Recognition: 1 theorem link
· Lean TheoremHumorRank: A Tournament-Based Leaderboard for Evaluating Humor Generation in Large Language Models
Pith reviewed 2026-05-13 23:01 UTC · model grok-4.3
The pith
HumorRank ranks language models on humor generation through automated joke tournaments that reveal skill in comedic mechanisms over model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HumorRank is a tournament-based evaluation framework and leaderboard that performs automated pairwise comparisons of LLM-generated humor using judgments grounded in the General Theory of Verbal Humor, aggregates those results via an Adaptive Swiss tournament, and derives globally consistent rankings through Bradley-Terry Maximum Likelihood Estimation, yielding statistically grounded model stratifications that show humor quality depends on mastery of comedic mechanisms rather than model scale.
What carries the argument
HumorRank tournament system that converts GTVH-grounded pairwise judgments into global rankings through Adaptive Swiss scheduling and Bradley-Terry MLE.
Load-bearing premise
Automated pairwise judgments based on the General Theory of Verbal Humor accurately capture true humor quality without systematic bias.
What would settle it
A direct comparison study in which human raters evaluate the same model outputs and produce model rankings that differ substantially from those generated by HumorRank.
Figures




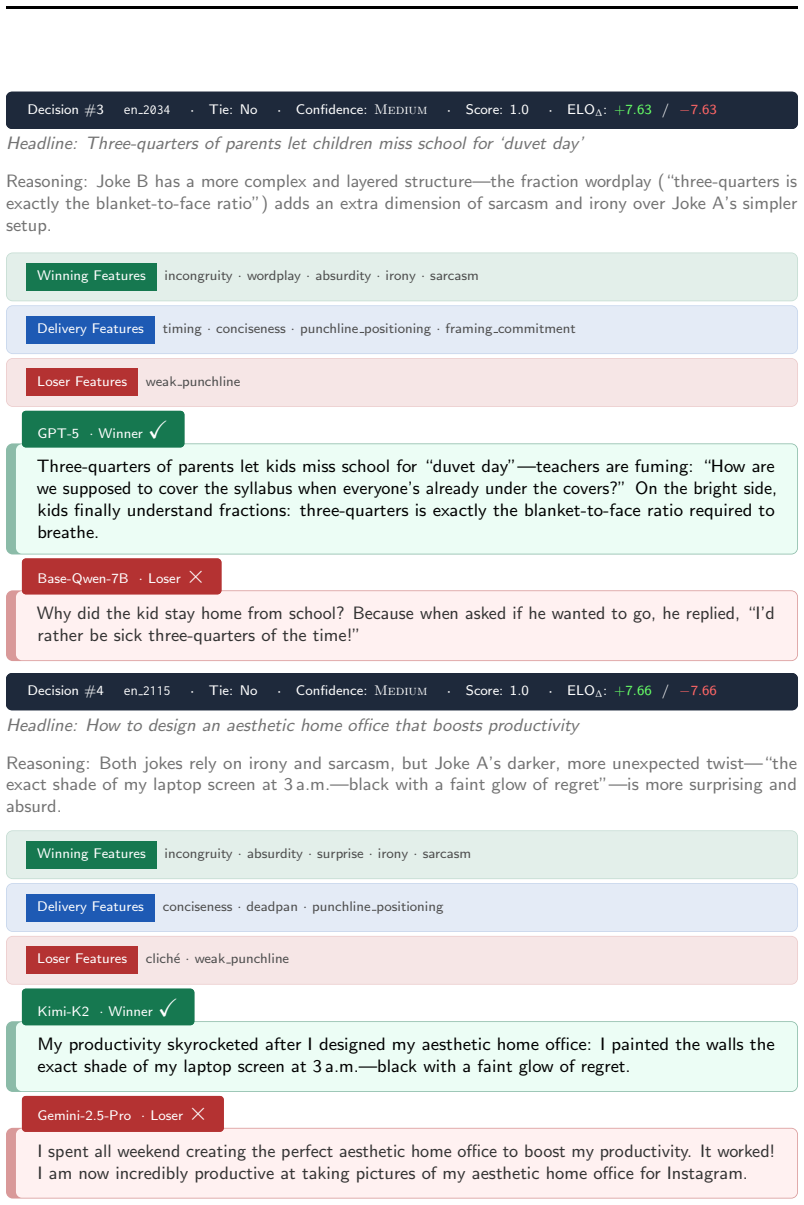





read the original abstract
Evaluating humor in large language models (LLMs) is an open challenge because existing approaches yield isolated, incomparable metrics rather than unified model rankings, making it difficult to track progress across systems. We introduce HumorRank, a tournament-based evaluation framework and leaderboard for textual humor generation. Using SemEval-2026 MWAHAHA test dataset, we conduct an extensive automated pairwise evaluation across nine models spanning proprietary, open-weight, and specialized systems. Pairwise judgments grounded in the General Theory of Verbal Humor (GTVH) are aggregated via an Adaptive Swiss tournament, with Bradley-Terry Maximum Likelihood Estimation (MLE) producing globally consistent humor generation capability rankings. Our results demonstrate that HumorRank yields statistically grounded model stratifications, showing that humor quality is driven by mastery of comedic mechanisms rather than model scale alone. HumorRank thus provides a scalable, interpretable methodology for benchmarking and understanding LLM-generated humor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HumorRank, a tournament-based evaluation framework and leaderboard for textual humor generation in LLMs. Using the SemEval-2026 MWAHAHA test dataset, it conducts automated pairwise judgments grounded in the General Theory of Verbal Humor (GTVH) across nine models, aggregates outcomes via an Adaptive Swiss tournament, and applies Bradley-Terry MLE to produce globally consistent rankings. The central claim is that these rankings yield statistically grounded stratifications demonstrating that humor quality is driven by mastery of comedic mechanisms rather than model scale alone.
