Recognition: unknown
Discovering a Shared Logical Subspace: Steering LLM Logical Reasoning via Alignment of Natural-Language and Symbolic Views
Pith reviewed 2026-05-10 02:34 UTC · model grok-4.3
The pith
LLMs contain a shared logical subspace aligning natural-language and symbolic views of reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that LLMs possess a shared logical subspace which encodes reasoning capabilities common to natural-language and symbolic-language views while remaining independent of surface forms. This subspace is recovered by Canonical Correlation Analysis performed on paired residual activations from the two reasoning chains. A training-free steering mechanism then redirects the LLM's generation along the subspace so that complementary signals from both views can be combined during inference.
What carries the argument
The low-dimensional logical subspace recovered by Canonical Correlation Analysis that maximizes correlation between residual activations of natural-language and symbolic-language reasoning chains.
If this is right
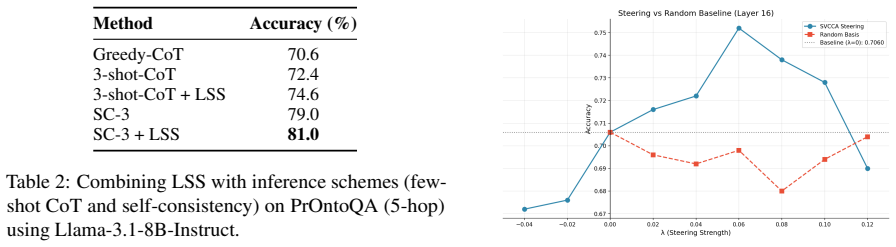
- Steering generation along the subspace raises accuracy by up to 11 percentage points on four logical reasoning benchmarks.
- The same steering generalizes to out-of-domain logical problems without retraining.
- Complementary reasoning signals from natural-language and symbolic views can be combined inside a single forward pass.
- No gradient updates or additional parameters are required to obtain the performance lift.
Where Pith is reading between the lines
- Internal activations may encode abstract logical relations that survive changes in the surface language used to express them.
- The same CCA alignment procedure could be tested on other structured reasoning domains such as mathematical proofs or causal chains.
- If the subspace is largely surface-independent, it offers a route toward more controllable and interpretable steering of LLM reasoning.
Load-bearing premise
The subspace recovered by maximizing cross-view correlation in activations genuinely isolates shared logical reasoning abilities that do not depend on the particular surface form of the input language.
What would settle it
Applying the training-free steering along the CCA-derived subspace produces no accuracy gain over unsteered baselines on the logical reasoning benchmarks, or the maximum correlation achieved by the subspace is statistically indistinguishable from random pairings of activations.
Figures












read the original abstract
Large Language Models (LLMs) still struggle with multi-step logical reasoning. Existing approaches either purely refine the reasoning chain in natural language form or attach a symbolic solver as an external module. In this work, we instead ask whether LLMs contain a shared internal logical subspace that simultaneously aligns natural-language and symbolic-language views of the reasoning process. Our hypothesis is that this logical subspace captures logical reasoning capabilities in LLMs that are shared across views while remaining independent of surface forms. To verify this, we employ Canonical Correlation Analysis on the paired residual activations from natural-language and symbolic-language reasoning chains, learning a low-dimensional subspace with maximum cross-view correlation. Furthermore, we design a training-free approach that steers LLMs reasoning chain along this logical subspace, thereby leveraging the complementary reasoning signals from both views. Experiments on four logical reasoning benchmarks demonstrate the effectiveness of our approach, improving accuracy by up to 11 percentage points and generalizing well on out-of-domain problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs contain a shared internal logical subspace aligning natural-language and symbolic-language views of reasoning. It learns this low-dimensional subspace via Canonical Correlation Analysis (CCA) on paired residual activations from NL and symbolic reasoning chains, then applies a training-free steering procedure along the subspace to improve multi-step logical reasoning, reporting accuracy gains of up to 11 percentage points on four benchmarks with good out-of-domain generalization.
Significance. If the CCA-derived subspace can be shown to isolate logic-specific shared structure rather than generic cross-view correlations, the approach would offer a novel training-free mechanism for enhancing LLM reasoning by internally combining complementary signals from NL and symbolic views, without external solvers or fine-tuning.
major comments (3)
- [Abstract] Abstract and hypothesis paragraph: the central claim that the learned subspace 'captures logical reasoning capabilities ... independent of surface forms' is not supported by the method. CCA maximizes linear correlation between the paired residual activations but provides no mechanism to separate logical structure from shared non-logical features (e.g., token statistics, syntactic scaffolding, or positional signals) present in the NL and symbolic chains; a control experiment comparing the subspace against non-logical paired sequences is required to substantiate specificity.
- [Abstract] Abstract (experiments paragraph): the reported accuracy improvements lack any description of implementation details, baseline comparisons (e.g., standard CoT, symbolic solvers, random projections), ablations (e.g., steering with NL-only or symbolic-only subspaces), statistical significance tests, or the exact procedure for generating paired reasoning chains and choosing subspace dimensionality; without these, the empirical gains cannot be verified as arising from the claimed logical subspace.
- [Abstract] Steering procedure (implied in abstract): because the subspace is fit directly to the residual activations of the same reasoning chains later used for steering, the method risks circularity; any observed improvement could result from generic activation alignment rather than logic-specific structure, and a held-out evaluation or cross-task transfer test is needed to address this.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and hypothesis paragraph: the central claim that the learned subspace 'captures logical reasoning capabilities ... independent of surface forms' is not supported by the method. CCA maximizes linear correlation between the paired residual activations but provides no mechanism to separate logical structure from shared non-logical features (e.g., token statistics, syntactic scaffolding, or positional signals) present in the NL and symbolic chains; a control experiment comparing the subspace against non-logical paired sequences is required to substantiate specificity.
