Recognition: unknown
TeamFusion: Supporting Open-ended Teamwork with Multi-Agent Systems
Pith reviewed 2026-05-10 00:40 UTC · model grok-4.3
The pith
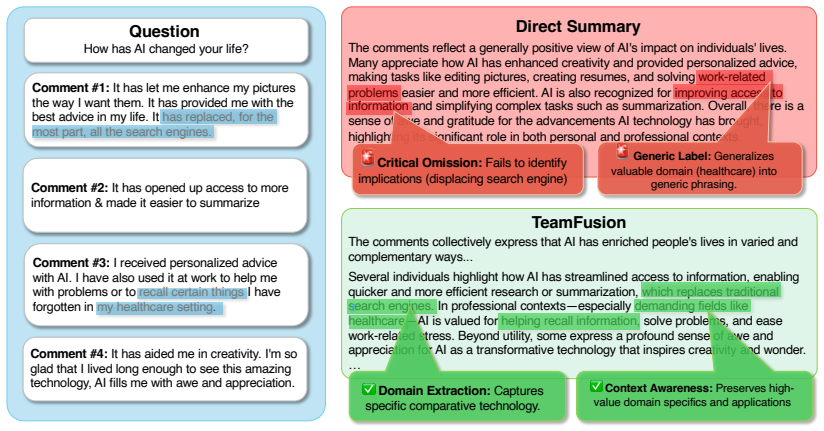
TeamFusion uses proxy agents and structured discussions to reconcile diverse views in open-ended teamwork better than direct aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TeamFusion instantiates a proxy agent for each team member conditioned on their expressed preferences, conducts a structured discussion to surface agreements and disagreements, and synthesizes more consensus-oriented deliverables that feed into new iterations of discussion and refinement, outperforming direct aggregation baselines across metrics, tasks, and team configurations.
What carries the argument
Proxy agents conditioned on expressed preferences that enable structured multi-agent discussion and iterative synthesis of deliverables.
If this is right
- Deliverables from TeamFusion receive higher ratings for how well individual views are represented than those from direct aggregation.
- Final outputs show measurably stronger consensual strength on the same tasks and team sizes.
- The gains hold across different teamwork tasks and varying team configurations.
- Iterative cycles of discussion and synthesis produce progressively better-aligned results.
Where Pith is reading between the lines
- The same proxy-and-discussion structure could be tested on larger groups or longer projects where viewpoint drift becomes a bigger issue.
- If the representation holds, the method might transfer to domains such as collaborative writing or joint planning where participants cannot meet in person.
Load-bearing premise
Proxy agents conditioned on expressed preferences can accurately represent individual team members' viewpoints during discussion without distortions from the underlying AI model.
What would settle it
A study in which actual team members review the synthesized deliverables blind and report no higher sense of personal view representation or consensual strength than they report for directly aggregated versions.
Figures










read the original abstract
In open-ended domains, teams must reconcile diverse viewpoints to produce strong deliverables. Answer aggregation approaches commonly used in closed domains are ill-suited to this setting, as they tend to suppress minority perspectives rather than resolve underlying disagreements. We present TeamFusion, a multi-agent system designed to support teamwork in open-ended domains by: 1. Instantiating a proxy agent for each team member conditioned on their expressed preferences; 2. Conducting a structured discussion to surface agreements and disagreements; and 3. Synthesizing more consensus-oriented deliverables that feed into new iterations of discussion and refinement. We evaluate TeamFusion on two teamwork tasks where team members can assess how well their individual views are represented in team decisions and how consensually strong the final deliverables are, finding that it outperforms direct aggregation baselines across metrics, tasks, and team configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TeamFusion, a multi-agent system for open-ended teamwork. It creates a proxy agent for each team member conditioned on their expressed preferences, runs a structured discussion protocol to surface agreements and disagreements, and synthesizes consensus-oriented deliverables that can be fed back into further iterations. The central empirical claim is that this approach outperforms direct aggregation baselines on two teamwork tasks, as measured by team-member ratings of individual-view representation in decisions and consensual strength of deliverables, across multiple metrics, tasks, and team configurations.
Significance. If the empirical results prove robust after the addition of missing methodological details, the work would offer a concrete mechanism for multi-agent systems to reconcile diverse viewpoints in open-ended domains without the minority-suppression problem typical of aggregation methods. The combination of proxy conditioning, structured discussion, and iterative synthesis is a distinctive contribution relative to existing LLM-based collaboration frameworks.
major comments (2)
- [Evaluation section] The central claim of outperformance (abstract and Evaluation section) rests on member-rated metrics for representation and consensual strength, yet the manuscript supplies no information on experimental design, team sizes or compositions, preference-elicitation format, number of iterations, statistical tests, or controls for confounds. This absence renders the reported gains uninterpretable and load-bearing for the paper's main result.
