Recognition: unknown
From Top-1 to Top-K: A Reproducibility Study and Benchmarking of Counterfactual Explanations for Recommender Systems
Pith reviewed 2026-05-10 01:25 UTC · model grok-4.3
The pith
Reproducing eleven counterfactual explanation methods for recommender systems shows that their effectiveness-sparsity trade-offs depend strongly on the chosen method and evaluation format.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
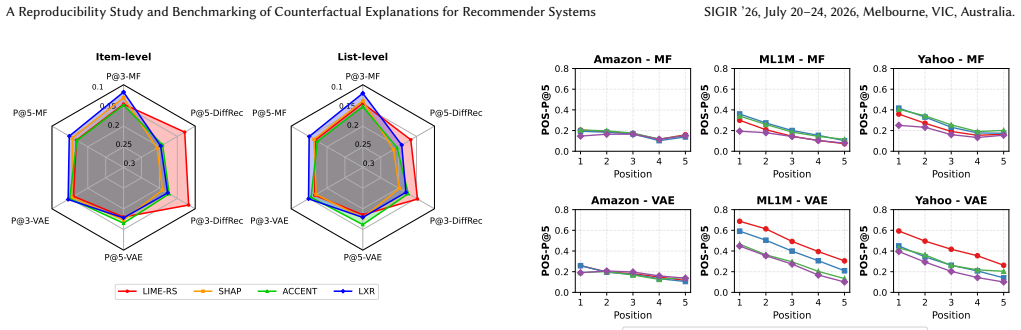
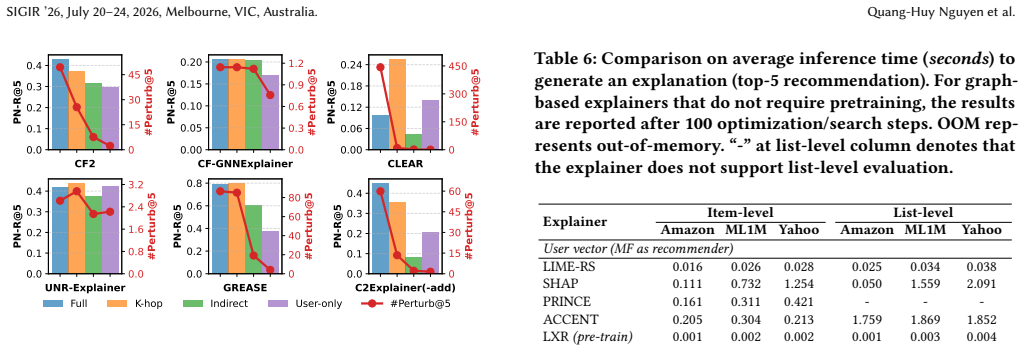
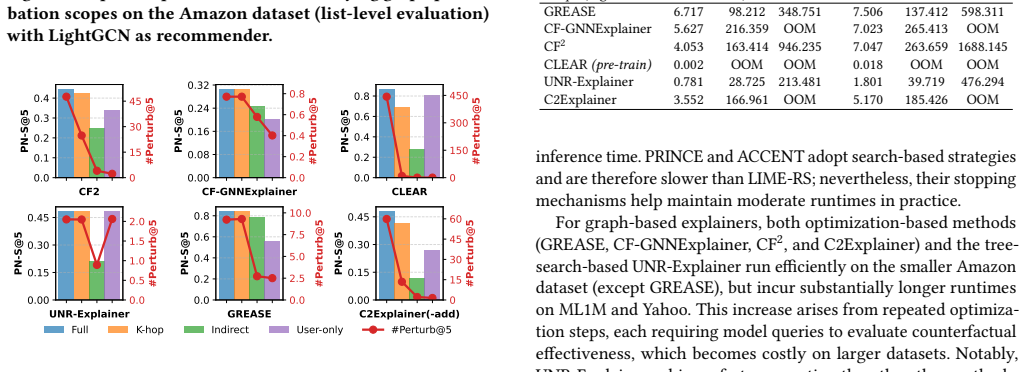
Under a unified protocol that measures effectiveness, sparsity, and runtime, the balance between producing useful changes and keeping those changes minimal varies by explainer and by whether the format is implicit or explicit. Performance rankings remain largely stable when evaluations move from single recommended items to full top-K lists. Several graph-based methods encounter clear scalability barriers on larger interaction graphs.
