Recognition: unknown
SpanVLA: Efficient Action Bridging and Learning from Negative-Recovery Samples for Vision-Language-Action Model
Pith reviewed 2026-05-10 02:31 UTC · model grok-4.3
The pith
SpanVLA bridges vision-language reasoning to a flow-matching policy conditioned on historical trajectories to generate driving actions faster while learning recoveries from negative examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpanVLA integrates an autoregressive VLM for reasoning with a flow-matching policy for action generation. The efficient bridge conditions the flow-matching policy on historical trajectory initialization to leverage VLM vision and reasoning guidance, which reduces inference time. GRPO post-training on the mReasoning dataset enables learning from both positive samples and negative-recovery behaviors, improving robustness in reasoning-demanding scenarios. This yields competitive performance on NAVSIM v1 and v2.
What carries the argument
The efficient bridge that conditions a flow-matching policy on historical trajectory initialization and VLM guidance to plan future trajectories.
Load-bearing premise
Conditioning the flow-matching policy on historical trajectory initialization plus VLM guidance will produce safe trajectories across real-world driving distributions without extra constraints.
What would settle it
A recorded driving sequence in which the generated trajectory collides or fails to recover in a scenario covered by the negative-recovery training data.
Figures



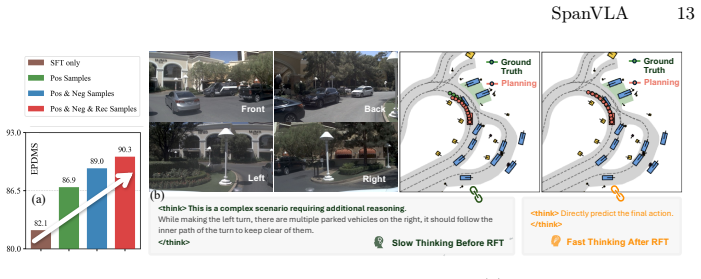

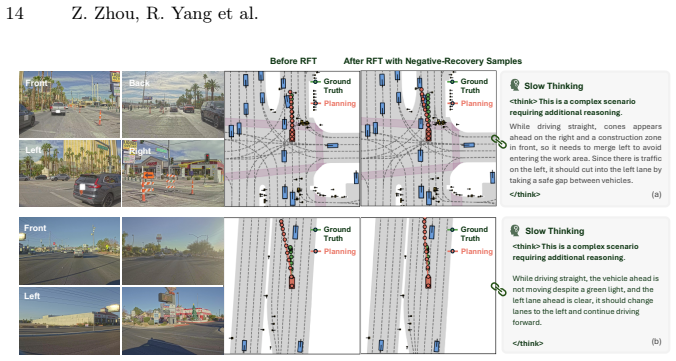

read the original abstract
Vision-Language-Action (VLA) models offer a promising autonomous driving paradigm for leveraging world knowledge and reasoning capabilities, especially in long-tail scenarios. However, existing VLA models often struggle with the high latency in action generation using an autoregressive generation framework and exhibit limited robustness. In this paper, we propose SpanVLA, a novel end-to-end autonomous driving framework, integrating an autoregressive reasoning and a flow-matching action expert. First, SpanVLA introduces an efficient bridge to leverage the vision and reasoning guidance of VLM to efficiently plan future trajectories using a flow-matching policy conditioned on historical trajectory initialization, which significantly reduces inference time. Second, to further improve the performance and robustness of the SpanVLA model, we propose a GRPO-based post-training method to enable the VLA model not only to learn from positive driving samples but also to learn how to avoid the typical negative behaviors and learn recovery behaviors. We further introduce mReasoning, a new real-world driving reasoning dataset, focusing on complex, reasoning-demanding scenarios and negative-recovery samples. Extensive experiments on the NAVSIM (v1 and v2) demonstrate the competitive performance of the SpanVLA model. Additionally, the qualitative results across diverse scenarios highlight the planning performance and robustness of our model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SpanVLA, an end-to-end Vision-Language-Action framework for autonomous driving that combines autoregressive VLM reasoning with a flow-matching action expert. It introduces an efficient bridge to condition a flow-matching policy on VLM guidance and historical trajectory initialization for reduced inference latency, a GRPO-based post-training procedure to learn from negative-recovery samples in addition to positive ones, and the mReasoning dataset focused on complex reasoning and recovery scenarios. Experiments are reported to show competitive performance on NAVSIM v1 and v2 with qualitative robustness gains.
