Recognition: unknown
Safe Continual Reinforcement Learning in Non-stationary Environments
Pith reviewed 2026-05-10 02:38 UTC · model grok-4.3
The pith
Reinforcement learning controllers face an unresolved tension between staying safe and adapting to changing conditions without forgetting past lessons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
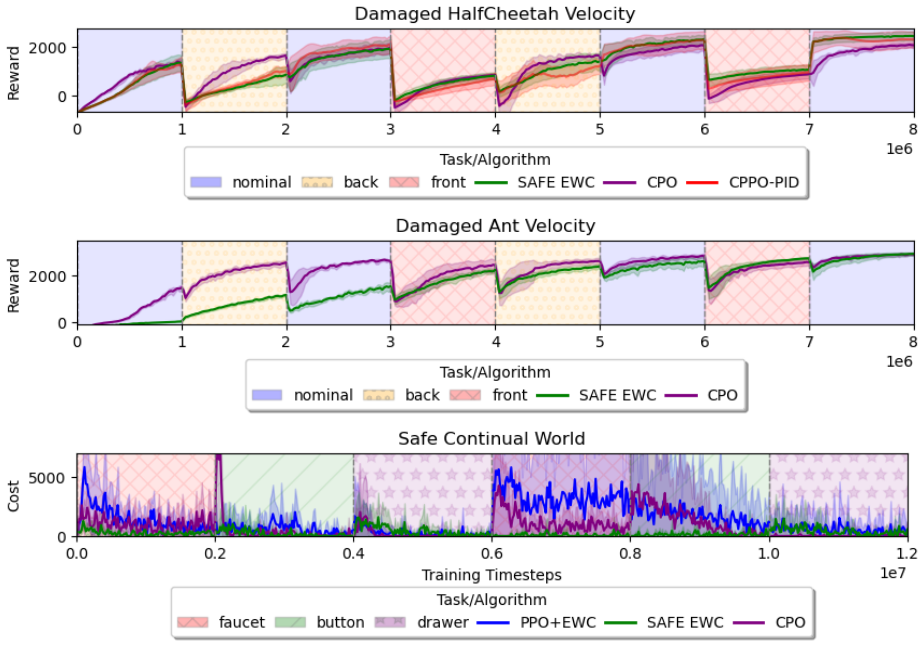
The central finding is that a fundamental tension exists between maintaining safety constraints and preventing catastrophic forgetting when reinforcement learning agents must adapt continually under non-stationary dynamics. Representative methods drawn from safe RL, continual RL, and their direct combinations generally cannot satisfy both requirements simultaneously across the introduced benchmarks. Regularization-based strategies can reduce the severity of the conflict to a degree but do not eliminate it.
What carries the argument
Three custom benchmark environments that embed safety-critical continual adaptation tasks, together with systematic comparisons of safe RL, continual RL, and hybrid algorithms plus regularization strategies.
If this is right
- Methods that enforce safety constraints during learning tend to overwrite earlier policies when dynamics change.
- Direct combinations of safe RL and continual RL techniques do not overcome the safety-forgetting trade-off.
- Regularization approaches can narrow the performance gap but still permit either transient violations or loss of prior competence.
- Developing controllers for sustained operation will require addressing open challenges in joint safety and adaptation.
Where Pith is reading between the lines
- Real-world systems such as robotic platforms or process control may require explicit mechanisms to detect and respond to distribution shifts while preserving safety margins.
- Extending the benchmarks with sensor noise or partial observability could expose whether the observed tension persists under more realistic conditions.
- The trade-off suggests that theoretical work linking safety certificates to continual-learning guarantees could guide the design of next-generation methods.
Load-bearing premise
The three benchmark environments adequately capture the main difficulties that arise when safety-critical controllers must adapt to real non-stationary physical systems.
What would settle it
Demonstration of an algorithm that keeps all safety constraints satisfied while showing no measurable performance drop from forgetting across multiple non-stationary transitions in the three benchmarks would contradict the reported tension.
