Recognition: unknown
Learning When Not to Decide: A Framework for Overcoming Factual Presumptuousness in AI Adjudication
Pith reviewed 2026-05-10 02:03 UTC · model grok-4.3
The pith
Requiring AI to explicitly identify missing information before deciding overcomes factual presumptuousness in legal adjudication, reaching 89% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
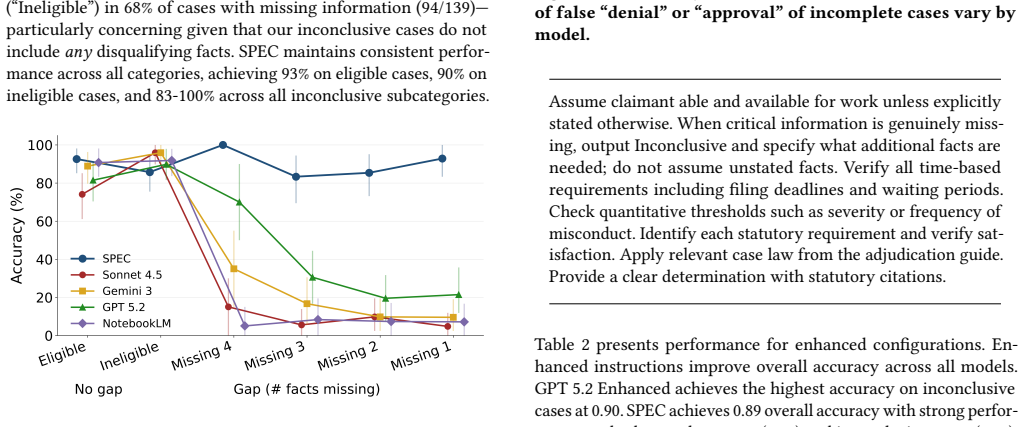
The authors establish that factual presumptuousness in AI adjudication is systematic across leading platforms but addressable through a structured prompting framework called SPEC. On a novel benchmark that systematically varies information completeness using official training materials, standard RAG approaches reach only 15% accuracy on insufficient-information cases, advanced prompting improves inconclusive handling but over-corrects by deferring on clear cases, and SPEC achieves 89% overall accuracy by requiring explicit identification of missing information before any determination, thereby supporting rather than supplanting human judgment wherever evidence is incomplete.
What carries the argument
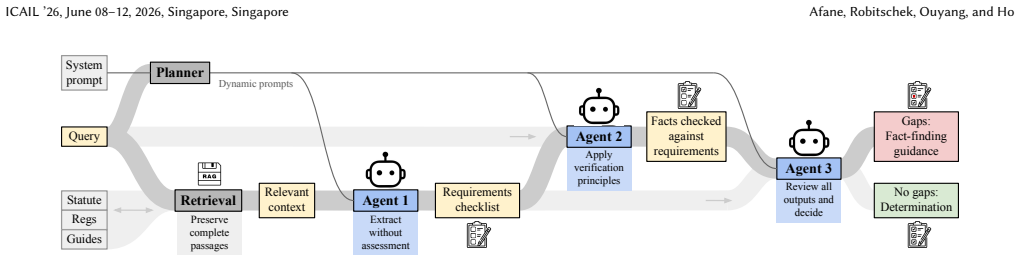
SPEC (Structured Prompting for Evidence Checklists), a prompting structure that requires the AI to produce an explicit list of missing information before outputting any adjudication decision.
If this is right
- Standard RAG-based approaches achieve only 15% accuracy when information is insufficient.
- Advanced prompting improves accuracy on inconclusive cases but causes over-deferral on cases with sufficient evidence.
- SPEC reaches 89% overall accuracy while deferring appropriately on inconclusive cases.
- Presumptuousness is systematic but can be addressed, forming a necessary step toward AI that supports human judgment in adjudication.
- The problem and the fix appear across four leading AI platforms.
Where Pith is reading between the lines
- Similar evidence-checklist prompting could be tested in other evidence-dependent fields such as medical diagnosis or regulatory review.
- Benchmarks that deliberately vary information completeness may become useful for measuring AI reliability beyond standard accuracy scores.
- Embedding explicit deferral signals could allow hybrid systems where AI surfaces cases needing extra human fact-finding, lowering overall error rates.