Significance. If the automated judgments prove reliable, HumorRank would provide a valuable, scalable methodology for unified benchmarking of LLM humor generation, replacing isolated incomparable metrics with interpretable global rankings. The GTVH grounding and Bradley-Terry aggregation offer a theoretically motivated and reproducible approach that could help track progress and identify key drivers of humor capability.
major comments (2)
- [Evaluation pipeline] Evaluation pipeline (abstract and methods): The automated GTVH-based pairwise judgments lack any reported human validation, inter-annotator agreement metrics, or bias audit. This is load-bearing for the headline claim that the stratifications show mechanism mastery (not scale) drives humor quality, as systematic bias in the LLM judge correlated with model family or size could artifactually produce the observed inversion.
- [Results section] Results section: No statistical significance tests for the scale-vs-mechanism finding, confidence intervals on the Bradley-Terry parameters, or sensitivity analysis to Adaptive Swiss tournament parameters are reported, leaving the assertion of 'statistically grounded model stratifications' under-supported.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important areas for strengthening the manuscript. We address each major point below and commit to revisions that enhance the rigor and transparency of our evaluation framework.
read point-by-point responses
-
Referee: Evaluation pipeline (abstract and methods): The automated GTVH-based pairwise judgments lack any reported human validation, inter-annotator agreement metrics, or bias audit. This is load-bearing for the headline claim that the stratifications show mechanism mastery (not scale) drives humor quality, as systematic bias in the LLM judge correlated with model family or size could artifactually produce the observed inversion.
Authors: We agree that human validation is essential to substantiate the reliability of the automated GTVH judgments and rule out potential biases. In the revised manuscript, we will add a dedicated validation subsection reporting results from a human study on a stratified sample of 300 pairwise comparisons. This will include inter-annotator agreement metrics (Cohen's kappa and Fleiss' kappa), a bias audit examining correlations between judgment errors and model family/size, and qualitative analysis of disagreement cases. These additions will directly support the claim that observed stratifications reflect genuine differences in comedic mechanism mastery rather than judge artifacts. revision: yes
-
Referee: Results section: No statistical significance tests for the scale-vs-mechanism finding, confidence intervals on the Bradley-Terry parameters, or sensitivity analysis to Adaptive Swiss tournament parameters are reported, leaving the assertion of 'statistically grounded model stratifications' under-supported.
