inductive biases. We will strengthen the transition section by explicitly contrasting the generic nature of the analysis benchmarks with the CLEVR evaluation. To directly address the transfer concern we will also add a controlled experiment applying the identical architecture (trained only on the core components) to at least one additional dataset without modification. revision: yes
Circularity Check
No significant circularity; derivation rests on empirical analysis and external benchmarks
full rationale
The paper's chain proceeds from analysis of prior sprite-based models on clustering benchmarks, identification of core components, to proposal of a deep architecture whose CLEVR performance, linear scaling, and interpretability are reported as empirical outcomes. No equation reduces a claimed prediction to a fitted input by construction, no self-citation is invoked as a uniqueness theorem that forces the result, and no ansatz is smuggled via prior self-work. The central claims remain falsifiable against standard unsupervised segmentation baselines and do not collapse to self-definition or renaming of known patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Core components of sprite-based models can be identified through analysis and used to design a scalable deep variant
Reference graph
Works this paper leans on
-
[1]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization.arXiv preprint arXiv:1907.02893,
work page internal anchor Pith review arXiv 1907
-
[2]
MONet: Unsupervised Scene Decomposition and Representation
Christopher P Burgess, Loic Matthey, Nicholas Watters, Rishabh Kabra, Irina Higgins, Matt Botvinick, and Alexander Lerchner. MoNet: Unsupervised scene decomposition and representation.arXiv preprint arXiv:1901.11390,
work page Pith review arXiv 1901
-
[3]
Binding via reconstruction clustering
Klaus Greff, Rupesh Kumar Srivastava, and Jürgen Schmidhuber. Binding via reconstruction clustering. arXiv preprint arXiv:1511.06418,
-
[4]
On the binding problem in artificial neural networks.arXiv preprint arXiv:2012.05208, 2020
Klaus Greff, Sjoerd Van Steenkiste, and Jürgen Schmidhuber. On the binding problem in artificial neural networks. arXiv preprint arXiv:2012.05208,
-
[5]
Jindong Jiang, Fei Deng, Gautam Singh, and Sungjin Ahn. Object-centric slot diffusion.arXiv preprint arXiv:2303.10834,
-
[6]
Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool
[Accessed 04-11-2025]. Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool. SCAN: Learning to classify images without labels. InProceedings of the IEEE/CVF European Conference on Computer Vision,
2025
-
[7]
José-Fabian Villa-Vásquez and Marco Pedersoli. Unsupervised object discovery: A comprehensive survey and unified taxonomy.arXiv preprint arXiv:2411.00868,
-
[8]
Canqun Xiang, Zhennan Wang, Wenbin Zou, and Chen Xu. DPR-CAE: capsule autoencoder with dynamic part representation for image parsing.arXiv preprint arXiv:2104.14735,
-
[9]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747,
work page internal anchor Pith review arXiv
-
[10]
23 .1 Dataset Descriptions MNIST(LeCunetal.,2010)MNISTisawidelyuseddatasetofhandwrittengrayscaledigits, containing 60,000 training images and 10,000 testing images. ColoredMNIST (Arjovsky et al., 2019)Colored MNIST is built from the MNIST dataset by randomly adding color to the foreground and background, resulting in a collection of 70,000 images. Each di...
2010
-
[11]
Although released for visual reasoning tasks, it is commonly used in object discovery
CLEVR (Johnson et al., 2017)CLEVR dataset contains 6 unique objects with varying scale, color, and position on a uniform background. Although released for visual reasoning tasks, it is commonly used in object discovery. We reported results in 2 versions of CLEVR: CLEVR6 and CLEVR where the maximum numbers of objects in an image are 6 and 10, respectively....
2017
-
[12]
Due to its computational complexity, we adopt the training schedule reported for CLEVR6 in Monnier et al
For Table 8, we report the mean and standard error of 3 runs. Due to its computational complexity, we adopt the training schedule reported for CLEVR6 in Monnier et al. (2021) to CLEVR for DTI-Sprites (italicin Table 8). To be comparable with the literature (Karazija et al., 2021), we reported the mean and standard deviation of 3 runs for Table
2021
-
[13]
gauss. std. 5 7 10 10 sprite tr. id id, scale+rot. id, proj. id, proj. bkg. tr. - color color color layer tr. color, scale+affine color, scale+affine color, scale+affine color, scale+affine sprite tr. curr. - 40 300 300 sprite size 24, 24 28, 28 40, 40 40, 40 image size 35, 35 35, 35 128, 128 128, 128 occlusion -✓ ✓ ✓ Training avg. pool 1, 1 1, 1 1, 1 1, ...
2020
-
[14]
We observed thatλbin acts as a regularizer that improves the probabilities to be one-hot, but has a lower impact on overall performance compared toλfreq
Our results indicate thatλfreq is a critical hyperparameter for preventing cluster collapse. We observed thatλbin acts as a regularizer that improves the probabilities to be one-hot, but has a lower impact on overall performance compared toλfreq. Although tuning regularization hyperparameters via ground truth labels allows us to establish a performance up...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.