Recognition: unknown
TransSplat: Unbalanced Semantic Transport for Language-Driven 3DGS Editing
Pith reviewed 2026-05-10 02:11 UTC · model grok-4.3
The pith
TransSplat frames language-driven 3DGS editing as multi-view unbalanced semantic transport to match edited 2D evidence directly to 3D Gaussians.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
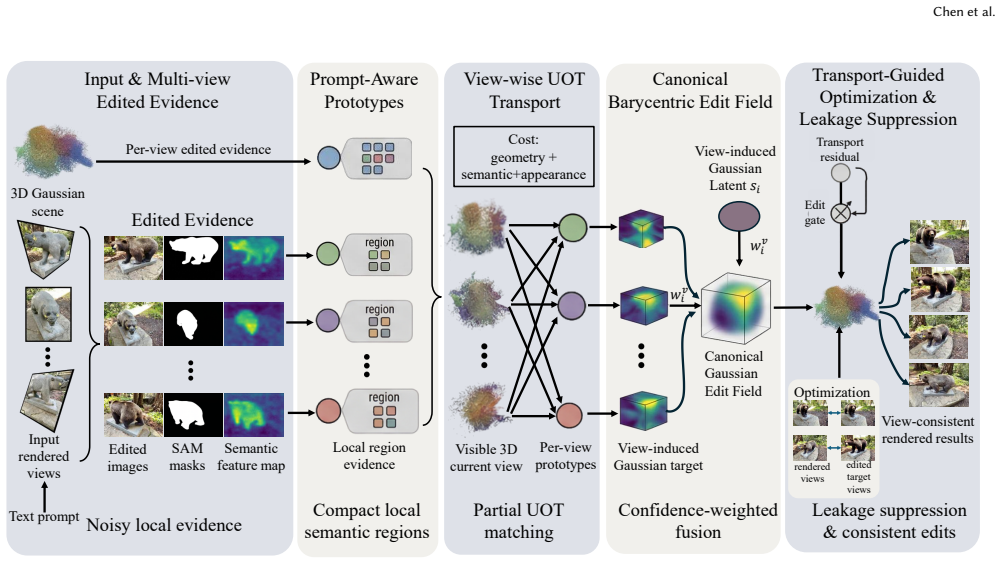
TransSplat formulates language-driven 3DGS editing as a multi-view unbalanced semantic transport problem. It establishes correspondences between visible Gaussians and view-specific editing prototypes, thereby explicitly characterizing the semantic relationship between edited 2D evidence and 3D Gaussians. The method recovers a cross-view shared canonical 3D edit field to guide unified 3D appearance updates and uses transport residuals to suppress erroneous edits in non-target regions.
What carries the argument
Multi-view unbalanced semantic transport that matches view-specific editing prototypes to visible 3D Gaussians and recovers a shared canonical 3D edit field.
If this is right
- Edits remain confined to the language-specified target region because transport residuals explicitly penalize mass assigned to non-target Gaussians.
- A single canonical 3D edit field is recovered from multiple independent 2D observations, removing the need for iterative recalibration or post-hoc fusion.
- Local editing accuracy improves because the transport cost explicitly encodes semantic similarity between 2D prototypes and 3D points.
- Structural consistency across views follows directly from the shared edit field rather than from separate consistency losses.
Where Pith is reading between the lines
- The same transport formulation could be tested on other explicit 3D representations such as point clouds or meshes if the visibility and prototype extraction steps are adapted.
- Because the method separates the transport step from the final Gaussian optimization, it may allow faster iteration when users refine language prompts without restarting the entire 3D optimization.
- The residual-suppression idea suggests a general way to add spatial masks to optimal-transport formulations whenever partial or noisy observations must be ignored.
Load-bearing premise
That the correspondences produced by unbalanced semantic transport between edited 2D prototypes and visible Gaussians will recover a single consistent 3D edit field without introducing new cross-view inconsistencies.
What would settle it
Applying the method to a scene with clear target and non-target regions and then observing visible leakage of edits outside the intended area or structural distortions across novel views would show the transport correspondences have failed to produce reliable unified updates.
