Recognition: 2 theorem links
· Lean TheoremAvoiding Overthinking and Underthinking: Curriculum-Aware Budget Scheduling for LLMs
Pith reviewed 2026-05-14 21:50 UTC · model grok-4.3
The pith
Conditioning LLM reasoning policies on token budgets and scheduling them by curriculum difficulty improves accuracy under tight compute limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A budget-conditioned unified policy, a curriculum-aware scheduler that redistributes token budgets according to real-time progress, and truncation-aware dense rewards together let an LLM allocate compute proportionally to problem difficulty, yielding higher final accuracy at lower total token cost across MATH, GSM8K, AIME, and Minerva Math.
What carries the argument
Budget-Adaptive Curriculum Reasoning framework whose core mechanism is a single policy that receives the token budget as a continuous conditioning input and whose training distribution is shifted by a scheduler that tracks learning progress on easy versus hard items.
If this is right
- Accuracy gains appear largest under the tightest token budgets tested.
- Average token consumption drops 34 percent while accuracy still rises.
- The same policy works across the full range of tested budgets without separate thinking or summarization heads.
- Budget-conditioned advantage estimation reduces gradient variance relative to standard baselines.
Where Pith is reading between the lines
- The same conditioning-plus-curriculum pattern could be tested on code-generation or multi-hop QA tasks where difficulty also varies widely.
- Deployment systems might adopt the trained policy to choose per-query budgets on the fly rather than using a fixed global limit.
- If the scheduler generalizes, it could reduce the energy cost of serving many reasoning queries by lowering the long-tail token usage.
- The interaction between curriculum ordering and model scale remains open and could be measured by repeating the experiments at different parameter counts.
Load-bearing premise
The scheduler can accurately sense real-time learning progress and reallocate budgets from easy to hard problems without destabilizing policy updates or introducing bias.
What would settle it
Replacing the curriculum scheduler with uniform or random budget sampling across the same training problems and observing whether the accuracy and token-efficiency gains disappear.
Figures



read the original abstract
Scaling test-time compute via extended reasoning has become a key paradigm for improving the capabilities of large language models (LLMs). However, existing approaches optimize reasoning under fixed or uniformly sampled token budgets, ignoring the fundamental mismatch between problem difficulty and allocated compute. This leads to overthinking on easy problems and underthinking on hard ones, resulting in suboptimal token efficiency across diverse reasoning scenarios. In this paper, we propose Budget-Adaptive Curriculum Reasoning (BCAE), a unified framework that jointly optimizes reasoning quality and token efficiency through three synergistic components: (1) a \emph{budget-conditioned unified policy} that embeds the token budget as a continuous conditioning signal, eliminating the need for decoupled thinking and summarization strategies; (2) a \emph{curriculum-aware budget scheduler} that adaptively shifts the training budget distribution from easy to hard problems based on real-time learning progress; and (3) a \emph{truncation-aware dense reward} mechanism that provides fine-grained credit assignment at intermediate reasoning steps via process-level verification. We further introduce \emph{Budget-Conditioned Advantage Estimation} (BCAE), a novel variance reduction technique that conditions the advantage baseline on the sampled budget, yielding more stable policy gradients. Experiments on mathematical reasoning benchmarks (MATH, GSM8K, AIME, and Minerva Math) demonstrate that BACR consistently outperforms other strong baselines across all token budgets, achieving up to 8.3\% accuracy improvement under tight budgets while reducing average token consumption by 34\% compared to unconstrained reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Budget-Adaptive Curriculum Reasoning (BACR/BCAE), a framework that jointly optimizes LLM reasoning quality and token efficiency via three components: a budget-conditioned unified policy that treats token budget as a continuous conditioning signal, a curriculum-aware budget scheduler that shifts budget distribution from easy to hard problems based on real-time progress, and a truncation-aware dense reward for process-level credit assignment. It also introduces Budget-Conditioned Advantage Estimation for variance reduction in policy gradients. Experiments on MATH, GSM8K, AIME, and Minerva Math claim consistent outperformance over baselines across token budgets, with up to 8.3% accuracy gains under tight budgets and 34% average token reduction versus unconstrained reasoning.
