Recognition: 2 theorem links
· Lean TheoremHidden Reliability Risks in Large Language Models: Systematic Identification of Precision-Induced Output Disagreements
Pith reviewed 2026-05-13 21:56 UTC · model grok-4.3
The pith
Precision differences in LLMs cause hidden output disagreements on safety-critical inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
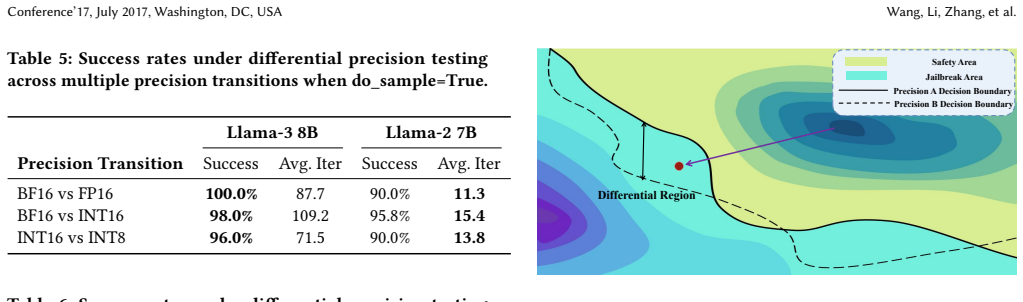
Precision-induced behavioral disagreements arise when the same input yields divergent outputs under different numerical precisions, including cases where jailbreak attempts are blocked in one setting but succeed in another. PrecisionDiff addresses this by automatically creating precision-sensitive test inputs and running cross-precision comparative analysis, revealing that these divergences occur frequently in aligned open-source models and that standard evaluation methods miss most of them.
What carries the argument
PrecisionDiff, an automated differential testing framework that generates precision-sensitive inputs and performs cross-precision output comparison to expose subtle behavioral divergences.
If this is right
- Safety alignment checks must account for precision settings used in deployment to avoid missed vulnerabilities.
- Pre-deployment evaluation of efficient LLMs should incorporate automated cross-precision testing.
- Training pipelines could add precision-robustness objectives to reduce such divergences.
- Quantized models require targeted verification beyond standard accuracy benchmarks.
Where Pith is reading between the lines
- Similar hidden inconsistencies may appear in other numerical computations within AI pipelines, such as in training stability or inference on specialized hardware.
- Edge deployments that rely on aggressive quantization would benefit from routine application of this style of differential testing.
- Addressing these issues could improve the reliability of resource-constrained LLM applications without sacrificing efficiency gains.
Load-bearing premise
The generated test inputs represent real user queries and that observed output differences are caused by precision rather than other implementation details.
What would settle it
A controlled run showing no output disagreements on a large sample of actual user queries when precision is the only changed variable, or manual inspection revealing that detected differences stem from non-precision factors.
Figures




read the original abstract
Large language models (LLMs) are increasingly deployed under diverse numerical precision configurations, including standard floating-point formats (e.g., bfloat16 and float16) and quantized integer formats (e.g., int16 and int8), to meet efficiency and resource constraints. However, minor inconsistencies between LLMs of different precisions are difficult to detect and are often overlooked by existing evaluation methods. In this paper, we present PrecisionDiff, an automated differential testing framework for systematically detecting precision-induced behavioral disagreements in LLMs. PrecisionDiff generates precision-sensitive test inputs and performs cross-precision comparative analysis to uncover subtle divergences that remain hidden under conventional testing strategies. To demonstrate its practical significance, we instantiate PrecisionDiff on the alignment verification task, where precision-induced disagreements manifest as jailbreak divergence-inputs that are rejected under one precision may produce harmful responses under another. Experimental results show that such behavioral disagreements are widespread across multiple open-source aligned LLMs and precision settings, and that PrecisionDiff significantly outperforms vanilla testing methods in detecting these issues. Our work enables automated precision-sensitive test generation, facilitating effective pre-deployment evaluation and improving precision robustness during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PrecisionDiff, an automated differential testing framework that generates precision-sensitive test inputs and performs cross-precision comparative analysis to detect subtle behavioral disagreements in LLMs arising from different numerical formats (bfloat16, float16, int8, etc.). It applies the framework to alignment verification, identifying jailbreak divergence cases where outputs are rejected under one precision but produce harmful responses under another, and reports that such disagreements are widespread across open-source aligned models while PrecisionDiff outperforms standard testing methods.
