Recognition: unknown
ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
Pith reviewed 2026-05-10 02:22 UTC · model grok-4.3
The pith
High-quality controllable human videos are generated by first creating appearance via image models then applying motion and temporal refinement without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
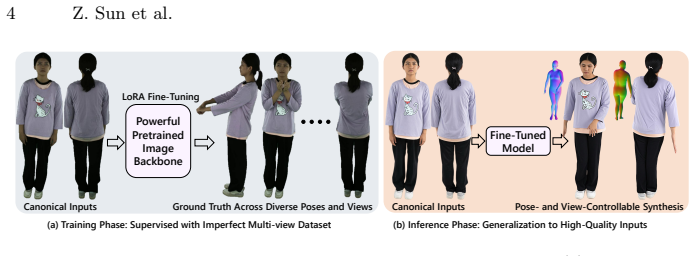
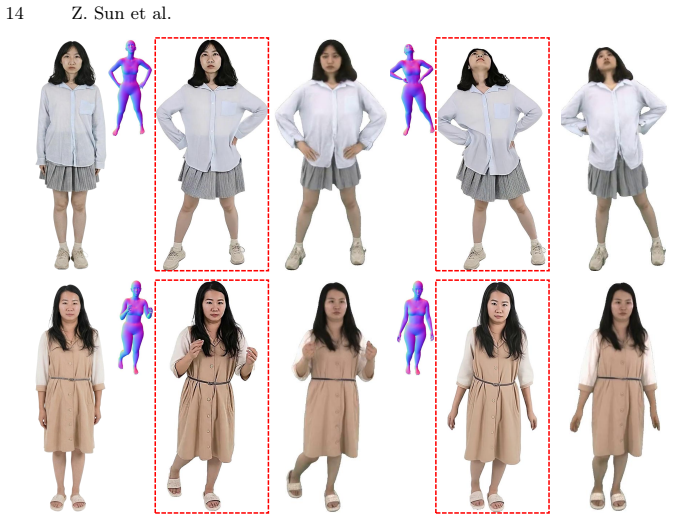
By treating high-quality human appearance as a prior learned through image generation and then layering SMPL-X-based motion guidance plus training-free temporal refinement from a video diffusion model, the method produces temporally consistent, high-quality videos under varied poses and viewpoints without requiring joint end-to-end training on video data.
What carries the argument
A pretrained image backbone that supplies appearance priors, combined with SMPL-X parametric body guidance for pose and viewpoint control, followed by a training-free temporal refinement stage that uses a separate pretrained video diffusion model.
If this is right
- Videos can be produced with independent control over identity appearance, body pose sequence, and camera trajectory.
- No video-specific fine-tuning is needed once the image backbone and refinement model are pretrained.
- New human identities can be introduced by swapping the image-generation stage while keeping the same motion and refinement pipeline.
- The released canonical dataset enables direct comparison of appearance priors across methods.
Where Pith is reading between the lines
- The same image-first separation could extend to other domains such as animal or object video generation where multi-view video data is scarce.
- If the refinement stage can be made conditional on additional signals, finer control over lighting or clothing dynamics might become possible without retraining.
- Compositional image models released with the paper could allow mixing body parts or outfits at the appearance stage before motion is applied.
Load-bearing premise
High-quality appearance learned only from still images can transfer directly to video synthesis when guided by SMPL-X and refined with an off-the-shelf video model, without any joint training on video data.
What would settle it
Generate videos of the same person in extreme novel viewpoints or rapid pose transitions; if visible artifacts, identity drift, or temporal flickering appear at rates higher than competing joint-training methods, the image-first prior fails to carry over effectively.
