Recognition: unknown
MedFlowSeg: Flow Matching for Medical Image Segmentation with Frequency-Aware Attention
Pith reviewed 2026-05-10 02:56 UTC · model grok-4.3
The pith
MedFlowSeg uses conditional flow matching with frequency-aware attention to segment medical images more efficiently than diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedFlowSeg formulates medical image segmentation as learning a time-dependent vector field that transports a simple prior distribution to the target segmentation distribution. It introduces a dual-conditioning mechanism consisting of a Dual-Branch Spatial Attention (DB-SA) module to inject multi-frequency structural priors and a Frequency-Aware Attention (FA-Attention) module that models interactions between spatial and spectral representations through discrepancy-aware fusion and time-dependent modulation. These components improve alignment between noisy intermediate states and clean semantic features, resulting in improved structural consistency and boundary delineation, and the overall框架e
What carries the argument
Conditional flow matching with Dual-Branch Spatial Attention (DB-SA) for multi-frequency priors and Frequency-Aware Attention (FA-Attention) for spatial-spectral discrepancy fusion and time modulation.
If this is right
- Inference reduces to solving one ODE rather than many stochastic diffusion steps.
- Structural consistency and boundary delineation improve through better intermediate-state alignment.
- Performance advantage holds across multiple imaging modalities including MRI and CT variants.
- Generative formulation retains capacity to capture uncertainty and anatomical variability.
Where Pith is reading between the lines
- The same conditioning strategy could be tested on 3D volumetric segmentation where frequency cues vary across slices.
- Clinical deployment might become feasible in settings that previously rejected diffusion models because of latency.
- The frequency-aware fusion could be adapted to other conditional image tasks such as synthesis or denoising.
- If the modules prove robust, they may lower the need for modality-specific hyperparameter searches.
Load-bearing premise
The Dual-Branch Spatial Attention and Frequency-Aware Attention modules will reliably improve alignment between noisy states and clean semantic features without introducing artifacts or requiring extensive per-dataset tuning.
What would settle it
Head-to-head evaluation on a standard medical segmentation benchmark where MedFlowSeg shows no gain in Dice or boundary metrics and no reduction in inference steps compared with a diffusion baseline would disprove the claimed advantage.
Figures



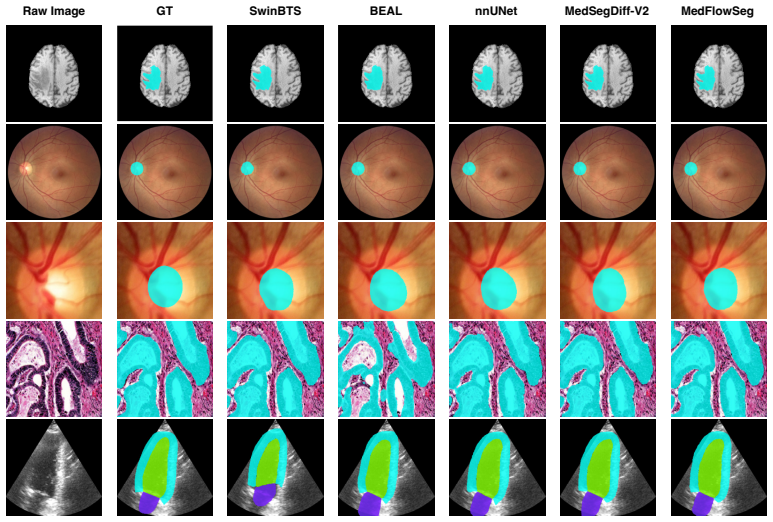
read the original abstract
Flow matching has recently emerged as a principled framework for learning continuous-time transport maps, enabling efficient ODE-based sampling without relying on stochastic diffusion processes. While generative modeling has shown promise for medical image segmentation, particularly in capturing uncertainty and complex anatomical variability, existing approaches are predominantly based on diffusion models, which require iterative sampling and incur substantial computational overhead. In this work, we propose MedFlowSeg, a conditional flow matching framework that formulates medical image segmentation as learning a time-dependent vector field that transports a simple prior distribution to the target segmentation distribution. Compared to diffusion-based methods, our formulation enables more efficient inference through solving an ordinary differential equation, while preserving the flexibility of generative modeling. To effectively incorporate conditional information, we introduce a dual-conditioning mechanism. Specifically, we propose a Dual-Branch Spatial Attention (DB-SA) module to inject multi-frequency structural priors, and a Frequency-Aware Attention (FA-Attention) module to model interactions between spatial and spectral representations via discrepancy-aware fusion and time-dependent modulation. These components improve the alignment between noisy intermediate states and clean semantic features, leading to better structural consistency and boundary delineation. We conduct extensive experiments across multiple medical imaging