Recognition: unknown
Benign Overfitting in Adversarial Training for Vision Transformers
Pith reviewed 2026-05-10 02:53 UTC · model grok-4.3
The pith
Adversarial training on simplified Vision Transformers achieves nearly zero robust training loss and generalization error under specific signal-to-noise ratio conditions, leading to benign overfitting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
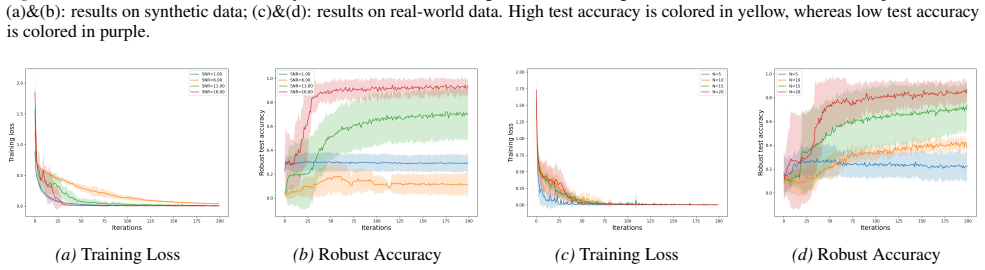
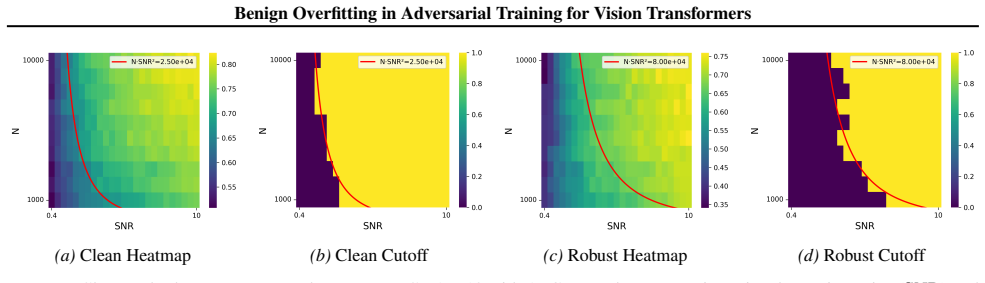
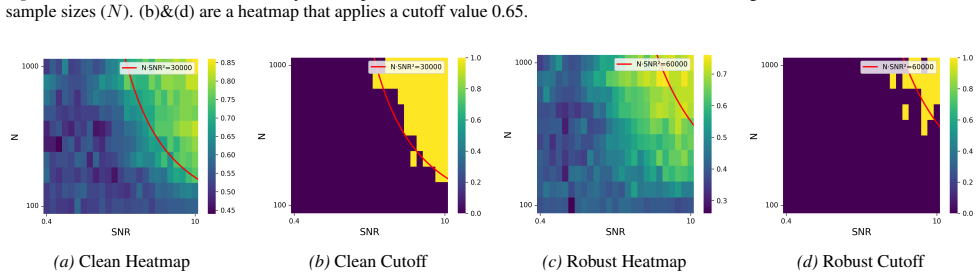
When trained under a signal-to-noise ratio that satisfies a certain condition and within a moderate perturbation budget, adversarial training enables simplified Vision Transformers to achieve nearly zero robust training loss and robust generalization error under certain regimes, resulting in benign overfitting.
What carries the argument
Simplified Vision Transformer architectures analyzed through robust training loss and generalization error bounds under adversarial training subject to a signal-to-noise ratio condition.
If this is right
- Vision Transformers can exhibit benign overfitting similar to CNNs in adversarial training settings.
- Robust generalization holds despite overfitting when the signal-to-noise condition is met.
- Theoretical guarantees apply within moderate perturbation budgets.
- Empirical validation extends to both synthetic and real-world data.
