Recognition: unknown
Accelerating Optimization and Machine Learning through Decentralization
Pith reviewed 2026-05-10 02:43 UTC · model grok-4.3
The pith
Decentralized optimization reaches optimal solutions in fewer iterations than centralized methods even when each iteration takes equal time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decentralized optimization enables multiple devices to learn a global machine learning model while each device only accesses its local dataset. Traditionally viewed as a compromise for privacy or communication reasons, the work shows that this approach can paradoxically accelerate convergence by requiring fewer iterations than centralized training on the full dataset. Through examples in logistic regression and neural network training, distributing data and computation across agents produces faster learning even when each iteration is assumed to take the same amount of time whether performed centrally on the full dataset or decentrally on local subsets.
What carries the argument
The decentralized iteration process on partitioned local datasets, where agents update models locally before coordination, that produces lower total iteration counts to convergence compared with full-dataset central updates.
If this is right
- Decentralized training can reach target accuracy with a smaller total iteration budget than centralized training under equal per-iteration cost.
- Privacy-preserving distributed learning can simultaneously improve both data locality and convergence speed.
- Large-scale optimization systems may benefit from deliberate data partitioning even when communication is cheap.
- The advantage appears in both convex logistic regression and non-convex neural network objectives.
Where Pith is reading between the lines
- Increasing the number of agents beyond the examples might produce still larger reductions in iteration count for fixed total data size.
- The same partitioning logic could be tested on other first-order methods or on non-smooth objectives not covered in the paper.
- Hardware schedulers might deliberately over-partition workloads to exploit the observed iteration savings.
Load-bearing premise
Each iteration requires the same amount of time whether performed centrally on the full dataset or decentrally on local subsets.
What would settle it
A controlled timing experiment in which a centralized run on the complete dataset and a decentralized run on equal-sized subsets are forced to identical per-iteration wall-clock time, then measuring whether the decentralized version still reaches the target accuracy in strictly fewer iterations.
Figures

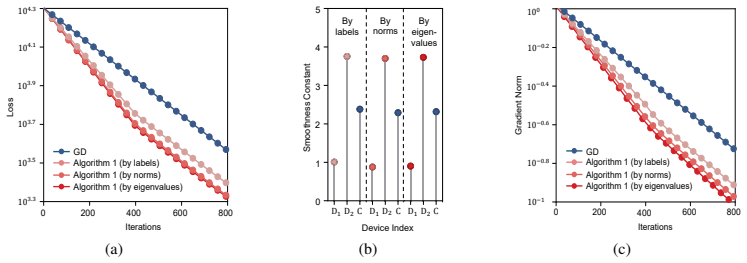




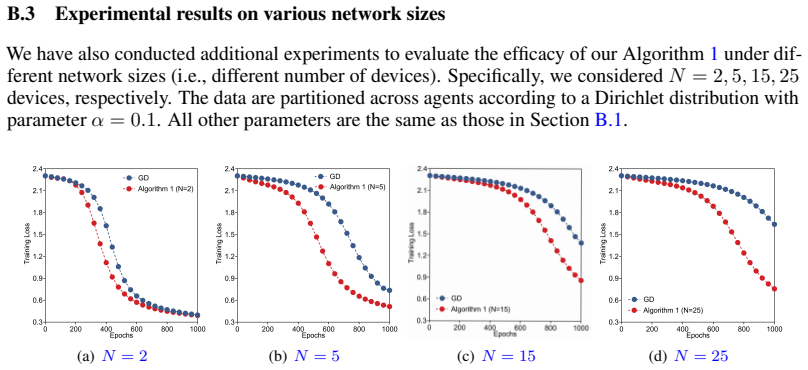



read the original abstract
Decentralized optimization enables multiple devices to learn a global machine learning model while each individual device only has access to its local dataset. By avoiding the need for training data to leave individual users' devices, it enhances privacy and scalability compared to conventional centralized learning, where all data has to be aggregated to a central server. However, decentralized optimization has traditionally been viewed as a necessary compromise, used only when centralized processing is impractical due to communication constraints or data privacy concerns. In this study, we show that decentralization can paradoxically accelerate convergence, outperforming centralized methods in the number of iterations needed to reach optimal solutions. Through examples in logistic regression and neural network training, we demonstrate that distributing data and computation across multiple agents can lead to faster learning than centralized approaches, even when each iteration is assumed to take the same amount of time, whether performed centrally on the full dataset or decentrally on local subsets. This finding challenges longstanding assumptions and reveals decentralization as a strategic advantage, offering new opportunities for more efficient optimization and machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that decentralized optimization can accelerate convergence relative to centralized methods by distributing data and computation across agents. It argues that this leads to fewer iterations to reach optimal solutions, even under the explicit assumption that each iteration takes the same amount of time whether performed centrally on the full dataset or decentrally on local subsets plus any averaging. The claim is illustrated via examples in logistic regression and neural network training, reframing decentralization as a potential strategic advantage for efficiency rather than solely a privacy or scalability workaround.