Authors: We acknowledge that the current results section would be strengthened by explicit statistical support. In the revision, we will expand the results to include: bootstrap 95% confidence intervals on all Bradley-Terry parameters; statistical significance tests (Mann-Whitney U and permutation tests) comparing the mechanism-mastery group against scale-based groupings; and sensitivity analyses varying Adaptive Swiss parameters (e.g., round count from 4-12 and reporting Kendall tau rank stability across configurations). These will be presented with tables and figures to rigorously ground the reported stratifications. revision: yes
Circularity Check
No circularity: HumorRank rankings derive from external GTVH judgments aggregated by standard MLE without self-referential reduction
full rationale
The paper's derivation chain consists of (1) applying the external General Theory of Verbal Humor to generate automated pairwise judgments on the SemEval-2026 dataset, followed by (2) aggregation via Adaptive Swiss tournament and Bradley-Terry MLE to produce global rankings. No equations, self-citations, or ansatzes reduce the final stratifications or the claim that mechanism mastery (not scale) drives quality to the inputs by construction. The MLE step is a standard statistical aggregation of independent judgment data; GTVH supplies an external theoretical basis rather than a self-defined loop. Absence of human validation is a correctness risk but does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bradley-Terry strength parameters
axioms (1)
- domain assumption General Theory of Verbal Humor provides valid, automatable criteria for judging relative humor quality
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pairwise judgments grounded in the General Theory of Verbal Humor (GTVH) are aggregated via an Adaptive Swiss tournament, with Bradley-Terry Maximum Likelihood Estimation (MLE) producing globally consistent humor generation capability rankings.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Edward Ajayi and Prasenjit Mitra. Humorgen: Cognitive synergy for humor generation in large language models via persona-based distillation. https://huggingface.co/Jayi2424/HumorGen-7B, 2025 a . Preprint
work page 2025
-
[4]
Edward Ajayi and Prasenjit Mitra. Automatic humor detection: A comprehensive survey from theoretical foundations to large language models. December 2025 b . doi:10.13140/RG.2.2.24393.61288. URL https://doi.org/10.13140/RG.2.2.24393.61288. Preprint
-
[5]
Elo-rating as a tool in the sequential estimation of dominance strengths
Paul CH Albers and Han de Vries. Elo-rating as a tool in the sequential estimation of dominance strengths. Animal behaviour, pp.\ 489--495, 2001
work page 2001
-
[6]
The claude 3 model family: Opus, sonnet, haiku
Anthropic . The claude 3 model family: Opus, sonnet, haiku. https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf, 2024. Model card
work page 2024
-
[7]
The general theory of verbal humor
Salvatore Attardo. The general theory of verbal humor. In The Routledge handbook of language and humor, pp.\ 126--142. Routledge, 2017
work page 2017
-
[8]
Linguistic theories of humor, volume 1
Salvatore Attardo. Linguistic theories of humor, volume 1. Walter de Gruyter GmbH & Co KG, 2024
work page 2024
-
[9]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39 0 (3/4): 0 324--345, 1952
work page 1952
-
[11]
Santiago Castro, Luis Chiruzzo, Santiago G \'o ngora, Salar Rahili, Naihao Deng, Ignacio Sastre, Victoria Amoroso, Guillermo Rey, Aiala Ros \'a , Guillermo Moncecchi, J. A. Meaney, Juan Jos \'e Prada, and Rada Mihalcea. SemEval-2026 Task 1: MWAHAHA, Models Write Automatic Humor And Humans Annotate . In Proceedings of the 20th International Workshop on Sem...