- The use of official domain guidance to build the benchmark indicates that access to authoritative training materials is important for creating effective safeguards.
Load-bearing premise
The benchmark systematically varies information completeness in a manner representative of real-world adjudication bottlenecks and the performance results on four leading AI platforms generalize.
What would settle it
Running SPEC on a new collection of unemployment insurance cases with independently verified missing-information patterns, or in live deployment by the department, to check whether the 89% accuracy and appropriate deferral behavior persist.
Figures





read the original abstract
A well-known limitation of AI systems is presumptuousness: the tendency of AI systems to provide confident answers when information may be lacking. This challenge is particularly acute in legal applications, where a core task for attorneys, judges, and administrators is to determine whether evidence is sufficient to reach a conclusion. We study this problem in the important setting of unemployment insurance adjudication, which has seen rapid integration of AI systems and where the question of additional fact-finding poses the most significant bottleneck for a system that affects millions of applicants annually. First, through a collaboration with the Colorado Department of Labor and Employment, we secure rare access to official training materials and guidance to design a novel benchmark that systematically varies in information completeness. Second, we evaluate four leading AI platforms and show that standard RAG-based approaches achieve an average of only 15% accuracy when information is insufficient. Third, advanced prompting methods improve accuracy on inconclusive cases but over-correct, withholding decisions even on clear cases. Fourth, we introduce a structured framework requiring explicit identification of missing information before any determination (SPEC, Structured Prompting for Evidence Checklists). SPEC achieves 89% overall accuracy, while appropriately deferring when evidence is insufficient -- demonstrating that presumptuousness in legal AI is systematic but addressable, and that doing so is a necessary step towards systems that reliably support, rather than supplant, human judgment wherever decisions must await sufficient evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI systems exhibit systematic factual presumptuousness in high-stakes legal adjudication, particularly unemployment insurance decisions. Using a novel benchmark constructed from Colorado Department of Labor and Employment training materials that varies information completeness, it shows standard RAG approaches achieve only 15% accuracy on insufficient-evidence cases. Advanced prompting improves inconclusive-case handling but over-corrects on clear cases. The introduced SPEC (Structured Prompting for Evidence Checklists) framework, which mandates explicit missing-information identification before any determination, reaches 89% overall accuracy while appropriately deferring, demonstrating that presumptuousness is addressable and that AI should support rather than supplant human judgment on evidence sufficiency.
Significance. If the benchmark is representative of real adjudication bottlenecks and the performance gains generalize, the work is significant for AI deployment in legal and administrative domains. It supplies concrete empirical evidence of a known limitation (presumptuousness) with a practical, structured prompting intervention that improves deferral behavior without sacrificing accuracy on complete cases. Credit is due for the rare collaboration yielding official training materials, the independently constructed benchmark, and the emphasis on systems that reliably flag evidence insufficiency rather than forcing decisions.
major comments (2)
- [Benchmark construction section] Benchmark construction section: the claim that the novel benchmark 'systematically varies information completeness' in a manner representative of real-world adjudication requires quantitative support (e.g., frequency distributions of missing-fact categories, inter-expert agreement rates on sufficiency labels, or mapping to actual docket statistics). Without this, the reported 15% RAG accuracy on insufficient cases and the 89% SPEC gain risk being artifacts of the authors' instantiation of 'insufficient' rather than a general property, directly undermining the central conclusion that presumptuousness is systematic and addressable.
- [Experimental evaluation section] Experimental evaluation section: the concrete accuracy figures (15% for RAG, 89% for SPEC) are presented without sample sizes, confidence intervals, statistical significance tests, or precise protocols for labeling sufficiency and measuring deferral. This detail is load-bearing for assessing whether the performance gap and appropriate-deferral claim hold beyond the specific benchmark instances.
minor comments (2)
- [Abstract] The abstract refers to 'four leading AI platforms' without naming them; listing the specific models or systems in the abstract or introduction would improve immediate clarity for readers.