What carries the argument
The unified benchmarking framework that standardizes assessment across explanation format (implicit versus explicit), evaluation level (item versus list), and perturbation scope (user vectors versus full graphs).
If this is right
- Method selection for counterfactual explanations must account for the target format and graph size rather than relying on earlier single-setting results.
- Item-level and list-level evaluations produce similar performance orderings, so separate optimization for top-K lists may not be required.
- Graph-based explainers require additional engineering for large-scale recommender deployments.
- Earlier claims about the overall robustness of these methods need updating when tested under consistent but varied conditions.
Where Pith is reading between the lines
- Practitioners could use the benchmark to pick an explainer once they fix their dataset size and preferred output format.
- New counterfactual methods could be developed to target the explicit-format regime where the effectiveness-sparsity trade-off is most sensitive.
- The observed consistency between item and list levels suggests that list-level explanation quality might be predictable from cheaper item-level tests.
Load-bearing premise
That the re-implementations of the eleven methods match the originals closely enough and that the three datasets plus six recommenders produce results typical of recommender systems in general.
What would settle it
An independent re-implementation of one graph-based explainer that runs in linear time on the largest dataset while preserving the reported effectiveness-sparsity balance would contradict the scalability limitation.
Figures

read the original abstract
Counterfactual explanations (CEs) provide an intuitive way to understand recommender systems by identifying minimal modifications to user-item interactions that alter recommendation outcomes. Existing CE methods for recommender systems, however, have been evaluated under heterogeneous protocols, using different datasets, recommenders, metrics, and even explanation formats, which hampers reproducibility and fair comparison. Our paper systematically reproduces, re-implement, and re-evaluate eleven state-of-the-art CE methods for recommender systems, covering both native explainers (e.g., LIME-RS, SHAP, PRINCE, ACCENT, LXR, GREASE) and specific graph-based explainers originally proposed for GNNs. Here, a unified benchmarking framework is proposed to assess explainers along three dimensions: explanation format (implicit vs. explicit), evaluation level (item-level vs. list-level), and perturbation scope (user interaction vectors vs. user-item interaction graphs). Our evaluation protocol includes effectiveness, sparsity, and computational complexity metrics, and extends existing item-level assessments to top-K list-level explanations. Through extensive experiments on three real-world datasets and six representative recommender models, we analyze how well previously reported strengths of CE methods generalize across diverse setups. We observe that the trade-off between effectiveness and sparsity depends strongly on the specific method and evaluation setting, particularly under the explicit format; in addition, explainer performance remains largely consistent across item level and list level evaluations, and several graph-based explainers exhibit notable scalability limitations on large recommender graphs. Our results refine and challenge earlier conclusions about the robustness and practicality of CE generation methods in recommender systems: https://github.com/L2R-UET/CFExpRec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a reproducibility study and benchmarking of eleven counterfactual explanation (CE) methods for recommender systems (native explainers such as LIME-RS, SHAP, PRINCE, ACCENT, LXR, GREASE and graph-based ones for GNNs). It proposes a unified framework to evaluate them along three dimensions—explanation format (implicit vs. explicit), evaluation level (item-level vs. list-level), and perturbation scope (user interaction vectors vs. user-item graphs)—using effectiveness, sparsity, and computational complexity metrics. Experiments span three real-world datasets and six recommender models, extending prior item-level assessments to top-K list-level explanations. Key observations are that the effectiveness-sparsity trade-off depends strongly on the method and setting (especially explicit format), explainer performance is largely consistent across item and list levels, and several graph-based explainers show scalability limitations on large graphs. The results are positioned as refining and challenging earlier conclusions on the robustness and practicality of CE methods, with code released at https://github.com/L2R-UET/CFExpRec.
Significance. If the re-implementations prove faithful, the work is significant for the explainable recommender systems community because it directly tackles the heterogeneity of prior evaluation protocols that has hindered fair comparisons. The unified multi-dimensional framework, extension to list-level top-K explanations, and large-scale experiments across datasets and models provide a reusable benchmark that can clarify the practical trade-offs of CE generation. The public GitHub release of the framework and implementations is a clear strength that supports reproducibility and future extensions.
major comments (2)
- [Methods and Implementation] The manuscript asserts that the eleven CE methods have been systematically re-implemented and re-evaluated, yet no fidelity verification is provided (e.g., tables in the Methods or Experimental Setup sections that recover, within reasonable tolerance, the effectiveness, sparsity, or runtime figures originally reported by each method on its source dataset/recommender pair). This is load-bearing for the central claim that the observed differences 'refine and challenge earlier conclusions,' because discrepancies could stem from hyperparameter mismatches, preprocessing differences, or subtle algorithmic deviations rather than intrinsic method properties.