Significance. If the quantitative claims hold with proper validation, the work could advance efficient VLA models for driving by demonstrating a practical bridge between VLMs and flow-matching policies plus negative-sample post-training, potentially aiding long-tail scenario handling. The mReasoning dataset may provide a useful resource for reasoning-focused driving research.
major comments (2)
- Abstract: The claim of 'competitive performance' on NAVSIM v1/v2 and 'improved robustness' is asserted without any quantitative metrics, baselines, error bars, ablation results, or statistical details, preventing assessment of whether the efficient bridge or GRPO components deliver measurable gains over prior VLA methods.
- The central construction (efficient bridge + flow-matching policy conditioned on historical trajectories and VLM output): No analysis is provided of out-of-distribution failure modes, mode collapse risks, or uncertainty quantification for the learned conditional distribution, which is load-bearing for the robustness and safety claims across real-world driving distributions.
minor comments (2)
- Abstract: The description of the 'efficient bridge' and 'GRPO-based post-training' would benefit from a high-level diagram or pseudocode to clarify the integration of autoregressive reasoning with the flow-matching expert.
- The introduction of mReasoning is noted as a contribution, but the abstract does not specify its size, collection protocol, or how negative-recovery samples are annotated, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve the presentation of results and analysis.
read point-by-point responses
-
Referee: Abstract: The claim of 'competitive performance' on NAVSIM v1/v2 and 'improved robustness' is asserted without any quantitative metrics, baselines, error bars, ablation results, or statistical details, preventing assessment of whether the efficient bridge or GRPO components deliver measurable gains over prior VLA methods.
Authors: We agree that the abstract is high-level and does not include specific metrics. The full manuscript reports quantitative results on NAVSIM v1 and v2 with baseline comparisons, ablations for the bridge and GRPO components, and qualitative robustness examples in Section 4. We will revise the abstract to include key performance numbers and references to the supporting experiments and ablations. revision: yes
-
Referee: The central construction (efficient bridge + flow-matching policy conditioned on historical trajectories and VLM output): No analysis is provided of out-of-distribution failure modes, mode collapse risks, or uncertainty quantification for the learned conditional distribution, which is load-bearing for the robustness and safety claims across real-world driving distributions.
Authors: The manuscript supports robustness claims primarily through the GRPO post-training on negative-recovery samples and the mReasoning dataset, with qualitative results across diverse scenarios. No dedicated quantitative analysis of OOD failure modes, mode collapse, or uncertainty quantification is currently included. We will add a new discussion subsection addressing these aspects, including limitations and future work, to better substantiate the safety-related claims. revision: yes
Circularity Check
No circularity: SpanVLA framework and training are additive proposals validated on external benchmarks.
full rationale
The paper introduces SpanVLA as a composite architecture (autoregressive VLM reasoning bridged to a flow-matching policy conditioned on historical trajectories, plus GRPO post-training on negative-recovery samples and a new mReasoning dataset). No equations, derivations, or self-referential definitions appear in the provided abstract or description that reduce claimed performance gains to quantities fitted from the same data by construction. Results are reported as empirical outcomes on NAVSIM v1/v2 rather than as logical consequences of prior fitted parameters or self-citations. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
MDrive: Benchmarking Closed-Loop Cooperative Driving for End-to-End Multi-agent Systems
MDrive benchmark shows multi-agent cooperative driving systems generally outperform single-agent ones in closed-loop settings but perception sharing does not always improve planning and negotiation can harm performanc...