Significance. If the results hold under rigorous controls, the work would meaningfully advance test-time compute scaling for LLMs by addressing the mismatch between problem difficulty and allocated budget, offering a practical route to higher token efficiency without sacrificing accuracy on reasoning tasks.
major comments (1)
- [§3.2] §3.2: The curriculum-aware budget scheduler computes its progress signal (moving-average accuracy threshold on a held-out difficulty-stratified batch) from the same policy under training. This creates a potential feedback loop in which early accuracy dominated by easy problems can trigger premature budget reallocation to hard items before intermediate reasoning steps are acquired, directly risking the overthinking/underthinking the method claims to avoid. No ablation isolates the scheduler from the policy and reward components or tests stability under noisy early signals.
minor comments (2)
- [Abstract] Abstract: Acronym inconsistency—Budget-Adaptive Curriculum Reasoning is introduced as BCAE but subsequently referred to as BACR; standardize throughout.
- [Abstract] Abstract: Specific performance numbers (8.3% accuracy, 34% token reduction) are reported without reference to baseline implementations, statistical significance tests, or controls for post-hoc budget sampling choices; these details belong in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The concern about potential feedback loops in the curriculum-aware budget scheduler is well-taken, and we address it directly below while committing to additional experiments in the revision.
read point-by-point responses
-
Referee: [§3.2] §3.2: The curriculum-aware budget scheduler computes its progress signal (moving-average accuracy threshold on a held-out difficulty-stratified batch) from the same policy under training. This creates a potential feedback loop in which early accuracy dominated by easy problems can trigger premature budget reallocation to hard items before intermediate reasoning steps are acquired, directly risking the overthinking/underthinking the method claims to avoid. No ablation isolates the scheduler from the policy and reward components or tests stability under noisy early signals.
Authors: We appreciate this observation on the scheduler's design. The progress signal is deliberately computed on a held-out, difficulty-stratified batch (distinct from the training trajectories) and smoothed via a moving average precisely to reduce sensitivity to early noisy estimates dominated by easy problems. This separation, combined with the budget-conditioned policy's gradual adaptation, is intended to prevent premature reallocation. That said, we agree that an explicit isolation of the scheduler and targeted stability tests would strengthen the claims. In the revised manuscript we will add a new ablation section that (i) replaces the online scheduler with a fixed or oracle progress estimator and (ii) injects controlled noise into early accuracy signals to measure robustness. These results will be reported alongside the existing experiments on MATH, GSM8K, AIME, and Minerva Math. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces an empirical framework (BCAE/BACR) with three new components—a budget-conditioned policy, curriculum-aware scheduler using moving-average accuracy on held-out batches, and truncation-aware dense reward—plus Budget-Conditioned Advantage Estimation. No equations, predictions, or first-principles results are shown to reduce by construction to fitted parameters or self-defined quantities. Claims rest on external benchmark validation (MATH, GSM8K, etc.) rather than internal redefinition. The scheduler's use of the training policy for progress detection is a design choice open to stability concerns but does not create a self-referential loop that forces the reported accuracy or token reductions. No self-citation load-bearing, ansatz smuggling, or renaming of known results appears in the provided text.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Budget-Conditioned Advantage Estimation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
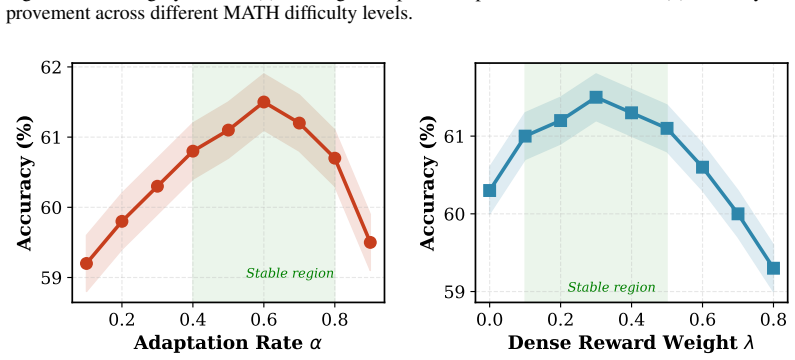
curriculum-aware budget scheduler that adaptively shifts the training budget distribution from easy to hard problems based on real-time learning progress... μ_k(e) = μ_k(0)·(1−α·ρ_k(e)) + β·(1−ρ_k(e))·b_max
-
IndisputableMonolith/Foundation/AlphaCoordinateFixationalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Budget-Conditioned Advantage Estimation (BCAE)... V_ψ(q, b) = MLP_ψ(h_q ⊕ ϕ(b))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.09567 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.