Recognition: unknown
KnowPilot: Your Knowledge-Driven Copilot for Domain Tasks
Pith reviewed 2026-05-10 06:12 UTC · model grok-4.3
The pith
KnowPilot integrates task-specific priors, explicit knowledge retrieval, and experiential memory to achieve superior performance in domain-oriented text generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
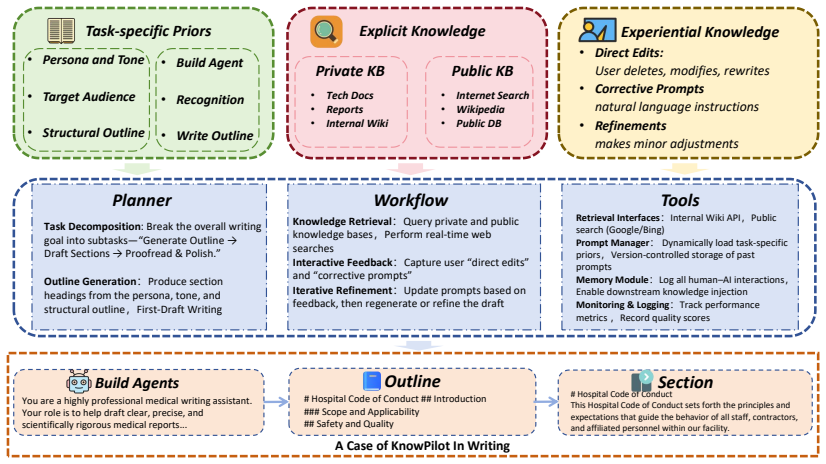
KnowPilot is a Domain-Specific Knowledge Augmented Generative Agent System that integrates task-specific priors, explicit knowledge, and experiential knowledge to enhance agent performance in specialized applications. It combines knowledge retrieval from structured repositories with a memory system capable of capturing expert experience through human-AI interaction. Taking domain-specific writing generation as a representative case, KnowPilot enables private deployment, supports injection of task requirements, loads private knowledge bases, and stores tacit expert knowledge as persistent memory, with experimental results demonstrating superior performance in domain-oriented text generation.
What carries the argument
The KnowPilot framework, which integrates task-specific priors, explicit knowledge retrieval from structured repositories, and a memory system for capturing expert experience via human-AI interaction.
If this is right
- Enables private deployment and secure handling of sensitive domain data.
- Allows injection of task requirements and loading of custom private knowledge bases.
- Stores tacit expert knowledge from human interactions as reusable persistent memory.
- Delivers measurable gains in generating accurate domain-specific text.
- Extends to multiple sectors including medicine, finance, and industry.
Where Pith is reading between the lines
- The memory component could support ongoing refinement of agent behavior in repeated domain interactions without full model retraining.
- Similar knowledge layering might apply to non-text tasks like structured decision support or data summarization in the same fields.
- The design suggests a path for reducing reliance on large general models by grounding outputs in smaller, domain-curated sources.
- Live deployment in industry workflows would test whether the human-AI memory capture scales without adding excessive overhead.
Load-bearing premise
That combining task-specific priors, explicit knowledge retrieval, and experiential memory through human-AI interaction will reliably produce superior agent performance in domain tasks.
What would settle it
A controlled test on the same domain text generation tasks where an agent using only one or two of the three knowledge components matches or exceeds the full KnowPilot performance would falsify the need for the complete integration.