Figures





read the original abstract
Reinforcement learning (RL) offers a compelling data-driven paradigm for synthesizing controllers for complex systems when accurate physical models are unavailable; however, most existing control-oriented RL methods assume stationarity and, therefore, struggle in real-world non-stationary deployments where system dynamics and operating conditions can change unexpectedly. Moreover, RL controllers acting in physical environments must satisfy safety constraints throughout their learning and execution phases, rendering transient violations during adaptation unacceptable. Although continual RL and safe RL have each addressed non-stationarity and safety, respectively, their intersection remains comparatively unexplored, motivating the study of safe continual RL algorithms that can adapt over the system's lifetime while preserving safety. In this work, we systematically investigate safe continual reinforcement learning by introducing three benchmark environments that capture safety-critical continual adaptation and by evaluating representative approaches from safe RL, continual RL, and their combinations. Our empirical results reveal a fundamental tension between maintaining safety constraints and preventing catastrophic forgetting under non-stationary dynamics, with existing methods generally failing to achieve both objectives simultaneously. To address this shortcoming, we examine regularization-based strategies that partially mitigate this trade-off and characterize their benefits and limitations. Finally, we outline key open challenges and research directions toward developing safe, resilient learning-based controllers capable of sustained autonomous operation in changing environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces three new benchmark environments designed to capture safety-critical continual adaptation under non-stationary dynamics. It evaluates representative algorithms from safe RL, continual RL, and their combinations, empirically demonstrating a fundamental tension between satisfying safety constraints and mitigating catastrophic forgetting. Regularization-based strategies are examined as a partial mitigation, with benefits and limitations characterized, and key open challenges for future work are outlined.
Significance. If the reported tension holds under representative conditions, the work highlights an important and underexplored intersection between safety and continual learning in RL, with direct implications for deploying learning-based controllers in changing physical environments. The new benchmarks and the systematic comparison of existing approaches provide a useful starting point for the community, and the partial success of regularization offers concrete directions, though the strength of these contributions depends on the fidelity of the test environments.
major comments (2)
- The central empirical claim of a fundamental tension rests on results from the three introduced benchmark environments. The manuscript should provide explicit details on how non-stationarity is instantiated (e.g., specific parameter jumps or regime changes, their timing, and persistence) and how safety constraints are enforced (hard vs. soft, violation detection during adaptation phases). Without these modeling choices being load-bearing and clearly justified, the generality of the observed failures of existing methods and the partial benefits of regularization cannot be fully assessed.
- In the experimental sections reporting performance across the benchmarks, the paper should include statistical rigor such as the number of independent runs, error bars or confidence intervals, and any hypothesis testing used to support statements that existing methods 'generally fail' to achieve both objectives simultaneously.
minor comments (2)
- The abstract could briefly name or characterize the three benchmark environments to give readers immediate context for the empirical claims.
- Notation for safety constraints and forgetting metrics should be introduced consistently when first used in the evaluation sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve the clarity and rigor of our empirical evaluation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central empirical claim of a fundamental tension rests on results from the three introduced benchmark environments. The manuscript should provide explicit details on how non-stationarity is instantiated (e.g., specific parameter jumps or regime changes, their timing, and persistence) and how safety constraints are enforced (hard vs. soft, violation detection during adaptation phases). Without these modeling choices being load-bearing and clearly justified, the generality of the observed failures of existing methods and the partial benefits of regularization cannot be fully assessed.
Authors: We agree that greater explicitness on these modeling choices will strengthen the paper. In the revised version, we will expand the 'Benchmark Environments' section with a dedicated subsection that specifies the exact parameter values before and after each change, the precise timing and duration of each regime shift, and whether constraints are enforced as hard barriers (with immediate termination on violation) or soft penalties (with continued training). We will also detail the violation detection mechanism used during both training and evaluation phases. These additions will make the design choices load-bearing and easier for readers to evaluate. revision: yes
-
Referee: In the experimental sections reporting performance across the benchmarks, the paper should include statistical rigor such as the number of independent runs, error bars or confidence intervals, and any hypothesis testing used to support statements that existing methods 'generally fail' to achieve both objectives simultaneously.