modalities, where MedFlowSeg consistently outperforms prior state-of-the-art (SOTA) baselines, including diffusion-based and flow-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce MedFlowSeg, a conditional flow matching framework for medical image segmentation that learns a time-dependent vector field to transport a prior distribution to the target segmentation distribution. It proposes a dual-conditioning mechanism consisting of the Dual-Branch Spatial Attention (DB-SA) module for multi-frequency structural priors and the Frequency-Aware Attention (FA-Attention) module for spatial-spectral fusion with discrepancy-aware and time-dependent modulation. The authors state that these components lead to better alignment between noisy intermediate states and clean semantic features, resulting in superior structural consistency and boundary delineation, and that extensive experiments demonstrate consistent outperformance over prior SOTA baselines including diffusion-based and flow-based methods across multiple medical imaging modalities.
Significance. If the results hold, this work has potential significance in providing an efficient alternative to diffusion models for generative medical image segmentation by leveraging flow matching's ODE-based sampling. The frequency-aware attention mechanisms could help in capturing complex anatomical structures more effectively. It contributes to the growing body of work on adapting generative models to conditional tasks in medical imaging, with possible implications for reducing computational costs in inference while maintaining or improving accuracy.
major comments (2)
- [Abstract] The abstract claims that 'MedFlowSeg consistently outperforms prior state-of-the-art (SOTA) baselines' but does not include any quantitative metrics, error bars, dataset specifications, or ablation results. This is a load-bearing issue for the central claim as it prevents verification that the proposed DB-SA and FA-Attention modules are responsible for the improvements rather than differences in training protocols or other unmentioned factors.
- [Method] The description of the dual-conditioning mechanism (DB-SA and FA-Attention) asserts that they 'improve the alignment between noisy intermediate states and clean semantic features' without any supporting analysis, such as feature visualizations, frequency domain comparisons, or sensitivity to hyperparameters. If these modules introduce new artifacts or their benefits are not robust, the outperformance claim would not hold.
minor comments (1)
- The abstract could benefit from a brief mention of the specific medical imaging modalities used in the experiments to provide context for the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the verifiability of our claims. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract claims that 'MedFlowSeg consistently outperforms prior state-of-the-art (SOTA) baselines' but does not include any quantitative metrics, error bars, dataset specifications, or ablation results. This is a load-bearing issue for the central claim as it prevents verification that the proposed DB-SA and FA-Attention modules are responsible for the improvements rather than differences in training protocols or other unmentioned factors.
Authors: We agree that the abstract would benefit from quantitative context to support the outperformance claim. In the revised version, we will add key metrics such as mean Dice scores (with standard deviations) and Hausdorff distances on the primary datasets (e.g., ACDC, Synapse, and ISIC), along with the number of modalities and a brief note on ablation trends. This will help readers immediately assess the improvements while keeping the abstract concise; full tables, error bars across all runs, and detailed ablations will remain in the experimental section. revision: yes
-
Referee: [Method] The description of the dual-conditioning mechanism (DB-SA and FA-Attention) asserts that they 'improve the alignment between noisy intermediate states and clean semantic features' without any supporting analysis, such as feature visualizations, frequency domain comparisons, or sensitivity to hyperparameters. If these modules introduce new artifacts or their benefits are not robust, the outperformance claim would not hold.