Figures








read the original abstract
Language-driven 3D Gaussian Splatting (3DGS) editing provides a more convenient approach for modifying complex scenes in VR/AR. Standard pipelines typically adopt a two-stage strategy: first editing multiple 2D views, and then optimizing the 3D representation to match these edited observations. Existing methods mainly improve view consistency through multi-view feature fusion, attention filtering, or iterative recalibration. However, they fail to explicitly address a more fundamental issue: the semantic correspondence between edited 2D evidence and 3D Gaussians. To tackle this problem, we propose TransSplat, which formulates language-driven 3DGS editing as a multi-view unbalanced semantic transport problem. Specifically, our method establishes correspondences between visible Gaussians and view-specific editing prototypes, thereby explicitly characterizing the semantic relationship between edited 2D evidence and 3D Gaussians. It further recovers a cross-view shared canonical 3D edit field to guide unified 3D appearance updates. In addition, we use transport residuals to suppress erroneous edits in non-target regions, mitigating edit leakage and improving local control precision. Qualitative and quantitative results show that, compared with existing 3D editing methods centered on enhancing view consistency, TransSplat achieves superior performance in local editing accuracy and structural consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TransSplat, which reformulates language-driven 3D Gaussian Splatting editing as a multi-view unbalanced semantic transport problem. It establishes per-view correspondences between visible Gaussians and editing prototypes derived from 2D edits, recovers a shared canonical 3D edit field to drive unified appearance updates, and applies transport residuals to suppress leakage outside target regions. The central claim is that this explicit semantic modeling yields better local editing accuracy and structural consistency than prior methods relying on feature fusion or attention.
Significance. If the empirical results hold, the work supplies a transport-theoretic treatment of the 2D-to-3D semantic mapping that prior 3DGS editing pipelines have treated heuristically. The unbalanced formulation and residual suppression constitute a concrete technical contribution that could generalize to other cross-view consistency problems in scene editing.
major comments (2)
- [§4.3] §4.3 (Canonical Edit Field Recovery): the aggregation of independent per-view transport plans into a single canonical 3D edit field is presented without an explicit consistency regularizer, joint optimization, or compatibility constraint. Because the central claim of improved structural consistency rests on this recovery step producing a coherent field rather than an average of potentially conflicting signals, the absence of such a mechanism is load-bearing and requires either a formal justification or an added constraint.
- [§5.2, Table 3] §5.2 and Table 3: the quantitative superiority is asserted via metrics on local accuracy and consistency, yet the ablation isolating the contribution of the unbalanced transport versus the residual term is not reported; without this, it is difficult to attribute the gains specifically to the semantic transport formulation rather than to other pipeline choices.
minor comments (2)
- [§3.1] §3.1: the definition of the view-specific editing prototype could include an explicit equation linking the language prompt embedding to the prototype feature vector.
- [Figure 5] Figure 5: the qualitative comparison panels would benefit from zoomed insets on the edited regions to make the claimed reduction in leakage visually verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below and will revise the paper to incorporate clarifications and additional experiments where appropriate.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Canonical Edit Field Recovery): the aggregation of independent per-view transport plans into a single canonical 3D edit field is presented without an explicit consistency regularizer, joint optimization, or compatibility constraint. Because the central claim of improved structural consistency rests on this recovery step producing a coherent field rather than an average of potentially conflicting signals, the absence of such a mechanism is load-bearing and requires either a formal justification or an added constraint.
Authors: We appreciate the referee pointing out the need for clearer exposition on the canonical edit field recovery. The per-view transport plans are aggregated by mapping edit signals from visible Gaussians back to the shared 3D Gaussian parameters, which are inherently consistent across views by construction of the 3DGS representation. This produces the canonical field without an additional explicit regularizer in the current formulation. However, we agree that the manuscript would benefit from a more formal justification of this aggregation step to substantiate the structural consistency claim. In the revised manuscript, we will expand §4.3 with a detailed mathematical description of the recovery process and a justification showing how the shared 3D structure prevents conflicting signals. We will also consider adding a lightweight compatibility constraint if empirical tests indicate further improvement. revision: partial
-
Referee: [§5.2, Table 3] §5.2 and Table 3: the quantitative superiority is asserted via metrics on local accuracy and consistency, yet the ablation isolating the contribution of the unbalanced transport versus the residual term is not reported; without this, it is difficult to attribute the gains specifically to the semantic transport formulation rather than to other pipeline choices.