- [System Description] The proxy-agent component (System Description) is presented as faithfully representing individual preferences via conditioning, but no validation experiment, fidelity metric, or ablation that isolates the proxy from the discussion protocol is reported. Without such evidence, any measured advantage could arise from base-model priors rather than the intended fusion mechanism, directly undermining the comparison to direct-aggregation baselines.
minor comments (1)
- [Abstract] The abstract refers to 'two teamwork tasks' without naming or briefly characterizing them; adding one sentence of description would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that the current manuscript lacks critical methodological details in the Evaluation and System Description sections, which weakens the interpretability of the results. We will revise the paper to address both major comments by adding the requested information, experiments, and ablations. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Evaluation section] The central claim of outperformance (abstract and Evaluation section) rests on member-rated metrics for representation and consensual strength, yet the manuscript supplies no information on experimental design, team sizes or compositions, preference-elicitation format, number of iterations, statistical tests, or controls for confounds. This absence renders the reported gains uninterpretable and load-bearing for the paper's main result.
Authors: We agree that the Evaluation section is insufficiently detailed and that this omission makes the empirical claims difficult to interpret. In the revised manuscript we will expand the section to specify: team sizes (3–5 members), team composition method (participants recruited with pre-elicited preference profiles on task-relevant dimensions), preference-elicitation format (structured Likert-scale questionnaires plus open-ended statements), number of iterations (fixed at 4 per task), statistical tests (paired Wilcoxon signed-rank tests with effect sizes and p-values), and confound controls (same base LLM across conditions, randomized task order, and a no-proxy baseline). We will also add an appendix with the full experimental protocol and summary statistics. revision: yes
-
Referee: [System Description] The proxy-agent component (System Description) is presented as faithfully representing individual preferences via conditioning, but no validation experiment, fidelity metric, or ablation that isolates the proxy from the discussion protocol is reported. Without such evidence, any measured advantage could arise from base-model priors rather than the intended fusion mechanism, directly undermining the comparison to direct-aggregation baselines.
Authors: We acknowledge that the manuscript currently provides no direct validation or ablation isolating the proxy-agent component. In the revision we will add (1) a fidelity evaluation in which original team members rate how accurately their proxy reproduces their views on held-out preference items, and (2) an ablation comparing full TeamFusion against (a) direct aggregation, (b) independent proxy generation without structured discussion, and (c) proxies conditioned on random preferences. These additions will quantify the contribution of proxy conditioning versus the discussion protocol and help rule out base-model effects. revision: yes
Circularity Check
No circularity: empirical system evaluation independent of internal definitions
full rationale
The paper introduces TeamFusion as a multi-agent architecture with proxy agents, structured discussion, and iterative synthesis, then reports empirical outperformance versus direct aggregation baselines on two tasks using human ratings of view representation and consensus strength. No equations, fitted parameters, predictions derived from the system itself, or self-referential definitions appear in the provided text. The central claims rest on external comparisons to baselines and human judgments, which are falsifiable outside the system's own outputs and do not reduce to the inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked to force the result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Proxy agents conditioned on expressed preferences can faithfully represent team members' viewpoints in multi-agent interactions.
- domain assumption Structured discussion between proxies can surface genuine agreements and disagreements without model-induced artifacts.
invented entities (1)
-
Proxy agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Prompt leakage effect and mitigation strate- gies for multi-turn LLM applications. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1255–1275, Miami, Florida, US. Association for Computational Linguistics. Adithya Bhaskar, Alex Fabbri, and Greg Durrett. 2023. Prompted opinion summarization w...
work page internal anchor Pith review arXiv 2024
-
[2]
arXiv preprint arXiv:2403.12482 , year=
Not what you’ve signed up for: Compromis- ing real-world llm-integrated applications with indi- rect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90. Xudong Guo, Kaixuan Huang, Jiale Liu, Wenhui Fan, Natalia Vélez, Qingyun Wu, Huazheng Wang, Thomas L Griffiths, and Mengdi Wang. 2024. Em- bodied...
-
[3]
Debate-to-write: A persona-driven multi-agent framework for diverse argument generation. InPro- ceedings of the 31st International Conference on Computational Linguistics, pages 4689–4703. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and 1 oth- ers. 2025. A survey on ...