Authors: The current manuscript supports the dual-conditioning claims through quantitative ablations in Section 4.2 showing consistent gains when DB-SA and FA-Attention are added. To directly substantiate the alignment and robustness assertions, we will add in the revision: (i) feature visualization comparisons (e.g., cosine similarity or t-SNE of intermediate states vs. clean features at sampled timesteps), (ii) frequency-domain spectrum plots before/after FA-Attention, and (iii) hyperparameter sensitivity analysis for the discrepancy-aware fusion and time-dependent modulation. These additions will be placed in a new subsection of Section 4 to confirm no artifacts are introduced and benefits are stable. revision: yes
Circularity Check
No circularity: independent architectural proposal with empirical validation
full rationale
The paper formulates medical segmentation as conditional flow matching to learn a time-dependent vector field transporting prior to target distribution, then introduces DB-SA for multi-frequency priors and FA-Attention for spatial-spectral fusion as new modules. These are presented as design choices that improve alignment, with outperformance asserted via experiments on multiple modalities versus diffusion and flow baselines. No equations reduce a claimed result to its own inputs by construction, no fitted parameters are renamed as predictions, and no load-bearing self-citations or uniqueness theorems from prior author work are invoked in the provided text. The central claims rest on the proposed components and external benchmarks rather than self-referential definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and attention parameters
axioms (1)
- domain assumption A time-dependent vector field learned via flow matching can transport a simple prior distribution to the target segmentation distribution when conditioned on input images.
invented entities (2)
-
Dual-Branch Spatial Attention (DB-SA) module
no independent evidence
-
Frequency-Aware Attention (FA-Attention) module
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
U. Baid, S. Ghodasara, S. Mohan, M. Bilello, E. Calabrese, E. Colak, K. Farahani, J. Kalpathy- Cramer, F. C. Kitamura, S. Pati, et al. The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification.arXiv preprint arXiv:2107.02314, 2021
work page internal anchor Pith review arXiv 2021
-
[3]
Bernard, A
O. Bernard, A. Lalande, C. Zotti, F. Cervenansky, X. Yang, P.-A. Heng, I. Cetin, K. Lekadir, O. Camara, M. A. G. Ballester, et al. Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved?IEEE transactions on medical imaging, 37(11):2514–2525, 2018
2018
-
[4]
Bogensperger, D
L. Bogensperger, D. Narnhofer, A. Falk, K. Schindler, and T. Pock. Flowsdf: Flow matching for medical image segmentation using distance transforms.International Journal of Computer Vision, 2025
2025
- [5]
-
[6]
H. Chen, X. Qi, L. Yu, and P.-A. Heng. Dcan: deep contour-aware networks for accurate gland segmentation. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2487–2496, 2016
2016
-
[7]
J. Chen, Y . Lu, Q. Yu, X. Luo, E. Adeli, Y . Wang, L. Lu, A. L. Yuille, and Y . Zhou. Tran- sunet: Transformers make strong encoders for medical image segmentation.arXiv preprint arXiv:2102.04306, 2021
work page internal anchor Pith review arXiv 2021
-
[8]
Dhivya, M
P. Dhivya, M. Shobana, N. Kumar, et al. Echo-segnet framework for accurate 2d echocardio- graphic image segmentation using the camus dataset. In2025 International Conference on Next Generation Computing Systems (ICNGCS), pages 1–8. IEEE, 2025
2025
-
[9]
F. I. Diakogiannis, F. Waldner, P. Caccetta, and C. Wu. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data.ISPRS Journal of Photogrammetry and Remote Sensing, 162:94–114, 2020
2020
- [10]
-
[11]
arXiv preprint arXiv:2201.01266 , year=
A. Hatamizadeh, V . Nath, Y . Tang, D. Yang, H. Roth, and D. Xu. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images.arXiv preprint arXiv:2201.01266, 2022
-
[12]
Hatamizadeh, Y
A. Hatamizadeh, Y . Tang, V . Nath, D. Yang, A. Myronenko, B. Landman, H. R. Roth, and D. Xu. Unetr: Transformers for 3d medical image segmentation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 574–584, 2022. 10
2022
-
[13]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[14]
Isensee, P
