Recognition: unknown
Volume Transformer: Revisiting Vanilla Transformers for 3D Scene Understanding
Pith reviewed 2026-05-10 03:30 UTC · model grok-4.3
The pith
A minimally adapted vanilla Transformer processes 3D scenes as volumetric tokens and surpasses specialized backbones when trained at scale across datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
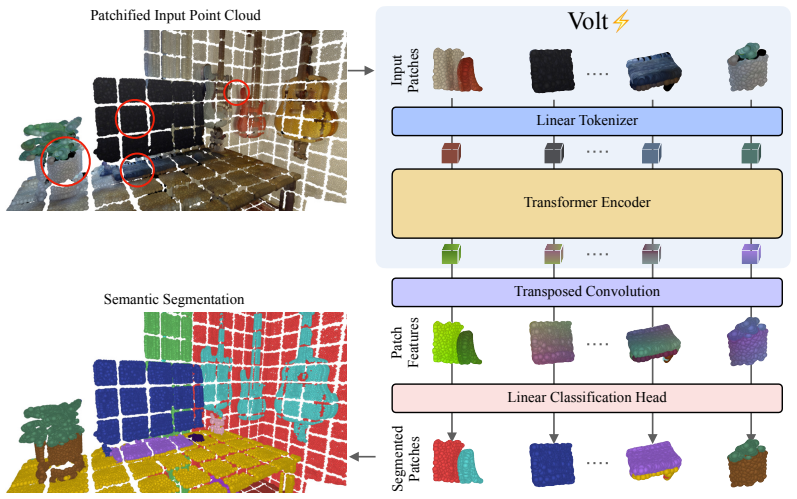
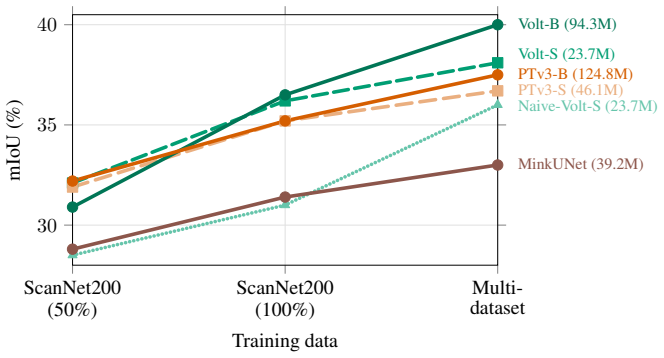
The central discovery is that the Volume Transformer, using volumetric patch tokens and full self-attention with 3D rotary positional embeddings, can serve as a general-purpose backbone for 3D scenes. After addressing shortcut learning through a data-efficient training strategy involving augmentations, regularization, and teacher distillation, and further scaling supervision by joint training on multiple indoor and outdoor datasets, it achieves state-of-the-art performance across benchmarks and in instance segmentation pipelines.
What carries the argument
Volumetric patch tokens processed with global self-attention and extended rotary positional embeddings, supported by a training pipeline of 3D augmentations, regularization, and convolutional distillation.
Load-bearing premise
The combination of strong 3D augmentations, regularization, and distillation from a convolutional teacher fully prevents shortcut learning on existing 3D datasets without requiring per-dataset tuning.
What would settle it
A controlled experiment showing that Volt trained only on a single large dataset without the proposed recipe performs worse than current specialized backbones, or that multi-dataset scaling does not yield superior gains compared to domain-specific models.