work page 2026
-
[12]
Chatbot arena: An open platform for evaluating llms by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[13]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Improving llm leaderboards with psychometrical methodology
Denis Federiakin. Improving llm leaderboards with psychometrical methodology. arXiv preprint arXiv:2501.17200, 2025
-
[15]
Automating humor: A novel approach to joke generation using template extraction and infilling
Mayank Goel, Parameswari Krishnamurthy, and Radhika Mamidi. Automating humor: A novel approach to joke generation using template extraction and infilling. In Proceedings of the 21st International Conference on Natural Language Processing (ICON), pp.\ 442--448, 2024
work page 2024
-
[16]
Crowd score: A method for the evaluation of jokes using large language model ai voters as judges
Fabricio Goes, Zisen Zhou, Piotr Sawicki, Marek Grzes, and Daniel G Brown. Crowd score: A method for the evaluation of jokes using large language model ai voters as judges. arXiv preprint arXiv:2212.11214, 2022
-
[17]
How funny is chatgpt? a comparison of human-and ai-produced jokes
Drew Gorenz and Norbert Schwarz. How funny is chatgpt? a comparison of human-and ai-produced jokes. Plos one, 19 0 (7): 0 e0305364, 2024
work page 2024
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Chumor 2.0: Towards benchmarking chinese humor understanding
Ruiqi He, Yushu He, Longju Bai, Jiarui Liu, Zhenjie Sun, Zenghao Tang, He Wang, Hanchen Xia, Rada Mihalcea, and Naihao Deng. Chumor 2.0: Towards benchmarking chinese humor understanding. arXiv preprint arXiv:2412.17729, 2024
-
[20]
Getting serious about humor: Crafting humor datasets with unfunny large language models
Zachary Horvitz, Jingru Chen, Rahul Aditya, Harshvardhan Srivastava, Robert West, Zhou Yu, and Kathleen McKeown. Getting serious about humor: Crafting humor datasets with unfunny large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 855--869, 2024
work page 2024
-
[21]
Semeval-2020 task 7: Assessing humor in edited news headlines
Nabil Hossain, John Krumm, Michael Gamon, and Henry Kautz. Semeval-2020 task 7: Assessing humor in edited news headlines. In Proceedings of the fourteenth workshop on semantic evaluation, pp.\ 746--758, 2020
work page 2020
-
[22]
Is ai fun? humordb: a curated dataset and benchmark to investigate graphical humor
Veedant Jain, Felipe dos Santos Alves Feitosa, and Gabriel Kreiman. Is ai fun? humordb: a curated dataset and benchmark to investigate graphical humor. arXiv preprint arXiv:2406.13564, 2024
-
[23]
Ai humor generation: Cognitive, social and creative skills for effective humor
Sean Kim and Lydia B Chilton. Ai humor generation: Cognitive, social and creative skills for effective humor. arXiv preprint arXiv:2502.07981, 2025
-
[24]
Cristina Larkin-Gali \ n anes. An overview of humor theory. The Routledge handbook of language and humor, pp.\ 4--16, 2017
work page 2017
-
[25]
Aidar Myrzakhan, Sondos Mahmoud Bsharat, and Zhiqiang Shen. Open-llm-leaderboard: From multi-choice to open-style questions for llms evaluation, benchmark, and arena. arXiv preprint arXiv:2406.07545, 2024
-
[26]
Which llms get the joke? probing non-stem reasoning abilities with humorbench
Reuben Narad, Siddharth Suresh, Jiayi Chen, Pine SL Dysart-Bricken, Bob Mankoff, Robert Nowak, Jifan Zhang, and Lalit Jain. Which llms get the joke? probing non-stem reasoning abilities with humorbench. arXiv preprint arXiv:2507.21476, 2025
-
[27]
Open ko-llm leaderboard: Evaluating large language models in korean with ko-h5 benchmark
Chanjun Park, Hyeonwoo Kim, Dahyun Kim, Seonghwan Cho, Sanghoon Kim, Sukyung Lee, Yungi Kim, and Hwalsuk Lee. Open ko-llm leaderboard: Evaluating large language models in korean with ko-h5 benchmark. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 3220--3234, 2024
work page 2024
-
[28]
Can ai take a joke—or make one? a study of humor generation and recognition in llms
Kexin Quan, Pavithra Ramakrishnan, and Jessie Chin. Can ai take a joke—or make one? a study of humor generation and recognition in llms. In Proceedings of the 2025 Conference on Creativity and Cognition, pp.\ 431--437, 2025
work page 2025
-
[29]
Small but funny: A feedback-driven approach to humor distillation
Sahithya Ravi, Patrick Huber, Akshat Shrivastava, Vered Shwartz, and Arash Einolghozati. Small but funny: A feedback-driven approach to humor distillation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 13078--13090, 2024