- Consider adding a table summarizing the benchmark's information-completeness variations (e.g., number of cases per completeness level and example missing-fact types) to make the evaluation setup more transparent.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript. We have carefully considered the major comments and provide point-by-point responses below, along with proposed revisions to address the concerns raised.
read point-by-point responses
-
Referee: Benchmark construction section: the claim that the novel benchmark 'systematically varies information completeness' in a manner representative of real-world adjudication requires quantitative support (e.g., frequency distributions of missing-fact categories, inter-expert agreement rates on sufficiency labels, or mapping to actual docket statistics). Without this, the reported 15% RAG accuracy on insufficient cases and the 89% SPEC gain risk being artifacts of the authors' instantiation of 'insufficient' rather than a general property, directly undermining the central conclusion that presumptuousness is systematic and addressable.
Authors: We appreciate this feedback on strengthening the benchmark validation. The benchmark was designed by starting with complete case scenarios from the official Colorado Department of Labor and Employment training materials and systematically varying the presence of key evidentiary facts as defined in those materials. In the revised manuscript, we will add a table showing the frequency distribution of missing-fact categories (e.g., missing wage information, missing separation details) across the insufficient-evidence cases. We did not compute inter-expert agreement rates because the sufficiency determinations follow explicit criteria from the official guidance, which we treat as ground truth. Regarding mapping to docket statistics, we are unable to provide this due to restrictions on accessing aggregated real-world case data; however, we will include additional discussion on how the training materials are used to train adjudicators and thus reflect real adjudication requirements. These additions will better support the claim that the benchmark captures systematic aspects of presumptuousness. revision: partial
-
Referee: Experimental evaluation section: the concrete accuracy figures (15% for RAG, 89% for SPEC) are presented without sample sizes, confidence intervals, statistical significance tests, or precise protocols for labeling sufficiency and measuring deferral. This detail is load-bearing for assessing whether the performance gap and appropriate-deferral claim hold beyond the specific benchmark instances.
Authors: We agree that these details are essential for reproducibility and assessing the robustness of our results. The benchmark consists of 200 instances, with 100 cases having sufficient evidence and 100 with insufficient evidence. In the revised version, we will explicitly state the sample size, report 95% confidence intervals calculated via bootstrapping, and include results of statistical significance tests (e.g., McNemar's test) comparing the methods. Additionally, we will expand the experimental setup section to provide precise protocols: sufficiency labels are assigned based on whether all required facts per the official checklist are present, and deferral is measured by whether the model outputs that evidence is insufficient rather than making a determination. These revisions will allow readers to better evaluate the generalizability of the findings. revision: yes
- Mapping the benchmark instances to actual docket statistics from the Colorado Department of Labor and Employment, as this data is not accessible due to privacy constraints.
Circularity Check
No significant circularity detected
full rationale
The paper constructs its benchmark from external official Colorado Department of Labor and Employment training materials, evaluates four existing AI platforms on it to report baseline performance (e.g., 15% accuracy on insufficient-information cases), and introduces the SPEC prompting framework whose 89% overall accuracy is measured directly on that same benchmark. No equations, parameter fits, self-citations, or definitional steps are present in the provided text that would reduce the central claims to tautological re-expression of the inputs. The derivation chain consists of independent empirical measurement rather than self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The official training materials and guidance from Colorado Department of Labor and Employment accurately reflect real adjudication information sufficiency requirements.
Reference graph
Works this paper leans on
-
[1]
Technical Report
2023.State of New Hampshire Use of Artificial Intelligence (AI) Technologies Policy. Technical Report. State of New Hampshire Department of Information Technol- ogy Office of the Chief Information Officer. https://mm.nh.gov/files/uploads/ doit/documents/sonh-use-of-artificial-intelligence-technologies-policy.pdf
2023
-
[2]
Natalie Alms. 2024. Labor Department experiments with AI in unemployment sys- tems. https://www.nextgov.com/digital-government/2024/02/labor-department- experiments-ai-unemployment-systems/394179/
2024
-
[3]
Saar Alon-Barkat and Madalina Busuioc. 2023. Human–AI Interactions in Public Sector Decision Making: “Automation Bias” and “Selective Adherence” to Algo- rithmic Advice.Journal of Public Administration Research and Theory33, 1 (Jan. 2023), 153–169. doi:10.1093/jopart/muac007
-
[4]
Kevin D. Ashley. 2017.Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age(1 ed.). Cambridge University Press. doi:10.1017/ 9781316761380
2017
-
[5]
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2024. Graph of Thoughts: Solving Elaborate Prob- lems with Large Language Models.Proceedings of the AAAI Conference on Artificial Intelligence38, 16 (March 2024), 17682–176...