Authors: We agree that an explicit ablation isolating the unbalanced transport component from the residual suppression term would help attribute the observed gains more precisely. In the revised manuscript, we will add this ablation study (including variants with balanced transport and without residuals) and update Table 3 or introduce a supplementary table with the corresponding metrics on local accuracy and consistency. This will clarify the specific contribution of the semantic transport formulation. revision: yes
Circularity Check
No circularity detected; new formulation with independent empirical claims
full rationale
The paper introduces TransSplat as a novel formulation of language-driven 3DGS editing as a multi-view unbalanced semantic transport problem. It describes establishing correspondences between visible Gaussians and view-specific editing prototypes, recovering a cross-view canonical 3D edit field, and using transport residuals for suppression. These steps are presented as methodological contributions whose value is asserted via qualitative/quantitative results on local accuracy and consistency. No equations or text reduce any claimed prediction or result to a fitted input by construction, nor do they rely on self-citation chains, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The derivation chain is self-contained against external benchmarks and does not exhibit self-definitional or renaming patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T., Mildenhall, B., Verbin, D., Srinivasan, P
Barron, J. T., Mildenhall, B., Verbin, D., Srinivasan, P. P., and Hedman, P. Mip- nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5470–5479, 2022
2022
-
[2]
Brooks, T., Holynski, A., and Efros, A. A. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 18392–18402, 2023
2023
-
[3]
Dge: Direct gaussian 3d editing by consistent multi-view editing
Chen, M., Laina, I., and Vedaldi, A. Dge: Direct gaussian 3d editing by consistent multi-view editing. InEuropean conference on computer vision, pp. 74–92. Springer, 2024
2024
-
[4]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting
Chen, Y., Chen, Z., Zhang, C., Wang, F., Yang, X., Wang, Y., Cai, Z., Yang, L., Liu, H., and Lin, G. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 21476–21485, 2024
2024
-
[5]
Scaling algorithms for unbalanced transport problems.arXiv preprint arXiv:1607.05816, 2016
Chizat, L., Peyré, G., Schmitzer, B., and Vialard, F.-X. Scaling algorithms for unbalanced transport problems.arXiv preprint arXiv:1607.05816, 2016
-
[6]
Unbalanced optimal trans- port: Dynamic and kantorovich formulations.Journal of Functional Analysis, 274 (11):3090–3123, 2018
Chizat, L., Peyré, G., Schmitzer, B., and Vialard, F.-X. Unbalanced optimal trans- port: Dynamic and kantorovich formulations.Journal of Functional Analysis, 274 (11):3090–3123, 2018
2018
-
[7]
and Doucet, A
Cuturi, M. and Doucet, A. Fast computation of wasserstein barycenters. In International conference on machine learning, pp. 685–693. PMLR, 2014
2014
-
[8]
and Wang, Y.-X
Dong, J. and Wang, Y.-X. Vica-nerf: View-consistency-aware 3d editing of neural radiance fields.Advances in Neural Information Processing Systems, 36:61466– 61477, 2023
2023
-
[9]
A., Holynski, A., and Kanazawa, A
Haque, A., Tancik, M., Efros, A. A., Holynski, A., and Kanazawa, A. Instruct- nerf2nerf: Editing 3d scenes with instructions. InProceedings of the IEEE/CVF international conference on computer vision, pp. 19740–19750, 2023
2023
-
[10]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., and Cohen-Or, D. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[12]
3dego: 3d editing on the go! InEuropean Conference on Computer Vision, pp
Khalid, U., Iqbal, H., Farooq, A., Hua, J., and Chen, C. 3dego: 3d editing on the go! InEuropean Conference on Computer Vision, pp. 73–89. Springer, 2024
2024
-
[13]
C., Lo, W.-Y., et al
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026, 2023
2023
-
[14]
Flowedit: Inversion-free text-based editing using pre-trained flow models
Kulikov, V., Kleiner, M., Huberman-Spiegelglas, I., and Michaeli, T. Flowedit: Inversion-free text-based editing using pre-trained flow models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 19721–19730, 2025
2025
-
[15]
I., Park, H., Seo, J., Park, E., Park, H., Baek, H
Lee, D. I., Park, H., Seo, J., Park, E., Park, H., Baek, H. D., Shin, S., Kim, S., and Kim, S. Editsplat: Multi-view fusion and attention-guided optimization for view- consistent 3d scene editing with 3d gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 11135–11145, 2025
2025
-
[16]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pp. 38–55. Springer, 2024
2024
-
[17]
Chordedit: One-step low-energy transport for image editing.arXiv preprint arXiv:2602.19083, 2026