-
DriveFuture: Future-Aware Latent World Models for Autonomous Driving
DriveFuture achieves SOTA results on NAVSIM by conditioning latent world model states on future predictions to directly inform trajectory planning.
Reference graph
Works this paper leans on
-
[1]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vi- sion (WACV)
Arai, H., Miwa, K., Sasaki, K., Watanabe, K., Yamaguchi, Y., Aoki, S., Ya- mamoto, I.: Covla: Comprehensive vision-language-action dataset for autonomous driving. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vi- sion (WACV). pp. 1933–1943. IEEE (2025)
2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Cai, T., Liu, Y., Zhou, Z., Ma, H., Zhao, S.Z., Wu, Z., Ma, J.: Driving with regulation: Interpretable decision-making for autonomous vehicles with retrieval- augmented reasoning via llm. arXiv preprint arXiv:2410.04759 (2024)
- [4]
-
[5]
IEEE Transactions on Pattern Analysis and Ma- chine Intelligence (2024)
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence (2024)
2024
-
[6]
IEEE trans- actions on pattern analysis and machine intelligence45(11), 12878–12895 (2022)
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: Transfuser: Imi- tation with transformer-based sensor fusion for autonomous driving. IEEE trans- actions on pattern analysis and machine intelligence45(11), 12878–12895 (2022)
2022
-
[7]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Contributors, O.: Openscene: The largest up-to-date 3d occupancy predic- tion benchmark in autonomous driving.https://github.com/OpenDriveLab/ OpenScene(2023)
2023
-
[9]
DriveFine : Refining-augmented masked diffusion VLA for precise and robust driving
Dang, C., Ang, S., Li, Y., Tian, H., Wang, J., Li, G., Ye, H., Ma, J., Chen, L., Wang, Y.: Drivefine: Refining-augmented masked diffusion vla for precise and ro- bust driving. arXiv preprint arXiv:2602.14577 (2026)
-
[10]
Advances in Neural Information Processing Systems37, 28706–28719 (2024)
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschenski, I., Ivanovic, B., Pavone, M., et al.: Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. Advances in Neural Information Processing Systems37, 28706–28719 (2024)
2024
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ettinger, S., Cheng, S., Caine, B., Liu, C., Zhao, H., Pradhan, S., Chai, Y., Sapp, B., Qi, C.R., Zhou, Y., et al.: Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9710–9719 (2021)
2021
-
[12]
arXiv preprint arXiv:2509.15968 (2025)
Fang, S., Cui, Y., Liang, H., Lv, C., Hang, P., Sun, J.: Corevla: A dual-stage end- to-end autonomous driving framework for long-tail scenarios via collect-and-refine. arXiv preprint arXiv:2509.15968 (2025)
-
[13]
Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
Feng, L., Gao, Y., Zablocki, E., Li, Q., Li, W., Liu, S., Cord, M., Alahi, A.: Rap: 3d rasterization augmented end-to-end planning. arXiv preprint arXiv:2510.04333 (2025)
-
[14]
IEEE Robotics and Automation Letters11(1), 226–233 (2025) 16 Z
Feng, R., Xi, N., Chu, D., Wang, R., Deng, Z., Wang, A., Lu, L., Wang, J., Huang, Y.: Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving. IEEE Robotics and Automation Letters11(1), 226–233 (2025) 16 Z. Zhou, R. Yang et al
2025
-
[15]
Fu, H., Zhang, D., Zhao, Z., Cui, J., Liang, D., Zhang, C., Zhang, D., Xie, H., Wang, B., Bai, X.: Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. arXiv preprint arXiv:2503.19755 (2025)
-
[16]
Minddrive: A vision-language-action model for autonomous driving via online reinforcement learning,