Figures



read the original abstract
Despite the rapid advancement of generative agents, their deployment in real-world industry scenarios often encounters significant challenges due to a lack of domain-specific knowledge. To address this gap, we present KnowPilot: a Domain-Specific Knowledge Augmented Generative Agent System. KnowPilot is an open-source framework that integrates task-specific priors, explicit knowledge, and experiential knowledge to enhance agent performance in specialized applications. It combines knowledge retrieval from structured repositories with a memory system capable of capturing expert experience through human AI interaction. Taking domain-specific writing generation as a representative case, KnowPilot enables private deployment, supports injection of task requirements, loads private knowledge bases, and stores tacit expert knowledge as persistent memory. Experimental results demonstrate that KnowPilot achieves superior performance in domain-oriented text generation and is applicable across fields such as medicine, finance and industry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KnowPilot, an open-source Domain-Specific Knowledge Augmented Generative Agent System that integrates task-specific priors, explicit knowledge retrieval from structured repositories, and experiential memory captured through human-AI interaction. Taking domain-specific text generation as a case study, the system supports private deployment, task requirement injection, and persistent storage of tacit expert knowledge. The central claim is that experimental results demonstrate superior performance in domain-oriented text generation, with applicability across medicine, finance, and industry.
Significance. If the claimed performance gains are substantiated, KnowPilot could provide a useful open-source framework for enhancing generative agents with domain knowledge in real-world settings where general LLMs lack specialized expertise. The combination of structured retrieval and experiential memory addresses a recognized gap, potentially enabling more reliable private deployments in professional domains.
major comments (1)
- Abstract: The assertion that 'Experimental results demonstrate that KnowPilot achieves superior performance in domain-oriented text generation' is presented without any supporting details on experimental design, task definitions, baselines (e.g., vanilla LLMs or RAG-only systems), metrics (automatic or human), quantitative results, or ablation studies on component interactions. This omission is load-bearing for the paper's primary claim and leaves the asserted advantages unevaluable.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [—] Abstract: The assertion that 'Experimental results demonstrate that KnowPilot achieves superior performance in domain-oriented text generation' is presented without any supporting details on experimental design, task definitions, baselines (e.g., vanilla LLMs or RAG-only systems), metrics (automatic or human), quantitative results, or ablation studies on component interactions. This omission is load-bearing for the paper's primary claim and leaves the asserted advantages unevaluable.
Authors: We agree that the abstract, as a concise summary, does not include the requested supporting details on experimental design, task definitions, baselines, metrics, quantitative results, or ablations, which can make the primary claim harder to evaluate at first glance. The full manuscript provides these details in Section 4 (Experiments), including task definitions for domain-specific text generation, baselines such as vanilla LLMs and RAG-only systems, both automatic metrics (e.g., BLEU, ROUGE) and human evaluations, quantitative performance gains, and ablation studies isolating the contributions of structured knowledge retrieval and experiential memory. To address the referee's concern directly, we will revise the abstract to incorporate a brief high-level summary of the evaluation setup and key findings while respecting length constraints. We will also add a forward reference in the introduction to the Experiments section for readers seeking immediate details. revision: yes
Circularity Check
No circularity: paper asserts empirical superiority without derivations, equations, or self-referential predictions
full rationale
The manuscript describes an agent framework (KnowPilot) that integrates task-specific priors, knowledge retrieval, and experiential memory via human-AI interaction. The sole performance claim ('Experimental results demonstrate that KnowPilot achieves superior performance in domain-oriented text generation') is presented as an external empirical outcome rather than a derived result. No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the provided text. No step reduces a prediction to its own inputs by construction, and no self-citations are invoked as load-bearing justifications. The lack of experimental details (baselines, metrics, ablations) renders the claim unevaluable but does not create circularity within any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Integrating task-specific priors, explicit knowledge, and experiential memory improves generative agent performance on domain tasks.
Reference graph
Works this paper leans on
-
[1]
Bridging legal knowledge and ai: Retrieval- augmented generation with vector stores, knowledge graphs, and hierarchical non-negative matrix factor- ization. Preprint, arXiv:2502.20364. Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark...