Authors: We appreciate the emphasis on statistical standards. All reported results were obtained from 10 independent random seeds per algorithm-environment combination. In the revision we will add error bars (standard deviation) to every performance plot and include a table summarizing mean and standard deviation for the key metrics. While our original claims were based on consistent qualitative trends across environments rather than formal hypothesis tests, we will add a brief discussion of this limitation and, where appropriate, include two-sample t-test p-values to support the statement that existing methods generally fail to satisfy both safety and continual-learning objectives simultaneously. revision: partial
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The paper is an empirical study that introduces three benchmark environments and reports experimental results from evaluating safe RL, continual RL, and combined methods. No mathematical derivations, predictions, or first-principles results are claimed that could reduce to fitted parameters or self-citations by construction. All outcomes derive directly from experimentation on the defined benchmarks, making the work self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hwangbo, J
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V. Tsounis, V. Koltun, M. Hutter, Learning agile and dynamic motor skills for legged robots, Science Robotics 4 (26) (2019) eaau5872
2019
-
[2]
B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, P. Pérez, Deep rein- forcement learning for autonomous driving: A survey, IEEE transactions on intelligent transportation systems 23 (6) (2021) 4909–4926
2021
-
[3]
Y. Song, A. Romero, M. Müller, V. Koltun, D. Scaramuzza, Reaching the limit in autonomous racing: Optimal control versus reinforcement learning, Science Robotics 8 (82) (2023) eadg1462
2023
-
[4]
T. Kim, M. Jang, J. Kim, A survey on simulation environments for reinforcement learning, in: 2021 18th International Conference on Ubiquitous Robots (UR), IEEE, 2021, pp. 63–67. 19
2021
-
[5]
A. Xie, J. Harrison, C. Finn, Deep reinforcement learning amidst continual structured non-stationarity, in: International Conference on Machine Learning, PMLR, 2021, pp. 11393–11403
2021
-
[6]
S. Gu, L. Yang, Y. Du, G. Chen, F. Walter, J. Wang, A. Knoll, A review of safe reinforcement learning: Methods, theories and applications, IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[7]
Khetarpal, M
K. Khetarpal, M. Riemer, I. Rish, D. Precup, Towards continual reinforcement learning: A review and perspectives, Journal of Artificial Intelligence Research 75 (2022) 1401–1476
2022
-
[8]
Kemker, M
R. Kemker, M. McClure, A. Abitino, T. Hayes, C. Kanan, Measuring catastrophic forgetting in neural networks, in: Proceedings of the AAAI conference on artificial intelligence, Vol. 32, 2018
2018
-
[9]
L.Brunke, M.Greeff, A.W.Hall, Z.Yuan, S.Zhou, J.Panerati, A.P.Schoellig, Safelearninginrobotics: From learning-based control to safe reinforcement learning, Annual Review of Control, Robotics, and Autonomous Systems 5 (1) (2022) 411–444
2022
-
[10]
Bar-Kana, H
I. Bar-Kana, H. Kaufman, Simple adaptive control of uncertain systems, International Journal of Adap- tive Control and Signal Processing 2 (2) (1988) 133–143
1988
-
[11]
Z. T. Dydek, A. M. Annaswamy, E. Lavretsky, Adaptive control of quadrotor uavs: A design trade study with flight evaluations, IEEE Transactions on control systems technology 21 (4) (2012) 1400–1406
2012
-
[12]
Xiong, G
J. Xiong, G. Zhang, Adaptive control of deposited height in gmaw-based layer additive manufacturing, Journal of Materials Processing Technology 214 (4) (2014) 962–968
2014
-
[13]
N. T. Nguyen, Model-reference adaptive control, in: Model-Reference Adaptive Control: A Primer, Springer, 2018, pp. 83–123
2018
-
[14]
Z. Hou, S. Jin, Model free adaptive control, CRC press Boca Raton, FL, USA, 2013