Figures












read the original abstract
Human video generation remains challenging due to the difficulty of jointly modeling human appearance, motion, and camera viewpoint under limited multi-view data. Existing methods often address these factors separately, resulting in limited controllability or reduced visual quality. We revisit this problem from an image-first perspective, where high-quality human appearance is learned via image generation and used as a prior for video synthesis, decoupling appearance modeling from temporal consistency. We propose a pose- and viewpoint-controllable pipeline that combines a pretrained image backbone with SMPL-X-based motion guidance, together with a training-free temporal refinement stage based on a pretrained video diffusion model. Our method produces high-quality, temporally consistent videos under diverse poses and viewpoints. We also release a canonical human dataset and an auxiliary model for compositional human image synthesis. Code and data are publicly available at https://github.com/Taited/ReImagine.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ReImagine, an image-first pipeline for pose- and viewpoint-controllable high-quality human video generation. High-quality appearance is learned via a pretrained image backbone and used as a prior; motion and viewpoint are controlled via SMPL-X guidance; temporal consistency is achieved through a training-free refinement stage that employs a pretrained video diffusion model. The authors also release a canonical human dataset and an auxiliary model for compositional human image synthesis, with code and data made publicly available.
Significance. If the central claims hold, the work would be significant for its modular decoupling of appearance modeling (via image priors) from motion and temporal consistency, potentially reducing reliance on scarce multi-view video data. The public release of the dataset, auxiliary model, and code is a clear strength that supports reproducibility and downstream research in controllable human video synthesis.
major comments (2)
- [§3] §3 (Method), temporal refinement stage: the claim that a training-free video diffusion model can reliably resolve frame-to-frame appearance/lighting mismatches induced by SMPL-X pose and viewpoint changes (without joint training or fine-tuning) is load-bearing for the temporal-consistency guarantee, yet the manuscript provides no ablations or failure-case analysis on distribution shift between the image-backbone outputs and the diffusion model's training distribution.
- [§4] §4 (Experiments): quantitative support for the claim of 'high-quality, temporally consistent videos under diverse poses and viewpoints' is not fully detailed in the provided description; without reported metrics (e.g., FVD, temporal consistency scores) and direct comparisons against jointly-trained baselines on the same SMPL-X-driven test cases, the superiority of the image-first + training-free approach cannot be assessed.
minor comments (2)
- The abstract and method overview would benefit from a concise diagram or pseudocode summarizing the three-stage pipeline (image backbone → SMPL-X guidance → training-free refinement) to clarify data flow and conditioning.
- Notation for SMPL-X parameters (pose, shape, viewpoint) should be explicitly defined in the first use within the method section to avoid ambiguity for readers unfamiliar with the exact parameterization.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance, the recognition of our public releases, and the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), temporal refinement stage: the claim that a training-free video diffusion model can reliably resolve frame-to-frame appearance/lighting mismatches induced by SMPL-X pose and viewpoint changes (without joint training or fine-tuning) is load-bearing for the temporal-consistency guarantee, yet the manuscript provides no ablations or failure-case analysis on distribution shift between the image-backbone outputs and the diffusion model's training distribution.
Authors: We agree that additional ablations and failure-case analysis for the training-free temporal refinement stage would better substantiate the claims. In the revised manuscript, we will add experiments ablating the refinement stage (with/without it) across diverse SMPL-X pose and viewpoint changes, including quantitative measures of mismatch resolution and qualitative discussion of remaining failure cases due to distribution shifts between the image backbone outputs and the video diffusion model's training data. revision: yes
-
Referee: [§4] §4 (Experiments): quantitative support for the claim of 'high-quality, temporally consistent videos under diverse poses and viewpoints' is not fully detailed in the provided description; without reported metrics (e.g., FVD, temporal consistency scores) and direct comparisons against jointly-trained baselines on the same SMPL-X-driven test cases, the superiority of the image-first + training-free approach cannot be assessed.
Authors: We acknowledge that expanded quantitative evaluation would allow better assessment of the approach. The revised experiments section will report standard metrics such as Fréchet Video Distance (FVD) and temporal consistency scores. We will also add direct comparisons to relevant jointly-trained baselines on the same SMPL-X-driven test cases, using our publicly released canonical human dataset and code to support reproducibility. revision: yes
Circularity Check
No significant circularity; pipeline assembles independent pretrained components
full rationale
The paper presents a pipeline that decouples appearance modeling (via a pretrained image backbone) from motion (via SMPL-X guidance) and applies a separate training-free refinement stage using an off-the-shelf pretrained video diffusion model. No equations, fitted parameters, or self-citations are shown that would reduce any claimed prediction or result to the inputs by construction. The central claims rest on the empirical combination of existing models rather than on any self-definitional loop, uniqueness theorem imported from the authors' prior work, or renaming of known results. This is the standard case of an engineering synthesis paper whose derivation chain remains externally grounded.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Pretrained image diffusion models provide high-quality human appearance priors suitable for video synthesis.