-
[2]
I mproving language models by retrieving from trillions of tokens
Improving lan- guage models by retrieving from trillions of tokens. Preprint, arXiv:2112.04426. Jiaxi Cui, Munan Ning, Zongjian Li, Bohua Chen, Yang Yan, Hao Li, Bin Ling, Yonghong Tian, and Li Yuan
-
[3]
Chatlaw: Open- source legal large language model with integrated exter- nal knowledge bases
Chatlaw: A multi-agent collabora- tive legal assistant with knowledge graph enhanced mixture-of-experts large language model. Preprint, arXiv:2306.16092. Yunfan Gao, Yun Xiong, Meng Wang, and Haofen Wang
-
[4]
Modular RAG: Transforming RAG systems into LEGO-like reconfigurable frameworks,
Modular rag: Transforming rag systems into lego-like reconfigurable frameworks. Preprint, arXiv:2407.21059. Neel Guha, Julian Nyarko, Daniel E. Ho, Christo- pher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Tal- isman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gr...
-
[5]
Legalbench: A collaboratively built benchmark for measuring le- gal reasoning in large language models. Preprint, arXiv:2308.11462. Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasu- pat, and Ming-Wei Chang
-
[6]
REALM: Retrieval-Augmented Language Model Pre-Training
Realm: Retrieval- augmented language model pre-training. Preprint, arXiv:2002.08909. Yucheng Jiang, Yijia Shao, Dekun Ma, Sina J. Semnani, and Monica S. Lam
work page internal anchor Pith review arXiv 2002
-
[7]
Into the unknown un- knowns: Engaged human learning through participa- tion in language model agent conversations. Preprint, arXiv:2408.15232. Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo
-
[8]
Prometheus 2: An open source language model specialized in evaluating other language mod- els. Preprint, arXiv:2405.01535. Xiangyu Li, Yawen Zeng, Xiaofen Xing, Jin Xu, and Xiangmin Xu. 2025a. Hedgeagents: A balanced- aware multi-agent financial trading system. Preprint, arXiv:2502.13165. Yangning Li, Yinghui Li, Xinyu Wang, Yong Jiang, Zhen Zhang, Xinran...
-
[9]
WebGPT: Browser-assisted question-answering with human feedback
Webgpt: Browser- assisted question-answering with human feedback. Preprint, arXiv:2112.09332. Ikujiro Nonaka
work page internal anchor Pith review arXiv
-
[10]
arXiv preprint arXiv:2408.08921 (2024) A CQ-Driven RAG Workflow for Digital Storytelling 19
Graph retrieval-augmented generation: A survey. Preprint, arXiv:2408.08921. Shuofei Qiao, Runnan Fang, Zhisong Qiu, Xiaobin Wang, Ningyu Zhang, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen
-
[11]
arXiv preprint arXiv:2410.07869 , year=
Bench- marking agentic workflow generation. Preprint, arXiv:2410.07869. Nils Reimers and Iryna Gurevych
-
[12]
Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer: Language models can teach themselves to use tools. Preprint, arXiv:2302.04761. Zirui Song, Bin Yan, Yuhan Liu, Miao Fang, Mingzhe Li, Rui Yan, and Xiuying Chen
work page internal anchor Pith review arXiv
-
[13]
In- jecting domain-specific knowledge into large lan- guage models: A comprehensive survey. Preprint, arXiv:2502.10708. Takehiro Takayanagi, Kiyoshi Izumi, Javier Sanz- Cruzado, Richard McCreadie, and Iadh Ounis
-
[14]
Are generative ai agents effective personalized finan- cial advisors? Preprint, arXiv:2504.05862. Zekun Xi, Wenbiao Yin, Jizhan Fang, Jialong Wu, Run- nan Fang, Ningyu Zhang, Jiang Yong, Pengjun Xie, Fei Huang, and Huajun Chen
-
[15]
Omnithink: Ex- panding knowledge boundaries in machine writing through thinking. Preprint, arXiv:2501.09751. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayi- heng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 oth- ers. 2025a. Q...
-
[16]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models. Preprint, arXiv:2210.03629. Murong Yue
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
A survey of large language model agents for question answering
A survey of large language model agents for question answering. Preprint, arXiv:2503.19213
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.