Figures


read the original abstract
Transformers have become a common foundation across deep learning, yet 3D scene understanding still relies on specialized backbones with strong domain priors. This keeps the field isolated from the broader Transformer ecosystem, limiting the transfer of new advances as well as the benefits of increasingly optimized software and hardware stacks. To bridge this gap, we adapt the vanilla Transformer encoder to 3D scenes with minimal modifications. Given an input 3D scene, we partition it into volumetric patch tokens, process them with full global self-attention, and inject positional information via a 3D extension of rotary positional embeddings. We call the resulting model the Volume Transformer (Volt) and apply it to 3D semantic segmentation. Naively training Volt on standard 3D benchmarks leads to shortcut learning, highlighting the limited scale of current 3D supervision. To overcome this, we introduce a data-efficient training recipe based on strong 3D augmentations, regularization, and distillation from a convolutional teacher, making Volt competitive with state-of-the-art methods. We then scale supervision through joint training on multiple datasets and show that Volt benefits more from increased scale than domain-specific 3D backbones, achieving state-of-the-art results across indoor and outdoor datasets. Finally, when used as a drop-in backbone in a standard 3D instance segmentation pipeline, Volt again sets a new state of the art, highlighting its potential as a simple, scalable, general-purpose backbone for 3D scene understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Volume Transformer (Volt), a minimally modified vanilla Transformer encoder for 3D scene understanding. Input scenes are partitioned into volumetric patch tokens processed with full global self-attention and 3D rotary positional embeddings. Naive training on standard benchmarks leads to shortcut learning due to limited 3D scale; this is addressed via a data-efficient recipe of strong 3D augmentations, regularization, and distillation from a convolutional teacher. Joint training across multiple datasets then demonstrates that Volt benefits more from scale than domain-specific 3D backbones, yielding SOTA semantic segmentation on indoor/outdoor datasets. Volt is also shown to set a new SOTA when used as a drop-in backbone in a standard 3D instance segmentation pipeline.
Significance. If the empirical claims hold under fair comparisons, the work is significant as it provides evidence that a simple, general-purpose vanilla Transformer can match or exceed specialized 3D architectures when properly scaled and trained. This could help integrate 3D scene understanding into the broader Transformer ecosystem, facilitating transfer of scaling techniques, software optimizations, and hardware support. The scaling results, if reproducible and controlled, would be a useful data point on architecture-agnostic benefits of increased supervision in 3D.
major comments (2)
- [§4 (scaling experiments) and associated tables] §4 (scaling experiments) and associated tables: The central claim that 'Volt benefits more from increased scale than domain-specific 3D backbones' is load-bearing. The manuscript must explicitly document that the comparison baselines (e.g., MinkowskiNet, Point Transformer variants) received identical joint multi-dataset training, the same strong 3D augmentations, regularization, and distillation from the convolutional teacher. If the recipe was applied only to Volt, the differential scaling advantage cannot be attributed to the vanilla architecture.
- [§3.2 (training recipe) and ablation tables] §3.2 (training recipe) and ablation tables: The recipe is presented as overcoming shortcut learning, yet the paper provides limited quantitative ablations isolating the contribution of each component (augmentations vs. regularization vs. distillation). This weakens the ability to attribute success to the transformer backbone rather than the training procedure.
minor comments (2)
- [Abstract] Abstract: Claims of SOTA performance are made without any numerical results, dataset names, or baseline deltas; adding 1-2 key metrics would improve readability and impact.
- [§2.2] Notation: The 3D extension of rotary embeddings is introduced but the exact formulation (e.g., how angles are computed per axis) should be stated in a single equation for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scaling experiments and training recipe. We address each major comment below and will revise the manuscript to improve clarity and strengthen the empirical claims.
read point-by-point responses
-
Referee: [§4 (scaling experiments) and associated tables] §4 (scaling experiments) and associated tables: The central claim that 'Volt benefits more from increased scale than domain-specific 3D backbones' is load-bearing. The manuscript must explicitly document that the comparison baselines (e.g., MinkowskiNet, Point Transformer variants) received identical joint multi-dataset training, the same strong 3D augmentations, regularization, and distillation from the convolutional teacher. If the recipe was applied only to Volt, the differential scaling advantage cannot be attributed to the vanilla architecture.
Authors: We agree that the differential scaling claim requires controlled, identical training conditions to be fully attributable to the architecture. The current manuscript compares Volt (trained with the full recipe) against baselines using their originally published numbers, which did not employ our joint multi-dataset training, augmentations, regularization, or distillation. To resolve this, we will add new controlled experiments in the revision: we will retrain MinkowskiNet and Point Transformer variants using exactly the same joint training protocol, augmentations, regularization, and teacher distillation as Volt. Updated tables and text in §4 will report these results, allowing a direct apples-to-apples comparison of scaling behavior. revision: yes
-
Referee: [§3.2 (training recipe) and ablation tables] §3.2 (training recipe) and ablation tables: The recipe is presented as overcoming shortcut learning, yet the paper provides limited quantitative ablations isolating the contribution of each component (augmentations vs. regularization vs. distillation). This weakens the ability to attribute success to the transformer backbone rather than the training procedure.