2013
-
[15]
Z. Hou, S. Jin, Data-driven model-free adaptive control for a class of mimo nonlinear discrete-time systems, IEEE transactions on neural networks 22 (12) (2011) 2173–2188
2011
-
[16]
D.Xu, B.Jiang, P.Shi, Anovelmodel-freeadaptivecontroldesignformultivariableindustrialprocesses, IEEE Transactions on Industrial Electronics 61 (11) (2014) 6391–6398
2014
-
[17]
S. Zhao, X. Wang, D. Zhang, L. Shen, Model-free fuzzy adaptive control of the heading angle of fixed- wing unmanned aerial vehicles, Journal of Aerospace Engineering 30 (4) (2017) 04017019
2017
-
[18]
Ma, W.-W
Y.-S. Ma, W.-W. Che, C. Deng, Dynamic event-triggered model-free adaptive control for nonlinear cpss under aperiodic dos attacks, Information Sciences 589 (2022) 790–801
2022
-
[19]
Plasticity Loss in Deep Reinforcement Learning: A Survey
T. Klein, L. Miklautz, K. Sidak, C. Plant, S. Tschiatschek, Plasticity loss in deep reinforcement learning: A survey, arXiv preprint arXiv:2411.04832 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Abbas, R
Z. Abbas, R. Zhao, J. Modayil, A. White, M. C. Machado, Loss of plasticity in continual deep rein- forcement learning, in: Conference on lifelong learning agents, PMLR, 2023, pp. 620–636
2023
-
[21]
Nikishin, J
E. Nikishin, J. Oh, G. Ostrovski, C. Lyle, R. Pascanu, W. Dabney, A. Barreto, Deep reinforcement learning with plasticity injection, Advances in Neural Information Processing Systems 36 (2023) 37142– 37159
2023
-
[22]
Juliani, J
A. Juliani, J. Ash, A study of plasticity loss in on-policy deep reinforcement learning, Advances in Neural Information Processing Systems 37 (2025) 113884–113910
2025
-
[23]
Kaplanis, M
C. Kaplanis, M. Shanahan, C. Clopath, Continual reinforcement learning with complex synapses, in: International Conference on Machine Learning, PMLR, 2018, pp. 2497–2506. 20
2018
-
[24]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al., Overcoming catastrophic forgetting in neural networks, Proceedings of the national academy of sciences 114 (13) (2017) 3521–3526
2017
-
[25]
Schwarz, W
J. Schwarz, W. Czarnecki, J. Luketina, A. Grabska-Barwinska, Y. W. Teh, R. Pascanu, R. Hadsell, Progress & compress: A scalable framework for continual learning, in: International conference on machine learning, PMLR, 2018, pp. 4528–4537
2018
-
[26]
Rolnick, A
D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, G. Wayne, Experience replay for continual learning, Advances in neural information processing systems 32 (2019)
2019
-
[27]
Pathmanathan, N
P. Pathmanathan, N. Díaz-Rodríguez, J. Del Ser, Using curiosity for an even representation of tasks in continual offline reinforcement learning, Cognitive Computation 16 (1) (2024) 425–453
2024
-
[28]
C. Li, Y. Li, Y. Zhao, P. Peng, X. Geng, Sler: Self-generated long-term experience replay for continual reinforcement learning, Applied Intelligence 51 (1) (2021) 185–201
2021
-
[29]
Kessler, J
S. Kessler, J. Parker-Holder, P. Ball, S. Zohren, S. J. Roberts, Unclear: A straightforward method for continual reinforcement learning, in: Proceedings of the 37th International Conference on Machine Learning, 2020
2020
-
[30]
Zhang, Z
T. Zhang, Z. Lin, Y. Wang, D. Ye, Q. Fu, W. Yang, X. Wang, B. Liang, B. Yuan, X. Li, Dynamics- adaptive continual reinforcement learning via progressive contextualization, IEEE Transactions on Neu- ral Networks and Learning Systems (2023)
2023
-
[31]
M. Xu, W. Ding, J. Zhu, Z. Liu, B. Chen, D. Zhao, Task-agnostic online reinforcement learning with an infinite mixture of gaussian processes, Advances in Neural Information Processing Systems 33 (2020) 6429–6440
2020
-
[32]
T. Xu, Y. Liang, G. Lan, Crpo: A new approach for safe reinforcement learning with convergence guarantee, in: International Conference on Machine Learning, PMLR, 2021, pp. 11480–11491
2021
-
[33]