Significance. If the empirical claims hold after proper controls, the work is significant for LLM reliability and safety: it surfaces an under-examined source of nondeterminism that can affect alignment properties in production deployments under efficiency-driven precision choices. The automated test-generation approach and focus on falsifiable behavioral divergences provide a concrete tool that could be integrated into pre-deployment pipelines and training robustness checks.
major comments (1)
- [Methodology and Experimental Results] The cross-precision comparative analysis (described in the methodology and experimental sections) does not include explicit ablations or controls that hold all other implementation variables fixed while varying only the numeric format. Without isolating effects from GEMM kernels, rounding-mode defaults, or library dispatch paths, the attribution of observed output divergences—including jailbreak failures—solely to precision remains insecure and load-bearing for the central claim.
minor comments (1)
- [Abstract] The abstract asserts widespread disagreements and superior detection performance but supplies no methodological details, controls, or quantitative results (e.g., detection rates, statistical significance), reducing immediate clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We address the single major comment below and outline the revisions we will make to strengthen the attribution of observed divergences to numeric precision.
read point-by-point responses
-
Referee: [Methodology and Experimental Results] The cross-precision comparative analysis (described in the methodology and experimental sections) does not include explicit ablations or controls that hold all other implementation variables fixed while varying only the numeric format. Without isolating effects from GEMM kernels, rounding-mode defaults, or library dispatch paths, the attribution of observed output divergences—including jailbreak failures—solely to precision remains insecure and load-bearing for the central claim.
Authors: We appreciate the referee's emphasis on rigorous isolation of the precision variable. In the current experiments, PrecisionDiff loads the identical model weights and uses the same Hugging Face Transformers + PyTorch inference pipeline for all configurations, changing only the torch_dtype argument (bfloat16, float16) or the quantization recipe (int8/int4 via bitsandbytes). This keeps the high-level dispatch and most kernel selection paths constant. Nevertheless, we acknowledge that low-level GEMM implementations and default rounding behaviors can still differ across precisions. In the revised manuscript we will add an explicit ablation subsection that (1) fixes the numeric format while swapping backends (PyTorch native vs. ONNX Runtime with fixed kernels) and (2) reports results under explicitly set rounding modes where the library exposes them. These new controls will be presented alongside the original results to demonstrate that the jailbreak divergences persist primarily under precision changes. revision: yes
Circularity Check
No significant circularity; framework is an independent external testing procedure
full rationale
The paper presents PrecisionDiff as a standalone automated differential testing framework that generates precision-sensitive inputs and performs cross-precision comparisons on LLMs. No load-bearing step reduces by definition, by fitted-parameter renaming, or by self-citation chain to the target result. The central claim (widespread precision-induced disagreements and superior detection) is an empirical outcome of applying the framework, not a tautology constructed from its own inputs or prior self-referential theorems. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We optimize the suffix by minimizing a dual-precision objective: min L(f_p2(x), y_harm) + λ L(f_p1(x), y_safe)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Layer-wise divergence localization via Mean Absolute Difference and Relative Divergence Lift
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. 2021. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
work page 2020
-
[4]
Nicholas Carlini, Milad Nasr, Christopher A Choquette-Choo, Matthew Jagielski, Irena Gao, Pang Wei W Koh, Daphne Ippolito, Florian Tramer, and Ludwig Schmidt. 2023. Are aligned neural networks adversarially aligned?Advances in Neural Information Processing Systems36 (2023), 61478–61500
work page 2023
-
[5]
Nicholas Carlini and David Wagner. 2017. Towards evaluating the robustness of neural networks. In2017 ieee symposium on security and privacy (sp). Ieee, 39–57
work page 2017
-
[6]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. 2025. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 23–42
work page 2025
- [7]
-
[8]
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023)2, 3 (2023), 6
work page 2023
-
[9]
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. 2023. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. InProceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis. 423–435
work page 2023
-
[10]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems35 (2022), 30318–30332
work page 2022
-
[11]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems36 (2023), 10088–10115
work page 2023
-
[12]
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. 2018. Boosting adversarial attacks with momentum. InProceedings of the IEEE conference on computer vision and pattern recognition. 9185–9193
work page 2018
-