Fu, H., Zhang, D., Zhao, Z., Cui, J., Xie, H., Wang, B., Chen, G., Liang, D., Bai, X.: Minddrive: A vision-language-action model for autonomous driving via online reinforcement learning. arXiv Preprint arXiv:2512.13636 (2025)
-
[17]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Gao, H., Chen, S., Jiang, B., Liao, B., Shi, Y., Guo, X., Pu, Y., haoran yin, Li, X., xinbang zhang, ying zhang, Liu, W., Zhang, Q., Wang, X.: RAD: Training an end-to-end driving policy via large-scale 3DGS-based reinforcement learning. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[18]
Gemini Team, Google DeepMind: Gemini 3: A new era of intelligence with gemini
-
[19]
Technical Report (2025),https://deepmind.google/models/gemini/
2025
-
[20]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[22]
Hu, T., Liu, X., Wang, S., Zhu, Y., Liang, A., Kong, L., Zhao, G., Gong, Z., Cen, J., Huang, Z., et al.: Vision-language-action models for autonomous driving: Past, present, and future. arXiv preprint arXiv:2512.16760 (2025)
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17853– 17862 (2023)
2023
-
[24]
Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
Hwang, J.J., Xu, R., Lin, H., Hung, W.C., Ji, J., Choi, K., Huang, D., He, T., Cov- ington, P., Sapp, B., et al.: Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262 (2024)
-
[25]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Intelligence, P., Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dhabalia, K., DiCarlo, J., et al.: pi0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759 (2025)
work page Pith review arXiv 2025
-
[26]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al.: Openai o1 system card. arXiv preprint arXiv:2412.16720 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jia, X., Wu, P., Chen, L., Xie, J., He, C., Yan, J., Li, H.: Think twice before driving: Towards scalable decoders for end-to-end autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21983–21994 (2023)
2023
- [28]
-
[29]
IRL-VLA: Training an vision-language-action policy via reward world model,
Jiang, A., Gao, Y., Wang, Y., Sun, Z., Wang, S., Heng, Y., Sun, H., Tang, S., Zhu, L., Chai, J., et al.: Irl-vla: Training an vision-language-action policy via reward world model. arXiv preprint arXiv:2508.06571 (2025)
-
[30]
Jiang, B., Chen, S., Liao, B., Zhang, X., Yin, W., Zhang, Q., Huang, C., Liu, W., Wang, X.: Senna: Bridging large vision-language models and end-to-end au- tonomous driving. arXiv preprint arXiv:2410.22313 (2024)
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang,C.,Wang,X.:Vad:Vectorizedscenerepresentationforefficientautonomous SpanVLA 17 driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8340–8350 (2023)
2023
-
[32]
Jiang, B., Chen, S., Zhang, Q., Liu, W., Wang, X.: Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reasoning. arXiv preprint arXiv:2503.07608 (2025)
-
[33]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Karnchanachari, N., Geromichalos, D., Tan, K.S., Li, N., Eriksen, C., Yaghoubi, S., Mehdipour, N., Bernasconi, G., Fong, W.K., Guo, Y., et al.: Towards learning- based planning: The nuplan benchmark for real-world autonomous driving. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 629–636. IEEE (2024)
2024
-
[34]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success, 2025. URL https://arxiv. org/abs/2502.19645 (2016)
work page internal anchor Pith review arXiv 2025
-
[35]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review arXiv 2024
-
[36]
Driving on registers.arXiv preprint arXiv:2601.05083, 2026