- [Experimental Setup] §4 (Experimental Protocol): the claim that the chosen three datasets, six recommenders, and three evaluation dimensions produce representative results is not accompanied by any sensitivity analysis or explicit justification of coverage; without this, it remains possible that the reported trade-off dependencies and scalability limitations are idiosyncratic to the selected setups rather than general.
minor comments (1)
- [Abstract] The abstract lists example method names but does not enumerate all eleven; adding the full list would improve immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our reproducibility study and benchmarking of counterfactual explanation methods for recommender systems. The comments identify important areas for strengthening the manuscript, particularly around implementation fidelity and experimental justification. We address each major comment below and will incorporate revisions to improve rigor and transparency.
read point-by-point responses
-
Referee: [Methods and Implementation] The manuscript asserts that the eleven CE methods have been systematically re-implemented and re-evaluated, yet no fidelity verification is provided (e.g., tables in the Methods or Experimental Setup sections that recover, within reasonable tolerance, the effectiveness, sparsity, or runtime figures originally reported by each method on its source dataset/recommender pair). This is load-bearing for the central claim that the observed differences 'refine and challenge earlier conclusions,' because discrepancies could stem from hyperparameter mismatches, preprocessing differences, or subtle algorithmic deviations rather than intrinsic method properties.
Authors: We appreciate the referee's emphasis on this point, as faithful re-implementation is essential for the validity of our benchmarking claims. Our implementations followed the original papers' algorithmic descriptions, pseudocode, and any released code as closely as possible, with hyperparameters set to match reported values where specified. To directly address the absence of fidelity verification, we will add a new subsection (or table) in the revised Experimental Setup section. This will report side-by-side comparisons of our reproduced effectiveness, sparsity, and runtime metrics against the originally published figures on the source datasets and recommender models, where such direct comparisons are feasible. Deviations will be discussed (e.g., due to random seeds or minor implementation choices), and we will explicitly note cases where original details were insufficient for exact replication. This addition will confirm that our unified framework, rather than re-implementation artifacts, drives the observed differences and trade-offs. revision: yes
-
Referee: [Experimental Setup] §4 (Experimental Protocol): the claim that the chosen three datasets, six recommenders, and three evaluation dimensions produce representative results is not accompanied by any sensitivity analysis or explicit justification of coverage; without this, it remains possible that the reported trade-off dependencies and scalability limitations are idiosyncratic to the selected setups rather than general.
Authors: We agree that providing explicit justification and sensitivity checks would better support the generalizability of our findings. The three datasets were selected for their varying scales, densities, and domains (e.g., rating vs. implicit feedback), and the six recommenders were chosen to span traditional (MF), neural, and graph-based paradigms commonly studied in the literature. The three evaluation dimensions directly address gaps identified in prior CE work. In the revision, we will expand §4 with a dedicated paragraph justifying these choices, supported by references to their frequent use in recommender systems and explainability papers. We will also add a sensitivity analysis (reported in the main text or appendix) by varying key aspects such as dataset subsample size or model hyperparameters on a subset of experiments, demonstrating that core observations—such as method-dependent effectiveness-sparsity trade-offs and graph explainer scalability limits—remain consistent. This will mitigate concerns about idiosyncrasy. revision: yes
Circularity Check
Empirical reproducibility study with no circular derivation chain
full rationale