[13]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. 2021. A mathematical framework for transformer circuits.Transformer Circuits Thread1, 1 (2021), 12
work page 2021
-
[14]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and harnessing adversarial examples.arXiv preprint arXiv:1412.6572(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Jiazhen Gu, Xuchuan Luo, Yangfan Zhou, and Xin Wang. 2022. Muffin: Testing deep learning libraries via neural architecture fuzzing. InProceedings of the 44th International Conference on Software Engineering. 1418–1430
work page 2022
-
[18]
Qianyu Guo, Sen Chen, Xiaofei Xie, Lei Ma, Qiang Hu, Hongtao Liu, Yang Liu, Jianjun Zhao, and Xiaohong Li. 2019. An empirical study towards characterizing deep learning development and deployment across different frameworks and platforms. In2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 810–822
work page 2019
-
[19]
Qianyu Guo, Xiaofei Xie, Yi Li, Xiaoyu Zhang, Yang Liu, Xiaohong Li, and Chao Shen. 2020. Audee: Automated testing for deep learning frameworks. InPro- ceedings of the 35th IEEE/ACM international conference on automated software engineering. 486–498
work page 2020
- [20]
-
[21]
Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.ArXivabs/231...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Erik Jones, Anca Dragan, Aditi Raghunathan, and Jacob Steinhardt. 2023. Auto- matically auditing large language models via discrete optimization. InInterna- tional Conference on Machine Learning. PMLR, 15307–15329
work page 2023
-
[23]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[24]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Yu, Joey Gonzalez, Hao Zhang, and Ion Stoica. 2023. vllm: Easy, fast, and cheap llm serving with pagedattention.See https://vllm. ai/(accessed 9 August 2023) (2023)
work page 2023
-
[25]
Meiziniu Li, Dongze Li, Jianmeng Liu, Jialun Cao, Yongqiang Tian, and Shing-Chi Cheung. 2024. Enhancing differential testing with llms for testing deep learning libraries.ACM Transactions on Software Engineering and Methodology(2024)
work page 2024
-
[26]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. Awq: Activation-aware weight quantization for on-device llm compression and accel- eration.Proceedings of machine learning and systems6 (2024), 87–100
work page 2024
-
[27]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023. Autodan: Generat- ing stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2017. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt.Advances in neural information processing systems35 (2022), 17359–17372
work page 2022
-
[30]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. 2017. Mixed precision training.arXiv preprint arXiv:1710.03740 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [31]
-
[32]
Jonas Möller, Lukas Pirch, Felix Weissberg, Sebastian Baunsgaard, Thorsten Eisen- hofer, and Konrad Rieck. 2025. Adversarial inputs for linear algebra backends. In Forty-second International Conference on Machine Learning
work page 2025
-
[33]
ONNX Runtime developers. 2018.ONNX Runtime. https://github.com/microsoft/ onnxruntime
work page 2018
-
[34]
Hung Viet Pham, Thibaud Lutellier, Weizhen Qi, and Lin Tan. 2019. CRADLE: cross-backend validation to detect and localize bugs in deep learning libraries. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 1027–1038. Conference’17, July 2017, Washington, DC, USA Wang, Li, Zhang, et al
work page 2019
- [35]
-
[36]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. 2023. Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. 2024. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 1671–1685
work page 2024
-
[38]
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2013. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[39]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Jiannan Wang, Hung Viet Pham, Qi Li, Lin Tan, Yu Guo, Adnan Aziz, and Erik Meijer. 2024. D 3: Differential testing of distributed deep learning with model generation.IEEE Transactions on Software Engineering51, 1 (2024), 38–52
work page 2024
-
[41]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail?Advances in neural information processing systems 36 (2023), 80079–80110
work page 2023
-
[42]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning. PMLR, 38087–38099
work page 2023
-
[43]
Xiaofei Xie, Lei Ma, Haijun Wang, Yuekang Li, Yang Liu, and Xiaohong Li. 2019. Diffchaser: Detecting disagreements for deep neural networks. International Joint Conferences on Artificial Intelligence Organization
work page 2019
- [44]
-
[45]
Shaoyu Yang, Chunrong Fang, Haifeng Lin, Xiang Chen, Jia Liu, and Zhenyu Chen
- [46]
- [47]
- [48]
-
[49]
Qi Zhan, Xing Hu, Yuanyi Lin, Tongtong Xu, Xin Xia, and Shanping Li. 2025. When AllClose Fails: Round-Off Error Estimation for Deep Learning Programs. In 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 91–103
work page 2025
-
[50]
Boyang Zhang, Yicong Tan, Yun Shen, Ahmed Salem, Michael Backes, Savvas Zannettou, and Yang Zhang. 2025. Breaking agents: Compromising autonomous llm agents through malfunction amplification. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing. 34952–34964
work page 2025
- [51]
-
[52]
Jiawen Zhang, Kejia Chen, Lipeng He, Jian Lou, Dan Li, Zunlei Feng, Mingli Song, Jian Liu, Kui Ren, and Xiaohu Yang. 2025. Activation Approximations Can Incur Safety Vulnerabilities in Aligned {LLMs}: Comprehensive Analysis and Defense. In34th USENIX Security Symposium (USENIX Security 25). 339–358
work page 2025
- [53]
-
[54]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.