Z. Liu, Z. Cen, V. Isenbaev, W. Liu, S. Wu, B. Li, D. Zhao, Constrained variational policy optimization for safe reinforcement learning, in: International Conference on Machine Learning, PMLR, 2022, pp. 13644–13668
2022
-
[34]
Zhang, R
L. Zhang, R. Zhang, T. Wu, R. Weng, M. Han, Y. Zhao, Safe reinforcement learning with stability guarantee for motion planning of autonomous vehicles, IEEE transactions on neural networks and learning systems 32 (12) (2021) 5435–5444
2021
-
[35]
Y. Emam, G. Notomista, P. Glotfelter, Z. Kira, M. Egerstedt, Safe reinforcement learning using robust control barrier functions, IEEE Robotics and Automation Letters (2022)
2022
-
[36]
K. Srinivasan, B. Eysenbach, S. Ha, J. Tan, C. Finn, Learning to be safe: Deep rl with a safety critic, arXiv preprint arXiv:2010.14603 (2020)
-
[37]
Lütjens, M
B. Lütjens, M. Everett, J. P. How, Safe reinforcement learning with model uncertainty estimates, in: 2019 International Conference on Robotics and Automation (ICRA), IEEE, 2019, pp. 8662–8668
2019
-
[38]
Selim, A
M. Selim, A. Alanwar, S. Kousik, G. Gao, M. Pavone, K. H. Johansson, Safe reinforcement learning using black-box reachability analysis, IEEE Robotics and Automation Letters 7 (4) (2022) 10665–10672
2022
-
[39]
Chandak, S
Y. Chandak, S. Jordan, G. Theocharous, M. White, P. S. Thomas, Towards safe policy improvement for non-stationary mdps, Advances in Neural Information Processing Systems 33 (2020) 9156–9168
2020
-
[40]
B. Chen, Z. Liu, J. Zhu, M. Xu, W. Ding, L. Li, D. Zhao, Context-aware safe reinforcement learning for non-stationary environments, in: 2021 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2021, pp. 10689–10695. 21
2021
-
[41]
Y. Ding, J. Lavaei, Provably efficient primal-dual reinforcement learning for cmdps with non-stationary objectives and constraints, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37, 2023, pp. 7396–7404
2023
-
[42]
M. Cho, C. Sun, Constrained meta-reinforcement learning for adaptable safety guarantee with differen- tiable convex programming, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, 2024, pp. 20975–20983
2024
-
[43]
Zhang, C
Q. Zhang, C. Wu, H. Tian, Y. Gao, W. Yao, L. Wu, Safety reinforcement learning control via transfer learning, Automatica 166 (2024) 111714
2024
-
[44]
Y. Wang, M. Xiao, Z. Wu, Safe transfer-reinforcement-learning-based optimal control of nonlinear systems, IEEE Transactions on Cybernetics 54 (12) (2024) 7272–7284
2024
-
[45]
H.B.Ammar, R.Tutunov, E.Eaton, Safepolicysearchforlifelongreinforcementlearningwithsublinear regret, in: F. Bach, D. Blei (Eds.), Proceedings of the 32nd International Conference on Machine Learning, Vol. 37 of Proceedings of Machine Learning Research, PMLR, Lille, France, 2015, pp. 2361– 2369. URLhttps://proceedings.mlr.press/v37/ammar15.html
2015
-
[46]
Ganie, S
I. Ganie, S. Jagannathan, Online continual safe reinforcement learning-based optimal control of mobile robot formations, in: 2024 IEEE Conference on Control Technology and Applications (CCTA), 2024, pp. 519–524
2024
-
[47]
A. Coursey, M. Quinones-Grueiro, G. Biswas, On the design of safe continual rl methods for control of nonlinear systems (2025).arXiv:2502.15922. URLhttps://arxiv.org/abs/2502.15922
-
[48]
Altman, Constrained Markov Decision Processes, Chapman and Hall/CRC, 1999
E. Altman, Constrained Markov Decision Processes, Chapman and Hall/CRC, 1999
1999
-
[49]
D. Abel, A. Barreto, B. Van Roy, D. Precup, H. P. van Hasselt, S. Singh, A definition of continual reinforcement learning, Advances in Neural Information Processing Systems 36 (2023) 50377–50407
2023
-
[50]
Lecarpentier, E
E. Lecarpentier, E. Rachelson, Non-stationary markov decision processes, a worst-case approach using model-based reinforcement learning, in: H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, R. Garnett (Eds.), Advances in Neural Information Processing Systems 32: Annual Confer- ence on Neural Information Processing Systems 2019, Neu...