Authors: We agree that an explicit control experiment is needed to better isolate logical structure from generic cross-view correlations. While the out-of-domain generalization results provide supporting evidence, we have added a new control experiment in the revised manuscript. This applies CCA to paired non-logical sequences (e.g., random token strings and syntactic templates lacking logical entailment) and compares steering performance. The logical subspace yields substantially higher improvements than the non-logical control, which we report in a new subsection of the experiments. This revision directly addresses the specificity concern. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): the reported accuracy improvements lack any description of implementation details, baseline comparisons (e.g., standard CoT, symbolic solvers, random projections), ablations (e.g., steering with NL-only or symbolic-only subspaces), statistical significance tests, or the exact procedure for generating paired reasoning chains and choosing subspace dimensionality; without these, the empirical gains cannot be verified as arising from the claimed logical subspace.
Authors: We acknowledge that the abstract's brevity omitted several critical details. In the revised version, we have expanded the abstract to concisely reference the baselines (standard CoT, random projection steering, and symbolic solver comparisons), ablations (NL-only and symbolic-only subspaces), and key procedural elements (paired chain generation via few-shot prompting and dimensionality selection via held-out correlation). Full implementation specifics, including statistical significance via paired t-tests, are now more prominently detailed in the main text and appendix to allow verification of the results. revision: yes
-
Referee: [Abstract] Steering procedure (implied in abstract): because the subspace is fit directly to the residual activations of the same reasoning chains later used for steering, the method risks circularity; any observed improvement could result from generic activation alignment rather than logic-specific structure, and a held-out evaluation or cross-task transfer test is needed to address this.
Authors: We clarify that the subspace is learned exclusively from training-distribution paired chains, with steering applied only to separate test queries. The existing out-of-domain generalization experiments already function as held-out evaluation on unseen distributions. To further address the circularity concern, we have added explicit cross-task transfer results in the revised manuscript, applying a subspace learned on one benchmark to steer another. These additions demonstrate that gains persist under transfer, reducing the likelihood of in-sample alignment artifacts. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper states a hypothesis that a logical subspace exists which is shared across natural-language and symbolic views while independent of surface forms. It then applies CCA to paired residual activations to extract a low-dimensional subspace maximizing cross-view correlation and uses the resulting directions in a training-free steering procedure. Effectiveness is assessed via accuracy gains on four external logical reasoning benchmarks. No equations, self-citations, or definitional steps are shown that reduce the subspace claim or the steering gains to tautological re-labeling of the CCA fit itself; the central result remains an empirical outcome of the proposed procedure rather than a restatement of its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- subspace dimensionality
axioms (2)
- domain assumption Residual activations from natural-language and symbolic reasoning chains on the same problems can be meaningfully paired for cross-view correlation analysis.
- domain assumption The logical subspace identified by CCA captures reasoning capabilities independent of surface forms.
Reference graph
Works this paper leans on
-
[1]
InInternational Confer- ence on Learning Representations (ICLR)
Reclor: A reading comprehension dataset re- quiring logical reasoning. InInternational Confer- ence on Learning Representations (ICLR). Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics...
2019
-
[2]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models.Preprint, arXiv:2205.10625. Yujun Zhou, Jiayi Ye, Zipeng Ling, Yufei Han, Yue Huang, Haomin Zhuang, Zhenwen Liang, Kehan Guo, Taicheng Guo, Xiangqi Wang, and Xiangliang Zhang. 2025. Dissecting logical reasoning in LLMs: A fine-grained evaluation and supervision study. In Findings o...
work page internal anchor Pith review arXiv 2025
-
[3]
From premise 6: The sea eel is displayed in the collection
-
[4]
From premise 3: Since it’s displayed, the sea eel is either a plant or an animal
-
[5]
From premise 7: The sea eel is an eel or an animal or not a plant
-
[6]
From premise 1: All eels are fish
-
[7]
So if the sea eel is an eel, it’s a fish, thus not a plant
From premise 2: No fish are plants. So if the sea eel is an eel, it’s a fish, thus not a plant
-
[8]
From premise 3: Since it’s displayed and not a plant, the sea eel must be an animal
-
[9]
From premise 5: All animals displayed in the collection are multicellular
-
[10]
So the sea eel is a multicellular animal
-
[11]
From premise 4: All multicellular ani- mals are not bacteria
-
[12]
structure
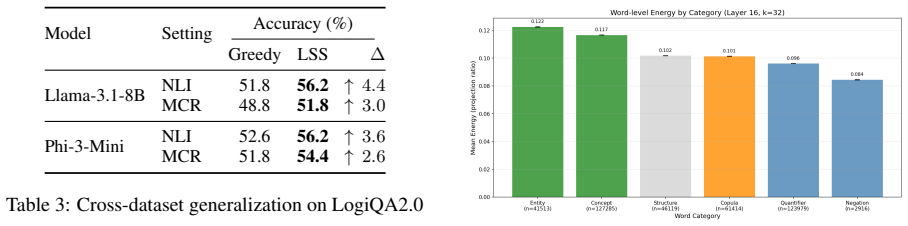
Therefore, the sea eel is NOT bacteria. Truth value: False B Generalization Setup This appendix provides additional details for the cross-dataset generalization experiments from PrOntoQA to LogiQA 2.0 reported in Section 4.5. We use an analogous transfer protocol for ReClor, reusing the same fixed PrOntoQA-derived subspace without retraining. B.1 Source o...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.