Significance. If the central claim holds after addressing the cost-equivalence issue, the result would be significant for the field of distributed optimization and machine learning. It would challenge the longstanding view of decentralization as a necessary compromise and suggest new design principles for faster distributed training protocols that simultaneously preserve privacy. The provision of concrete examples in logistic regression and neural networks is a positive step toward making the argument concrete and falsifiable.
major comments (2)
- [Abstract] Abstract: The load-bearing assumption that 'each iteration is assumed to take the same amount of time, whether performed centrally on the full dataset or decentrally on local subsets' is stated without supporting complexity analysis, FLOPs accounting, communication-round costing, or wall-clock measurements. The logistic regression and neural-network examples report lower iteration counts for the decentralized case, but without evidence that a local gradient step plus averaging equals the cost of a centralized full-batch step, the iteration advantage does not establish acceleration.
- [Examples in logistic regression and neural network training] Logistic regression and neural network examples: The manuscript uses these cases to demonstrate the iteration advantage, yet provides no breakdown of per-iteration costs (e.g., how local subset gradients plus any consensus/averaging rounds compare in arithmetic operations or communication volume to a centralized full-dataset gradient). This omission directly undermines the cross-setting comparison under the equal-time premise.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly specified the convergence criterion (e.g., loss threshold or gradient norm) used to count iterations in the examples.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the equal-time-per-iteration assumption requires explicit justification through complexity analysis to support the acceleration interpretation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing assumption that 'each iteration is assumed to take the same amount of time, whether performed centrally on the full dataset or decentrally on local subsets' is stated without supporting complexity analysis, FLOPs accounting, communication-round costing, or wall-clock measurements. The logistic regression and neural-network examples report lower iteration counts for the decentralized case, but without evidence that a local gradient step plus averaging equals the cost of a centralized full-batch step, the iteration advantage does not establish acceleration.
Authors: We acknowledge that the manuscript presents the equal-time assumption without accompanying complexity analysis or cost accounting, which limits the strength of the acceleration claim. In the revised manuscript we will add a new subsection (likely in the Methods or a dedicated Complexity Analysis section) that provides FLOPs estimates for gradient evaluation, accounts for the communication volume of averaging/consensus steps, and discusses conditions (e.g., when local subsets are small and communication is overlapped with computation) under which per-iteration wall-clock time is comparable between the two regimes. This addition will make the iteration-count advantage interpretable as potential acceleration while clearly delineating the assumptions. revision: yes
-
Referee: [Examples in logistic regression and neural network training] Logistic regression and neural network examples: The manuscript uses these cases to demonstrate the iteration advantage, yet provides no breakdown of per-iteration costs (e.g., how local subset gradients plus any consensus/averaging rounds compare in arithmetic operations or communication volume to a centralized full-dataset gradient). This omission directly undermines the cross-setting comparison under the equal-time premise.