2019
-
[51]
J. Ji, B. Zhang, J. Zhou, X. Pan, W. Huang, R. Sun, Y. Geng, Y. Zhong, J. Dai, Y. Yang, Safety gymnasium: A unified safe reinforcement learning benchmark, in: Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URLhttps://openreview.net/forum?id=WZmlxIuIGR
2023
-
[52]
A. Xie, J. Harrison, C. Finn, Deep reinforcement learning amidst continual structured non-stationarity, in: M. Meila, T. Zhang (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Vol. 139 of Proceedings of Machine Learning Research, PMLR, 2021, pp. 11393–11403. URLhttp://proceedings.mlr....
2021
-
[53]
Lee, S.-W
S.-H. Lee, S.-W. Seo, Unsupervised skill discovery for learning shared structures across changing envi- ronments, in: A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, J. Scarlett (Eds.), Proceedings of the 40th International Conference on Machine Learning, Vol. 202 of Proceedings of Machine Learning Research, PMLR, 2023, pp. 19185–19199. URLhttp...
2023
-
[54]
Wołczyk, M
M. Wołczyk, M. Zając, R. Pascanu, Ł. Kuciński, P. Miłoś, Continual world: A robotic benchmark for continual reinforcement learning, Advances in Neural Information Processing Systems 34 (2021) 28496–28510
2021
-
[55]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, S. Levine, Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning, in: Conference on robot learning, PMLR, 2020, pp. 1094–1100
2020
-
[56]
H.Ahn, J.Hyeon, Y.Oh, B.Hwang, T.Moon, Prevalenceofnegativetransferincontinualreinforcement learning: Analyses and a simple baseline, in: The Thirteenth International Conference on Learning Representations, 2025
2025
-
[57]
S. Nath, C. Peridis, E. Ben-Iwhiwhu, X. Liu, S. Dora, C. Liu, S. Kolouri, A. Soltoggio, Sharing life- long reinforcement learning knowledge via modulating masks, in: S. Chandar, R. Pascanu, H. Sedghi, D. Precup (Eds.), Proceedings of The 2nd Conference on Lifelong Learning Agents, Vol. 232 of Pro- ceedings of Machine Learning Research, PMLR, 2023, pp. 936...
2023
-
[58]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal policy optimization algorithms, arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[59]
Schulman, S
J. Schulman, S. Levine, P. Abbeel, M. Jordan, P. Moritz, Trust region policy optimization, in: Inter- national conference on machine learning, PMLR, 2015, pp. 1889–1897
2015
-
[60]
Achiam, D
J. Achiam, D. Held, A. Tamar, P. Abbeel, Constrained policy optimization, in: International conference on machine learning, PMLR, 2017, pp. 22–31
2017
-
[61]
A. Ray, J. Achiam, D. Amodei, Benchmarking safe exploration in deep reinforcement learning, Preprint (2019). URLhttps://cdn.openai.com/safexp-short.pdf
2019
-
[62]
9133–9143
A.Stooke, J.Achiam, P.Abbeel, Responsivesafetyinreinforcementlearningbypidlagrangianmethods, in: International Conference on Machine Learning, PMLR, 2020, pp. 9133–9143
2020
-
[63]
Bergstra, R
J. Bergstra, R. Bardenet, Y. Bengio, B. Kégl, Algorithms for hyper-parameter optimization, Advances in neural information processing systems 24 (2011)
2011
-
[64]
importance
T. Akiba, S. Sano, T. Yanase, T. Ohta, M. Koyama, Optuna: A next-generation hyperparameter opti- mization framework, in: Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 2623–2631. 23 Appendix A. Appendix Appendix A.1. Additional Methodology Information In this section, we provide additional detai...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.