Kirby, E., Boulch, A., Xu, Y., Yin, Y., Puy, G., Zablocki, É., Bursuc, A., Gi- daris, S., Marlet, R., Bartoccioni, F., et al.: Driving on registers. arXiv preprint arXiv:2601.05083 (2026)
-
[37]
IEEE Robotics and Automation Letters11(1), 818–825 (2025)
Lei, M., Zhou, Z., Li, H., Ma, J., Hu, J.: Risk map as middleware: Toward inter- pretable cooperative end-to-end autonomous driving for risk-aware planning. IEEE Robotics and Automation Letters11(1), 818–825 (2025)
2025
-
[38]
Li, D., Ren, J., Wang, Y., Wen, X., Li, P., Xu, L., Zhan, K., Xia, Z., Jia, P., Lang, X., et al.: Finetuning generative trajectory model with reinforcement learning from human feedback. arXiv preprint arXiv:2503.10434 (2025)
-
[39]
Li, Y., Shang, S., Liu, W., Zhan, B., Wang, H., Wang, Y., Chen, Y., Wang, X., An, Y., Tang, C., et al.: Drivevla-w0: World models amplify data scaling law in autonomous driving. arXiv preprint arXiv:2510.12796 (2025)
-
[40]
Li, Y., Wang, Y., Liu, Y., He, J., Fan, L., Zhang, Z.: End-to-end driving with onlinetrajectoryevaluationviabevworldmodel.In:ProceedingsoftheIEEE/CVF International Conference on Computer Vision. pp. 27137–27146 (2025)
2025
-
[41]
Li, Y., Xiong, K., Guo, X., Li, F., Yan, S., Xu, G., Zhou, L., Chen, L., Sun, H., Wang, B., et al.: Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. arXiv preprint arXiv:2506.08052 (2025)
-
[42]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Li, Z., Li, K., Wang, S., Lan, S., Yu, Z., Ji, Y., Li, Z., Zhu, Z., Kautz, J., Wu, Z., et al.: Hydra-mdp: End-to-end multimodal planning with multi-target hydra- distillation. arXiv preprint arXiv:2406.06978 (2024)
work page internal anchor Pith review arXiv 2024
-
[43]
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., et al.: Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. arXiv preprint arXiv:2411.15139 (2024)
-
[44]
Liao, H., Kong, H., Wang, B., Wang, C., Ye, W., He, Z., Xu, C., Li, Z.: Cot-drive: Efficient motion forecasting for autonomous driving with llms and chain-of-thought prompting. arXiv preprint arXiv:2503.07234 (2025)
-
[45]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
IEEE Robotics and Automation Letters11(2), 1738–1745 (2025)
Liu, D., Gao, Y., Qian, D., Zhang, Q., Ye, X., Han, J., Zheng, Y., Liu, X., Xia, Z., Ding, D., et al.: Takead: Preference-based post-optimization for end-to-end autonomous driving with expert takeover data. IEEE Robotics and Automation Letters11(2), 1738–1745 (2025)
2025
-
[47]
Liu, L., Song, Z., Jia, C., Ye, H., Hao, X., Chen, L., et al.: Driveworld-vla: Unified latent-space world modeling with vision-language-action for autonomous driving. arXiv preprint arXiv:2602.06521 (2026) 18 Z. Zhou, R. Yang et al
-
[48]
CogDriver: Integrating Cognitive Inertia for Temporally Coherent Planning in Autonomous Driving
Liu, P., Ning, Q., Lu, X., Liu, H., Ma, W., She, D., Jia, P., Lang, X., Ma, J.: Omnireason: A temporal-guided vision-language-action framework for autonomous driving. arXiv preprint arXiv:2509.00789 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
arXiv preprint arXiv:2510.00154 (2025)
Liu, X., Sani, M.F., Zhou, Z., Wirbel, J., Zarrin, B., Galeazzi, R.: Robopilot: Gen- eralizable dynamic robotic manipulation with dual-thinking modes. arXiv preprint arXiv:2510.00154 (2025)
-
[50]
Ma, Y., Cao, Y., Ding, W., Zhang, S., Wang, Y., Ivanovic, B., Jiang, M., Pavone, M., Xiao, C.: dvlm-ad: Enhance diffusion vision-language-model for driving via controllable reasoning (2025)
2025
-
[51]
Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415, 2023
Mao, J., Qian, Y., Ye, J., Zhao, H., Wang, Y.: Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415 (2023)
-
[52]
o Research: 2025 waymo open dataset challenge: Vision-based end-to-end driv- ing.https://waymo.com/open/challenges/2025/e2e-driving/(2025), accessed: 2025-04-25
2025
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pan, C., Yaman, B., Nesti, T., Mallik, A., Allievi, A.G., Velipasalar, S., Ren, L.: Vlp: Vision language planning for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14760– 14769 (2024)
2024
-
[54]
Park, S.Y., Cui, C., Ma, Y., Moradipari, A., Gupta, R., Han, K., Wang, Z.: Nu- planqa: A large-scale dataset and benchmark for multi-view driving scene under- standing in multi-modal large language models. arXiv preprint arXiv:2503.12772 (2025)
-
[55]
Peng, Z., Ding, W., You, Y., Chen, Y., Luo, W., Tian, T., Cao, Y., Sharma, A., Xu, D., Ivanovic, B., et al.: Counterfactual vla: Self-reflective vision-language-action model with adaptive reasoning. arXiv preprint arXiv:2512.24426 (2025)
-
[56]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Qian, T., Chen, J., Zhuo, L., Jiao, Y., Jiang, Y.G.: Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 4542–4550 (2024)
2024
-
[57]
Advances in Neural Information Processing Systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems36, 53728–53741 (2023)
2023
-
[58]
Rawal, I., Gupta, S., Hu, Y., Zhan, W.: Nord: A data-efficient vision-language- action model that drives without reasoning. arXiv preprint arXiv:2602.21172 (2026)
-
[59]
arXiv preprint arXiv:2506.11234 , year =
Rowe, L., de Schaetzen, R., Girgis, R., Pal, C., Paull, L.: Poutine: Vision-language- trajectory pre-training and reinforcement learning post-training enable robust end- to-end autonomous driving. arXiv preprint arXiv:2506.11234 (2025)
-
[60]
Shang, S., Chen, Y., Wang, Y., Li, Y., Zhang, Z.: Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving. arXiv preprint arXiv:2509.17940 (2025)
-
[61]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
In: European Conference on Computer Vision
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. In: European Conference on Computer Vision. pp. 256–274. Springer (2024)
2024
-
[63]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Song, R., Liang, C., Cao, H., Yan, Z., Zimmer, W., Gross, M., Festag, A., Knoll, A.: Collaborative semantic occupancy prediction with hybrid feature fusion in con- nected automated vehicles. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 17996–18006 (2024) SpanVLA 19
2024
-
[64]
Latent Chain-of-Thought World Modeling for End-to-End Driving
Tan, S., Chitta, K., Chen, Y., Tian, R., You, Y., Wang, Y., Luo, W., Cao, Y., Krahenbuhl, P., Pavone, M., et al.: Latent chain-of-thought world modeling for end-to-end driving. arXiv preprint arXiv:2512.10226 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
arXiv preprint arXiv:2510.11083 (2025)
Tan, T., Zheng, Y., Liang, R., Wang, Z., Zheng, K., Zheng, J., Li, J., Zhan, X., Liu, J.: Flow matching-based autonomous driving planning with advanced interactive behavior modeling. arXiv preprint arXiv:2510.11083 (2025)
-
[66]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Tian, X., Gu, J., Li, B., Liu, Y., Wang, Y., Zhao, Z., Zhan, K., Jia, P., Lang, X., Zhao, H.: Drivevlm: The convergence of autonomous driving and large vision- language models. arXiv preprint arXiv:2402.12289 (2024)
work page internal anchor Pith review arXiv 2024
-
[67]