Authors: We acknowledge that the existing ablations in §3.2 demonstrate the overall effectiveness of the recipe but do not fully isolate the marginal contribution of each element (strong 3D augmentations, regularization, and distillation). While some component-wise results are present (particularly for distillation), we agree that more granular quantitative breakdowns would strengthen the analysis. In the revision we will expand the ablation tables and accompanying text to include separate runs isolating each component and their combinations, clarifying how much of the performance gain is due to the training procedure versus the vanilla Transformer backbone itself. revision: yes
Circularity Check
No significant circularity: purely empirical adaptation and scaling results
full rationale
The paper describes an empirical adaptation of the vanilla Transformer encoder to 3D volumetric patches using rotary embeddings, followed by a training recipe of augmentations, regularization, and teacher distillation to address shortcut learning on limited 3D data. It then reports results from joint multi-dataset training and drop-in use in instance segmentation. No derivation chain, equations, or fitted parameters are presented as predictions; all claims rest on benchmark comparisons. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear. The work is self-contained against external public benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All You Need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” inNeurIPS, 2017
2017
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthineret al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” inICLR, 2021
2021
-
[3]
Language Models are Few-Shot Learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sas- try, A. Askellet al., “Language Models are Few-Shot Learners,” inNeurIPS, 2020
2020
-
[4]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,” inICML, 2023
2023
-
[5]
Learning Transferable Visual Models From Natural Language Supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning Transferable Visual Models From Natural Language Supervision,” inICML, 2021
2021
-
[6]
RoFormer: Enhanced Transformer with Rotary Position Embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: Enhanced Transformer with Rotary Position Embedding,”Neurocomputing, 2024
2024
-
[7]
Masked Autoencoders Are Scalable Vision Learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” inCVPR, 2022
2022
-
[8]
Query-Key Normalization for Transformers,
A. Henry, P. R. Dachapally, S. S. Pawar, and Y . Chen, “Query-Key Normalization for Transformers,” in Findings of the Association for Computational Linguistics: EMNLP 2020, 2020, pp. 4246–4253
2020
-
[9]
NVIDIA Hopper Architecture In-Depth,
M. Andersch, G. Palmer, R. Krashinsky, N. Stam, V . Mehta, G. Brito, and S. Ramaswamy, “NVIDIA Hopper Architecture In-Depth,” https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/, 2022, NVIDIA Technical Blog. Accessed 2026-02-23
2022
-
[10]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´e, “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,” inNeurIPS, 2022
2022
-
[11]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning,
T. Dao, “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning,” inICLR, 2024
2024
-
[12]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision,
J. Shah, G. Bikshandi, Y . Zhang, V . Thakkar, P. Ramani, and T. Dao, “FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision,” inNeurIPS, 2024
2024
-
[13]
4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks,
C. Choy, J. Gwak, and S. Savarese, “4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks,” inCVPR, 2019
2019
-
[14]
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR Segmentation,
X. Zhu, H. Zhou, T. Wang, F. Hong, Y . Ma, W. Li, H. Li, and D. Lin, “Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR Segmentation,” inCVPR, 2021
2021
-
[15]
Mask3D: Mask Transformer for 3D Semantic Instance Segmentation,
J. Schult, F. Engelmann, A. Hermans, O. Litany, S. Tang, and B. Leibe, “Mask3D: Mask Transformer for 3D Semantic Instance Segmentation,” inICRA, 2023