This paper is a benchmarking and reproducibility exercise that re-implements 11 existing CE methods, defines a unified evaluation framework, and reports experimental results on three datasets and six recommenders. No central claim is obtained by fitting parameters to data and then treating the fitted values as predictions, by self-defining quantities in terms of each other, or by load-bearing self-citations whose validity is internal to the paper. The observed trade-offs, consistency across levels, and scalability findings are direct outputs of the experiments rather than tautological reductions of the inputs. The work is therefore self-contained against external benchmarks (original method papers) and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vineeta Anand and Ashish Kumar Maurya. 2025. A survey on recommender systems using graph neural network.ACM Transactions on Information Systems 43, 1 (2025), 1–49
2025
-
[2]
Oren Barkan, Veronika Bogina, Liya Gurevitch, Yuval Asher, and Noam Koenig- stein. 2024. A counterfactual framework for learning and evaluating explanations for recommender systems. InProceedings of the ACM Web Conference 2024. 3723– 3733
2024
-
[3]
Ziheng Chen, Jin Huang, Fabrizio Silvestri, Yongfeng Zhang, Hongshik Ahn, and Gabriele Tolomei. 2025. Joint Factual and Counterfactual Explanations for Top- k GNN-based Recommendations.ACM Transactions on Recommender Systems (2025)
2025
- [4]
-
[5]
Weiyu Cheng, Yanyan Shen, Linpeng Huang, and Yanmin Zhu. 2019. Incor- porating interpretability into latent factor models via fast influence analysis. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 885–893
2019
-
[6]
Ervin Dervishaj, Tuukka Ruotsalo, Maria Maistro, and Christina Lioma. 2025. Are Representation Disentanglement and Interpretability Linked in Recommendation Models? A Critical Review and Reproducibility Study. InEuropean Conference on Information Retrieval. Springer, 31–47
2025
-
[7]
Gideon Dror, Noam Koenigstein, Yehuda Koren, and Markus Weimer. 2011. The Yahoo! Music Dataset and KDD-Cup’11. InProceedings of the 2011 International Conference on KDD Cup 2011 - Volume 18 (KDDCUP’11). JMLR.org, 3–18
2011
-
[8]
Azin Ghazimatin, Oana Balalau, Rishiraj Saha Roy, and Gerhard Weikum. 2020. Prince: Provider-side interpretability with counterfactual explanations in rec- ommender systems. InProceedings of the 13th International Conference on Web Search and Data Mining. 196–204
2020
-
[9]
Riccardo Guidotti. 2024. Counterfactual explanations and how to find them: literature review and benchmarking.Data Mining and Knowledge Discovery38, 5 (2024), 2770–2824
2024
-
[10]
Liya Gurevitch, Veronika Bogina, Oren Barkan, Yahlly Schein, Yehonatan Elisha, and Noam Koenigstein. 2025. LXR: Learning to eXplain Recommendations.ACM Transactions on Recommender Systems4, 2 (2025), 1–39
2025
-
[11]
Maxwell Harper and Joseph A
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context.ACM Trans. Interact. Intell. Syst.5, 4, Article 19 (Dec. 2015), 19 pages
2015
-
[12]
Emrul Hasan, Mizanur Rahman, Chen Ding, Jimmy Huang, and Shaina Raza
-
[13]
Surveys(2024)
Based recommender systems: a survey of approaches, challenges and future perspectives.Comput. Surveys(2024)
2024
-
[14]
Taher H Haveliwala. 2002. Topic-sensitive pagerank. InProceedings of the 11th international conference on World Wide Web. 517–526
2002
-
[15]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
2020
-
[16]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[17]
Bridging Language and Items for Retrieval and Recommendation.arXiv preprint arXiv:2403.03952(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Niall Hurley and Scott Rickard. 2009. Comparing measures of sparsity.IEEE Transactions on Information Theory55, 10 (2009), 4723–4741
2009
-
[19]
Hyunju Kang, Geonhee Han, and Hogun Park. 2024. Unr-explainer: Counterfac- tual explanations for unsupervised node representation learning models. InThe Twelfth International Conference on Learning Representations
2024
-
[20]
Pang Wei Koh and Percy Liang. 2017. Understanding black-box predictions via influence functions. InInternational conference on machine learning. PMLR, 1885–1894
2017
-
[21]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems.Computer42, 8 (2009), 30–37
2009
-
[22]
Chaoliu Li, Lianghao Xia, Xubin Ren, Yaowen Ye, Yong Xu, and Chao Huang. 2023. Graph transformer for recommendation. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval. 1680– 1689
2023
-
[23]
Dawen Liang, Rahul G Krishnan, Matthew D Hoffman, and Tony Jebara. 2018. Variational autoencoders for collaborative filtering. InProceedings of the 2018 world wide web conference. 689–698