Where Pith is reading between the lines
- Practical Vision Transformers may achieve similar robustness if their effective signal-to-noise ratios align with the analyzed condition.
- Benign overfitting could be a broader property across attention-based models in adversarial robustness tasks.
- Future extensions might relax the simplified architecture assumptions to cover standard ViT scales.
- Links to non-adversarial benign overfitting phenomena in transformers warrant further study.
Load-bearing premise
The analysis depends on simplified Vision Transformer architectures and the existence of a specific condition on the signal-to-noise ratio that may not directly apply to complex real-world models or data.
What would settle it
Observing high robust training loss or non-vanishing robust generalization error in experiments where the signal-to-noise ratio condition is violated or when using non-simplified full-scale Vision Transformers.
Figures





read the original abstract
Despite the remarkable success of Vision Transformers (ViTs) across a wide range of vision tasks, recent studies have revealed that they remain vulnerable to adversarial examples, much like Convolutional Neural Networks (CNNs). A common empirical defense strategy is adversarial training, yet the theoretical underpinnings of its robustness in ViTs remain largely unexplored. In this work, we present the first theoretical analysis of adversarial training under simplified ViT architectures. We show that, when trained under a signal-to-noise ratio that satisfies a certain condition and within a moderate perturbation budget, adversarial training enables ViTs to achieve nearly zero robust training loss and robust generalization error under certain regimes. Remarkably, this leads to strong generalization even in the presence of overfitting, a phenomenon known as \emph{benign overfitting}, previously only observed in CNNs (with adversarial training). Experiments on both synthetic and real-world datasets further validate our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide the first theoretical analysis of adversarial training under simplified Vision Transformer (ViT) architectures. It asserts that, when the signal-to-noise ratio satisfies a certain (unspecified) condition and the perturbation budget is moderate, adversarial training yields nearly zero robust training loss and robust generalization error, resulting in benign overfitting. This extends prior observations from CNNs and is supported by experiments on synthetic and real-world datasets.
Significance. If the results hold, the work would meaningfully extend the study of benign overfitting in adversarial settings from CNNs to ViTs, offering conditions under which robust generalization can occur despite overfitting. The theoretical framing combined with empirical validation on both synthetic and real data strengthens its potential impact for understanding transformer robustness, though the simplifications limit immediate applicability to practical ViTs.
major comments (3)
- [§3] §3 (Simplified ViT Architecture and Theoretical Analysis): The central claim of benign overfitting under adversarial training is derived only for a simplified single-head, single-layer ViT. No reduction or argument is provided showing that the SNR condition and the zero robust-loss regime are preserved when restoring multi-head self-attention and multiple layers, where patch embedding interactions and perturbation effects on attention weights may qualitatively differ.
- [Abstract, §4] Abstract and §4 (Main Theoretical Result): The 'certain condition' on signal-to-noise ratio and the 'certain regimes' for nearly zero robust training loss and generalization error are stated without an explicit statement, derivation, or bound. This makes the load-bearing claim difficult to verify or falsify from the given analysis.
- [§5] §5 (Experiments): The real-world dataset results are presented without reported statistical significance, error bars across multiple runs, or explicit controls confirming that the tested SNR and perturbation budgets match the theoretical condition, weakening the link between theory and the claimed validation.
minor comments (3)
- [Abstract, §1] The abstract and introduction refer to 'benign overfitting, previously only observed in CNNs' without citing the specific prior CNN adversarial-training papers being extended.
- [§3] Notation for the SNR condition and perturbation budget should be introduced with symbols early in the theoretical section rather than described only in prose.
- [§5] Figure captions for synthetic data plots should explicitly state the SNR value and perturbation radius used in each panel to allow direct comparison with the theoretical condition.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating the revisions we will make where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Simplified ViT Architecture and Theoretical Analysis): The central claim of benign overfitting under adversarial training is derived only for a simplified single-head, single-layer ViT. No reduction or argument is provided showing that the SNR condition and the zero robust-loss regime are preserved when restoring multi-head self-attention and multiple layers, where patch embedding interactions and perturbation effects on attention weights may qualitatively differ.