Authors: We agree that the examples lack an explicit per-iteration cost breakdown, which is necessary for a transparent comparison. We will revise the experimental sections to include tables that report (i) the number of arithmetic operations per local gradient step, (ii) the additional operations and communication volume required for averaging, and (iii) the corresponding cost of a full-batch centralized gradient. These tables will be placed alongside the iteration-count results for both logistic regression and neural-network training, allowing readers to assess the validity of the equal-time premise directly from the data. revision: yes
Circularity Check
No circularity; claims rest on stated examples without definitional or self-referential reductions
full rationale
The manuscript asserts faster convergence under decentralization via logistic regression and neural-network examples, under an explicit equal-time-per-iteration assumption. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the supplied text that would reduce any prediction to its own inputs by construction. The central claim therefore remains an empirical observation rather than a tautological re-labeling of fitted quantities or prior self-work, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning.Nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.Nature, 521(7553):436–444, 2015
2015
-
[2]
Swarm learning for decentralized and confidential clinical machine learning.Nature, 594(7862):265–270, 2021
Stefanie Warnat-Herresthal, Hartmut Schultze, Krishnaprasad Lingadahalli Shastry, Sathya- narayanan Manamohan, Saikat Mukherjee, Vishesh Garg, Ravi Sarveswara, Kristian Händler, Peter Pickkers, N Ahmad Aziz, et al. Swarm learning for decentralized and confidential clinical machine learning.Nature, 594(7862):265–270, 2021
2021
-
[3]
Using large-scale experiments and machine learning to discover theories of human decision-making.Science, 372(6547):1209–1214, 2021
Joshua C Peterson, David D Bourgin, Mayank Agrawal, Daniel Reichman, and Thomas L Griffiths. Using large-scale experiments and machine learning to discover theories of human decision-making.Science, 372(6547):1209–1214, 2021
2021
-
[4]
Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
2023
-
[5]
Wind dispersal of battery-free wireless devices.Nature, 603(7901):427–433, 2022
Vikram Iyer, Hans Gaensbauer, Thomas L Daniel, and Shyamnath Gollakota. Wind dispersal of battery-free wireless devices.Nature, 603(7901):427–433, 2022
2022
-
[6]
David Neelin, Nicholas J
Tom Beucler, Pierre Gentine, Janni Yuval, Ankitesh Gupta, Liran Peng, Jerry Lin, Sungduk Yu, Stephan Rasp, Fiaz Ahmed, Paul A O’Gorman, J. David Neelin, Nicholas J. Lutsko, and Michael Pritchard. Climate-invariant machine learning.Science Advances, 10(6):eadj7250, 2024
2024
-
[7]
Collaborative deep learning in fixed topology networks.Advances in Neural Information Processing Systems, 30, 2017
Zhanhong Jiang, Aditya Balu, Chinmay Hegde, and Soumik Sarkar. Collaborative deep learning in fixed topology networks.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[8]
Decentralized deep learning with arbitrary communication compression
Anastasia Koloskova, Tao Lin, Sebastian U Stich, and Martin Jaggi. Decentralized deep learning with arbitrary communication compression. InInternational Conference on Learning Representations, 2019
2019
-
[9]
Nedic, A
A. Nedic, A. Ozdaglar, and P. A. Parrilo. Constrained consensus and optimization in multi-agent networks.IEEE Transactions on Automatic Control, 55(4):922–938, 2010
2010
-
[10]
Extra: An exact first-order algorithm for decentralized consensus optimization.SIAM Journal on Optimization, 25(2):944–966, 2015
Wei Shi, Qing Ling, Gang Wu, and Wotao Yin. Extra: An exact first-order algorithm for decentralized consensus optimization.SIAM Journal on Optimization, 25(2):944–966, 2015
2015
-
[11]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial Intelligence and Statistics, pages 1273–1282. PMLR, 2017
2017
-
[12]
Advances and open problems in federated learning.Foundations and Trends in Machine Learning, 14(1–2):1–210, 2021
Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Ar- jun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning.Foundations and Trends in Machine Learning, 14(1–2):1–210, 2021
2021
-
[13]
Distributed optimization for control.Annual Review of Control, Robotics, and Autonomous Systems, 1(1):77–103, 2018
Angelia Nedi´c and Ji Liu. Distributed optimization for control.Annual Review of Control, Robotics, and Autonomous Systems, 1(1):77–103, 2018
2018
-
[14]
Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[15]
On the linear speedup analysis of communication efficient momentum sgd for distributed non-convex optimization
Hao Yu, Rong Jin, and Sen Yang. On the linear speedup analysis of communication efficient momentum sgd for distributed non-convex optimization. InInternational Conference on Machine Learning, pages 7184–7193. PMLR, 2019