work page 2024
-
[30]
Adrianna Romanowski, Pedro HV Valois, and Kazuhiro Fukui. From punchlines to predictions: A metric to assess llm performance in identifying humor in stand-up comedy. In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, pp.\ 36--46, 2025
work page 2025
-
[31]
Humor in pixels: Benchmarking large multimodal models understanding of online comics
Yuriel Ryan, Rui Yang Tan, Kenny Tsu Wei Choo, and Roy Ka-Wei Lee. Humor in pixels: Benchmarking large multimodal models understanding of online comics. arXiv preprint arXiv:2509.12248, 2025
-
[32]
Not all jokes land: Evaluating large language models understanding of workplace humor
Mohammadamin Shafiei and Hamidreza Saffari. Not all jokes land: Evaluating large language models understanding of workplace humor. arXiv preprint arXiv:2506.01819, 2025
-
[33]
Clarin-pt-ldb: An open llm leaderboard for portuguese to assess language, culture and civility
Jo \ a o Silva, Lu \' s Gomes, and Ant \'o nio Branco. Clarin-pt-ldb: An open llm leaderboard for portuguese to assess language, culture and civility. arXiv preprint arXiv:2603.12872, 2026
-
[34]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Large language models for subjective language understanding: A survey
Changhao Song, Yazhou Zhang, Hui Gao, Ben Yao, and Peng Zhang. Large language models for subjective language understanding: A survey. arXiv preprint arXiv:2508.07959, 2025
-
[36]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https://qwenlm.github.io/blog/qwen2.5/
work page 2024
-
[38]
Understanding llm leaderboards: Metrics, benchmarks, and why they matter, November 2023
Toloka Team . Understanding llm leaderboards: Metrics, benchmarks, and why they matter, November 2023. URL https://toloka.ai/blog/llm-leaderboard/. Accessed: 2026-03-23
work page 2023
- [39]
-
[40]
Han Wang, Yilin Zhao, Dian Li, Xiaohan Wang, Gang Liu, Xuguang Lan, and Hui Wang. Innovative Thinking , Infinite Humor : Humor Research of Large Language Models through Structured Thought Leaps , April 2025. URL http://arxiv.org/abs/2410.10370. arXiv:2410.10370 [cs]
-
[41]
Evaluating humor generation in an improvisational comedy setting
Thomas Winters and Stijn Van der Stockt. Evaluating humor generation in an improvisational comedy setting. Computational Linguistics in the Netherlands Journal, 14: 0 505--523, 2025
work page 2025
-
[42]
Humour classification according to genre and technique by fine-tuning llms
Shih-Hung Wu, Tsz-Yeung Lau, and Yu-Feng Huang. Humour classification according to genre and technique by fine-tuning llms. In International Conference of the Cross-Language Evaluation Forum for European Languages, pp.\ 156--169. Springer, 2025 a
work page 2025
-
[43]
Zhikun Wu, Thomas Weber, and Florian M \"u ller. One does not simply meme alone: Evaluating co-creativity between llms and humans in the generation of humor. In Proceedings of the 30th International Conference on Intelligent User Interfaces, pp.\ 1082--1092, 2025 b
work page 2025
-
[44]
Generic joke generation with moral constraints
Hiroaki Yamane. Generic joke generation with moral constraints. In International Conference on Artificial Neural Networks, pp.\ 340--355. Springer, 2024
work page 2024
-
[45]
Humor in ai: Massive scale crowd-sourced preferences and benchmarks for cartoon captioning
Jifan Zhang, Lalit Jain, Yang Guo, Jiayi Chen, Kuan L Zhou, Siddharth Suresh, Andrew Wagenmaker, Scott Sievert, Timothy Rogers, Kevin Jamieson, et al. Humor in ai: Massive scale crowd-sourced preferences and benchmarks for cartoon captioning. Advances in Neural Information Processing Systems, 37: 0 125264--125286, 2024
work page 2024
-
[46]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36: 0 46595--46623, 2023
work page 2023
-
[47]
Shanshan Zhong, Zhongzhan Huang, Shanghua Gao, Wushao Wen, Liang Lin, Marinka Zitnik, and Pan Zhou. Let's Think Outside the Box : Exploring Leap -of- Thought in Large Language Models with Creative Humor Generation . pp.\ 13246--13257, 2024. URL https://openaccess.thecvf.com/content/CVPR2024/html/Zhong_Lets_Think_Outside_the_Box_Exploring_Leap-of-Thought_i...
work page 2024
-
[48]
Kuan Lok Zhou, Jiayi Chen, Siddharth Suresh, Reuben Narad, Timothy T Rogers, Lalit K Jain, Robert D Nowak, Bob Mankoff, and Jifan Zhang. Bridging the creativity understanding gap: Small-scale human alignment enables expert-level humor ranking in llms. arXiv preprint arXiv:2502.20356, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.