Authors: We agree that the analysis is restricted to a simplified single-head, single-layer architecture. This simplification was chosen to enable a rigorous closed-form analysis of the attention mechanism under adversarial perturbations while isolating the effects of SNR and perturbation budget. Extending the proof to multi-head and multi-layer cases involves substantial additional technical difficulties arising from inter-head interactions and layer-wise propagation of perturbations. In the revision we will add an explicit limitations subsection in §3 that discusses these challenges, explains why the simplified model still captures the core benign-overfitting mechanism, and reports new empirical results on deeper ViT variants to show that the phenomenon persists. revision: partial
-
Referee: [Abstract, §4] Abstract and §4 (Main Theoretical Result): The 'certain condition' on signal-to-noise ratio and the 'certain regimes' for nearly zero robust training loss and generalization error are stated without an explicit statement, derivation, or bound. This makes the load-bearing claim difficult to verify or falsify from the given analysis.
Authors: We accept that the SNR condition and the regimes for near-zero robust loss should be stated explicitly. The condition is that the signal strength exceeds a threshold determined by the noise variance and the perturbation radius (specifically SNR > 1 + O(ε) where ε is the perturbation budget). In the revised manuscript we will insert the precise mathematical statement and a short derivation sketch into the abstract, the introduction, and §4 so that the claim is directly verifiable. revision: yes
-
Referee: [§5] §5 (Experiments): The real-world dataset results are presented without reported statistical significance, error bars across multiple runs, or explicit controls confirming that the tested SNR and perturbation budgets match the theoretical condition, weakening the link between theory and the claimed validation.
Authors: We thank the referee for this observation. In the revision we will augment §5 with results from at least five independent runs, reporting means and standard deviations with error bars, together with statistical significance tests. We will also add a table that explicitly verifies that the SNR values and perturbation budgets used in the real-world experiments satisfy the theoretical condition derived in §4. revision: yes
- A formal reduction proving that the SNR condition and zero robust-loss regime are preserved under multi-head, multi-layer self-attention is beyond the scope of the present theoretical framework and would require a substantially longer, separate analysis.
Circularity Check
No circularity detected; theoretical result self-contained under stated simplifications
full rationale
The paper presents a theoretical analysis of adversarial training for simplified ViT architectures, claiming nearly zero robust training loss and generalization error (benign overfitting) when SNR satisfies an unspecified condition and perturbation budget is moderate. No equations, fitted parameters, or self-citations appear in the provided abstract or summary that reduce the central claim to a self-definition, renamed empirical pattern, or load-bearing prior result by the same authors. The derivation is framed as a first-principles proof under explicit architectural simplifications rather than any internal fitting or ansatz smuggling. This is the normal case of an independent mathematical argument whose validity can be checked externally against the stated assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Stable Vision Concept Transformers for Medical Diagnosis , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2025 , organization=
2025
-
[2]
arXiv preprint arXiv:2310.06112 , year=
Theoretical analysis of robust overfitting for wide DNNs: An NTK approach , author=. arXiv preprint arXiv:2310.06112 , year=
-
[3]
ICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models , year=
Understanding Private Learning From Feature Perspective , author=. ICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models , year=
2025
-
[4]
IEEE Transactions on Knowledge and Data Engineering , year=
Towards stable and explainable attention mechanisms , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[5]
Forty-first International Conference on Machine Learning , year=
Improving interpretation faithfulness for vision transformers , author=. Forty-first International Conference on Machine Learning , year=
-
[6]
Understanding forgetting in continual learning with linear regression , author=. arXiv preprint arXiv:2405.17583 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Revisiting differentially private relu regression , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Seat: stable and explainable attention , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[9]