Wang, R., Li, H., Han, X., Zhang, Y., Baldwin, T.: Learning from failure: Inte- grating negative examples when fine-tuning large language models as agents. arXiv preprint arXiv:2402.11651 (2024)
-
[68]
Wang, S., Yu, Z., Jiang, X., Lan, S., Shi, M., Chang, N., Kautz, J., Li, Y., Alvarez, J.M.: Omnidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning. arXiv preprint arXiv:2405.01533 (2024)
-
[69]
Wang, Y., Luo, W., Bai, J., Cao, Y., Che, T., Chen, K., Chen, Y., Diamond, J., Ding, Y., Ding, W., et al.: Alpamayo-r1: Bridging reasoning and action pre- diction for generalizable autonomous driving in the long tail. arXiv preprint arXiv:2511.00088 (2025)
-
[70]
Vq-vla: Improving vision-language- action models via scaling vector-quantized action tokenizers
Wang, Y., Ding, P., Li, L., Cui, C., Ge, Z., Tong, X., Song, W., Zhao, H., Zhao, W., Hou, P., et al.: Vla-adapter: An effective paradigm for tiny-scale vision-language- action model. arXiv preprint arXiv:2509.09372 (2025)
-
[71]
Latentvla: Efficient vision-language models for autonomous driving via latent action prediction
Xie, C., Sun, B., Li, T., Wu, J., Hao, Z., Lang, X., Li, H.: Latentvla: Efficient vision-language models for autonomous driving via latent action prediction. arXiv preprint arXiv:2601.05611 (2026)
-
[72]
In: Proceed- ings of the Winter Conference on Applications of Computer Vision
Xing, S., Qian, C., Wang, Y., Hua, H., Tian, K., Zhou, Y., Tu, Z.: Openemma: Open-source multimodal model for end-to-end autonomous driving. In: Proceed- ings of the Winter Conference on Applications of Computer Vision. pp. 1001–1009 (2025)
2025
-
[73]
Xu, R., Lin, H., Jeon, W., Feng, H., Zou, Y., Sun, L., Gorman, J., Tolstaya, E., Tang, S., White, B., et al.: Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios. arXiv preprint arXiv:2510.26125 (2025)
-
[74]
Xu, Y., Hu, Y., Zhang, Z., Meyer, G.P., Mustikovela, S.K., Srinivasa, S., Wolff, E.M.,Huang,X.:Vlm-ad:End-to-endautonomousdrivingthroughvision-language model supervision. arXiv preprint arXiv:2412.14446 (2024)
-
[75]
arXiv preprint arXiv:2506.06659 (2025)
Yao, W., Li, Z., Lan, S., Wang, Z., Sun, X., Alvarez, J.M., Wu, Z.: Drivesuprim: Towards precise trajectory selection for end-to-end planning. arXiv preprint arXiv:2506.06659 (2025)
-
[76]
A survey on efficient vision-language-action models, 2025
Yu, Z., Wang, B., Zeng, P., Zhang, H., Zhang, J., Gao, L., Song, J., Sebe, N., Shen, H.T.: A survey on efficient vision-language-action models. arXiv preprint arXiv:2510.24795 (2025)
-
[77]
Yuan, C., Zhang, Z., Sun, J., Sun, S., Huang, Z., Lee, C.D.W., Li, D., Han, Y., Wong, A., Tee, K.P., et al.: Drama: An efficient end-to-end motion planner for autonomous driving with mamba. arXiv preprint arXiv:2408.03601 (2024)
-
[78]
Zeng, S., Chang, X., Xie, M., Liu, X., Bai, Y., Pan, Z., Xu, M., Wei, X., Guo, N.: Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. arXiv preprint arXiv:2505.17685 (2025)
-
[79]
arXiv preprint arXiv:2602.21952 (2026) 20 Z
Zhang, L., Yuan, Y., Wu, C., Chang, X., Cai, X., Zeng, S., Shi, L., Wang, S., Zhang, H., Xu, M.: Minddriver: Introducing progressive multimodal reasoning for autonomous driving. arXiv preprint arXiv:2602.21952 (2026) 20 Z. Zhou, R. Yang et al
-
[80]
BridgeSim: Unveiling the OL-CL Gap in End-to-End Autonomous Driving
Zhao, S.Z., Wang, L., Ruan, H., Bao, Y., Chen, Y., Leng, Z., Ravichandran, A., He, H., Zhou, Z., Han, X., et al.: Bridgesim: Unveiling the ol-cl gap in end-to-end autonomous driving. arXiv preprint arXiv:2604.10856 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.