2018
-
[24]
Ana Lucic, Maartje A Ter Hoeve, Gabriele Tolomei, Maarten De Rijke, and Fabrizio Silvestri. 2022. Cf-gnnexplainer: Counterfactual explanations for graph neural networks. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 4499–4511
2022
-
[25]
Jing Ma, Ruocheng Guo, Saumitra Mishra, Aidong Zhang, and Jundong Li. 2022. Clear: Generative counterfactual explanations on graphs.Advances in neural information processing systems35 (2022), 25895–25907
2022
-
[26]
Jiali Ma, Ichigaku Takigawa, and Akihiro Yamamoto. 2025. C2Explainer: Cus- tomizable Mask-based Counterfactual Explanation for Graph Neural Networks. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Trans- parency. 137–149
2025
-
[27]
Amir Reza Mohammadi, Andreas Peintner, Michael Müller, and Eva Zangerle
-
[28]
InProceedings of the Nineteenth ACM Conference on Recommender Systems
Beyond Top-1: Addressing Inconsistencies in Evaluating Counterfactual Explanations for Recommender Systems. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 515–520
-
[29]
Huy-Son Nguyen, Tuan-Nghia Bui, Long-Hai Nguyen, Hung Hoang, Cam-Van Thi Nguyen, Hoang-Quynh Le, and Duc-Trong Le. 2024. Bundle recommenda- tion with item-level causation-enhanced multi-view learning. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 324–341
2024
-
[30]
Huy-Son Nguyen, Yuanna Liu, Masoud Mansoury, Mohammad Aliannejadi, Alan Hanjalic, and Maarten de Rijke. 2025. A Reproducibility Study of Product-side Fairness in Bundle Recommendation. InProceedings of the Nineteenth ACM Con- ference on Recommender Systems. 696–705
2025
-
[31]
Huy-Son Nguyen, Quang-Huy Nguyen, Duc-Hoang Pham, Duc-Trong Le, Hoang- Quynh Le, Padipat Sitkrongwong, Atsuhiro Takasu, and Masoud Mansoury. 2025. RaMen: Multi-Strategy Multi-Modal Learning for Bundle Construction. InECAI
2025
-
[32]
IOS Press, 1889–1896
-
[33]
Caio Nóbrega and Leandro Marinho. 2019. Towards explaining recommenda- tions through local surrogate models. InProceedings of the 34th ACM/SIGAPP symposium on applied computing. 1671–1678
2019
-
[34]
Georgina Peake and Jun Wang. 2018. Explanation mining: Post hoc interpretabil- ity of latent factor models for recommendation systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2060–2069
2018
-
[35]
Why should i trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " Why should i trust you?" Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1135–1144
2016
-
[36]
Yuta Saito and Thorsten Joachims. 2021. Counterfactual learning and evaluation for recommender systems: Foundations, implementations, and recent advances. InProceedings of the 15th ACM Conference on Recommender Systems. 828–830
2021
-
[37]
We Share Our Code Online
Faisal Shehzad, Timo Breuer, Maria Maistro, and Dietmar Jannach. 2025. “We Share Our Code Online”: Why This Is Not Enough to Ensure Reproducibility and Progress in Recommender Systems Research. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 884–893
2025
- [38]
-
[39]
Juntao Tan, Shijie Geng, Zuohui Fu, Yingqiang Ge, Shuyuan Xu, Yunqi Li, and Yongfeng Zhang. 2022. Learning and evaluating graph neural network explana- tions based on counterfactual and factual reasoning. InProceedings of the ACM web conference 2022. 1018–1027
2022
-
[40]
Khanh Hiep Tran, Azin Ghazimatin, and Rishiraj Saha Roy. 2021. Counterfactual explanations for neural recommenders. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1627–1631
2021
-
[41]
Wenjie Wang, Yiyan Xu, Fuli Feng, Xinyu Lin, Xiangnan He, and Tat-Seng Chua
-
[42]
InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval
Diffusion recommender model. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval. 832–841
- [43]
-
[44]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? simple graph contrastive learning for recommendation. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1294–1303
2022
-
[45]
Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep learning based recom- mender system: A survey and new perspectives.ACM computing surveys (CSUR) 52, 1 (2019), 1–38
2019
-
[46]
Yongfeng Zhang, Xu Chen, et al. 2020. Explainable recommendation: A survey and new perspectives.Foundations and Trends®in Information Retrieval14, 1 (2020), 1–101
2020
-
[47]
Jinfeng Zhong and Elsa Negre. 2022. Shap-enhanced counterfactual explanations for recommendations. InProceedings of the 37th ACM/SIGAPP Symposium on Applied Computing. 1365–1372
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.