2019
-
[16]
Smooth strongly convex interpo- lation and exact worst-case performance of first-order methods.Mathematical Programming, 161:307–345, 2017
Adrien B Taylor, Julien M Hendrickx, and François Glineur. Smooth strongly convex interpo- lation and exact worst-case performance of first-order methods.Mathematical Programming, 161:307–345, 2017
2017
-
[17]
Several performance bounds on decentralized online optimization are highly conservative and potentially misleading
Erwan Meunier and Julien M Hendrickx. Several performance bounds on decentralized online optimization are highly conservative and potentially misleading. InProc. IEEE 64th Conf. Decis. Control, pages 6201–6207. IEEE, 2025
2025
-
[18]
Springer Science & Business Media, New York, 2006
Vladimir Vapnik.Estimation of dependences based on empirical data. Springer Science & Business Media, New York, 2006
2006
-
[19]
Cambridge University Press, Cambridge, 2014
Shai Shalev-Shwartz and Shai Ben-David.Understanding machine learning: From theory to algorithms. Cambridge University Press, Cambridge, 2014. 10
2014
-
[20]
Gradient convergence in gradient methods with errors.SIAM Journal on Optimization, 10(3):627–642, 2000
Dimitri P Bertsekas and John N Tsitsiklis. Gradient convergence in gradient methods with errors.SIAM Journal on Optimization, 10(3):627–642, 2000
2000
-
[21]
Springer Science & Business Media, New York, 2013
Yurii Nesterov.Introductory lectures on convex optimization: A basic course, volume 87. Springer Science & Business Media, New York, 2013
2013
-
[22]
Distributed opti- mization and statistical learning via the alternating direction method of multipliers.Foundations and Trends in Machine learning, 3(1):1–122, 2011
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, Jonathan Eckstein, et al. Distributed opti- mization and statistical learning via the alternating direction method of multipliers.Foundations and Trends in Machine learning, 3(1):1–122, 2011
2011
-
[23]
Quasi-newton methods, motivation and theory.SIAM Review, 19(1):46–89, 1977
John E Dennis, Jr and Jorge J Moré. Quasi-newton methods, motivation and theory.SIAM Review, 19(1):46–89, 1977
1977
-
[24]
Stochastic gradient push for distributed deep learning
Mahmoud Assran, Nicolas Loizou, Nicolas Ballas, and Mike Rabbat. Stochastic gradient push for distributed deep learning. InInternational Conference on Machine Learning, pages 344–353. PMLR, 2019
2019
-
[25]
Distributed subgradient methods for multi-agent opti- mization.IEEE Transactions on Automatic Control, 54(1):48–61, 2009
Angelia Nedic and Asuman Ozdaglar. Distributed subgradient methods for multi-agent opti- mization.IEEE Transactions on Automatic Control, 54(1):48–61, 2009
2009
-
[26]
Distributed nonconvex optimization over networks
Paolo Di Lorenzo and Gesualdo Scutari. Distributed nonconvex optimization over networks. In 6th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), pages 229–232. IEEE, 2015
2015
-
[27]
Achieving geometric convergence for distributed optimization over time-varying graphs.SIAM Journal on Optimization, 27(4):2597–2633, 2017
Angelia Nedic, Alex Olshevsky, and Wei Shi. Achieving geometric convergence for distributed optimization over time-varying graphs.SIAM Journal on Optimization, 27(4):2597–2633, 2017
2017
-
[28]
Harnessing smoothness to accelerate distributed optimization.IEEE Transactions on Control of Network Systems, 5(3):1245–1260, 2017
Guannan Qu and Na Li. Harnessing smoothness to accelerate distributed optimization.IEEE Transactions on Control of Network Systems, 5(3):1245–1260, 2017
2017
-
[29]
Convergence of asynchronous distributed gradient methods over stochastic networks.IEEE Transactions on Automatic Control, 63(2):434–448, 2017
Jinming Xu, Shanying Zhu, Yeng Chai Soh, and Lihua Xie. Convergence of asynchronous distributed gradient methods over stochastic networks.IEEE Transactions on Automatic Control, 63(2):434–448, 2017
2017
-
[30]
Scaffold: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learning. In International Conference on Machine Learning, pages 5132–5143. PMLR, 2020
2020
-
[31]
Efficient federated learning against heterogeneous and non-stationary client unavailability.Advances in Neural Information Processing Systems, 37:104281–104328, 2024
Ming Xiang, Stratis Ioannidis, Edmund Yeh, Carlee Joe-Wong, and Lili Su. Efficient federated learning against heterogeneous and non-stationary client unavailability.Advances in Neural Information Processing Systems, 37:104281–104328, 2024
2024
-
[32]
The privacy power of correlated noise in decentralized learning
Youssef Allouah, Anastasia Koloskova, Aymane El Firdoussi, Martin Jaggi, and Rachid Guer- raoui. The privacy power of correlated noise in decentralized learning. InForty-first Interna- tional Conference on Machine Learning, 2024
2024
-
[33]