2023
-
[16]
OneFormer3D: One Transformer for Unified Point Cloud Segmentation,
M. Kolodiazhnyi, A. V orontsova, A. Konushin, and D. Rukhovich, “OneFormer3D: One Transformer for Unified Point Cloud Segmentation,” inCVPR, 2024
2024
-
[17]
Mask4Former: Mask Transformer for 4D Panoptic Segmentation,
K. Yilmaz, J. Schult, A. Nekrasov, and B. Leibe, “Mask4Former: Mask Transformer for 4D Panoptic Segmentation,” inICRA, 2024. 12
2024
-
[18]
Point Transformer,
H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V . Koltun, “Point Transformer,” inICCV, 2021
2021
-
[19]
Point Transformer V2: Grouped Vector Attention and Partition-based Pooling,
X. Wu, Y . Lao, L. Jiang, X. Liu, and H. Zhao, “Point Transformer V2: Grouped Vector Attention and Partition-based Pooling,” inNeurIPS, 2022
2022
-
[20]
Point Transformer V3: Simpler, Faster, Stronger,
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao, “Point Transformer V3: Simpler, Faster, Stronger,” inCVPR, 2024
2024
-
[21]
Swin3D: A Pre- trained Transformer Backbone for 3D Indoor Scene Understanding,
Y .-Q. Yang, Y .-X. Guo, J.-Y . Xiong, Y . Liu, H. Pan, P.-S. Wang, X. Tong, and B. Guo, “Swin3D: A Pre- trained Transformer Backbone for 3D Indoor Scene Understanding,”arXiv preprint arXiv:2304.06906, 2023
-
[22]
Stratified Transformer for 3D Point Cloud Segmentation,
X. Lai, J. Liu, L. Jiang, L. Wang, H. Zhao, S. Liu, X. Qi, and J. Jia, “Stratified Transformer for 3D Point Cloud Segmentation,” inCVPR, 2022
2022
-
[23]
Spherical Transformer for LiDAR-Based 3D Recognition,
X. Lai, Y . Chen, F. Lu, J. Liu, and J. Jia, “Spherical Transformer for LiDAR-Based 3D Recognition,” in CVPR, 2023
2023
-
[24]
arXiv preprint arXiv:2512.13689 (2025) 21
Y . Yue, D. Robert, J. Wang, S. Hong, J. D. Wegner, C. Rupprecht, and K. Schindler, “LitePT: Lighter Yet Stronger Point Transformer,”arXiv preprint arXiv:2512.13689, 2025
-
[25]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schel- ten, A. Vaughanet al., “The Llama 3 Herd of Models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ram ´e, M. Rivi`ereet al., “Gemma 3 Technical Report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J´egou, P. Labatut, and P. Bojanowski, “DINOv3,”arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huanget al., “SAM 3: Segment Anything with Concepts,”arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes,” inCVPR, 2017
2017
-
[30]
nuScenes: A Multimodal Dataset for Autonomous Driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuScenes: A Multimodal Dataset for Autonomous Driving,” inCVPR, 2020
2020
-
[31]
On the Relationship between Self-Attention and Convolu- tional Layers,
J.-B. Cordonnier, A. Loukas, and M. Jaggi, “On the Relationship between Self-Attention and Convolu- tional Layers,” inICLR, 2020
2020
-
[32]
Do Vision Transformers See Like Convolutional Neural Networks?
M. Raghu, T. Unterthiner, S. Kornblith, C. Zhang, and A. Dosovitskiy, “Do Vision Transformers See Like Convolutional Neural Networks?” inNeurIPS, 2021
2021
-
[33]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling Laws for Neural Language Models,”arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[34]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” inCVPR, 2009
2009
-
[35]
Revisiting Unreasonable Effectiveness of Data in Deep Learning Era,
C. Sun, A. Shrivastava, S. Singh, and A. Gupta, “Revisiting Unreasonable Effectiveness of Data in Deep Learning Era,” inICCV, 2017
2017
-
[36]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki, “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs,”arXiv preprint arXiv:2111.02114, 2021
work page internal anchor Pith review arXiv 2021
-
[37]
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers,
A. P. Steiner, A. Kolesnikov, X. Zhai, R. Wightman, J. Uszkoreit, and L. Beyer, “How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers,”TMLR, 2022
2022
-
[38]
Training Data-Efficient Image Transformers & Distillation Through Attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J´egou, “Training Data-Efficient Image Transformers & Distillation Through Attention,” inICML, 2021
2021
-
[39]