Lu, L., Chen, X., Guo, M., Li, S., Wang, J., and Shi, Y. Chordedit: One-step low-energy transport for image editing.arXiv preprint arXiv:2602.19083, 2026
-
[18]
P., Tancik, M., Barron, J
Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., and Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[19]
Null-text inversion for editing real images using guided diffusion models
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., and Cohen-Or, D. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6038–6047, 2023
2023
-
[20]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fer- nandez, P., Haziza, D., Massa, F., El-Nouby, A., et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
and Cuturi, M.Computational optimal transport: With applications to data science
Peyré, G. and Cuturi, M.Computational optimal transport: With applications to data science. Now Foundations and Trends, 2019
2019
-
[22]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J. T., and Mildenhall, B. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review arXiv 2022
-
[23]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pp. 8748–8763. PmLR, 2021
2021
-
[24]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022
2022
-
[25]
MMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models
Shi, Y., Xie, Y., Guo, M., Lu, L., Huang, M., Wang, J., Zhu, Z., Xu, B., and Huang, Z. Mmerror: A benchmark for erroneous reasoning in vision-language models. arXiv preprint arXiv:2601.03331, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Clip-nerf: Text-and-image driven manipulation of neural radiance fields
Wang, C., Chai, M., He, M., Chen, D., and Liao, J. Clip-nerf: Text-and-image driven manipulation of neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 3835–3844, 2022
2022
-
[27]
Gaussianeditor: Editing 3d gaussians delicately with text instructions
Wang, J., Fang, J., Zhang, X., Xie, L., and Tian, Q. Gaussianeditor: Editing 3d gaussians delicately with text instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 20902–20911, 2024
2024
-
[28]
Wu, J., Bian, J.-W., Li, X., Wang, G., Reid, I., Torr, P., and Prisacariu, V. A. Gaussctrl: Multi-view consistent text-driven 3d gaussian splatting editing. InEuropean conference on computer vision, pp. 55–71. Springer, 2024
2024
-
[29]
Blend- edmvs: A large-scale dataset for generalized multi-view stereo networks
Yao, Y., Luo, Z., Li, S., Zhang, J., Ren, Y., Zhou, L., Fang, T., and Quan, L. Blend- edmvs: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1790–1799, 2020
2020
-
[30]
Text2nerf: Text-driven 3d scene generation with neural radiance fields.IEEE Transactions on Visualization and Computer Graphics, 30(12):7749–7762, 2024
Zhang, J., Li, X., Wan, Z., Wang, C., and Liao, J. Text2nerf: Text-driven 3d scene generation with neural radiance fields.IEEE Transactions on Visualization and Computer Graphics, 30(12):7749–7762, 2024
2024
-
[31]
Adding conditional control to text-to-image diffusion models
Zhang, L., Rao, A., and Agrawala, M. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pp. 3836–3847, 2023
2023
-
[32]
Dreameditor: Text-driven 3d scene editing with neural fields
Zhuang, J., Wang, C., Lin, L., Liu, L., and Li, G. Dreameditor: Text-driven 3d scene editing with neural fields. InSIGGRAPH Asia 2023 conference papers, pp. 1–10, 2023. Chen et al. TransSplat: Unbalanced Semantic Transport for Language-Driven 3DGS Editing Supplementary Material Contents Abstract 1 1 Introduction 2 2 Related Work 3 3 Method 3 3.1 Problem S...
2023
-
[33]
Your feedback will help improve the quality of diffusion model-based editing techniques
Purpose: This study aims to evaluate the effectiveness and perceived quality of various 3DGS scene editing methods. Your feedback will help improve the quality of diffusion model-based editing techniques. Instructions:
-
[34]
You will see a 2D image of an original 3DGS scene, followed by several edited versions generated using different methods
-
[35]
Please rate each processed image based on the following criteria
-
[36]
Evaluation Criteria:
Please use a rating scale from 1 (Poor) to 5 (Excellent). Evaluation Criteria:
-
[37]
Target Semantics Alignment: Assess the extent to which the edited scene accurately and convincingly reflects the intended semantic changes
-
[38]
Background Preservation: Assess the consistency of the unedited areas in the image with the original image (e.g., no unnecessary distortion, color shifts, or texture changes in the background)
-
[39]
older with wrinkles
Overall Coherence: Evaluate the visual plausibility and naturalness of the entire edited image by considering both the edited portion and the background. Image Evaluation Example: (Below is a demonstration of one group of images to serve as an example for the evaluation process.) Real image Method A Method B Method C Method D Criteria Method A Method B Me...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.