- domain assumption SMPL-X-based guidance is sufficient to control diverse poses and viewpoints in the generated video.
- domain assumption A training-free refinement stage using a pretrained video diffusion model can enforce temporal consistency.
Reference graph
Works this paper leans on
-
[1]
Apache-2.0 license
Alibaba-PAI: Wan2.1-fun-v1.1-14b-control.https://huggingface.co/alibaba- pai/Wan2.1-Fun-V1.1-14B-Control(2025), hugging Face Model, accessed: 2025- 01-21. Apache-2.0 license. 2, 10
2025
-
[2]
Chen, L., Ma, T., Liu, J., Li, B., Chen, Z., Liu, L., He, X., Li, G., He, Q., Wu, Z.: Humo:Human-centricvideogenerationviacollaborativemulti-modalconditioning. arXiv preprint arXiv:2509.08519 (2025) 2, 5
-
[4]
Cheng, G., Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Li, J., Meng, D., Qi, J., Qiao, P., et al.: Wan-animate: Unified character animation and replacement with holistic replication. arXiv preprint arXiv:2509.14055 (2025) 2, 10
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, T., Song, L., Ge, Y., Liu, W., Wang, X., Shan, Y.: Yolo-world: Real-time open-vocabulary object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16901–16911 (2024) 16
2024
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Cheng, W., Chen, R., Fan, S., Yin, W., Chen, K., Cai, Z., Wang, J., Gao, Y., Yu, Z., Lin, Z., Ren, D., Yang, L., Liu, Z., Loy, C.C., Qian, C., Wu, W., Lin, D., Dai, B., Lin, K.Y.: Dna-rendering: A diverse neural actor repository for high- fidelity human-centric rendering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). ...
2023
-
[7]
In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G
Choi, Y., Kwak, S., Lee, K., Choi, H., Shin, J.: Improving diffusion models for authentic virtual try-on in the wild. In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 206–235. Springer Nature Switzerland, Cham (2025) 5
2024
-
[8]
In: Forty-first International Conference on Machine Learning (2024) 3
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high- resolution image synthesis. In: Forty-first International Conference on Machine Learning (2024) 3
2024
-
[9]
In: European Conference on Computer Vision
Fu, J., Li, S., Jiang, Y., Lin, K.Y., Qian, C., Loy, C.C., Wu, W., Liu, Z.: Stylegan- human: A data-centric odyssey of human generation. In: European Conference on Computer Vision. pp. 1–19. Springer (2022) 4
2022
-
[10]
Communications of the ACM63(11), 139–144 (2020) 4
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM63(11), 139–144 (2020) 4
2020
-
[11]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868 (2022) 5
work page internal anchor Pith review arXiv 2022
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, L.: Animate anyone: Consistent and controllable image-to-video synthesis for character animation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8153–8163 (2024) 2, 5
2024
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 12
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 12
2024
-
[14]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) 3, 5, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with con- ditional adversarial networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1125–1134 (2017) 4
2017
-
[16]
co / jasperai / Flux
jasperai: Flux.1-dev-controlnet-surface-normals.https : / / huggingface . co / jasperai / Flux . 1 - dev - Controlnet - Surface - Normals(2025), hugging Face Model, accessed: 2025-01-21 9
2025
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ju, X., Zeng, A., Zhao, C., Wang, J., Zhang, L., Xu, Q.: Humansd: A native skeleton-guided diffusion model for human image generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15988–15998 (2023) 5 18 Z. Sun et al
2023
-
[18]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Karaev, N., Makarov, I., Wang, J., Neverova, N., Vedaldi, A., Rupprecht, C.: Co- tracker3: Simpler and better point tracking by pseudo-labelling real videos. In: Proc. arXiv:2410.11831 (2024) 12