Mix3D: Out-of-Context Data Augmen- tation for 3D Scenes,
A. Nekrasov, J. Schult, O. Litany, B. Leibe, and F. Engelmann, “Mix3D: Out-of-Context Data Augmen- tation for 3D Scenes,” in3DV, 2021
2021
-
[40]
Rethinking the Inception Architecture for Computer Vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the Inception Architecture for Computer Vision,” inCVPR, 2016
2016
-
[41]
Deep Networks with Stochastic Depth,
G. Huang, Y . Sun, Z. Liu, D. Sedra, and K. Q. Weinberger, “Deep Networks with Stochastic Depth,” in ECCV, 2016
2016
-
[42]
ScanNet++: A High-Fidelity Dataset of 3D Indoor Scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “ScanNet++: A High-Fidelity Dataset of 3D Indoor Scenes,” inICCV, 2023
2023
-
[43]
ARKitScenes - a diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data,
G. Baruch, Z. Chen, A. Dehghan, T. Dimry, Y . Feigin, P. Fu, T. Gebauer, B. Joffe, D. Kurz, A. Schwartz, and E. Shulman, “ARKitScenes - a diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data,” inNeurIPS, 2021. 13
2021
-
[44]
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation,” inCVPR, 2017
2017
-
[45]
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space,” inNeurIPS, 2017
2017
-
[46]
Pointconv: Deep Convolutional Networks on 3D Point Clouds,
W. Wu, Z. Qi, and L. Fuxin, “Pointconv: Deep Convolutional Networks on 3D Point Clouds,” inCVPR, 2019
2019
-
[47]
KPConv: Flexible and Deformable Convolution for Point Clouds,
H. Thomas, C. R. Qi, J.-E. Deschaud, B. Marcotegui, F. Goulette, and L. J. Guibas, “KPConv: Flexible and Deformable Convolution for Point Clouds,” inCVPR, 2019
2019
-
[48]
KPConvX: Modernizing Kernel Point Convolu- tion with Kernel Attention,
H. Thomas, Y .-H. H. Tsai, T. D. Barfoot, and J. Zhang, “KPConvX: Modernizing Kernel Point Convolu- tion with Kernel Attention,” inCVPR, 2024
2024
-
[49]
Deep Learning for 3D Point Clouds: A Survey,
Y . Guo, H. Wang, Q. Hu, H. Liu, L. Liu, and M. Bennamoun, “Deep Learning for 3D Point Clouds: A Survey,”IEEE TPAMI, 2020
2020
-
[50]
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks,
B. Graham, M. Engelcke, and L. Van Der Maaten, “3D Semantic Segmentation with Submanifold Sparse Convolutional Networks,” inCVPR, 2018
2018
-
[52]
Spconv: Spatially Sparse Convolution Library,
SpconvContributors, “Spconv: Spatially Sparse Convolution Library,” https://github.com/traveller59/ spconv, 2022
2022
-
[53]
U-Net: Convolutional Networks for Biomedical Image Seg- mentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Networks for Biomedical Image Seg- mentation,” inMICCAI, 2015
2015
-
[54]
OctFormer: Octree-based Transformers for 3D Point Clouds,
P.-S. Wang, “OctFormer: Octree-based Transformers for 3D Point Clouds,”ACM Transactions on Graph- ics (SIGGRAPH), vol. 42, no. 4, 2023
2023
-
[55]
PCT: Point Cloud Transformer,
M.-H. Guo, J.-X. Cai, Z.-N. Liu, T.-J. Mu, R. R. Martin, and S.-M. Hu, “PCT: Point Cloud Transformer,” Computational Visual Media, 2021
2021
-
[56]
Masked Autoencoders for Point Cloud Self-supervised Learning,
Y . Pang, W. Wang, F. E. Tay, W. Liu, Y . Tian, and L. Yuan, “Masked Autoencoders for Point Cloud Self-supervised Learning,” inECCV, 2022
2022
-
[57]
Point-BERT: Pre-Training 3D Point Cloud Trans- formers With Masked Point Modeling,
X. Yu, L. Tang, Y . Rao, T. Huang, J. Zhou, and J. Lu, “Point-BERT: Pre-Training 3D Point Cloud Trans- formers With Masked Point Modeling,” inCVPR, 2022
2022
-
[58]
Point2Vec for Self-Supervised Representation Learn- ing on Point Clouds,
K. Knaebel, J. Schult, A. Hermans, and B. Leibe, “Point2Vec for Self-Supervised Representation Learn- ing on Point Clouds,” inGCPR, 2023
2023
-
[59]
3D ShapeNets: A Deep Representation for V olumetric Shapes,
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao, “3D ShapeNets: A Deep Representation for V olumetric Shapes,” inCVPR, 2015
2015
-
[60]
ShapeNet: An Information-Rich 3D Model Repository
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Suet al., “ShapeNet: An Information-Rich 3D Model Repository,”arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review arXiv 2015
-
[61]
PyTorch Image Models,