arXiv preprint arXiv:2310.13345 , year=
An llm can fool itself: A prompt-based adversarial attack , author=. arXiv preprint arXiv:2310.13345 , year=
-
[10]
LeCun, Yann and Cortes, Corinna and Burges, CJ , journal=
-
[11]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[12]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[13]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[14]
International conference on machine learning , pages=
Benign overfitting in two-layer relu convolutional neural networks , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[15]
Advances in neural information processing systems , volume=
Benign overfitting in two-layer convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Unveil benign overfitting for transformer in vision: Training dynamics, convergence, and generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2502.12508 , year=
Understanding generalization in transformers: Error bounds and training dynamics under benign and harmful overfitting , author=. arXiv preprint arXiv:2502.12508 , year=
-
[18]
Forty-first International Conference on Machine Learning , year=
Benign overfitting in adversarial training of neural networks , author=. Forty-first International Conference on Machine Learning , year=
-
[19]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[20]
arXiv preprint arXiv:1906.06032 , year=
Adversarial training can hurt generalization , author=. arXiv preprint arXiv:1906.06032 , year=
-
[21]
International Conference on Machine Learning , pages=
More data can expand the generalization gap between adversarially robust and standard models , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[22]
Advances in Neural Information Processing Systems , volume=
Why robust generalization in deep learning is difficult: Perspective of expressive power , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Stability analysis and generalization bounds of adversarial training , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
International conference on machine learning , pages=
Towards better robust generalization with shift consistency regularization , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[25]
Intriguing properties of neural networks
Intriguing properties of neural networks , author=. arXiv preprint arXiv:1312.6199 , year=
work page internal anchor Pith review arXiv
-
[26]
Explaining and Harnessing Adversarial Examples
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
work page internal anchor Pith review arXiv
-
[27]
Towards Deep Learning Models Resistant to Adversarial Attacks
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
work page internal anchor Pith review arXiv
-
[28]
Advances in Neural Information Processing Systems , volume=
When adversarial training meets vision transformers: Recipes from training to architecture , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
arXiv preprint arXiv:2103.15670 , year=
On the adversarial robustness of vision transformers , author=. arXiv preprint arXiv:2103.15670 , year=
-
[30]
International conference on machine learning , pages=
Understanding the robustness in vision transformers , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[31]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[32]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[33]
Advances in neural information processing systems , volume=
Imagenet classification with deep convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[34]
Proceedings of the National Academy of Sciences , volume=
Benign overfitting in linear regression , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[35]
International Conference on Machine Learning , pages=
Implicit regularization leads to benign overfitting for sparse linear regression , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[36]
Journal of Machine Learning Research , volume=
Benign overfitting in ridge regression , author=. Journal of Machine Learning Research , volume=
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Benign Overfitting in Multiclass Classification: All Roads Lead to Interpolation , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[38]
arXiv preprint arXiv:2104.13628 , year=
Risk Bounds for Over-parameterized Maximum Margin Classification on Sub-Gaussian Mixtures , author=. arXiv preprint arXiv:2104.13628 , year=
-
[39]
arXiv preprint arXiv:2106.03212 , year=
Towards an understanding of benign overfitting in neural networks , author=. arXiv preprint arXiv:2106.03212 , year=
-
[40]
The Thirty Sixth Annual Conference on Learning Theory , pages=
Benign overfitting in linear classifiers and leaky relu networks from kkt conditions for margin maximization , author=. The Thirty Sixth Annual Conference on Learning Theory , pages=. 2023 , organization=