The non-iid data quagmire of decentralized machine learning
Kevin Hsieh, Amar Phanishayee, Onur Mutlu, and Phillip Gibbons. The non-iid data quagmire of decentralized machine learning. InInternational Conference on Machine Learning, pages 4387–4398. PMLR, 2020
2020
-
[34]
Decentralized gradient methods with time-varying uncoordinated stepsizes: Convergence analysis and privacy design.IEEE Transactions on Automatic Control, 69(8):5352–5367, 2023
Yongqiang Wang and Angelia Nedi ´c. Decentralized gradient methods with time-varying uncoordinated stepsizes: Convergence analysis and privacy design.IEEE Transactions on Automatic Control, 69(8):5352–5367, 2023
2023
-
[35]
Performance of first-order methods for smooth convex mini- mization: a novel approach.Mathematical Programming, 145(1):451–482, 2014
Yoel Drori and Marc Teboulle. Performance of first-order methods for smooth convex mini- mization: a novel approach.Mathematical Programming, 145(1):451–482, 2014
2014
-
[36]
Jump 1.0: Recent improvements to a modeling language for mathematical optimization
Miles Lubin, Oscar Dowson, Joaquim Dias Garcia, Joey Huchette, Benoît Legat, and Juan Pablo Vielma. Jump 1.0: Recent improvements to a modeling language for mathematical optimization. Mathematical Programming Computation, 15(3):581–589, 2023
2023
-
[37]
URLhttps://www.mosek.com/
MOSEK ApS.The MOSEK Optimization Software, 2019. URLhttps://www.mosek.com/
2019
-
[38]
LIBSVM: a library for support vector ma- chines.ACM Transactions on Intelligent Systems and Technology (TIST), 2(3):1–27, 2011
Chih-Chung Chang and Chih-Jen Lin. LIBSVM: a library for support vector ma- chines.ACM Transactions on Intelligent Systems and Technology (TIST), 2(3):1–27, 2011. https://www.csie.ntu.edu.tw/ cjlin/libsvmtools/datasets/binary.html
2011
-
[39]
12 fast training of support vector machines using sequential minimal optimization
John C Platt. 12 fast training of support vector machines using sequential minimal optimization. Advances in Kernel Methods, pages 185–208, 1999
1999
-
[40]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. Technical Report, 2009. https://www.cs.toronto.edu/ kriz/cifar.html. 11
2009
-
[41]
Recursive deep models for semantic compositionality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, 2013
2013
-
[42]
GLUE: A multi-task benchmark and analysis platform for natural language understanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, 2018
2018
-
[43]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186, 2019
2019
-
[44]
Wiley-Interscience, New York, 1983
Arkadi Memirovski and David Yudin.Problem complexity and method efficiency in optimization. Wiley-Interscience, New York, 1983
1983
-
[45]
Introduction to optimization.Optimization Software Inc., Publications Division, New York, 1, 1987
Boris Polyak. Introduction to optimization.Optimization Software Inc., Publications Division, New York, 1, 1987
1987
-
[46]
Semidefinite programming.SIAM Review, 38(1): 49–95, 1996
Lieven Vandenberghe and Stephen Boyd. Semidefinite programming.SIAM Review, 38(1): 49–95, 1996
1996
-
[47]
Automatic performance estimation for decentralized optimization.IEEE Transactions on Automatic Control, 68(12):7136–7150, 2023
Sebastien Colla and Julien M Hendrickx. Automatic performance estimation for decentralized optimization.IEEE Transactions on Automatic Control, 68(12):7136–7150, 2023
2023
-
[48]
Exact worst-case performance of first-order methods for composite convex optimization.SIAM Journal on Optimization, 27(3): 1283–1313, 2017
Adrien B Taylor, Julien M Hendrickx, and François Glineur. Exact worst-case performance of first-order methods for composite convex optimization.SIAM Journal on Optimization, 27(3): 1283–1313, 2017
2017
-
[49]
LeCun, C
Y . LeCun, C. Cortes, and C. Burges. The MNIST database of handwritten digits, 1994. http://yann.lecun.com/exdb/mnist/
1994
-
[50]
L. Deng. The MNIST database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012
2012
-
[51]
Push–pull gradient methods for distributed optimization in networks.IEEE Transactions on Automatic Control, 66(1):1–16, 2020
Shi Pu, Wei Shi, Jinming Xu, and Angelia Nedi´c. Push–pull gradient methods for distributed optimization in networks.IEEE Transactions on Automatic Control, 66(1):1–16, 2020
2020
-
[52]
Adaptive federated optimization,
Sashank Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcný, Sanjiv Kumar, and H. Brendan McMahan. Adaptive federated optimization, 2021. URL https://arxiv.org/abs/2003.00295
-
[53]
Ziheng Cheng, Xinmeng Huang, Pengfei Wu, and Kun Yuan. Momentum benefits non-iid federated learning simply and provably, 2024. URL https://arxiv.org/abs/2306.16504. A Performance evaluation A.1 PEP formulation It is worth noting that although numerous optimization algorithms have been proposed, quantifying and comparing their performance—typically evaluat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.