-
[19]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017) 4
work page internal anchor Pith review arXiv 2017
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019) 4
2019
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8110–8119 (2020) 4
2020
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollar, P., Girshick, R.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4015–4026 (October 2023) 16
2023
-
[23]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024) 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025) 3, 5, 9
work page internal anchor Pith review arXiv 2025
-
[25]
arXiv preprint arXiv:2505.01838 (2025) 3, 10
Li, C., Liao, H., Zhi, Y., Yang, X., Sun, Z., Chang, J., Cui, S., Han, X.: Mvhu- mannet++: A large-scale dataset of multi-view daily dressing human captures with richer annotations for 3d human digitization. arXiv preprint arXiv:2505.01838 (2025) 3, 10
-
[26]
ACM Transactions on Graphics (TOG)44(6), 1–21 (2025) 16
Lin, X., Yu, F., Hu, J., You, Z., Shi, W., Ren, J.S., Gu, J., Dong, C.: Harnessing diffusion-yielded score priors for image restoration. ACM Transactions on Graphics (TOG)44(6), 1–21 (2025) 16
2025
-
[27]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [28]
-
[29]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Liu, S., Zhao, Z., Zhi, Y., Zhao, Y., Huang, B., Wang, S., Wang, R., Xuan, M., Li, Z., Gao, S.: Heromaker: Human-centric video editing with motion priors. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 3761– 3770 (2024) 5
2024
-
[30]
arXiv preprint arXiv:2310.08579 (2023) 5
Liu, X., Ren, J., Siarohin, A., Skorokhodov, I., Li, Y., Lin, D., Liu, X., Liu, Z., Tulyakov, S.: Hyperhuman: Hyper-realistic human generation with latent struc- tural diffusion. arXiv preprint arXiv:2310.08579 (2023) 5
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lu, Y., Zhang, M., Ma, A.J., Xie, X., Lai, J.: Coarse-to-fine latent diffusion for pose-guided person image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6420–6429 (2024) 5
2024
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Men, Y., Yao, Y., Cui, M., Bo, L.: Mimo: Controllable character video synthesis with spatial decomposed modeling. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21181–21191 (2025) 5
2025
-
[33]
In: CVPR Workshops (June
Morelli, D., Fincato, M., Cornia, M., Landi, F., Cesari, F., Cucchiara, R.: Dress code: High-resolution multi-category virtual try-on. In: CVPR Workshops (June
-
[34]
5 ReImagine: Image-First Human Video Generation 19
-
[35]
arXiv preprint arXiv:2501.05369 (2025) 5
Ning,S.,Qin,Y.,Han,X.:1-2-1:Renaissanceofsingle-networkparadigmforvirtual try-on. arXiv preprint arXiv:2501.05369 (2025) 5
-
[36]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 4
2023
-
[37]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (June 2022) 4, 5
2022
-
[39]
Sarkar, K., Liu, L., Golyanik, V., Theobalt, C.: Humangan: A generative model of human images. In: 2021 International Conference on 3D Vision (3DV). pp. 258–267 (2021).https://doi.org/10.1109/3DV53792.2021.000364
-
[40]
Shao, R., Pang, Y., Zheng, Z., Sun, J., Liu, Y.: Human4dit: 360-degree human video generation with 4d diffusion transformer. arXiv preprint arXiv:2405.17405 (2024) 2, 5, 10
-
[41]
arXiv preprint (2024) 5
Shen, F., Jiang, X., He, X., Ye, H., Wang, C., Du, X., Li, Z., Tang, J.: Imagdressing- v1: Customizable virtual dressing. arXiv preprint (2024) 5
2024
-
[42]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020) 4
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[43]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023) 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tu, S., Xing, Z., Han, X., Cheng, Z.Q., Dai, Q., Luo, C., Wu, Z.: Stableanimator: High-quality identity-preserving human image animation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21096–21106 (2025) 5