-
[6]
Ho, Olivia Martin, Kit Rodolfa, and Amy Perez
Daniel E. Ho, Olivia Martin, Kit Rodolfa, and Amy Perez. 2025. Evaluation as Due Process: Civil Service in an Automated Age.Administrative Law Review(2025)
2025
-
[7]
Maria De-Arteaga, Riccardo Fogliato, and Alexandra Chouldechova. 2020. A Case for Humans-in-the-Loop: Decisions in the Presence of Erroneous Algorithmic Scores. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems. ACM, Honolulu HI USA, 1–12. doi:10.1145/3313831.3376638
-
[8]
Shrey Desai and Greg Durrett. 2020. Calibration of Pre-trained Transformers. doi:10.48550/arXiv.2003.07892
-
[9]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch
-
[10]
InProceedings of the 41st International Conference on Machine Learning (Vienna, Austria)(ICML’24)
Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st International Conference on Machine Learning (Vienna, Austria)(ICML’24). JMLR.org, Article 467, 31 pages
-
[11]
David Freeman Engstrom and Daniel E. Ho. 2020. Algorithmic Accountability in the Administrative State.Yale Journal on Regulation(Jan. 2020). https: //openyls.law.yale.edu/handle/20.500.13051/8311
2020
-
[12]
Ryan Felton. 2016. Michigan unemployment agency made 20,000 false fraud accusations – report.The Guardian(Dec. 2016). https://www.theguardian.com/ us-news/2016/dec/18/michigan-unemployment-agency-fraud-accusations
2016
-
[13]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Ji- awei Sun, Meng Wang, and Haofen Wang. 2023. Retrieval-Augmented Generation for Large Language Models: A Survey. doi:10.48550/ARXIV.2312.10997
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2023
-
[14]
Yonatan Geifman and Ran El-Yaniv. 2017. Selective Classification for Deep Neural Networks. doi:10.48550/ARXIV.1705.08500
-
[15]
Yonatan Geifman and Ran El-Yaniv. 2019. SelectiveNet: A Deep Neural Network with an Integrated Reject Option. doi:10.48550/ARXIV.1901.09192
-
[16]
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rock- more, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H. C...
-
[17]
Luxi He, Nimra Nadeem, Michel Liao, Howard Chen, Danqi Chen, Mariano- Florentino Cuéllar, and Peter Henderson. 2025. Statutory Construction and Interpretation for Artificial Intelligence. doi:10.48550/ARXIV.2509.01186
-
[18]
Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball. [n. d.]. CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review. ([n. d.])
-
[19]
Nils Holzenberger, Andrew Blair-Stanek, and Benjamin Van Durme. 2020. A Dataset for Statutory Reasoning in Tax Law Entailment and Question Answering. doi:10.48550/ARXIV.2005.05257
- [20]
-
[22]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. doi:10.48550/ARXIV.2005.11401
work page internal anchor Pith review doi:10.48550/arxiv.2005.11401 2020
-
[24]
Shuyue Stella Li, Vidhisha Balachandran, Shangbin Feng, Jonathan S. Ilgen, Emma Pierson, Pang Wei Koh, and Yulia Tsvetkov. 2024. MediQ: Question-Asking LLMs and a Benchmark for Reliable Interactive Clinical Reasoning. doi:10.48550/ARXIV. 2406.00922
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[25]
Sravanthi Machcha, Sushrita Yerra, Sahil Gupta, Aishwarya Sahoo, Sharmin Sultana, Hong Yu, and Zonghai Yao. 2026. Knowing When to Abstain: Medical LLMs Under Clinical Uncertainty. doi:10.48550/ARXIV.2601.12471
-
[26]
Varun Magesh, Olivia H Martin, Faiz Surani, Amy Perez, Kit Rodolfa, and Daniel E Ho. 2026. Evaluating Generative AI in Benefits Administration: A Demonstration Project.Symposium on Computer Science and Law (CSLA W ’26)(2026). https: //dho.stanford.edu/wp-content/uploads/CDLE.pdf
2026
-
[27]
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Man- ning, and Daniel E. Ho. 2024. Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. doi:10.48550/arXiv.2405.20362
-
[28]
Motomura, Jason Reinecke, and Jonathan S