2023
-
[41]
arXiv preprint arXiv:2410.01774 , year=
Trained transformer classifiers generalize and exhibit benign overfitting in-context , author=. arXiv preprint arXiv:2410.01774 , year=
-
[42]
Uncertainty in Artificial Intelligence , pages=
Benign overfitting in adversarially robust linear classification , author=. Uncertainty in Artificial Intelligence , pages=. 2023 , organization=
2023
-
[43]
arXiv preprint arXiv:2012.09816 , year=
Towards understanding ensemble, knowledge distillation and self-distillation in deep learning , author=. arXiv preprint arXiv:2012.09816 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Vision transformers provably learn spatial structure , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International Conference on Machine Learning , pages=
Towards understanding how momentum improves generalization in deep learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[46]
arXiv preprint arXiv:2412.01021 , year=
On the feature learning in diffusion models , author=. arXiv preprint arXiv:2412.01021 , year=
-
[47]
International Conference on Machine Learning , pages=
The benefits of mixup for feature learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[48]
Conference on Learning Theory , pages=
Benign overfitting without linearity: Neural network classifiers trained by gradient descent for noisy linear data , author=. Conference on Learning Theory , pages=. 2022 , organization=
2022
-
[49]
Journal of Machine Learning Research , volume=
Deep linear networks can benignly overfit when shallow ones do , author=. Journal of Machine Learning Research , volume=
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Pyramid adversarial training improves vit performance , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
arXiv preprint arXiv:2501.01529 , year=
SAFER: Sharpness Aware layer-selective Finetuning for Enhanced Robustness in vision transformers , author=. arXiv preprint arXiv:2501.01529 , year=
-
[52]
Understanding In-Context Learning of Linear Models in Transformers Through an Adversarial Lens , author=
-
[53]
arXiv preprint arXiv:2505.14042 , year=
Adversarially Pretrained Transformers may be Universally Robust In-Context Learners , author=. arXiv preprint arXiv:2505.14042 , year=
-
[54]
arXiv preprint arXiv:2502.04204 , year=
Short-length Adversarial Training Helps LLMs Defend Long-length Jailbreak Attacks: Theoretical and Empirical Evidence , author=. arXiv preprint arXiv:2502.04204 , year=
-
[55]
arXiv preprint arXiv:2502.04679 , year=
Mechanistic understandings of representation vulnerabilities and engineering robust vision transformers , author=. arXiv preprint arXiv:2502.04679 , year=
-
[56]
European Conference on Computer Vision , pages=
Towards efficient adversarial training on vision transformers , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[57]
The surprising harmfulness of benign overfitting for adversarial robustness , author=. arXiv preprint arXiv:2401.12236 , year=
-
[58]
Communications on Pure and Applied Mathematics , volume=
The generalization error of random features regression: Precise asymptotics and the double descent curve , author=. Communications on Pure and Applied Mathematics , volume=. 2022 , publisher=
2022
-
[59]
Annals of statistics , volume=
Surprises in high-dimensional ridgeless least squares interpolation , author=. Annals of statistics , volume=
-
[60]
International conference on machine learning , pages=
To understand deep learning we need to understand kernel learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[61]
Advances in neural information processing systems , volume=
Adversarially robust generalization requires more data , author=. Advances in neural information processing systems , volume=
-
[62]
Advances in neural information processing systems , volume=
Are transformers more robust than cnns? , author=. Advances in neural information processing systems , volume=
-
[63]
Electronics , volume=
Comparative Study of Adversarial Defenses: Adversarial Training and Regularization in Vision Transformers and CNNs , author=. Electronics , volume=. 2024 , publisher=
2024
-
[64]
International conference on machine learning , pages=
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[65]
arXiv preprint arXiv:2410.07746 , year=
Benign overfitting in single-head attention , author=. arXiv preprint arXiv:2410.07746 , year=
-
[66]
arXiv preprint arXiv:2409.17625 , year=
Benign Overfitting in Token Selection of Attention Mechanism , author=. arXiv preprint arXiv:2409.17625 , year=
-
[67]
arXiv preprint arXiv:2302.06015 , year=
A theoretical understanding of shallow vision transformers: Learning, generalization, and sample complexity , author=. arXiv preprint arXiv:2302.06015 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.