-
[4]
Survey on factuality in large language models: Knowledge, retrieval and domain-specificity,
Survey on factuality in large language models: Knowledge, retrieval and domain-specificity.arXiv preprint arXiv:2310.07521. Zheng Wang, Zhongyang Li, Zeren Jiang, Dandan Tu, and Wei Shi. 2024. Crafting personalized agents through retrieval-augmented generation on editable memory graphs. InConference on Empirical Meth- ods in Natural Language Processing. J...
-
[5]
A survey on trustworthy llm agents: Threats and countermeasures. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 6216–6226. Haopeng Zhang, Philip S Yu, and Jiawei Zhang. 2025. A systematic survey of text summarization: From statistical methods to large language models.ACM Computing Surveys, 57(11):1–41. ...
-
[6]
strengthen product visibil- ity
Each team completed two ad-brief tasks (Brief A and Brief B). Wecounterbalanced condition or- derat the team level: (i) Team 1 used TeamFusion on Brief A and the baseline on Brief B; (ii) Team 2 used the baseline on Brief A and TeamFusion on Brief B. This controls for brief-specific difficulty and order effects. H.3 Materials Ad briefs.We prepared two ad ...
-
[7]
This represents your perspective in this discussion
**Understand and Hold Your Position**: Carefully read and internalize the viewpoint expressed in your comment. This represents your perspective in this discussion. Stay true to the sentiment and reasoning of your assigned comment
-
[8]
Go straight to the core point
**Advocate Effectively**: - Express the key points and reasoning behind your position - Always speak in concise and at most 2 paragraphs. Go straight to the core point. - Avoid adding any additional personal information or experience into discussion aside from given comments
-
[9]
**Engage Constructively**: - Listen to and acknowledge other participants’ viewpoints - Identify common ground where it exists - Respectfully challenge points you disagree with, using reasoning and evidence
-
[10]
**Contribute to Comprehensive Understanding**: Help ensure that your perspective is clearly understood and represented in the broader discussion, especially if it represents a minority or less common viewpoint. Remember: The goal is not to "win" the debate, but to ensure all perspectives—including minority opinions—are thoroughly heard, understood, and co...
-
[11]
RANKING: Establish a ranked list of images from best to worst, considering both aesthetic appeal and alignment with the creative brief
-
[12]
DESIGN IMPROVEMENT: Discuss how to enhance and combine the best elements from top 3 performing images. Consider: - Primary composition and layout structure from the strongest images - Visual elements that should be integrated or refined - Color schemes and typography that work best - Specific adjustments needed to balance different concerns
-
[13]
When you propose changes to improve, ground the instructions on top 3 performing images
SYNTHESIS: Develop a cohesive approach that merges strengths from the top 3 performing images while addressing any weaknesses identified in the discussion. When you propose changes to improve, ground the instructions on top 3 performing images. Share your reasoning and be open to different perspectives as you work toward both a final ranking and concrete ...
-
[14]
**FINAL RANKING**: Identify the consensus ranking of images from best to worst
-
[15]
Early messages may contain initial disagreements or positions that were later changed
**EDITING DIRECTIONS**: Extract specific instructions for creating an improved design by combining elements from different images ## Analysis Instructions: - Start from the END of the conversation and work backwards - the most recent messages contain the final consensus and should be given the highest priority. Early messages may contain initial disagreem...
-
[16]
Example templates include: Use the overall layout and structure from Image [number], specifically [describe the compositional elements, positioning, or arrangement]
**Primary Composition**. Example templates include: Use the overall layout and structure from Image [number], specifically [describe the compositional elements, positioning, or arrangement]
-
[17]
**Visual Elements Integration**. Example templates include: - Incorporate [specific visual element] from Image [number], such as [detailed description] - Add [specific design feature] from Image [number], particularly [detailed description] - Include [specific element] from Image [number], focusing on [detailed description]
-
[18]
**Color and Typography Refinements**. Example templates include: - Adopt the [color scheme/typography style] from Image [number], specifically [details] - Modify [specific aspect] using the approach seen in Image [number]
-
[19]
final_ranking
**Final Adjustments**. Example templates include: - Ensure [specific requirement based on discussion] - Balance [specific concern raised in discussion] - Maintain [specific positive aspect mentioned] ## Important Guidelines: - Always reference images by their specific numbers (Image 1, Image 2, etc.) - Be concrete and specific about visual elements (color...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.