Lisa Larrimore Ouellette, Amy R. Motomura, Jason Reinecke, and Jonathan S. Masur. 2025. Can AI Hold Office Hours?Journal of Legal Education (forthcoming) (Feb. 2025). doi:10.2139/ssrn.5166938
-
[29]
2023.Recoding America: Why Government Is Failing in the Digital Age and How We Can Do Better
Jennifer Pahlka. 2023.Recoding America: Why Government Is Failing in the Digital Age and How We Can Do Better. Henry Holt and Company
2023
-
[30]
Kusuma Raditya and Pantho Sayed. 2025. Retrieval-augmented gen- eration (RAG): Towards a promising LLM architecture for legal work? https://jolt.law.harvard.edu/digest/retrieval-augmented-generation-rag- towards-a-promising-llm-architecture-for-legal-work
2025
-
[31]
Maohao Shen, Subhro Das, Kristjan Greenewald, Prasanna Sattigeri, Gregory Wornell, and Soumya Ghosh. 2024. Thermometer: Towards Universal Calibration for Large Language Models. doi:10.48550/arXiv.2403.08819
-
[32]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. doi:10.48550/ARXIV.2303.11366
work page internal anchor Pith review doi:10.48550/arxiv.2303.11366 2023
-
[33]
Tejas Srinivasan, Jack Hessel, Tanmay Gupta, Bill Yuchen Lin, Yejin Choi, Jesse Thomason, and Khyathi Raghavi Chandu. 2024. Selective "Selective Prediction": Reducing Unnecessary Abstention in Vision-Language Reasoning. doi:10.48550/ ARXIV.2402.15610
-
[34]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. doi:10.48550/arXiv.2203.11171
-
[35]
Zora Zhiruo Wang, Yijia Shao, Omar Shaikh, Daniel Fried, Graham Neubig, and Diyi Yang. 2025. How Do AI Agents Do Human Work? Comparing AI and Human Workflows Across Diverse Occupations. doi:10.48550/arXiv.2510.22780
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and others. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[37]
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. 2025. Know Your Limits: A Survey of Abstention in Large Language Models.Transactions of the Association for Computational Linguistics 13 (June 2025), 529–556. doi:10.1162/tacl_a_00754
-
[38]
Nirmalie Wiratunga, Ramitha Abeyratne, Lasal Jayawardena, Kyle Martin, Stew- art Massie, Ikechukwu Nkisi-Orji, Ruvan Weerasinghe, Anne Liret, and Bruno Fleisch. 2024. CBR-RAG: Case-Based Reasoning for Retrieval Augmented Gener- ation in LLMs for Legal Question Answering. doi:10.48550/arXiv.2404.04302
-
[39]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 36. Curran Associates, Inc., 11809–11822
2023
-
[40]
F., Yilmaz, E., Shi, S., and Tu, Z
Fanghua Ye, Mingming Yang, Jianhui Pang, Longyue Wang, Derek F. Wong, Emine Yilmaz, Shuming Shi, and Zhaopeng Tu. 2024. Benchmarking LLMs via Uncertainty Quantification.Advances in Neural Information Processing Systems 37 (Dec. 2024), 15356–15385. doi:10.52202/079017-0491
-
[41]
Young, Johannes Himmelreich, Danylo Honcharov, and Sucheta Soundarajan
Matthew M. Young, Johannes Himmelreich, Danylo Honcharov, and Sucheta Soundarajan. 2022. Using Artificial Intelligence to Identify Administrative Errors in Unemployment Insurance.Government Information Quarterly39, 4 (Oct. 2022), 101758. doi:10.1016/j.giq.2022.101758
-
[42]
Jesus Manuel Niebla Zatarain. 2018. Book Review: Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age.Script-ed15, 1 (Aug. 2018), 156–161. doi:10.2966/scrip.150118.156
-
[43]
Anderson, Peter Henderson, and Daniel E
Lucia Zheng, Neel Guha, Brandon R. Anderson, Peter Henderson, and Daniel E. Ho. 2021. When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset. doi:10.48550/arXiv.2104.08671
-
[44]
Zhanke Zhou, Xiao Feng, Zhaocheng Zhu, Jiangchao Yao, Sanmi Koyejo, and Bo Han. 2025. From Passive to Active Reasoning: Can Large Language Models Ask the Right Questions under Incomplete Information? doi:10.48550/arXiv.2506. 08295
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.