F. Isensee, P. F. Jaeger, S. A. A. Kohl, J. Petersen, and K. H. Maier-Hein. nnu-net: a self- configuring method for deep learning-based biomedical image segmentation.Nature Methods, 18(2):203–211, 2021
2021
-
[15]
W. Ji, S. Yu, J. Wu, K. Ma, C. Bian, Q. Bi, J. Li, H. Liu, L. Cheng, and Y . Zheng. Learning calibrated medical image segmentation via multi-rater agreement modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12341–12351, 2021
2021
-
[16]
Jiang, Y
Y . Jiang, Y . Zhang, X. Lin, J. Dong, T. Cheng, and J. Liang. Swinbts: A method for 3d multimodal brain tumor segmentation using swin transformer.Brain sciences, 12(6):797, 2022
2022
-
[17]
Leclerc, E
S. Leclerc, E. Smistad, J. Pedrosa, A. Østvik, F. Cervenansky, F. Espinosa, T. Espeland, E. A. R. Berg, P.-M. Jodoin, T. Grenier, et al. Deep learning for segmentation using an open large-scale dataset in 2d echocardiography.IEEE transactions on medical imaging, 38(9):2198–2210, 2019
2019
-
[18]
A. Lin, B. Chen, J. Xu, Z. Zhang, G. Lu, and D. Zhang. Ds-transunet: Dual swin transformer u-net for medical image segmentation.IEEE Transactions on Instrumentation and Measurement, 71:1–15, 2022
2022
-
[19]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review arXiv 2022
-
[21]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [22]
-
[23]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015, pages 234–241. Springer, 2015
2015
-
[24]
Sirinukunwattana, J
K. Sirinukunwattana, J. P. Pluim, H. Chen, X. Qi, P.-A. Heng, Y . B. Guo, L. Y . Wang, B. J. Matuszewski, E. Bruni, U. Sanchez, et al. Gland segmentation in colon histology images: The glas challenge contest.Medical image analysis, 35:489–502, 2017
2017
-
[25]
H. Wang, M. Xian, and A. Vakanski. Ta-net: Topology-aware network for gland segmentation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1556–1564, 2022
2022
-
[26]
H. Wang, S. Xie, L. Lin, Y . Iwamoto, X.-H. Han, Y .-W. Chen, and R. Tong. Mixed transformer u-net for medical image segmentation. InICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 2390–2394. IEEE, 2022
2022
-
[27]
S. Wang, L. Yu, K. Li, X. Yang, C.-W. Fu, and P.-A. Heng. Boundary and entropy-driven adversarial learning for fundus image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 102–110. Springer, 2019
2019
-
[28]
W. Wang, C. Chen, M. Ding, H. Yu, S. Zha, and J. Li. Transbts: Multimodal brain tumor segmentation using transformer. InInternational conference on medical image computing and computer-assisted intervention, pages 109–119. Springer, 2021
2021
-
[29]
S. K. Warfield, K. H. Zou, and W. M. Wells. Simultaneous truth and performance level estimation (staple): an algorithm for the validation of image segmentation.IEEE transactions on medical imaging, 23(7):903–921, 2004. 11
2004
-
[30]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
J. Wolleb, R. Sandkühler, F. Bieder, P. Valmaggia, and P. C. Cattin. Diffusion models for implicit image segmentation ensembles.arXiv preprint arXiv:2112.03145, 2021. doi: 10.48550/arXiv. 2112.03145
work page internal anchor Pith review doi:10.48550/arxiv 2021
-
[31]
Wolleb, R
J. Wolleb, R. Sandkühler, F. Bieder, P. Valmaggia, and P. C. Cattin. Diffusion models for implicit image segmentation ensembles. InInternational conference on medical imaging with deep learning, pages 1336–1348. PMLR, 2022
2022
-
[32]
J. Wu, H. Fang, F. Shang, D. Yang, Z. Wang, J. Gao, Y . Yang, and Y . Xu. Seatrans: learning segmentation-assisted diagnosis model via transformer. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 677–687. Springer, 2022
2022
-
[33]
J. Wu, R. Fu, H. Fang, Y . Zhang, Y . Yang, H. Xiong, H. Liu, and Y . Xu. Medsegdiff: Medical image segmentation with diffusion probabilistic model. InMedical Imaging with Deep Learning, volume 227 ofProceedings of Machine Learning Research, pages 1623–1639, 2024
2024
-
[34]
J. Wu, W. Ji, H. Fu, M. Xu, Y . Jin, and Y . Xu. Medsegdiff-v2: Diffusion-based medical image segmentation with transformer. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 6030–6038, 2024
2024
-
[35]
Z. Zhou, M. M. Rahman Siddiquee, N. Tajbakhsh, and J. Liang. Unet++: A nested u-net architecture for medical image segmentation. InInternational workshop on deep learning in medical image analysis, pages 3–11. Springer, 2018. 12
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.