R. Wightman, “PyTorch Image Models,” https://github.com/rwightman/pytorch-image-models, 2019
2019
-
[62]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer Normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[63]
EV A-02: A Visual Representation for Neon Genesis,
Y . Fang, Q. Sun, X. Wang, T. Huang, X. Wang, and Y . Cao, “EV A-02: A Visual Representation for Neon Genesis,”Image and Vision Computing, vol. 149, p. 105171, 2024
2024
-
[64]
Rotary Position Embedding for Vision Transformer,
B. Heo, S. Park, D. Han, and S. Yun, “Rotary Position Embedding for Vision Transformer,” inECCV, 2024
2024
-
[65]
Superpoint Transformer for 3D Scene Instance Segmentation,
J. Sun, C. Qing, J. Tan, and X. Xu, “Superpoint Transformer for 3D Scene Instance Segmentation,” in AAAI, 2023
2023
-
[66]
DINOv2: Learning Robust Visual Features without Supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidovet al., “DINOv2: Learning Robust Visual Features without Supervision,”TMLR, 2024
2024
-
[67]
Transferring Inductive Biases through Knowledge Distilla- tion,
S. Abnar, M. Dehghani, and W. Zuidema, “Transferring Inductive Biases through Knowledge Distilla- tion,”arXiv preprint arXiv:2006.00555, 2020
-
[68]
DearKD: Data-Efficient Early Knowledge Distillation for Vision Transformers,
X. Chen, Q. Cao, Y . Zhong, J. Zhang, S. Gao, and D. Tao, “DearKD: Data-Efficient Early Knowledge Distillation for Vision Transformers,” inCVPR, 2022
2022
-
[69]
Cumulative Spatial Knowledge Distillation for Vision Transformers,
B. Zhao, R. Song, and J. Liang, “Cumulative Spatial Knowledge Distillation for Vision Transformers,” in ICCV, 2023
2023
-
[70]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the Knowledge in a Neural Network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[71]
ARKit LabelMaker: A New Scale for Indoor 3D Scene Understanding,
G. Ji, S. Weder, F. Engelmann, M. Pollefeys, and H. Blum, “ARKit LabelMaker: A New Scale for Indoor 3D Scene Understanding,” inCVPR, 2025. 14
2025
-
[72]
Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training,
X. Wu, Z. Tian, X. Wen, B. Peng, X. Liu, K. Yu, and H. Zhao, “Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training,” inCVPR, 2024
2024
-
[73]
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation,
K. Knaebel, K. Yilmaz, D. de Geus, A. Hermans, D. Adrian, T. Linder, and B. Leibe, “DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation,” in3DV, 2026
2026
-
[74]
PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies,
G. Qian, Y . Li, H. Peng, J. Mai, H. Hammoud, M. Elhoseiny, and B. Ghanem, “PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies,” inNeurIPS, 2022
2022
-
[75]
OA-CNNs: Omni-Adaptive Sparse CNNs for 3D Semantic Segmentation,
B. Peng, X. Wu, L. Jiang, Y . Chen, H. Zhao, Z. Tian, and J. Jia, “OA-CNNs: Omni-Adaptive Sparse CNNs for 3D Semantic Segmentation,” inCVPR, 2024
2024
-
[76]
The Lov ´asz-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks,
M. Berman, A. R. Triki, and M. B. Blaschko, “The Lov ´asz-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks,” inCVPR, 2018
2018
-
[77]
Decoupled Weight Decay Regularization,
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regularization,” inICLR, 2019
2019
-
[78]
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates,
L. N. Smith and N. Topin, “Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates,” inArtificial Intelligence and Machine Learning for Multi-Domain Operations Applica- tions, 2019
2019
-
[79]
Language-Grounded Indoor 3D Semantic Segmentation in the Wild,
D. Rozenberszki, O. Litany, and A. Dai, “Language-Grounded Indoor 3D Semantic Segmentation in the Wild,” inECCV, 2022
2022
-
[80]
Scalability in Perception for Autonomous Driving: Waymo Open Dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, V . Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, Z. Chen, and D. Anguelov, “Scalability in Perception for Autonomous Driving: Waymo Open Dataset,” inCVPR, 2020
2020
-
[81]
SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences,
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences,” inICCV, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.