2025
-
[45]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 1, 3, 5, 9, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Science China Information Sciences (2025) 1, 5
Wang, X., Zhang, S., Gao, C., Wang, J., Zhou, X., Zhang, Y., Yan, L., Sang, N.: Unianimate: Taming unified video diffusion models for consistent human image animation. Science China Information Sciences (2025) 1, 5
2025
-
[47]
arXiv preprint arXiv:2409.19911 (2024) 5
Wang, X., Zhang, S., Qiu, H., Chu, R., Li, Z., Zhang, Y., Gao, C., Wang, Y., Shen, C., Sang, N.: Replace anyone in videos. arXiv preprint arXiv:2409.19911 (2024) 5
-
[48]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 3, 5, 10
work page internal anchor Pith review arXiv 2025
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiong, Z., Li, C., Liu, K., Liao, H., Hu, J., Zhu, J., Ning, S., Qiu, L., Wang, C., Wang, S., Cui, S., Han, X.: Mvhumannet: A large-scale dataset of multi-view daily dressing human captures. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19801–19811 (June 2024) 10, 15, 16
2024
-
[50]
arXiv preprint arXiv:2403.01779 (2024) 5
Xu, Y., Gu, T., Chen, W., Chen, C.: Ootdiffusion: Outfitting fusion based latent diffusion for controllable virtual try-on. arXiv preprint arXiv:2403.01779 (2024) 5
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, Z., Zhang, J., Liew, J.H., Yan, H., Liu, J.W., Zhang, C., Feng, J., Shou, M.Z.: Magicanimate: Temporally consistent human image animation using diffu- sion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1481–1490 (2024) 2, 5 20 Z. Sun et al
2024
-
[52]
Advances in Neural Information Processing Systems 37, 51039–51062 (2024) 5
Yang, Q., Guan, J., Wang, K., Yu, L., Chu, W., Zhou, H., Feng, Z., Feng, H., Ding, E., Wang, J., et al.: Showmaker: Creating high-fidelity 2d human video via fine- grained diffusion modeling. Advances in Neural Information Processing Systems 37, 51039–51062 (2024) 5
2024
-
[53]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang, Z., Zeng, A., Yuan, C., Li, Y.: Effective whole-body pose estimation with two-stages distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4210–4220 (2023) 11
2023
-
[54]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024) 5
work page internal anchor Pith review arXiv 2024
-
[55]
In: European Conference on Computer Vision
Zhai, Y., Lin, K., Li, L., Lin, C.C., Wang, J., Yang, Z., Doermann, D., Yuan, J., Liu, Z., Wang, L.: Idol: Unified dual-modal latent diffusion for human-centric joint video-depth generation. In: European Conference on Computer Vision. pp. 134–152. Springer (2024) 5
2024
-
[56]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023) 5
2023
-
[57]
Zhang, Y., Gu, J., Wang, L.W., Wang, H., Cheng, J., Zhu, Y., Zou, F.: Mimic- motion: High-quality human motion video generation with confidence-aware pose guidance. arXiv preprint arXiv:2406.19680 (2024) 5
-
[58]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Zhi, Y., Li, C., Liao, H., Yang, X., Sun, Z., Chang, J., Cun, X., Feng, W., Han, X.: Mv-performer: Taming video diffusion model for faithful and synchronized multi- view performer synthesis. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–14 (2025) 2, 5
2025
-
[59]
In: European Conference on Com- puter Vision
Zhong, X., Huang, X., Yang, X., Lin, G., Wu, Q.: Deco: Decoupled human-centered diffusion video editing with motion consistency. In: European Conference on Com- puter Vision. pp. 352–370. Springer (2024) 5
2024
-
[60]
In: ECCV
Zhu, S., Chen, J.L., Dai, Z., Dong, Z., Xu, Y., Cao, X., Yao, Y., Zhu, H., Zhu, S.: Champ: Controllable and consistent human image animation with 3d parametric guidance. In: ECCV. Springer (2024) 2, 5 ReImagine: Image-First Human Video Generation 21 Supplementary Material This document provides additional discussion, experimental details, ablation studies...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.